







http://blog.csdn.net/gamer_gyt/article/details/51684716 原文
1:联系用户兴趣和物品的方式
2:标签系统的典型代表
3:用户如何打标签
4:基于标签的推荐系统
5:算法的改进
6:标签推荐
源代码查看地址:github查看
一:联系用户兴趣和物品的方式
推荐系统的目的是联系用户的兴趣和物品,这种联系方式需要依赖不同的媒介。目前流行的推荐系统基本上是通过三种方式联系用户兴趣和物品。
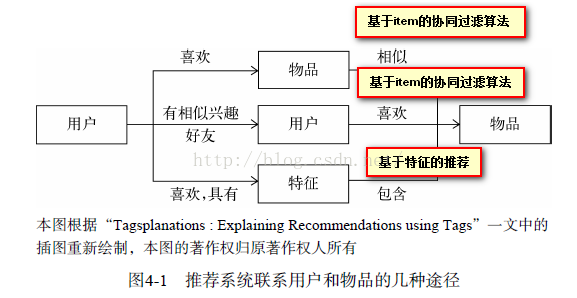
1:利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,即基于item的系统过滤推荐算法(算法分析可参考:点击阅读)
2:利用用户和兴趣用户兴趣相似的其他用户,给用户推荐哪些和他们兴趣爱好相似的其他用户喜欢的物品,即基于User的协同过滤推荐算法(算法分析可参考:点击阅读)
3:通过一些特征联系用户和物品,给用户推荐那些具有用户喜欢的特征的物品,这里的特征有不同的表现形式,比如可以表现为物品的属性集合,也可以表现为隐语义向量,而下面我们要讨论的是一种重要的特征表现形式——标签
二:标签系统的典型代表
pass掉那些国外网站,比如说豆瓣图书(左),网易云音乐(右)
标签系统确实能够帮助用户发现他们喜欢和感兴趣的物品
三:用户如何打标签
在互联网中每个人的行为都是随机的,但其实这些表面的行为隐藏着很多规律,那么我们对用户打的标签进行统计呢,便引入了标签流行度,我们定义的一个标签被一个用户使用在一个物品上,他的流行度就加1,可以如下代码实现:
- #统计标签流行度
- def TagPopularity(records):
- tagfreq = dict()
- for user, item ,tag in records:
- if tag not in tagfreq:
- tagfreq[tag] = 1
- else:
- tagfreq[tag] +=1
- return tagfreq
下面的是一个标签流行度分布图,其也是符合典型的长尾分布,他的双对数曲线几乎是一条直线
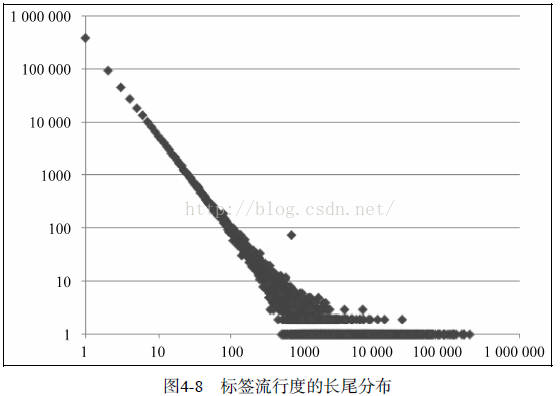
在用户看到一个物品时,我们希望他打的标签是能够准确的描述物品内容属性的关键词,但用户往往不是按照我们的想法操作,而是可能给物品打上各种各样奇奇怪怪的标签,此时便需要我们人工编辑一些特定的标签供用户选择,Scott A. Golder 总结了Delicious上的标签,将它们分为如下几类。
表明物品是什么 比如是一只鸟,就会有“鸟”这个词的标签;是豆瓣的首页,就有一个标签叫“豆瓣”;是乔布斯的首页,就会有个标签叫“乔布斯”。
表明物品的种类 比如在Delicious的书签中,表示一个网页类别的标签包括 article(文章)、blog(博客)、 book(图书)等。
表明谁拥有物品 比如很多博客的标签中会包括博客的作者等信息。
表达用户的观点 比如用户认为网页很有趣,就会打上标签funny(有趣),认为很无聊,就会打上标签boring(无聊)。
用户相关的标签 比如 my favorite(我最喜欢的)、my comment(我的评论)等。
用户的任务 比如 to read(即将阅读)、job search(找工作)
比如在豆瓣上,标签便被分为如下几个类别
四:基于标签的推荐系统
用户用标签来描述对物品的看法,因此标签是联系用户和物品的纽带,也是反应用户兴趣的重要数据源,如何利用用户的标签数据提高个性化推荐结果的质量是推荐系统研究的重要课题。
豆瓣很好地利用了标签数据,它将标签系统融入到了整个产品线中。
首先,在每本书的页面上,豆瓣都提供了一个叫做“豆瓣成员常用标签”的应用,它给出了这本书上用户最常打的标签。
同时,在用户给书做评价时,豆瓣也会让用户给图书打标签。
最后,在最终的个性化推荐结果里,豆瓣利用标签将用户的推荐结果做了聚类,显示了对不同标签下用户的推荐结果,从而增加了推荐的多样性和可解释性。
一个用户标签行为的数据集一般由一个三元组的集合表示,其中记录(u, i, b) 表示用户u给物品i打上了标签b。当然,用户的真实标签行为数据远远比三元组表示的要复杂,比如用户打标签的时间、用户的属性数据、物品的属性数据等。但是为了集中讨论标签数据,只考虑上面定义的三元组形式的数据,即用户的每一次打标签行为都用一个三元组(用户、物品、标签)表示。
1:试验设置
本节将数据集随机分成10份。这里分割的键值是用户和物品,不包括标签。也就是说,用户对物品的多个标签记录要么都被分进训练集,要么都被分进测试集,不会一部分在训练集,另一部分在测试集中。然后,我们挑选1份作为测试集,剩下的9份作为训练集,通过学习训练集中的用户标签数据预测测试集上用户会给什么物品打标签。对于用户u,令R(u)为给用户u的长度为N的推荐列表,里面包含我们认为用户会打标签的物品。令T(u)是测试集中用户u实际上打过标签的物品集合。然后,我们利用准确率(precision)和召回率(recall)评测个性化推荐算法的精度。
