









文章目录
前言
NodeManager因为OOM问题无法正常启动,我们发现是NodeManager在启动时会加载StateStore中的Application而StateStore中Application过多导致。
进一步,我们看到StateStore中Application过多是Log Aggregation Service失效导致。
本文详细记录事故分析和处理过程,并在代码层面分析NodeManager Recover和Log Aggregation的基本原理。
同样,我希望通过本文展示的不仅仅是Yarn的基本原理,更重要的是,是事故分析过程中的方法,风格和手段,以及在根本原因层面解决问题的重要习惯。
现象收集
- NodeManager崩溃并且启动也失败
查看NodeManager奔溃时候的日志,发现NodeManager的崩溃原因是发生了OOM。
2023-12-20 06:17:09,529 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 20693ms
GC pool 'ConcurrentMarkSweep' had collection(s): count=3 time=21174ms
2023-12-20 06:18:02,873 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 52843ms
GC pool 'ConcurrentMarkSweep' had collection(s): count=8 time=53299ms
2023-12-20 06:19:36,574 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 60370ms
GC pool 'ConcurrentMarkSweep' had collection(s): count=10 time=68325ms
2023-12-20 06:20:20,950 INFO org.apache.hadoop.yarn.server.nodemanager.NodeManager: STARTUP_MSG:
好在我们在Cloudera中配置了oom的时候就把内存dump下来,因此可以做事后的分析:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/yarn4_yarn4-NODEMANAGER-8851520f8344cd24bde633d2b7a7de99_pid25528.hprof
查看NodeManager重新启动以后的日志,发现NodeManager在忙于加载大量的历史Application日志。至于为什么需要加载这么多的历史application,以及为什么这些历史application结束了却没有被NodeManager删除,由于发现问题的时候已经重启了很多次,每次都是加载这种大量日志:
05:14:47,679 INFO containermanager.application.Application: Application application_1690345900625_83273 transitioned from NEW to INITING
05:14:47,679 INFO containermanager.ContainerManagerImpl: Recovering application application_1690345900625_83274
05:14:47,679 INFO containermanager.application.Application: Application application_1690345900625_83274 transitioned from NEW to INITING
05:14:47,679 INFO containermanager.ContainerManagerImpl: Recovering application application_1690345900625_83275
同时,我们也看到,NodeManager启动的时候在大量加载Localized Resource:
2024-07-24 05:26:27,005 INFO ResourceLocalizationService: Recovering localized resource { hdfs://nameservice-aa/user/spark/.sparkStaging/application_1701670515768_144417/__spark_conf__.zip, 1709923740877, ARCHIVE, null } at /corp/yarn/nm/usercache/spark/filecache/2215/__spark_conf__.zip
2024-07-24 05:26:27,005 INFO ResourceLocalizationService: Recovering localized resource { hdfs://nameservice-aa/user/spark/.sparkStaging/application_1701670515768_144418/__spark_conf__.zip, 1709923798972, ARCHIVE, null } at /corp/yarn/nm/usercache/spark/filecache/2216/__spark_conf__.zip
同时,有一部分NodeManager似乎躲过了Recover的过程,但是,却又抛出了下面的OOM异常:
2024-07-24 05:28:26,001 FATAL org.apache.hadoop.yarn.YarnUncaughtExceptionHandler: Thread Thread[LogAggregationService #90,5,main] threw an Error. Shutting down now...
java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at org.apache.hadoop.hdfs.LeaseRenewer.put(LeaseRenewer.java:326)
at org.apache.hadoop.hdfs.DFSClient.beginFileLease(DFSClient.java:877)
at org.apache.hadoop.hdfs.DFSClient.primitiveCreate(DFSClient.java:1814)
at org.apache.hadoop.fs.Hdfs.createInternal(Hdfs.java:105)
at org.apache.hadoop.fs.Hdfs.createInternal(Hdfs.java:59)
..............
org.apache.hadoop.yarn.logaggregation.AggregatedLogFormat$LogWriter$1.run(AggregatedLogFormat.java:382)
......
at org.apache.hadoop.yarn.logaggregation.AggregatedLogFormat$LogWriter.<init>(AggregatedLogFormat.java:376)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.AppLogAggregatorImpl.uploadLogsForContainers(AppLogAggregatorImpl.java:248)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.AppLogAggregatorImpl.doAppLogAggregation(AppLogAggregatorImpl.java:465)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.AppLogAggregatorImpl.run(AppLogAggregatorImpl.java:424)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService$2.run(LogAggregationService.java:404)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
从堆栈可以看到,是LogAggregationService在为这些从StateStore中恢复的Application创建对应的AppLogAggregatorImpl,但是AppLogAggregatorImpl在试图上传日志的时候,由于DFSClient需要创建独立的线程,但是内存不足导致无法再创建JVM Native Thread。下文会讲到为Application初始化对应的AppLogAggregatorImpl的过程。
代码层面,我们找到了日志Recovering application 的日志,查看调用堆栈如下:

同时,在NodeManager重启以前的日志中,我们看到了大量的关于LogAggregationService相关的权限异常:
2024-03-18 06:33:37,410 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: Remote Root Log Dir [/user/mapred/logs] already exist, but with incorrect permissions. Expected: [rwxrwxrwt], Found: [rwxr-xr-x]. The cluster may have problems with multiple users.
2024-03-18 06:33:37,410 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.AppLogAggregatorImpl: rollingMonitorInterval is set as -1. The log rolling monitoring interval is disabled. The logs will be aggregated after this application is finished.
2024-03-18 06:33:37,415 ERROR org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: Failed to setup application log directory for application_1701670515768_140108
org.apache.hadoop.security.AccessControlException: Permission denied: user=spark, access=WRITE, inode="/user/mapred/logs":mapred:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkFsPermission(DefaultAuthorizationProvider.java:279)
at .....................
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1001)
1,1 Top
2024-03-18 06:33:37,415 ERROR org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: Failed to setup application log directory for application_1701670515768_140108
org.apache.hadoop.security.AccessControlException: Permission denied: user=spark, access=WRITE, inode="/user/mapred/logs":mapred:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkFsPermission(DefaultAuthorizationProvider.java:279)
at ...........
