









论文链接:Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models
摘要
序列推荐旨在评估动态的用户偏好以及用户历史行为之间的序列依赖关系。尽管基于transformer的模型已被证明对序列推荐是有效的,但它们受到注意力算子的二次计算复杂性导致的推理效率低下的问题的困扰,特别是对于长程行为序列。受最近状态空间模型(ssm)成功的启发,本文提出Mamba4Rec,这是第一个探索选择性ssm高效序列推荐潜力的工作。基于基础的Mamba模块,即一个带有硬件感知并行算法的选择性SSM,我们结合了一系列序列建模技术,在保证推理效率的同时,进一步提升模型性能。在两个公开数据集上的实验表明,Mamba4Rec能够很好地解决效果-效率困境,在效果和效率上都优于基于RNN和基于注意力的基线。代码可以在https://github.com/chengkai-liu/Mamba4Rec上找到。
- 关键词:序列推荐,状态空间模型
1.引言
个性化在线服务严重依赖顺序推荐系统来捕捉动态的用户偏好[15,16,25]。这些系统旨在通过有效建模用户历史行为之间的时序依赖关系来预测用户未来的交互行为。早期的神经方法采用卷积神经网络(CNNs)[23]和循环神经网络(RNNs)[10,14],它们率先将神经网络应用于顺序推荐,但面临灾难性的遗忘问题[13,19]。最近,研究人员开始引入Transformer[24]作为骨干模块,并利用自注意力机制对动态用户行为序列进行建模[11,26]。尽管这些基于注意力的方法具有显著的性能,但由于注意力算子固有的二次计算复杂性,这些方法普遍存在推理效率低下的问题,特别是对于长用户行为序列或大规模数据集。
为了解决推荐性能和推理效率的两难问题,文中将状态空间模型(SSM)[5]作为序列推荐的核心算子。SSM(如S4[5]、S5[20]、Mega[17])在各种自然语言任务中被广泛用作rnn、cnn和transformer的替代品。由于递归性,它们具有固有的推理效率,同时通过结构化状态矩阵处理长程依赖关系具有强大的性能。此外,最近提出的一种SSM变体(Mamba[3])进一步引入了数据依赖的选择机制,通过高效的硬件感知设计来解决先前SSM的数据和时不变问题。这使得模型可以根据输入数据有选择地提取必要的知识,并过滤掉不相关的噪声,从而带来卓越的序列建模性能。
本文提出Mamba4Rec,这是第一个探索选择性SSM高效序列推荐潜力的工作。在基本Mamba块[3]的基础上,结合并讨论了一系列技术(如位置嵌入[24]、残差连接[8]、层归一化[1]和位置前馈网络[24]),补充了系统的非线性,稳定了训练动态,从而进一步提升了序列建模能力。
本文的主要贡献如下:
- 本文首次探索了选择性SSM在序列推荐中的潜力,解决了推荐性能和推理效率的困境。
- 本文提出Mamba4Rec,将基本Mamba块与各种技术相结合,如层规范化和前馈网络,在不牺牲推理效率的情况下,进一步提高了顺序建模能力。
- 在两个公开数据集上的实验表明,与基于RNN和基于注意力的基线方法相比,Mamba4Rec在有效性和效率方面均具有优越性。
2.预备知识
2.1 问题陈述
在序列推荐中:
U
=
{
u
1
,
u
2
,
…
,
u
∣
U
∣
}
\mathcal{U}=\left\{u_1, u_2, \ldots, u_{|\mathcal{U}|}\right\}
U={u1,u2,…,u∣U∣}:用户集
V
=
{
v
1
,
v
2
,
…
,
v
∣
V
∣
}
\mathcal{V}=\left\{v_1, v_2, \ldots, v_{|\mathcal{V}|}\right\}
