








2015年Google提出了Batch Normalization算法,Batch Normalization简称BN算法,它是为了克服神经网络层数加深导致难以训练而诞生的一个算法。根据ICS理论,当训练集的样本数据和目标样本数据分布不一致的时候,训练得到的模型无法很好的泛化。而在神经网络中,每一层的输入在经过层内操作之后必然会导致与原来对应的输入信号分布不同,并且前面层神经网络的增加会被后面的神经网络不断的累积放大。这个问题的一个解决思路就是根据训练样本与目标样本的比例对训练样本进行一个矫正,而BN算法则可以用来规范化某些层或者所有层的输入,从而固定每层输入信号的均值与方差。目前,该算法已经被广泛应用。
我们知道线性回归问题,本质上是一个多元一次函数的优化问题,多层神经网络(层数K=2),本质是一个多元K次函数优化问题。在线性回归当中,从任意一个点出发搜索,最终必然是下降到全局最小值附近的,而在多层神经网络中,从不同点出发,可能最终困在局部最小值处。在凸优化问题中,任何一个局部最小值点都是全局最小值点。然而局部最小值给神经网络结构带来的挥之不去的阴影,随着隐藏层层数的增加,非凸的目标函数越来越复杂,局部最小值点成倍增长(其实,对于很多高维非凸函数而言,局部最小值以及局部最大值事实上都远小于另为一类梯度为0的点——鞍点。鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点。在泛函中,既不是极大值点也不是极小值点的临界点,叫做鞍点。在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。在物理上要广泛一些,指在一个方向是极大值,另一个方向是极小值的点。)所以,从本质上来看,深度结构带来的非凸优化仍然不能解决,这限制着深度结构的发展。
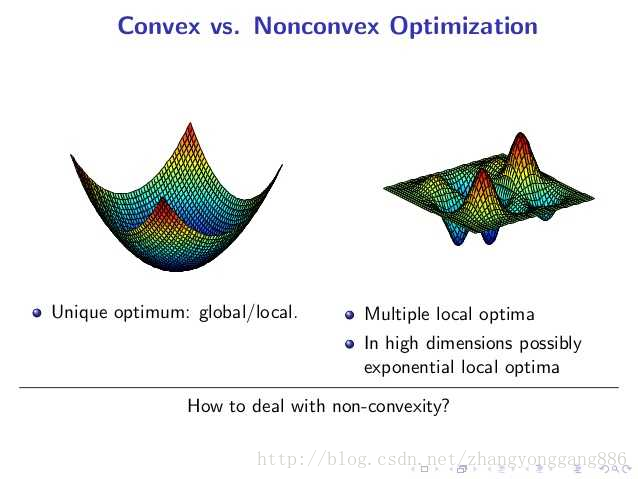
图一 凸函数与非凸函数
大多数机器学习问题都会涉及各种各样的优化问题,优化是指改变x已达到最小化或者最大化某一个函数的任务。梯度下降法(Gradient Descent)是一个最优化算法,通常也称为最速下降法,最速下降法是求解无约束优化问题最简单和最古老的方法之一。梯度下降算法由于每次更新参数,都遍历了一次所有的样本数据,这样做会具有更高的准确性,却在遍历m集合上会花费了大量的时间,当训练集合很大是,这种方法是很浪费时间的,所以引出随机梯度下降(Stochastic Gradient Descent)。随机梯度下降算法是机器学习中应用最多的优化算法。

图二 随机梯度下降算法
尽管随机梯度下降法对于训练深度网络简单高效,但是它有一个问题就是需要人为的去选择参数,比如学习率、参数初始化、权重衰减系数、Dropout比例等。这些参数的选择对训练结果至关重要,以至于我们在训练模型时往往花费很多时间调优参数。
下面我们来说一下BN算法的优点:
a) 减少了人为选择参数。在某些情况下可以取消dropout和L2正则项参数,或者采取更小的L2正则项约束参数;
b) 减少了对学习率的要求。现在我们可以使用初始
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















03-08
 115
115
115
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