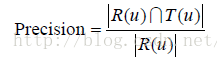
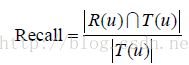
将上面的实验进行10次,每次选择不同的测试集,然后将每次实验的准确率和召回率的平均值作为最终的评测结果。为了全面评测个性化推荐的性能,我们同时评测了推荐结果的覆盖率(coverage)、多样性(diversity)和新颖度。覆盖率的计算公式如下:
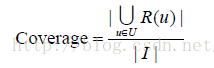
接下来我们用物品标签向量的余弦相似度度量物品之间的相似度。对于每个物品i,item_tags[i]存储了物品i的标签向量,其中item_tags[i][b]是对物品i打标签b的次数,那么物品i和j的余弦相似度可以通过如下程序计算。
- #计算余弦相似度
- def CosineSim(item_tags,i,j):
- ret = 0
- for b,wib in item_tags[i].items(): #求物品i,j的标签交集数目
- if b in item_tags[j]:
- ret += wib * item_tags[j][b]
- ni = 0
- nj = 0
- for b, w in item_tags[i].items(): #统计 i 的标签数目
- ni += w * w
- for b, w in item_tags[j].items(): #统计 j 的标签数目
- nj += w * w
- if ret == 0:
- return 0
- return ret/math.sqrt(ni * nj) #返回余弦值
在得到物品之间的相似度度量后,我们可以用如下公式计算一个推荐列表的多样性:
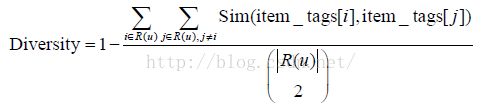
Python实现为:
- #计算推荐列表多样性
- def Diversity(item_tags,recommend_items):
- ret = 0
- n = 0
- for i in recommend_items.keys():
- for j in recommend_items.keys():
- if i == j:
- continue
- ret += CosineSim(item_tags,i,j)
- n += 1
- return ret/(n * 1.0)
推荐系统的多样性为所有用户推荐列表多样性的平均值。
至于推荐结果的新颖性,我们简单地用推荐结果的平均热门程度(AveragePopularity)度量。对于物品i,定义它的流行度item_pop(i)为给这个物品打过标签的用户数。而对推荐系统,我们定义它的平均热门度如下:
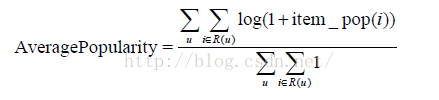
2:一个简单的算法
拿到了用户标签行为数据,相信大家都可以想到一个最简单的个性化推荐算法。这个算法的
描述如下所示。
统计每个用户最常用的标签。
对于每个标签,统计被打过这个标签次数最多的物品。
对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
对于上面的算法,用户u对物品i的兴趣公式如下:
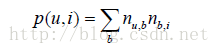
这里,B(u)是用户u打过的标签集合,B(i)是物品i被打过的标签集合,nu,b是用户u打过标签b的次数,nb,i是物品i被打过标签b的次数。本章用SimpleTagBased标记这个算法。
在Python中,我们遵循如下约定:
用 records 存储标签数据的三元组,其中records[i] = [user, item, tag];
用 user_tags 存储nu,b,其中user_tags[u][b] = nu,b;
用 tag_items存储nb,i,其中tag_items[b][i] = nb,i。
如下程序可以从records中统计出user_tags和tag_items:
- <span style="font-family:Microsoft YaHei;">#从records中统计出user_tags和tag_items
- def InitStat(records):
- user_tags = dict()
- tag_items = dict()
- user_items = dict()
- for user, item, tag in records.items():
- addValueToMat(user_tags, user, tag, 1)
- addValueToMat(tag_items, tag, item, 1)
- addValueToMat(user_items, user, item, 1)</span>
统计出user_tags和tag_items之后,我们可以通过如下程序对用户进行个性化推荐:
- <span style="font-family:Microsoft YaHei;">#对用户进行个性化推荐