V={v1,v2,…,v∣V∣}:商品集
S
u
=
{
v
1
,
v
2
,
…
,
v
n
u
}
\mathcal{S_u}=\left\{v_1, v_2, \ldots, v_{\mathcal{n_u}}\right\}
Su={v1,v2,…,vnu}:用户
u
u
u对应的按时间顺序排列的交互序列,其中
n
u
n_u
nu是序列的长度
给定用户
u
u
u的交互历史
S
u
\mathcal{S_u}
Su,任务是预测下一个交互商品,用
v
n
u
+
1
v_{\mathcal{n_{u+1}}}
vnu+1表示。
2.2 状态空间模型
状态空间模型(SSM)是一种基于线性常微分方程的序列建模框架。它通过隐状态
h
(
t
)
∈
R
N
h(t) \in \mathbb{R}^N
h(t)∈RN,将一个输入序列
x
(
t
)
∈
R
D
x(t) \in \mathbb{R}^D
x(t)∈RD映射到一个输出序列
y
(
t
)
∈
R
N
y(t) \in \mathbb{R}^N
y(t)∈RN:

离散化之后,序列模型就可以以线性递归的方式计算,这增强了计算效率。从普通的SSM衍生而来,结构化状态空间模型(S4)[5]通过HiPPO[4]初始化将结构强加于状态矩阵𝑨,以进一步改进长程依赖建模。
在S4的基础上,Mamba[3]引入了一种数据依赖的选择机制,并以循环模式利用硬件感知的并行算法。这种组合方法使Mamba能够有效地捕获上下文信息,特别是在长序列中,同时保持计算效率。作为一种线性时间序列模型,Mamba以更好的效率实现了Transformer的性能,特别是在长序列上。
3.Mamba4Rec
在本节中,我们介绍我们提出的框架Mamba4Rec。我们首先对该框架进行概述,然后探索其技术组件。本文描述了Mamba4Rec如何通过嵌入层、选择性状态空间模型和预测层构建顺序推荐模型。此外,讨论了在顺序推荐中广泛使用的关键组件,如位置嵌入[24]、前馈网络、dropout[21]和层归一化[1]。
3.1 框架概述
如图1所示,提出的Mamba4Rec是一个序列推荐模型,利用了通过Mamba块的选择性状态空间模型。Mamba4Rec的核心元素是Mamba层,它将Mamba块与位置前馈网络相结合。Mamba4Rec在其架构中提供了灵活性:虽然它可以与多个Mamba层堆叠,但是一个单一的Mamba层往往证明足够。每一层由一个Mamba块和一个前馈网络组成,使模型能够从用户的交互历史中有效地捕获特定商品的信息和顺序上下文。
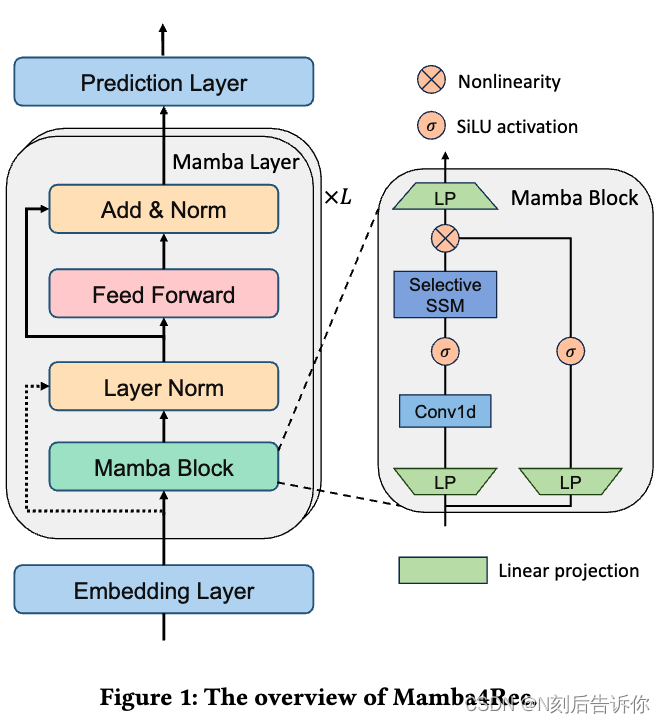
3.2 嵌入层
与现有模型类似,我们的方法利用嵌入层将商品IDs映射到高维空间。这个嵌入层使用一个可学习的嵌入矩阵
E
∈
R
∣
V
∣
×
D
\boldsymbol{E} \in \mathbb{R}^{|\mathcal{V}| \times D}
E∈R∣V∣×D,在这里
D
D
D是嵌入的维度。通过将嵌入层应用到输入商品序列
S
u
\mathcal{S_u}
Su,可以获得商品嵌入
H
H
H。为了增强鲁棒性并防止过拟合,在检索嵌入后,我们合并使用了嵌入层dropout和层归一化:
H
=
L
a
y
e
r
N
o
r
m
(
Dropout
(
H
o
)
)
∈
R
n
u
×
D
H= LayerNorm \left(\operatorname{Dropout}\left(H_o\right)\right) \in \mathbb{R}^{n_u \times D}
H=LayerNorm(Dropout(Ho))∈Rnu×D
在训练和推理阶段,我们将多个样本合并为一个小批量,从而为后续的Mamba块产生输入数据
x
∈
R
B