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:3115)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:3080)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1001)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:997)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:997)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:989)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.createDir(LogAggregationService.java:254)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.access$200(LogAggregationService.java:68)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService$1.run(LogAggregationService.java:307)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.createAppDir(LogAggregationService.java:278)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.initAppAggregator(LogAggregationService.java:384)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.initApp(LogAggregationService.java:337)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.handle(LogAggregationService.java:463)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.handle(LogAggregationService.java:68)
所以,我们的初步怀疑这个权限异常导致了内存不足,但是需要进一步确认。
事故分析
内存分析
由于NodeManager发生了Full GC而无法正常启动,并且幸运的是问题可重现,于是我们对发生问题的NodeManager进行heap dump然后分析。
我们通过jhat命令,在NodeManager服务器上打开heap dump文件,然后打开一个http端口,在本地浏览器中访问分析结果:
jhat -J-Xmx20G -port 7770 /tmp/yarn4_yarn4-NODEMANAGER-8851520f8344cd24bde633d2b7a7de99_pid6184.hprof

下图可以看到每一个class的instance数量,我们选择ApplicationIdPBImpl这个class,点进去,就可以看到这个class(其实是引用Class<ApplicationIdPBImpl>这个对象)的所有instance:

以其中ApplicationIdPBImpl作为起点,不断反向跟踪,最终找到引用该对象的引用链。反向跟踪的方法是,不断找到以当前对象作为field、引用该对象的object。在每一个对象的页面,References to this object就是指向该对象的所有引用:

引用链如下:
Class<ApplicationIdPBImpl> <- ApplicationIdPBImpl <- ApplicationFinishEvent <- java.util.concurrent.LinkedBlockingQueue$Node
从上面的这个引用链可以看到,一定有一个LinkedBlockingQueue<ApplicationFinishEvent>,保存了所有了ApplicationFinishEvent信息,而每一个ApplicationFinishEvent对象封装了一个ApplicationIdPBImpl ,这些Application数量太多,导致了NodeManager启动的时候发生了OOM的异常。
简单查看代码,我们看到,这个LinkedBlockingQueue<ApplicationFinishEvent>是来自于AsyncDispatcher的调度队列,而这些海量的ApplicationFinishEvent对象来自于recover()过程中为每一个Application生成的结束事件:NodeManager启动过程中,recover()会从本地的磁盘缓存(Level DB StateStore)中需要还原大量的Application, Container和Local Resource,试图将NodeManager中的这些元数据信息恢复到关闭以前的状态。但是,太多的Application需要恢复,导致内存占满,启动失败。
我们查看日志,看到这些海量的Application绝大部分都是很久以前的Application,显然,这些Application早应该从NodeManager的StateStore中删除。
所以,目前来看,解决问题的方法很简单,手动清空Level DB State Store然后重启NodeManager。
NOTE: 看到了吗,有时候,没有在原理层面找到根本原因,但是我们却已经找到了解决问题的方法。
问题是, 为什么会有这么多的Application存放在StateStore中?是因为基于某种Retention Policy才保留了这么多,还是因为某种异常才导致的问题?如果是基于某种Retention Policy,显然,这个Retention Policy并不合理因此需要修改,那些很久以前的Application根本不需要保留。如果是基于某种异常,看起来,似乎和Log Aggregation的异常相关?
LogAggregationService写入日志时候的权限控制
为了让对应的用户能够创建对应的日志目录,我们必须保证LogAggregation 根目录权限中允许任何用户进行写操作,否则,会抛出异常,从而用户的application log根本无法成功创建到我们配置的yarn.nodemanager.remote-app-log-dir中去:
2024-03-18 06:33:37,410 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: Remote Root Log Dir [/user/mapred/logs] already exist, but with incorrect permissions. Expected: [rwxrwxrwt], Found: [rwxr-xr-x]. The cluster may have problems with multiple users.
2024-03-18 06:33:37,410 INFO org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.AppLogAggregatorImpl: rollingMonitorInterval is set as -1. The log rolling monitoring interval is disabled. The logs will be aggregated after this application is finished.
2024-03-18 06:33:37,415 ERROR org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: Failed to setup application log directory for application_1701670515768_140108
org.apache.hadoop.security.AccessControlException: Permission denied: user=spark, access=WRITE, inode="/user/mapred/logs":mapred:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkFsPermission(DefaultAuthorizationProvider.java:279)
at .....................
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1001)
1,1 Top
2024-03-18 06:33:37,415 ERROR org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService: Failed to setup application log directory for application_1701670515768_140108
org.apache.hadoop.security.AccessControlException: Permission denied: user=spark, access=WRITE, inode="/user/mapred/logs":mapred:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkFsPermission(DefaultAuthorizationProvider.java:279)
at ...........
at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:3115)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:3080)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1001)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:997)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:997)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:989)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.createDir(LogAggregationService.java:254)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.access$200(LogAggregationService.java:68)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService$1.run(LogAggregationService.java:307)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.createAppDir(LogAggregationService.java:278)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.initAppAggregator(LogAggregationService.java:384)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.initApp(LogAggregationService.java:337)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.handle(LogAggregationService.java:463)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.logaggregation.LogAggregationService.handle(LogAggregationService.java:68)
