









文章目录
- peft-sam: Parameter Efficient Fine-Tuning of Segment Anything Models - 在生物医学成像领域为SAM实现了几种参数高效微调(PEFT)方法
- Lightning Segment-Anything Model(2023) - 仅代码,需要看代码确定其微调的具体是如何实现的
- SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation, and More(2023) - 通过Adapter实现微调,不需要标注prompt
- Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation(2023)- 通过adapter实现医学数据微调,需要prompt标注
- finetune-anything(2023)- 支持较高程度的定制化,可以自定义不同位置是否使用adapter
- Customized Segment Anything Model for Medical Image Segmentation(2023)- 通过lora实现医学数据的微调,且是无提示的自动语义分割,不需要标注prompt,但也丢失了SAM的交互能力
- [NIPS2023] HQ-SAM:Segment Anything in High Quality - 增加额外的token调整生成的mask
- [ICME2024]PA-SAM: Prompt Adapter SAM for High-quality Image Segmentation - 通过Adapter微调
SAM分割一切(论文解析)提出了新的任务、模型、数据集,实现了很好的通用分割能力,但对一些细分领域的数据适配仍然不是很好,因此需要进行微调,本篇重点整理一下与SAM微调相关的工作。
- 由于SAM是通用分割模型,在微调时通常要保留其强大的通用能力不被破坏,所以几乎所有论文微调方式与目前的大模型高效微调方式思路一致,主要采用lora、adapter等技术
- 部分博客通过仅微调mask decoder实现领域数据适配
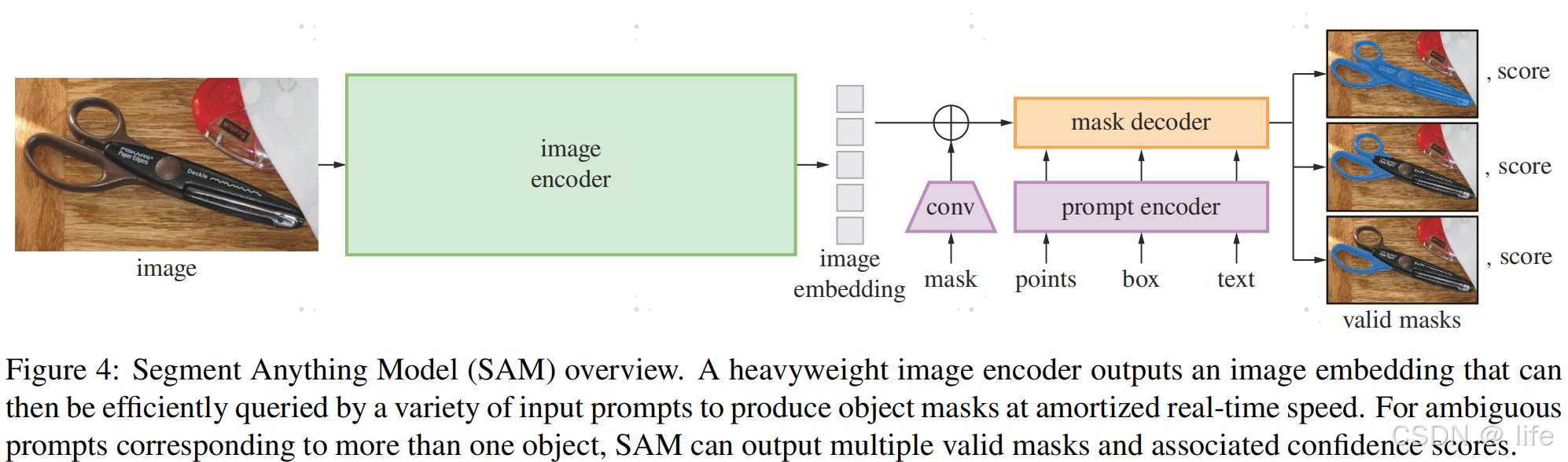
SAM主要由image encoder、prompt encoder、mask decoder三部分组成,因此在微调的时候也主要是围绕这3部分进行相关工作。
peft-sam: Parameter Efficient Fine-Tuning of Segment Anything Models - 在生物医学成像领域为SAM实现了几种参数高效微调(PEFT)方法
paper:https://arxiv.org/abs/2502.00418
code:https://github.com/computational-cell-analytics/peft-sam
Lightning Segment-Anything Model(2023) - 仅代码,需要看代码确定其微调的具体是如何实现的
code:https://github.com/luca-medeiros/lightning-sam
- 只支持标注框promt
该库允许你针对自定义的COCO格式数据集,对MetaAI强大的Segment-Anything模型进行微调。该库基于Lightning AI的Fabric框架构建,为实现最先进的实例分割结果提供了高效且易于使用的实现方式。
这个代码库是一次实验;是一个概念验证,旨在探究使用边界框作为提示来微调SAM,是否能总体上提高交并比(IoU)或改善掩码的质量。用户可以使用COCO格式的数据集,针对SAM表现不佳的特定任务(例如,分割文档上的文本)对SAM进行微调,然后像使用SAM一样,结合交互式提示使用该模型。
SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation, and More(2023) - 通过Adapter实现微调,不需要标注prompt
- 但项目中提示显存可能占用很大,需准备好资源……
code:https://github.com/tianrun-chen/SAM-Adapter-PyTorch
SAM在某些分割任务中可能会失败或表现不佳,例如阴影检测和伪装物体检测(隐蔽物体检测)。本研究首次为将大型预训练图像分割模型SAM应用于这些下游任务铺平了道路,即使在SAM表现不佳的情况下也是如此。我们没有对SAM网络进行微调,而是提出了SAM - Adapter,它通过使用简单而有效的适配器,将特定领域信息或视觉提示融入到分割网络中。通过将特定任务知识与大模型学到的通用知识相结合,如大量实验所示,SAM - 适配器可以显著提升SAM在具有挑战性任务中的性能。我们甚至超越了特定任务的网络模型,并在我们测试的任务(伪装物体检测、阴影检测)中取得了最先进的性能。我们还测试了息肉分割(医学图像分割),并取得了更好的结果。我们相信,我们的工作为在下游任务中利用SAM开辟了机会,其在包括医学图像处理、农业、遥感等各个领域都有潜在应用。
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation(2023)- 通过adapter实现医学数据微调,需要prompt标注
paper:https://arxiv.org/pdf/2304.12620
code:https://github.com/SuperMedIntel/Medical-SAM-Adapter,支持SAM/mobileSAM/EfficientSAM
由于缺乏特定的医学领域知识,SAM在医学图像分割任务中表现欠佳。这引发了如何提升SAM对医学图像分割能力的问题。本文提出了医学SAM适配器(Med-SA),通过轻量而高效的适配技术将特定领域的医学知识融入分割模型。在Med-SA中,我们设计了空间深度转置模块(SD-Trans)以将2D SAM适配于3D医学图像,并提出超提示适配器(HyP-Adpt)实现提示条件下的适配。我们在17项跨多种成像模态的医学图像分割任务上进行了全面评估实验,结果表明Med-SA在仅更新2%模型参数的情况下,性能超越了多个最先进的(SOTA)医学图像分割方法。
finetune-anything(2023)- 支持较高程度的定制化,可以自定义不同位置是否使用adapter
code:https://github.com/ziqi-jin/finetune-anything
分割一切模型(SAM)彻底改变了计算机视觉领域。依靠对SAM的微调将解决大量基础计算机视觉任务。我们正在设计一个基于SAM的用于训练微调模型的类别感知单阶段工具。
你需要提供任务所需的数据集以及支持的任务名称,此工具将帮助你获得针对任务的微调模型。你也可以设计自己的扩展SAM模型,FA将为你提供训练、测试和部署流程。
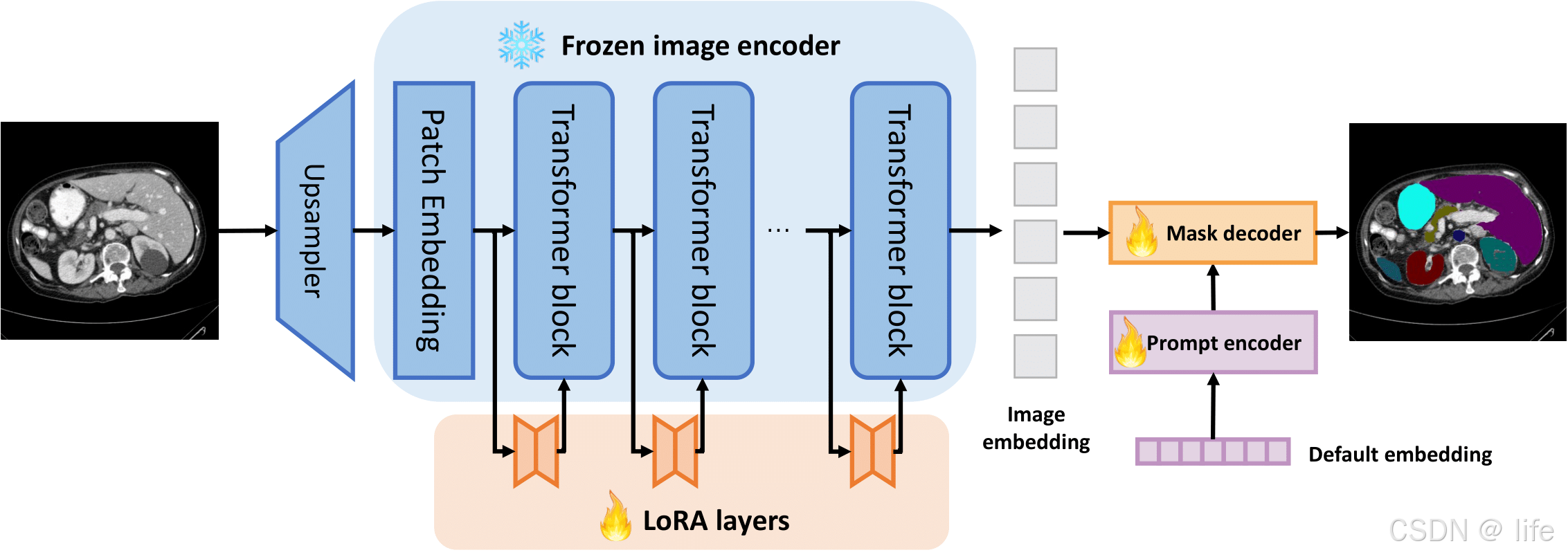
Customized Segment Anything Model for Medical Image Segmentation(2023)- 通过lora实现医学数据的微调,且是无提示的自动语义分割,不需要标注prompt,但也丢失了SAM的交互能力
paper:https://arxiv.org/pdf/2304.13785