×
L
×
D
x \in \mathbb{R}^{B \times L \times D}
x∈RB×L×D,这里
B
B
B是批量大小,
L
L
L是序列经过填充后的长度。
位置嵌入
本文研究了位置嵌入对模型性能的影响。这包括评估[11,22]中使用的可学习位置嵌入。这些嵌入通常在层规范化之前注入到输入项嵌入中。然而,与依赖位置嵌入来捕获序列顺序的基于transformer的模型不同,状态空间模型通过其循环性质内在地处理序列信息。虽然理论上没有必要,但在实验中分析了位置嵌入对模型行为的影响。
3.3 Mamba层
尽管Mamba块[3]具有作为序列到序列模型的潜力,我们在序列推荐任务中利用其优势。本文提出Mamba层,包括Mamba块和位置前馈网络。我们使用Mamba层作为架构的基本构建块,而不是简单地堆叠Mamba块。
Mamba Block
如算法1所述,Mamba块在每个时间步 t t t上对输入 x ∈ R B × L × D x \in \mathbb{R}^{B \times L \times D} x∈RB×L×D进行操作。① 它首先以扩展隐藏维度 D D D,对输入 x t x_t xt进行线性投影,以获得 x x x和 z z z。② 然后通过一维卷积和一个SiLU[2]激活函数处理这些投影。③ Mamba块的核心是一个带有离散化参数的选择性状态空间模型,其中参数由输入确定。这个离散化的SSM和 x ′ x' x′一起生成状态表示 y y y。④ 最后, y y y和应用SiLU后的 z z z进行残差连接,最终经过一个线性投影,在时间步 t t t得到最终输出 y t y_t yt。总的来说,Mamba块利用依赖输入的适应和选择性SSM来有效处理序列信息。Mamba块的参数由SSM状态扩展因子 N N N、用于卷积的内核大小 K K K和用于输入和输出线性投影的块扩展因子 E E E组成。选择扩展因子 N N N和 E E E涉及(捕获复杂关系)和训练效率(更高的 N N N, E E E增加计算成本)之间的权衡。
Mamba块解决了RNNs和Transformers中普遍存在的有效性-效率困境。Mamba块中的递归SSM相对于序列长度在线性时间内运行,使其与RNNs一样有效,通过离散参数实现推理。此外,选择机制使得SSM的参数具有数据依赖性。这使Mamba能够有选择地记住或忘记信息,这对于捕获序列数据中的复杂依赖关系至关重要。结构化状态矩阵通过HiPPO解决了长程依赖关系,在对长序列建模方面优于自注意力块。

位置前馈网络
利用位置前馈网络(PFFN)来改进隐藏维度中用户行为的建模:
PFFN
(
H
)
=
GELU
(
H
W
(
1
)
+
b
(
1
)
)
W
(
2
)
+
b
(
2
)
\operatorname{PFFN}(H)=\operatorname{GELU}\left(H \boldsymbol{W}^{(1)}+\boldsymbol{b}^{(1)}\right) \boldsymbol{W}^{(2)}+\boldsymbol{b}^{(2)}
PFFN(H)=GELU(HW(1)+b(1))W(2)+b(2)
其中
W
(
1
)
∈
R
D
×
4
D
,
W
(
2
)
∈
R
4
D
×
D
,
b
(
1
)
∈
R
4
D
\boldsymbol{W}^{(1)} \in \mathbb{R}^{D \times 4 D}, \boldsymbol{W}^{(2)} \in \mathbb{R}^{4 D \times D}, \boldsymbol{b}^{(1)} \in \mathbb{R}^{4 D}
W(1)∈RD×4D,W(2)∈R4D×D,b(1)∈R4D 和
b
(
2
)