为什么日志是由运行在NodeManager中的LogAggregationService上传的,即应该是以运行NodeManager的用户yarn去写入的,为什么实际上却是以具体的application owner(我们的例子是spark)写入的呢?
NodeManager读取日志时候的权限需要
LogAggregationService 将日志成功上传到HDFS以后,会设置对应的日志权限为770,这意味着只有Application Owner以及同一个Group的用户对这个Application的日志具有读写权限,如下所示:
root@storage-aa-qe-5:~# hdfs dfs -ls /user/mapred/logs/spark/logs | head -n 20
Found 10664 items
drwxrwx--- - spark supergroup 0 2024-03-11 06:56 /user/mapred/logs/spark/logs/application_1706753275423_57826
drwxrwx--- - spark supergroup 0 2024-03-11 06:57 /user/mapred/logs/spark/logs/application_1706753275423_57827
drwxrwx--- - spark supergroup 0 2024-03-11 06:58 /user/mapred/logs/spark/logs/application_1706753275423_57828
这个权限控制的含义是:只有Application Owner(在我们的例子中为spark),或者这个文件所属的group(这里是supergroup) 中的用户才能够读写这个Application的日志,Application Owner和supergroup以外的用户没有任何权限。
下文会讲到,当我们在Yarn的页面上访问这些日志时,NodeManager会检查日志是否在本地,如果在本地,那么NodeManager直接返回日志,如果Enable 了Log Aggregation并且本地的确没有日志,NodeManager会将请求重定向给Job History Server统一处理。
Job History Server会以yarn这个用户访问HDFS上这个Application的日志目录,如果yarn这个用户没有权限,我们在页面上会看到“Container Logs Not Found”的异常。
所以,当Log Aggregation恢复正常,但是日志访问却失败的时候,我们首先想到的是修改日志权限到777。但是从上面的代码可以看到,我们这样修改只能够让已有的日志可以访问,但是新的Application的日志总是会被强制设置为770,依然无法访问。
所以,结合代码中的逻辑,我们的正确操作应该是将用户yarn加入到supergroup中。
事故处理和时间线梳理
事故处理
-
在我们首先发现NodeManager端在抛出LogAggregation因为权限问题初始化失败以后,我们很容易修改权限,将LogAggregation的日志目录
/user/mapred/logs的权限修改为rwxrwxrwxt,这里的t属于粘滞位,用来将目录的写权限和删除权限分开,即,不同的用户都可以往这个目录上创建文件并写文件,但是没有权限写别人的文件或者删除别人的文件:export HADOOP_USER_NAME=hdfs hdfs dfs -chmod /user/mapred/logs rwxrwxrwxt当我们正确地设置了LogAggregation的日志目录
/user/mapred/logs的权限以后,日志中不再有Failed to setup application log directory for application_1701670515768_140108这种日志,并且,在/user/mapred/logs中开始出现Application的日志,说明LogAggregationService运行正常了。 -
当我们以为问题完全解决的时候,我们发现:
- 在Yarn的页面访问Application中的Container日志失败,抛出
Container Log Not Found的异常; - 当在Yarn中访问Container日志,URL会发生自动重定向到Job History Server,以前是不会发生重定向的。
我们采取的操作是,在HDFS的所有NameNode机器上,将yarn用户添加到supergroup 中(注意不是在ResourceManager上操作,而是在NameNode上进行),我们的HDFS的NameNode进行Authorization的时候,是基于所在机器的Unix User-Group Mapping来进行的,因此在NameNode的机器上(也需要添加到Standby机器上,防止HDFS发生failover的时候此修改失效)将用户
yarn添加到supergroup/usr/sbin/groupadd -r supergroup # 创建supergroup /usr/sbin/adduser yarn supergroup # 将用户yarn加入到supergroup /usr/sbin/adduser mapred supergroup # 将用户mapred加入到supergroup这时候再次在Yarn的ResourceManager页面访问Container日志,访问正常跳转到Job History Server,日志显示正常。
具体原理我们将在下文详细讲解。 - 在Yarn的页面访问Application中的Container日志失败,抛出
-
NodeManager端statestore清理
对于集群中的所有NodeManager,我们需要将它们逐个shutdown,清空我们根据yarn.nodemanager.recovery.dir配置的目录,然后再启动NodeManager。清空了Level DB StateStore,就避免了NodeManager在recover()过程中对Application、Container以及Localized Resource的加载。
可以看到,清理以后,这时候启动NodeManager的速度是非常快的,因为此时不需要加载大量的历史application -
NodeManager 本地相关日志目录的清理
由于LogAggregationService长期失败,此时的NodeManager是将application日志存放在本地磁盘的。我们可以清空并释放这个目录。这个目录是通过yarn.nodemanager.log-dirs来配置的 -
NodeManager Localized Resource 清理
同时,我们也清空了对应的Localized Resource目录。因为我们已经清空了StateStore,因此Localized Resource目录中的数据已经没有用了。但是本地存在的NodeManager Localized Resource并不是导致NodeManager 启动失败的原因。
这样,当用户从webportal中访问对应的日志,Yarn的NodeManager或者JobHistoryServer以yarn的身份读取用户日志的时候,就能够获取对应的组权限。 -
ResourceManager的参数调整
适当调整ResourceManager保留application history的最大数量,尽管这并不是造成本次事故的原因。这个数量是我们能在Yarn ResourceManager的Web Portal上能看到的最大的application的数量。这些application也是被ResourceManager保存在本地的LevelDB中,而不是内存中的。
这是由参数yarn.resourcemanager.max-completed-applications决定的,根据需要设置该参数即可。
事故时间线总结梳理
在查找到了整个事故的原因以后,我们梳理出整个事故发生的前因后果的时间线,而不仅仅是事故发生时的时间线。时间层面,我们只表征事故发生的先后顺序关系,不表征具体时刻。
- 权限问题导致NodeManager的LogAggregationService无法正常上传已经完成的Container的日志到HDFS,因此不会清空内存中的container信息。Statestore中也同步保存了对应的Container的信息,Localized Resource信息等;
- 随着内存中的Application和Container越来越多,NodeManager内存耗尽,发生OOM,崩溃;
- ClouderaManager自动重启NodeManager,NodeManager从StateStore中恢复所有Container的当前状态到内存中,但是由于Application太多,发生OOM而Crash。反复重启;
- 清空StateStore,以及Local Resource,设置
/user/mapred/logs权限,再次重启NodeManager,重启成功,系统运行正常,Application日志成功收集到HDFS; - 虽然日志收集正常,但是我们发现Application的Container Log反而无法正常访问,并且访问Container日志的时候,会Redirect到Job History Server,而之前是直接访问NodeManager获取日志,不会有Redirect;
- 检查代码和日志,确认这个Redirect是Log Aggregation成功以后的正常现象,无法访问时因为Job History Server的用户(yarn)没有对
/user/mapred/logs下面用户日志的访问权限,因此,将用户yarn添加到supergroup中。再次访问Container日志,一切正常。
代码解析
NodeManager Recover的基本过程
已经说过,NodeManger在启动的时候,会调用recover()方法,将Level DB State Store中的相应信息还原到内存。
我们具体查看堆栈中ContainerManagerImpl.recover()方法,发现是NodeManager在从StateStore中加载历史的container信息,然后逐个恢复:
-------------------------------- ContainerManagerImpl --------------------------------------------
@SuppressWarnings("unchecked")
private void recover() throws IOException, URISyntaxException {
NMStateStoreService stateStore = context.getNMStateStore();
if (stateStore.canRecover()) { // 这是一个可以支持recover的StateStore
rsrcLocalizationSrvc.recoverLocalizedResources( // 先Recover Localized Resource
stateStore.loadLocalizationState());
RecoveredApplicationsState appsState = stateStore.loadApplicationsState();
for (ContainerManagerApplicationProto proto :
appsState.getApplications()) {
recoverApplication(proto); // 再从StateStore中Recover Application的信息
}
for (RecoveredContainerState rcs : stateStore.loadContainersState()) {
recoverContainer(rcs); // 从StateStore中Recover对应Container的信息
}
