







华为诺亚方舟 EMNLP 2021 论文解析
DyLex: Incorporating Dynamic Lexicons into BERT for Sequence Labeling
作者:

论文链接:link
文章主要内容
BERT word-piece 和 Char embeddings 的方式会造成单词信息不能被完全利用,这使得难以准确地确定实体边界或正确预测实体类型。
文章提出了一种有效将外部词典知识引入到序列标注任务的框架,支持词汇的动态更新
在 CWS(汉语分词)、NER(命名实体识别)和NLU(自然语言理解)任务上取得了SOTA result。
当前研究的做法
文章中引用了三篇文章,介绍了当前做法和不足
做法:
- 首先匹配具有多个词汇的输入句子以获取所有匹配项。
- 然后修改模型的 layer 来使用匹配到的信息
缺点:
- 词表更新时需要对模型重新训练
- 忽略了词的类型
由此作者采用了下面的做法:
模型图

首先看模型图(a)分为两个部分,基于BERT的序列标签 和 词典知识抽取,词典知识抽取部分又包括 tag 的匹配、去噪和融合
BERT 的序列标签部分 与用BERT做序列标注的方法类似,这里不再介绍。
这里主要对第二块进行分析
词典知识抽取部分
匹配
通常的方法采用词典额外的词向量的方式学习词典知识,一旦词汇表更新,模型就需要重新训练。这篇文章通过设计一个字无关的表示,不依赖词汇表的大小和内容。其通过 prefix Trie树,对BERT 的输入进行快速匹配,直接匹配到其中包含的标签。

这里通过三个公式表示了词向量的计算过程,生成了 去噪部分的输入

去噪
去噪部分是对匹配部分的清洗操作,因为在匹配部分会匹配到很全部的可能性,这里需要根据训练语料对匹配到的不正确的tag 做清洗。
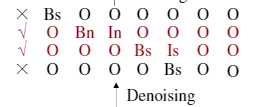
如上图,第一行和第四行属于匹配错误,进行删除
该部分的判断标准可以利用数据集自动生成的标签
作者特别强调,在没有提供词典标签的情况下,该方法也可以工作,该方法将退化为使用词典的边界。
首先通过下面公式从 词向量
E
d
(
i
)
E_{d}^{(i)}
Ed(i) 获取对应的第
i
i
i 个tag 序列

其中
S
e
l
f
A
t
t
SelfAtt
SelfAtt是 self attention 的计算方法
然后通过一个线性层判断改tag 序列是否为噪声序列,如在去噪部分的图中,第三行第四行必不能同时为真。
融合层
融合层通过attention 机制,利用bert 本身产生的向量与 词典知识抽取部分产生的向量做attention操作,得到最终的向量表示。
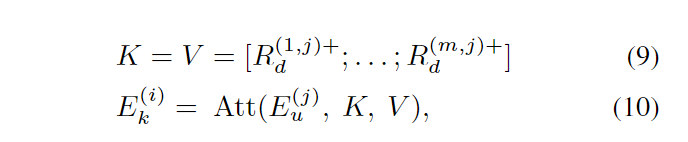
其中
K
V
K V
KV均为词典知识抽取模块得到的向量,Q为bert 生成的向量
将
E
k
(
j
)
E_{k}^{(j)}
Ek(j)拼接 得到词典知识抽取的最终表示。
最后label 预测
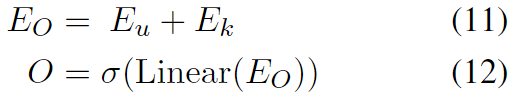
拼接两个向量得到完整的句子表示向量,然后通过linear 层得到标签。
实验结果
实验结果在三个任务上基本都是最优,可以从论文中查看
未来工作考虑在文本分类中应用,文中提到去噪是当前分类任务的研究难点














 1385
1385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