∈
R
D
\boldsymbol{b}^{(2)} \in \mathbb{R}^D
b(2)∈RD是两个全连接层的参数,我们使用GELU[9]激活函数。PFFN的目标是通过使用激活函数的全连接层进行两个非线性转换,以捕捉序列数据中的复杂模式和交互。此外,为了增强模型的鲁棒性并防止过拟合,在每个Mamba块和Mamba层内的前馈网络之后,采用类似于方程3的dropout和层归一化。这有助于模型的正则化和加速训练收敛。
GELU激活函数的是为了解决RELU函数在0点不可导(不光滑)而引入的,具体的, G E L U ( x ) = x ϕ ( x ) + 0 ( 1 − ϕ ( x ) ) = x ϕ ( x ) GELU(x)=x \phi(x)+0(1-\phi(x))=x \phi(x) GELU(x)=xϕ(x)+0(1−ϕ(x))=xϕ(x)其中 ϕ ( x ) \phi(x) ϕ(x)是标准高斯分布的累积分布函数。
堆叠mamba层
本文还探索了在顺序推荐中使用堆叠的Mamba层。虽然具有多层的更深网络本身不利于性能,但残差连接[8]在促进整个多层架构中低层特征向高层传播方面发挥着至关重要的作用。认识到堆叠的mamba层的潜在好处,特别是在长序列上,本文探索了两种mamba层的配置,以平衡有效性和效率:
- 单层:当只使用一个Mamba层时,我们应用层归一化而没有残差连接。单个mamba层与堆叠mamba层的有效性相当,同时在任务中实现了更高的效率。
- 堆叠层:对于堆叠的Mamba层,残差连接变得至关重要,并使最后访问项的嵌入能传播到最后一层。
为了探索效果和效率之间的权衡,在实验中进一步研究了堆叠层的潜力。
3.4 预测层
在预测层,我们采用了SASRec的方法,使用最后一项的嵌入来生成最终输出的预测分数:
y
^
=
Softmax
(
L
i
n
e
a
r
(
h
)
)
∈
R
∣
V
∣
\hat{y}=\operatorname{Softmax}(Linear(h)) \in \mathbb{R}^{|\mathcal{V}|}
y^=Softmax(Linear(h))∈R∣V∣
其中
h
∈
R
D
h\in \mathbb{R}^{D}
h∈RD是Mamba层的最后一个商品的嵌入。
y
^
∈
R
∣
V
∣
\hat{y} \in \mathbb{R}^{|\mathcal{V}|}
y^∈R∣V∣代表下一个商品在商品集
V
\mathcal{V}
V上的概率分布。
4.实验
4.1 实验设置
数据集:我们使用三个真实的数据集进行实验和评估我们的模型:
- MovieLens-1M:一个基准数据集包含来自用户的约100万条电影评分。
- Amazon-Beauty and Amazon-Video-Games:两个数据集包含亚马逊上“美丽”和“视频游戏”类别的产品评论和评级。
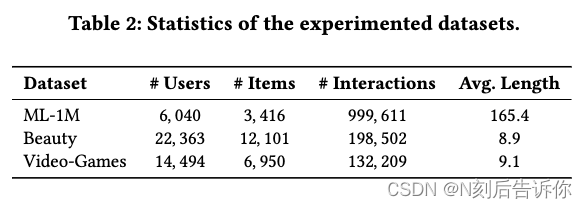
对于每个用户,基于时间戳对其交互记录进行排序,构建交互序列。按照之前工作[11]中的设置,过滤记录交互次数少于5次的用户和项目。每个数据集预处理后的详细统计数据汇总在表2中。
基线:将Mamba4Rec与几个基线方法进行了比较,其中包括基于RNN的模型,如GRU4Rec[10]和NARM[14],以及基于Transformer的模型,如SASRec[11]和BERT4Rec。
评价指标:我们采用命中率(HR)、归一化折损累积增益(NDCG)和截断在10处的平均倒数排名(MRR)作为评价指标,即HR@10、NDCG@10和MRR@10。