String diagnostic = "Application marked finished during recovery";
for (ApplicationId appId : appsState.getFinishedApplications()) {
dispatcher.getEventHandler().handle(
new ApplicationFinishEvent(appId, diagnostic)); // 标记Application已经结束
}
}
}
NodeManager启动并从LevelDB中加载相关信息的过程为:
-
从Level DB StateStore中加载Localized Resource。这里的意图是,NodeManager也许在以外退出以前,已经维护了一些本地资源,这些本地资源的元数据(这些本地资源在本地的路径是哪里,资源在远程的HDFS的哪个位置)。发生重启以后,需要对这些已经下载的本地资源恢复跟踪:
rsrcLocalizationSrvc.recoverLocalizedResources( // 先Recover Localized Resource stateStore.loadLocalizationState());关于recoverLocalizedResources() 的具体内容,读者可以自行查看代码。我们可以把Localized Resource理解为Yarn的分布式缓存机制。这篇文章【NodeManager中分布式缓存机制】详细讲解了Localized Resource机制。
-
从Level DB StateStore中加载Application的信息,然后恢复Application的信息到内存中:
RecoveredApplicationsState appsState = stateStore.loadApplicationsState(); for (ContainerManagerApplicationProto proto : appsState.getApplications()) { recoverApplication(proto); // 再从StateStore中Recover Application的信息 }我们从recoverApplication()方法中可以看到NodeManager从StateStore中恢复Application的哪些信息。从下面的代码我们可以看到,NodeManager从LevelDB中获取了Application的ID, Credentials, ACL List, Log AggregationContext,并将这些信息组装成为NodeManager端的 ApplicationImpl对象,还原到NMContext中。
同时,生成ApplicationInitEvent事件进行调度:private void recoverApplication(ContainerManagerApplicationProto p) throws IOException { ApplicationId appId = new ApplicationIdPBImpl(p.getId()); // 获取appId Credentials creds = new Credentials(); creds.readTokenStorageStream( new DataInputStream(p.getCredentials().newInput())); // 获取Application中的Credential信息 List<ApplicationACLMapProto> aclProtoList = p.getAclsList(); // 获取Application的ACL Map ...... LogAggregationContext logAggregationContext = null; if (p.getLogAggregationContext() != null) { // 获取Application的LogAggregationContext logAggregationContext = new LogAggregationContextPBImpl(p.getLogAggregationContext()); } LOG.info("Recovering application " + appId); // 将这些信息组装成为NodeManager的ApplicationImpl对象,存入NMContext中 ApplicationImpl app = new ApplicationImpl(dispatcher, p.getUser(), appId, creds, context); context.getApplications().put(appId, app); app.handle(new ApplicationInitEvent(appId, acls, logAggregationContext)); } -
从Level DB StateStore中加载Container的信息。注意,这里可以看出来,Level DB中存放的Application信息和Container信息是独立的,对Application信息的恢复和对Container信息的恢复也是分别进行的:
for (RecoveredContainerState rcs : stateStore.loadContainersState()) { recoverContainer(rcs); // 从StateStore中Recover对应Container的信息 }从recoverContainer()可以看到从StateStore中还原了Container哪些信息:
private void recoverContainer(RecoveredContainerState rcs) throws IOException { StartContainerRequest req = rcs.getStartRequest(); ContainerLaunchContext launchContext = req.getContainerLaunchContext(); ContainerTokenIdentifier token = BuilderUtils.newContainerTokenIdentifier(req.getContainerToken()); ContainerId containerId = token.getContainerID(); ApplicationId appId = containerId.getApplicationAttemptId().getApplicationId(); LOG.info("Recovering " + containerId + " in state " + rcs.getStatus() + " with exit code " + rcs.getExitCode()); if (context.getApplications().containsKey(appId)) { Credentials credentials = parseCredentials(launchContext); // 使用StateStore中存放的Container的LaunchContext, credentiaons,token,status,exit code信息,组装成Container对象 Container container = new ContainerImpl(getConfig(), dispatcher, req.getContainerLaunchContext(), credentials, metrics, token, rcs.getStatus(), rcs.getExitCode(), rcs.getDiagnostics(), rcs.getKilled(), context); context.getContainers().put(containerId, container); dispatcher.getEventHandler().handle( new ApplicationContainerInitEvent(container)); // 生成ApplicationContainerInitEvent事件 } else { // Container对应的Application不存在,因此添加到Completed Container中,准备告诉ResourceManager nodeStatusUpdater.addCompletedContainer(containerId); } }从recoverContainer()方法中可以看到
- 如果Container对应的Application已经在NMContext中存在,那么就从Level DB还原出了Container的Token,ContainerID,Credential,Launch Context,Status, Exit Code等信息,组装成NodeManager端的Container对象,存入 NMContext(内存)中。同时,调度ApplicationContainerInitEvent事件;
- 如果Container对应的Application已经在NMContext中不存在,那么就将Container添加到已经完成的Container列表中(这有可能是因为Application已经完全运行结束并成功进行Log Aggregation,因此在NodeManager异常关闭以前已经将Application从Level DB StateStore中删除,但是由于对应Container从StateStore中删除是有延迟的,因此Container从StateStore中删除以前NodeManager异常退出了,因此在recoverContainer()的时候找不到Application,这时候认为这个Container是已经完成的Container,随后会报告给ResourceManager。
-
对于已经完成的Application,生成对应的ApplicationFinishEvent,交给AsynDispatcher进行事件调度:
String diagnostic = "Application marked finished during recovery"; for (ApplicationId appId : appsState.getFinishedApplications()) { dispatcher.getEventHandler().handle( new ApplicationFinishEvent(appId, diagnostic)); // 标记Application已经结束 }我们后来对内存进行分析,发现占满内存的对象就是ApplicationFinishEvent。
所以,到这里,我们至少知道了为什么NodeManager在重启的时候为什么会抛出OOM的异常了。
解决NodeManager启动时OOM的关键在于删除StateStore;
上面讲过,NodeManager启动的时候,会启动ContainerManagerImpl,从StateStore中读出application的元数据信息,如果application是已经FINISH的application(后面会讲,finish对application只是代表执行完毕,并不代表log aggregation成功)进而为每一个Application生成一个ApplicationFinishEvent,然后委托AsyncDispatcher去调度这个Event。
关于AsyncDispatcher,我在另外一篇文章《Hadoop的心脏:中央异步调度器AsyncDispatcher代码和设计解析》中有详细的解析。
----------------------------------------------ContainerManagerImpl-------------------------------------------------
@SuppressWarnings("unchecked")
private void recover() throws IOException, URISyntaxException {