code:https://github.com/hitachinsk/SAMed
我们提出了SAMed,这是一种用于医学图像分割的通用解决方案。与以往方法不同,SAMed基于大规模图像分割模型“分割一切模型”(Segment Anything Model,简称SAM)构建,旨在探索为医学图像分割定制大规模模型的新研究范式。SAMed将基于低秩的(LoRA)微调策略应用于SAM图像编码器,并在有标注的医学图像分割数据集上,与提示编码器和掩码解码器一起对其进行微调。我们还观察到,预热微调策略和AdamW优化器使SAMed成功收敛并降低了损失。与SAM不同,SAMed可以对医学图像执行语义分割。我们训练的SAMed模型在Synapse多器官分割数据集上达到了81.88的DSC(Dice相似系数)和20.64的HD(Hausdorff距离),与当前最先进的方法相当。我们进行了大量实验来验证我们设计的有效性。由于SAMed只更新了SAM参数的一小部分,在实际应用中,其部署成本和存储成本相当低。
[NIPS2023] HQ-SAM:Segment Anything in High Quality - 增加额外的token调整生成的mask
苏黎世联邦理工、香港科技大学
paper:https://arxiv.org/abs/2306.01567
code:https://github.com/SysCV/sam-hq
尽管SAM在训练时使用了11亿个掩码,但在许多情况下,其掩码预测质量仍存在不足,尤其是在处理结构复杂的物体时。我们提出了HQ-SAM,在保留SAM原有的可提示设计、效率和零样本泛化能力的同时,赋予其精确分割任意物体的能力。我们的设计精心复用并保留了SAM的预训练模型权重,仅引入了极少的额外参数和计算量。我们设计了一个可学习的高质量输出token,将其注入SAM的掩码解码器中,专门负责预测高质量掩码。不同于仅在掩码解码器特征上应用,我们首先将这些特征与视觉Transformer(ViT)的早期和最终特征进行融合,以改善掩码细节。为了训练我们引入的可学习参数,我们从多个来源构建了包含4.4万个细粒度掩码的数据集。HQ-SAM仅在这个包含4.4万掩码的数据集上进行训练,使用8块GPU仅需4小时。我们在10个不同的下游任务分割数据集上验证了HQ-SAM的有效性,其中8个数据集通过零样本迁移协议进行评估。
[ICME2024]PA-SAM: Prompt Adapter SAM for High-quality Image Segmentation - 通过Adapter微调
paper:https://arxiv.org/abs/2401.13051
code:https://github.com/xzz2/pa-sam
我们将一种新颖的提示驱动适配器引入到SAM中,即提示适配器分割一切模型(PA - SAM),旨在提升原始SAM的分割掩码质量。通过仅对提示适配器进行训练,PA - SAM从图像中提取详细信息,并在稀疏和密集提示层面优化掩码解码器特征,从而提高SAM的分割性能以生成高质量掩码。实验结果表明,我们的PA - SAM在高质量、零样本和开放集分割方面优于其他基于SAM的方法。
参考:
https://zhuanlan.zhihu.com/p/622677489
https://encord.com/blog/learn-how-to-fine-tune-the-segment-anything-model-sam/
https://zhuanlan.zhihu.com/p/627098441


















 1597
1597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