实现细节:在我们模型的默认架构中,使用了单个Mamba层,没有位置嵌入。Adam优化器[12]的学习率为0.001。训练批次大小为2048,评估批次大小为4096。所有模型都使用64的嵌入维度。为了解决Amazon数据集的稀疏性问题,我们使用了0.4的辍学率,而MovieLens-1M的辍学率为0.2。最大序列长度与每个用户的平均操作数成比例设置:MovieLens1M为200,Amazon数据集为50。我们遵循RecBole[27]的进一步实现细节。对于Mamba块的参数,SSM状态扩展因子为32,一维卷积的核大小为4,线性投影的块扩展因子为2。
4.2 整体表现
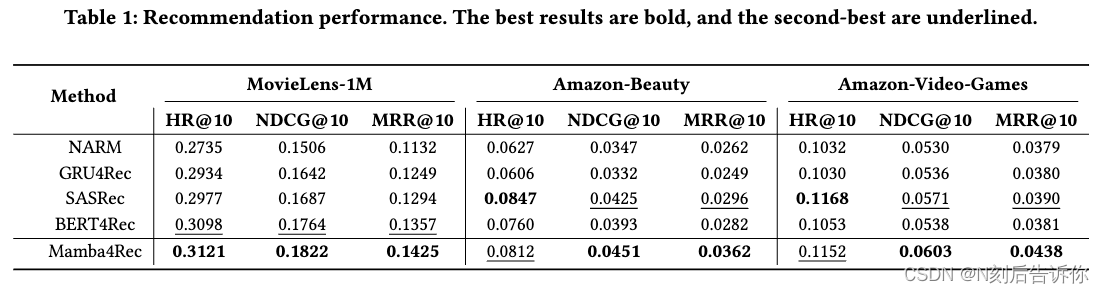
表1展示了总体推荐性能。在序列推荐方法中,基于Transformer的模型SASRec和BERT4Rec通常优于基于RNN的基线。值得注意的是,与基于RNN和Transformer的基线相比,基于状态空间的Mamba4Rec在稀疏和密集数据集以及不同的最大序列长度上取得了优越的性能。与SASRec相比,Mamba4Rec在MovieLens-1M数据集上取得了明显更好的性能,具有更长的序列长度。这突出了状态空间模型作为Transformer和RNN架构在顺序推荐方面令人信服的替代方案的潜力。
4.3 模型效率
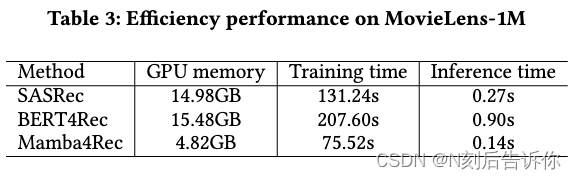
表3详细介绍了基于Transformer的模型和Mamba4Rec的效率性能,所有这些都是在单个Nvidia A5000 GPU上测量的。考虑到效率和效果之间的权衡,在长序列MovieLens-1M数据集上,使用具有单个Mamba层的模型,而不是只有一个Mamba块或堆叠的Mamba层的模型。Mamba4Rec在GPU内存使用、每个epoch的训练时间和每个批次的推理时间方面表现出卓越的性能。此外,与SASRec (epoch 70)和BERT4Rec (epoch 180)相比,该算法具有更快的收敛速度,在epoch 50左右达到了最佳验证性能。这些结果表明,与基于transformer的模型相比,Mamba4Rec实现了卓越的效率,并减少了GPU内存成本,特别是在长序列数据集上。
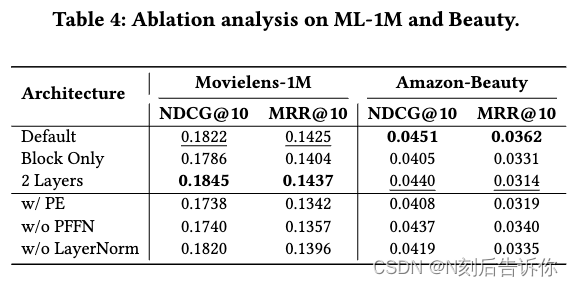
4.4 消融实验
为了解架构中每个组件的贡献,进行了消融研究。表4给出了结果。我们介绍每个变体并分析其各自的影响:
- 位置嵌入:结果表明,由于Mamba块的循环性质,
添加可学习的位置嵌入并没有提高性能。 - 层归一化:在每个Mamba块和前馈网络之后,我们采用dropout和层归一化。
实验结果证明了它们在缓解过拟合和提高性能方面的有效性。 - 前馈神经网络:结果表明,
PFFN层对于较长的序列数据集MovieLens-1M特别有益。这表明PFFN对非线性建模的能力可以提高性能。 - 单个Mamba块:用Mamba块替换Mamba层(并删除PFFN、dropout和层归一化)可以加快计算速度,但牺牲了整体性能。
- mamba层的数量:使用残差连接将两个Mamba层堆叠起来可以提高性能,特别是在更大的长序列MovieLens-1M数据集上。这显示了该模型以降低计算效率为代价处理复杂用户行为的能力。
5.结论和未来工作
本文解决了基于Transformer的序列推荐模型的局限性。本文介绍了基于选择性结构化状态空间模型的Mamba4Rec。实验表明,Mamba4Rec在具有不同稀疏度和序列长度的数据集上取得了强大的性能。此外,它在计算效率和内存成本方面都有显著的改进,使其对顺序推荐任务有效且高效。未来,我们的目标是设计适合于推荐系统的状态空间模型,并在该领域推广基于SSM的模型。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