NMStateStoreService stateStore = context.getNMStateStore();
......
String diagnostic = "Application marked finished during recovery";
for (ApplicationId appId : appsState.getFinishedApplications()) {
dispatcher.getEventHandler().handle(
new ApplicationFinishEvent(appId, diagnostic)); // 从statestore中加载的每一个application,都会构造一个ApplicationFinishEvent,交给AsyncDispatcher对象
}
}
dispatcher.getEventHandler().handle()其实并不是同步处理事件,而是将ApplicationFinishEvent放到内部维护的一个LinkedBlockingQueue中。这个LinkedBlockingQueue就是我们在heap dump分析中看到的那个Queue:
----------------------------------------------------AsyncDispatcher----------------------------------------------
class GenericEventHandler implements EventHandler<Event> {
public void handle(Event event) {
.......
try {
eventQueue.put(event); // 先将Event放到eventQueue中,然后会有独立的Daemon线程去线程中异步取出event,异步处理
NodeManager层面的Application History管理
NodeManager端Application的状态管理
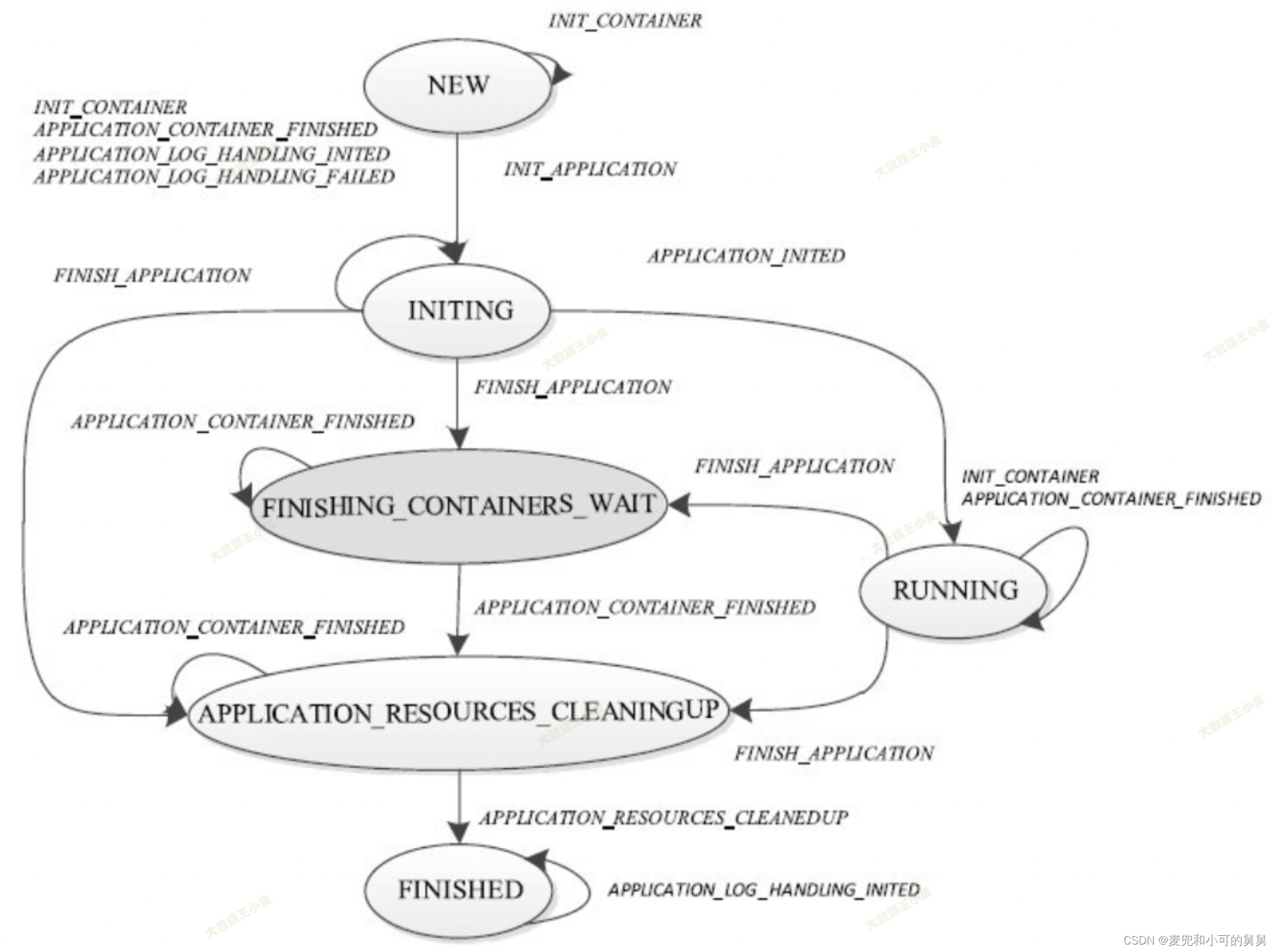
NodeManager层面的状态机定义在ApplicationImpl中,其基本的状态转换逻辑如下图所示:
LogAggregationService的启动过程
NodeManager使用一个独立线程AppLogAggregatorImpl(AppLogAggregatorImpl是一个Runnable)来负责这个NodeManager上这个Application的所有Container的Aggregation。在以下两种情况下,NodeManager端的LogAggregationService会为这个Application启动一个AppLogAggregator:
-
NodeManager在启动一个Container的时候,发现这是Application在这个NodeManager上的第一个Container(但是不一定是这个Application的全局第一个Container),因此会生成ApplicationInitEvent事件并交给AsyncDispatch调度:
------------------------------------- ContainerManagerImpl -------------------------------- private void startContainerInternal(NMTokenIdentifier nmTokenIdentifier, ContainerTokenIdentifier containerTokenIdentifier, StartContainerRequest request) throws YarnException, IOException { .... Application application = new ApplicationImpl(dispatcher, user, applicationID, credentials, context); if (null == context.getApplications().putIfAbsent(applicationID, application)) { // 这是NodeManager上第一次出现这个Application ..... // 生成ApplicationInitEvent,交给ContainerManagerImpl自己的AsyncDispatcher处理,这个AsyncDispatch在收到ApplicationInitEvent事件以后,会交给ApplicationImpl的状态机 dispatcher.getEventHandler().handle( new ApplicationInitEvent(applicationID, appAcls, logAggregationContext)); } // Container存入到Level DB this.context.getNMStateStore().storeContainer(containerId, request); ....... }这里的AsyncDispatcher是ContainerManagerImpl自己私有的AsyncDispatcher。
那么,AsyncDispatcher会将ApplicationInitEvent这个事件交给谁去处理呢?这取决于构造这个AsyncDispatcher的时候谁注册成为了这个Event的Handler,代码如下所示。AsyncDispatcher的注册意味着将某种类型的Event(第一个参数)的处理权交给某一个EventHandler的实现(第二个参数)来处理:----------------------------------- ContainerManagerImpl --------------------------------- public ContainerManagerImpl(.......){ ....... LogHandler logHandler = createLogHandler(conf, this.context, this.deletionService); dispatcher.register(ApplicationEventType.class, new ApplicationEventDispatcher()); dispatcher.register(LogHandlerEventType.class, logHandler); }上面的注册代码意味着:
- 将ApplicationEventType这种类型的Event交给ApplicationEventDispatcher这个EventHandler来处理
- 将LogHandlerEventType这种类型的Event交给LogHandler这个EventHandler来处理。其实LogHandler是一个接口,这里createLogHandler()返回的是LogHandler的实现类,即我们熟悉的LogAggregationService,即LogAggregationService是一个LogHandler实现类。
关于AsyncDispatcher的具体原理,请参考我的另一篇文章《Hadoop的心脏:AsyncDispatcher详解》
我们从
ApplicationEventDispatcher.handle()方法可以看到,它是委托ApplicationImpl来处理这个Event:class ApplicationEventDispatcher implements EventHandler<ApplicationEvent> { @Override public void handle(ApplicationEvent event) { Application app = ContainerManagerImpl.this.context.getApplications().get( event.getApplicationID()); app.handle(event); // 交给ApplicationImpl来处理这个事件,ApplicationImpl将会使用StateMachine来处理对应事件 } }ApplicationImpl是基于自身定义的状态机(StateMachine)来处理各种不同的Event,即定义了
ApplicationEventType.INIT_APPLICATION发生的时候的状态转换规则,这个规则是,将ApplicationImpl的状态从ApplicationState.NEW切换到ApplicationState.INITING,同时,运行AppInitTransition这个转换器:----------------------------- AppInitTransition --------------------------------- // Transitions from NEW state .addTransition(ApplicationState.NEW, ApplicationState.INITING, ApplicationEventType.INIT_APPLICATION, new AppInitTransition())AppInitTransition主要是生成
LogHandlerAppStartedEvent,然后交付给AsyncDispatcher处理:----------------------------- AppInitTransition --------------------------------- static class AppInitTransition implements SingleArcTransition<ApplicationImpl, ApplicationEvent> { @Override public void transition(ApplicationImpl app, ApplicationEvent event) { ApplicationInitEvent initEvent = (ApplicationInitEvent)event; app.applicationACLs = initEvent.getApplicationACLs(); app.aclsManager.addApplication(app.getAppId(), app.applicationACLs); // Inform the logAggregator app.logAggregationContext = initEvent.getLogAggregationContext(); app.dispatcher.getEventHandler().handle( // 生成LogHandlerAppStartedEvent,交给AsyncDispatch处理 new LogHandlerAppStartedEvent(app.appId, app.user, app.credentials, ContainerLogsRetentionPolicy.ALL_CONTAINERS, app.applicationACLs, app.logAggregationContext)); } }从上面AsyncDispatcher的注册机制可以看到,