- def Recommend(user):
- recommend_items = dict()
- tagged_items = user_items[user]
- for tag, wut in user_tags[user].items():
- for item, wti in tag_items[tag].items():
- #if items have been tagged, do not recommend them
- if item in tagged_items:
- continue
- if item not in recommend_items:
- recommend_items[item] = wut * wti
- else:
- recommend_items[item] += wut * wti
- return recommend_items
- </span>
五:算法的改进
再次回顾四中提出的简单算法
该算法存在许多缺点,比如说对于热门商品的处理,数据洗漱性的处理等,这也是在推荐系统中经常会遇见的问题
1:TF-IDF
前面这个公式倾向于给热门标签对应的热门物品很大的权重,因此会造成推荐热门的物品给用户,从而降低推荐结果的新颖性。另外,这个公式利用用户的标签向量对用户兴趣建模,其中每个标签都是用户使用过的标签,而标签的权重是用户使用该标签的次数。这种建模方法的缺点是给热门标签过大的权重,从而不能反应用户个性化的兴趣。这里我们可以借鉴TF-IDF的思想,对这一公式进行改进:
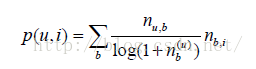
这里,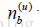
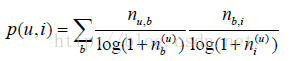
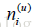 记录了物品i被多少个不同的用户打过标签。这个算法记为TagBasedTFIDF++。
记录了物品i被多少个不同的用户打过标签。这个算法记为TagBasedTFIDF++。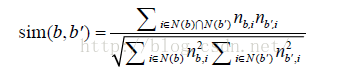
标签清理的另一个重要意义在于将标签作为推荐解释。如果我们要把标签呈现给用户,将其作为给用户推荐某一个物品的解释,对标签的质量要求就很高。首先,这些标签不能包含没有意义的停止词或者表示情绪的词,其次这些推荐解释里不能包含很多意义相同的词语。
一般来说有如下标签清理方法:
去除词频很高的停止词;
去除因词根不同造成的同义词,比如 recommender system和recommendation system;
去除因分隔符造成的同义词,比如 collaborative_filtering和collaborative-filtering。
推荐程序(更新查看地址:github // 数据集下载):
- #!/usr/bin/env python
- #-*-coding:utf-8-*-
- import random
- #统计各类数量
- def addValueToMat(theMat,key,value,incr):
- if key not in theMat: #如果key没出先在theMat中
- theMat[key]=dict();
- theMat[key][value]=incr;
- else:
- if value not in theMat[key]:
- theMat[key][value]=incr;
- else:
- theMat[key][value]+=incr;#若有值,则递增
- user_tags = dict();
- tag_items = dict();
- user_items = dict();
- user_items_test = dict();#测试集数据字典
- #初始化,进行各种统计
- def InitStat():
- data_file = open('delicious.dat')
- line = data_file.readline();
- while line:
- if random.random()>0.1:#将90%的数据作为训练集,剩下10%的数据作为测试集
- terms = line.split("\t");#训练集的数据结构是[user, item, tag]形式
- user=terms[0];
- item=terms[1];
- tag=terms[2];
- addValueToMat(user_tags,user,tag,1)
- addValueToMat(tag_items,tag,item,1)
- addValueToMat(user_items,user,item,1)
- line = data_file.readline();
- else:
- addValueToMat(user_items_test,user,item,1)
- data_file.close();
- #推荐算法