LogHandlerAppStartedEvent将会交付给LogHandler的实现类LogAggregationService这个EventHandler来处理。LogAggregationService对事件的处理全部直接定义在了一个简单的Switch-Case 语句中,而没有像ApplicationImpl基于状态机去处理。LogAggregationService调用LogAggregationService.initApp()来初始化这个Application的AppLogAggregator:------------------------------------ LogAggregationService --------------------------- public void handle(LogHandlerEvent event) { switch (event.getType()) { case APPLICATION_STARTED: LogHandlerAppStartedEvent appStartEvent = (LogHandlerAppStartedEvent) event; // 调用LogAggregationService.initApp(),就是创建对应的AppAggregator线程,负责这个Applicaiton在这个NodeManager上的Log Aggreagation initApp(appStartEvent.getApplicationId(), appStartEvent.getUser(), appStartEvent.getCredentials(), appStartEvent.getLogRetentionPolicy(), appStartEvent.getApplicationAcls(), appStartEvent.getLogAggregationContext());LogAggregationService.initApp()实际上会为一个Application启动一个独立的AppLogAggregatorImpl线程:protected void initAppAggregator(final ApplicationId appId, String user, Credentials credentials, ContainerLogsRetentionPolicy logRetentionPolicy, Map<ApplicationAccessType, String> appAcls, LogAggregationContext logAggregationContext) { ..... // New application final AppLogAggregator appLogAggregator = new AppLogAggregatorImpl(this.dispatcher, this.deletionService, getConfig(), appId, userUgi, this.nodeId, dirsHandler, getRemoteNodeLogFileForApp(appId, user), logRetentionPolicy, appAcls, logAggregationContext, this.context, getLocalFileContext(getConfig())); .... createAppDir(user, appId, userUgi); // 在HDFS上创建Applicatiion的日志根目录 // TODO Get the user configuration for the list of containers that need log // aggregation. // Schedule the aggregator. Runnable aggregatorWrapper = new Runnable() { public void run() { try { appLogAggregator.run(); // 为这个Application启动一个独立的AppLogAggregator,每一个AppLogAggregator是一个Runnable } finally { appLogAggregators.remove(appId); closeFileSystems(userUgi); } } }; this.threadPool.execute(aggregatorWrapper); } -
NodeManager在启动以后的
recover()过程中,会通过recoverApplication()尝试恢复这个Application的信息到内存,恢复到内存以后,会生成ApplicationInitEvent:private void recoverApplication(ContainerManagerApplicationProto p) throws IOException { ...... LOG.info("Recovering application " + appId); ApplicationImpl app = new ApplicationImpl(dispatcher, p.getUser(), appId, creds, context); context.getApplications().put(appId, app); // 生成 并交给 ApplicationImpl.handle()去处理 app.handle(new ApplicationInitEvent(appId, acls, logAggregationContext)); }上文讲过,
ApplicationInitEvent交给ApplicationImpl的状态机进行状态转换,最终会触发这个Application的AppLogAggregatorImpl线程,这个过程同NodeManager启动Application的第一个Container所触发的流程是一模一样的。
上面描述的状态转换,如下图所示:

从上面的状态转换图可以看到,当application执行结束(发生事件·APPLICATION_CONTAINER_FINISHED·),NodeManager会进入APPLICATION_RESOURCE_CLEANINGUP状态并进行日志的上传和本地日志的清理,当清理完成,就会发生事件APPLICATION_RESOURCES_CLEANEDUP时间并进入最终的FINISHED状态。
我们从代码也可以看到,当NodeManager对于container的 LogAggregation 成功以后,会清空本地存放的日志,本地日志存放的目录是由yarn.nodemanager.log-dirs配置的:
-------------------------------------- AppLogAggregatorImpl ----------------------------------
private void doAppLogAggregationPostCleanUp() {
// Remove the local app-log-dirs
List<Path> localAppLogDirs = new ArrayList<Path>();
for (String rootLogDir : dirsHandler.getLogDirsForCleanup()) {
Path logPath = new Path(rootLogDir, applicationId);
lfs.getFileStatus(logPath);
localAppLogDirs.add(logPath);
}
// 清空本地日志
if (localAppLogDirs.size() > 0) {
this.delService.delete(this.userUgi.getShortUserName(), null,
localAppLogDirs.toArray(new Path[localAppLogDirs.size()]));
}
}
NodeManager对日志请求的处理逻辑
当我们点击MapReduce或者Spark的application的某一个container,会首先访问到这个Container所在的NodeManager, URL的默认端口是8042,URL类似如下:
http://{{ Hostname of NameManager }}:8042/node/containerlogs/container_e16_1701670515768_167140_01_000003/spark/stdout?start=-4096
这个Http Request会首先被拦截器NMWebAppFilter拦截,拦截的原因是判断是判断这个日志请求是应该当前的NodeManager直接返回,还是转交给Job History Server解决:
- 如果日志请求是NodeManager直接返回日志,那么拦截器会放弃拦截,请求会来到NMWebServices进行处理;
- 如果日志请求是应该由Job History Server,那么拦截器直接组装出对应的重定向地址,返回给用户一个重定向,请求不会到达NMWebServices。
在满足重定向条件的情况下,这个URL会被NodeManager重定向到JobHistoryServer,重定向的URL类似:http://{{ DNS of Job History Server}}:19888/jobhistory/logs//{{ Hostname of the Corresponding NodeManager }}:8041/container_1706753275423_68443_01_000003/container_1706753275423_68443_01_000003/spark?start=-4096
拦截器的拦截逻辑在方法NMWebAppFilter.doFilter()中,代码如下所示:
-----------------------------------------------NMWebAppFilter---------------------------------------------------
@Override
public void doFilter(HttpServletRequest request,
HttpServletResponse response, FilterChain chain) throws IOException,
ServletException {
String redirectPath = containerLogPageRedirectPath(request);
if (redirectPath != null) {
String redirectMsg =
"Redirecting to log server" + " : " + redirectPath;
PrintWriter out = response.getWriter();
out.println(redirectMsg);
response.setHeader("Location", redirectPath);
response.setStatus(HttpServletResponse.SC_TEMPORARY_REDIRECT);
return;
}
super.doFilter(request, response, chain);
}
// 设置 重定向url
private String containerLogPageRedirectPath(HttpServletRequest request) {
String uri = HtmlQuoting.quoteHtmlChars(request.getRequestURI());
// 如果本地无法找到app信息,并且enable了LogAggregation,那么就转发给Job History Server
ApplicationId appId =
containerId.getApplicationAttemptId().getApplicationId();
Application app = nmContext.getApplications().get(appId); // 查询本地是否存放了这个applicationid
Configuration nmConf = nmContext.getLocalDirsHandler().getConfig();
if (app == null
&& nmConf.getBoolean(YarnConfiguration.LOG_AGGREGATION_ENABLED,
YarnConfiguration.DEFAULT_LOG_AGGREGATION_ENABLED)) {
String logServerUrl =
nmConf.get(YarnConfiguration.YARN_LOG_SERVER_URL);
if (logServerUrl != null && !logServerUrl.isEmpty()) {
StringBuilder sb = new StringBuilder();
.......
redirectPath =
WebAppUtils.appendQueryParams(request, sb.toString());
}
....
...
return redirectPath;
}
doFilter()方法调用containerLogPageRedirectPath()来判断这个请求是NodeManager亲自处理还是转发给Job History Server。containerLogPageRedirectPath()的基本逻辑是:
-
如果在自己的内存中已经找不到这个application的信息,并且的确enable了Log Aggregation,那么NodeManager会认为这个application已经完成了LogAggregation(所以才从本地删除了信息),因此会返回给客户端一个重定向,让客户端向Job History Server请求日志:
if (app == null && nmConf.getBoolean(YarnConfiguration.LOG_AGGREGATION_ENABLED, YarnConfiguration.DEFAULT_LOG_AGGREGATION_ENABLED)) { String logServerUrl = nmConf.get(YarnConfiguration.YARN_LOG_SERVER_URL); if (logServerUrl != null && !logServerUrl.isEmpty()) { ....... redirectPath = WebAppUtils.appendQueryParams(request, sb.toString()); // 将Job History Server的地址作为重定向的地址 }此时,Yarn直接在Filter层会直接返回一个重定向,重定向地址就是Job History Server的地址:
@Override public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws IOException, ServletException { String redirectPath = containerLogPageRedirectPath(request); if (redirectPath != null) { ..... response.setStatus(HttpServletResponse.SC_TEMPORARY_REDIRECT); // 设置重定向状态码 return; // 直接返回 } super.doFilter(request, response, chain); } -
如果没有满足上述要求,那么
containerLogPageRedirectPath()返回一个空的重定向地址,请求会进一步交付给NodeManager的Service层NMWebServices。Service层代码如下:------------------------------------------------NMWebServices---------------------------------------------------- @Path("/containerlogs/{containerid}/{filename}") @Produces({ MediaType.TEXT_PLAIN }) @Public @Unstable public Response getLogs(@PathParam("containerid") String containerIdStr, @PathParam("filename") String filename) { ........ File logFile = null; try { logFile = ContainerLogsUtils.getContainerLogFile( // 从本地读取container日志 containerId, filename, request.getRemoteUser(), nmContext); }.... try { final FileInputStream fis = ContainerLogsUtils.openLogFileForRead( containerIdStr, logFile, nmContext); StreamingOutput stream = new StreamingOutput() { ......// 将日志发送给客户端可以看到,
ContainerLogsUtils.getContainerLogFile()获取Container和Application的相应信息,其实是从Context context中获取的,这个Context是一个接口,NodeManager维护的这个接口的实现类(NMContext)的一个全局对象,包含了NodeManager端比如Container和Application等等丰富的信息:--------------------------------- ContainerLogsUtils -------------------------------------- public static File getContainerLogFile(ContainerId containerId, String fileName, String remoteUser, Context context) throws YarnException { Container container = context.getContainers().get(containerId); // 从Container Application application = getApplicationForContainer(containerId, context); .....
那么,现在的疑问是,NodeManager端的Context的Application和Context的生命周期比如Retention Policy是怎样的呢?发生在该NodeManager上该Application的所有Container的Log都已经成功的长传到Yarn上。
对应的状态机定义在NodeManager上的ApplicationImpl中,代码如下。其含义是,当前NodeManager端Application的状态为ApplicationState.FINISHED,发生了ApplicationEventType.APPLICATION_LOG_HANDLING_FINISHED事件,此时执行AppLogsAggregatedTransition,然后状态进入到ApplicationState.FINISHED(即状态不变):
------------------------------------- AppLogAggregatorImpl ------------------------------------
// Transitions from FINISHED state
.addTransition(ApplicationState.FINISHED,
ApplicationState.FINISHED,
ApplicationEventType.APPLICATION_LOG_HANDLING_FINISHED,
new AppLogsAggregatedTransition())
状态转换函数AppLogsAggregatedTransition的代码如下,主要是从NodeManager的全局NMContext中删除Application,同时从StateStore中也删除该Application:
----------------------------------- AppLogsAggregatedTransition -------------------------------
static class AppLogsAggregatedTransition implements
SingleArcTransition<ApplicationImpl, ApplicationEvent> {
@Override
public void transition(ApplicationImpl app, ApplicationEvent event) {
ApplicationId appId = event.getApplicationID();
app.context.getApplications().remove(appId); // 从NMContext中删除Application
app.aclsManager.removeApplication(appId);
try {
app.context.getNMStateStore().removeApplication(appId); // 从LevelDB中删除Application
} catch (IOException e) {
LOG.error("Unable to remove application from state store", e);
}
}
}
其中,APPLICATION_LOG_HANDLING_FINISHED事件发生的时机就是这个NodeManager上的Application的所有Container的Log全部成功完成了Aggregation,如下所示:
------------------------------------- AppLogAggregatorImpl ------------------------------------
private void doAppLogAggregation() {
while (!this.appFinishing.get() && !this.aborted.get()) {
.....
// App is finished, upload the container logs.
uploadLogsForContainers(true);
doAppLogAggregationPostCleanUp();
this.dispatcher.getEventHandler().handle(
new ApplicationEvent(this.appId,
ApplicationEventType.APPLICATION_LOG_HANDLING_FINISHED));
this.appAggregationFinished.set(true);
}
所以,可以看到,Application在NMContext(内存)和StateStore(磁盘)中的信息的清除是同时进行的。
NodeManager端的LevelDB中同时也存放了Application对应的Container的状态信息,注意,清除NMContext(内存)和StateStore(磁盘)中的Application信息不代表就会清除Container信息,二者完全独立。
- Container信息从NMContext(内存)中清除发生在Application从NMContext清除以后,NodeManager向ResourceManager进行注册(RegisterNodeManagerRequest)或者心跳(NodeHeartbeatRequest)的时候,这时候会遍历NMContext中所有的Container,将Application已经在NMContext中不存在的Container从NMContext中删除。
- Container从LevelDB中删除则会更滞后,同样在NodeManager向ResourceManager进行注册(RegisterNodeManagerRequest)或者心跳(NodeHeartbeatRequest)的时候,如果发现Container结束的时间已经距离当前时间超过了
yarn.nodemanger.duration-to-track-stopped-containers,那么就将Container从LevelDB中删除。详细过程可以查看方法removeVeryOldStoppedContainersFromCache()
ResourceManager层面的Application History生命周期管理
在ResourceManager层,一样会同时在内存和本地的LevelDB中保存历史Application的状态。对于已经完成的Application,ResourceManager会按照我们配置的最大允许保留的application的数量,清理掉最早的application,这是在方法checkAppNumCompletedLimit()中进行的:
------------------------------------------------------RMAppManager------------------------------------------------
public void handle(RMAppManagerEvent event) {
ApplicationId applicationId = event.getApplicationId();
LOG.debug("RMAppManager processing event for "
+ applicationId + " of type " + event.getType());
switch(event.getType()) {
case APP_COMPLETED:
{
finishApplication(applicationId); // 进行一些收尾工作,比如将application加入到completedApps中,写audit等
logApplicationSummary(applicationId); // 这里仅仅是打印一行关于这个 application的summary日志
checkAppNumCompletedLimit(); // 在这里,RM会清理内存和statestore中的
}
break;
default:
LOG.error("Invalid eventtype " + event.getType() + ". Ignoring!");
}
protected synchronized void checkAppNumCompletedLimit() {
// completedAppsInStateStore在LevelDB中保存了已经执行结束的application
while (completedAppsInStateStore > this.maxCompletedAppsInStateStore) {
ApplicationId removeId =
completedApps.get(completedApps.size() - completedAppsInStateStore);
RMApp removeApp = rmContext.getRMApps().get(removeId);
.....
rmContext.getStateStore().removeApplication(removeApp);
completedAppsInStateStore--;
}
// completedApps是在内存中中保存了已经执行结束的application
while (completedApps.size() > this.maxCompletedAppsInMemory) {
ApplicationId removeId = completedApps.remove();
.......