- def Recommend(usr):
- recommend_list = dict();
- tagged_item = user_items[usr];#得到该用户所有推荐过的物品
- for tag_,wut in user_tags[usr].items():#用户打过的标签及次数
- for item_,wit in tag_items[tag_].items():#物品被打过的标签及被打过的次数
- if item_ not in tagged_item:#已经推荐过的不再推荐
- if item_ not in recommend_list:
- recommend_list[item_]=wut*wit;#根据公式
- else:
- recommend_list[item_]+=wut*wit;
- return sorted(recommend_list.iteritems(), key=lambda a:a[1],reverse=True)
- InitStat()
- recommend_list = Recommend("48411")
- # print recommend_list
- for recommend in recommend_list[:10]: #兴趣度最高的十个itemid
- print recommend
('912', 610)
('3763', 394)
('52503', 238)
('39051', 154)
('45647', 147)
('21832', 144)
('1963', 143)
('1237', 140)
('33815', 140)
('5136', 138)
六:标签推荐
提高标签质量 同一个语义不同的用户可能用不同的词语来表示。这些同义词会使标签的词表变得很庞大,而且会使计算相似度不太准确。而使用推荐标签时,我们可以对词表进行选择,首先保证词表不出现太多的同义词,同时保证出现的词都是一些比较热门的、有代表性的词。
- <span style="font-family:Microsoft YaHei;font-size:14px;">def RecommendPopularTags(user,item, tags, N):
- return sorted(tags.items(), key=itemgetter(1), reverse=True)[0:N] </span>
- <span style="font-family:Microsoft YaHei;font-size:14px;">def RecommendItemPopularTags(user,item, item_tags, N):
- return sorted(item_tags[item].items(), key=itemgetter(1), reverse=True)[0:N]</span>
- <span style="font-family:Microsoft YaHei;font-size:14px;">def RecommendUserPopularTags(user,item, user_tags, N):
- return sorted(user_tags[user].items(), key=itemgetter(1), reverse=True)[0:N]</span>
- <span style="font-family:Microsoft YaHei;font-size:14px;">def RecommendHybridPopularTags(user,item, user_tags, item_tags, alpha, N):
- max_user_tag_weight = max(user_tags[user].values())
- for tag, weight in user_tags[user].items():
- ret[tag] = (1 – alpha) * weight / max_user_tag_weight
- </span>
- <span style="font-family:Microsoft YaHei;font-size:14px;"> max_item_tag_weight = max(item_tags[item].values())
- for tag, weight in item_tags[item].items():
- if tag not in ret:
- ret[tag] = alpha * weight / max_item_tag_weight
- else:
- ret[tag] += alpha * weight / max_item_tag_weight
- return sorted(ret[user].items(), key=itemgetter(1), reverse=True)[0:N]</span>















 2319
2319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