rmContext.getRMApps().remove(removeId);
this.applicationACLsManager.removeApplication(removeId);
}
}
注意: 这里需要和NodeManager区别开。在NodeManager层是不存在这样一个retention policy的,只要application执行结束,NodeManager就会将这个application从自己的内存NMContext中以及从LevelDB中删除。
内存中最大允许的保留的Application的数量是通过yarn.resourcemanager.max-completed-applications配置的,默认为10000
LevelDB中最大允许的保留的Application的数量是yarn.resourcemanager.state-store.max-completed-applications,默认也是10000
我们的疑问是,对于那些执行结束、但是container的log aggregation失败的application,是否在completedApps中呢?这个问题很重要,因为如果这些application不在completedApps中,就不会被清理,而如果这些application不被清理,再加上已经完成的completedApps中的10000个Application,迟早ResourceManager也会发生OOM。
我们通过测试发现,application的LogAggregation失败了,并不会影响这个application产生RMAppManagerEventType.APP_COMPLETED ,即这个application一样会被加入到RMAppManager.completedApps中,因此受到配置yarn.resourcemanager.max-completed-applications的约束。
测试环境的重现方法:
- 假如我们的
yarn.nodemanager.remote-app-log-dir路径为/tmp/yarn/logs。按照yarn的规则,某一个application的日志路径将会是/tmp/yarn/logs/{{application user name}}/logs/{{application id}}。我们假设当前这个application的user是foobar, 其中,yarn会检查路径/tmp/yarn/logs/{{application user name}}/logs/是否存在,如果不存在,那么就会以foobar这个用户递归创建/tmp/yarn/logs/foobar和/tmp/yarn/logs/foobar/logs。显然,如果/tmp/yarn/logs/对foobar没有写权限,那么log aggregation就会失败 - 我们清空
/tmp/yarn/logs,然后将/tmp/yarn/logs的权限改为700,让foobar这个用户失去写权限,此时所有的application都无法进行log aggregation了 - 打开
org.apache.hadoop.yarn.server.resourcemanager.RMAppManager的DEBUG日志,观察是否会打印如下的日志:RMAppManager processing event for {{ application id }} of type APP_COMPLETED------------------------------------------------RMAppManager-------------------------------------------------- @Override public void handle(RMAppManagerEvent event) { ApplicationId applicationId = event.getApplicationId(); LOG.debug("RMAppManager processing event for " // 这条日志标志着application进入APP_COMPLETED状态 + applicationId + " of type " + event.getType()); switch(event.getType()) { case APP_COMPLETED: { finishApplication(applicationId); // 进行一些收尾工作,比如将application加入到completedApps中,写audit等 logApplicationSummary(applicationId); // 这里仅仅是打印一行关于这个 application的summary日志 checkAppNumCompletedLimit(); // 在这里,RM会清理内存和statestore中的信息 } - 观察结果显示,即使log aggregation失败,上面的日志的确依然会打印
日志目录的权限管理
下文会讲到,NodeManager上的LogAggregationService会为一个新的Application在yarn.nodemanager.remote-app-log-dir下面初始化创建这个Application的目录,我们从下面的代码可以看到,创建这个目录的时候,NodeManager是impersonate(伪装)成当前application的owner的身份,而不是直接以NodeManager自己的yarn用户:
----------------------------------------------AppLogAggregatorImpl----------------------------------------------
// 先写入到临时文件,这里传入了application的对应用户的ugi,即会以userUgi中执行对应的文件的创建
// 在日志中,创建LogWriter会创建一个单独线程,如果Application过多,创建时内存不足,NodeManager也会抛出OOM
try (LogWriter writer = createLogWriter()) {
writer.initialize(this.conf, this.remoteNodeTmpLogFileForApp,
this.userUgi); // 这里传入了ugi
// Write ACLs once when the writer is created.
writer.writeApplicationACLs(appAcls);
writer.writeApplicationOwner(this.userUgi.getShortUserName());
.......
// 当日志上传完毕,同样会以用户的身份将临时文件挪动到最终目录
userUgi.doAs(new PrivilegedExceptionAction<Object>() {
@Override
public Object run() throws Exception {
FileSystem remoteFS = remoteNodeLogFileForApp.getFileSystem(conf);
if (remoteFS.exists(remoteNodeTmpLogFileForApp)) {
if (rename) {
remoteFS.rename(remoteNodeTmpLogFileForApp, renamedPath);
} else {
remoteFS.delete(remoteNodeTmpLogFileForApp, false);
}
}
return null;
}
});
所以,我们必须设置yarn.nodemanager.remote-app-log-dir目录的权限,让任何普通用户都有权限在这个目录下面创建子目录。这里,我们需要将目录权限设置为rwxrwxrwt。上面讲过,这里的t属于粘滞位,用来将目录的写权限和删除权限分开,即,不同的用户都可以往这个目录上创建文件并写文件,但是没有权限写别人的文件或者删除别人的文件。
除了yarn.nodemanager.remote-app-log-dir所配置的根目录权限要求是777以保证任何用户可以往该目录写入文件,具体的任何一个application的目录{{ Log Aggregation Root Dir }}/{{ User }}/logs/{{ appid }},NodeManager在创建完成以后,会将这个目录的权限设置为770,如下面的代码所示:
---------------------------------------------LogAggregationService---------------------------------------------
/**
* Permissions for the Application directory.
*/
private static final FsPermission APP_DIR_PERMISSIONS = FsPermission
.createImmutable((short) 0770);
protected void createAppDir(final String user, final ApplicationId appId,
UserGroupInformation userUgi) {
userUgi.doAs(new PrivilegedExceptionAction<Object>() { // 以当前用户的ugi创建子目录,并修改权限为770
@Override
public Object run() throws Exception {
// TODO: Reuse FS for user?
FileSystem remoteFS = getFileSystem(getConfig());
// 目录{{ Log Aggregation Root Dir }}/{{ User }}/logs/{{ appid }}
Path appDir = LogAggregationUtils.getRemoteAppLogDir(
LogAggregationService.this.remoteRootLogDir, appId, user,
LogAggregationService.this.remoteRootLogDirSuffix);
appDir = appDir.makeQualified(remoteFS.getUri(),
remoteFS.getWorkingDirectory());
// 检查目录 {{ Log Aggregation Root Dir }}/{{ User }}/logs/{{ appid }}
if (!checkExists(remoteFS, appDir, APP_DIR_PERMISSIONS)) {
Path suffixDir = LogAggregationUtils.getRemoteLogSuffixedDir(
LogAggregationService.this.remoteRootLogDir, user,
LogAggregationService.this.remoteRootLogDirSuffix);
suffixDir = suffixDir.makeQualified(remoteFS.getUri(),
remoteFS.getWorkingDirectory());
// 检查目录 {{ Log Aggregation Root Dir }}/{{ User }}/logs
if (!checkExists(remoteFS, suffixDir, APP_DIR_PERMISSIONS)) {
Path userDir = LogAggregationUtils.getRemoteLogUserDir(
LogAggregationService.this.remoteRootLogDir, user);
userDir = userDir.makeQualified(remoteFS.getUri(),
remoteFS.getWorkingDirectory());
// 检查目录 {{ Log Aggregation Root Dir }}/{{ User }}
if (!checkExists(remoteFS, userDir, APP_DIR_PERMISSIONS)) {
// 创建目录 {{ Log Aggregation Root Dir }}/{{ User }}
createDir(remoteFS, userDir, APP_DIR_PERMISSIONS);
}
// 创建目录 {{ Log Aggregation Root Dir }}/{{ User }}/logs/
createDir(remoteFS, suffixDir, APP_DIR_PERMISSIONS);
}
// 创建目录{{ Log Aggregation Root Dir }}/{{ User }}/logs/{{ appid }}
createDir(remoteFS, appDir, APP_DIR_PERMISSIONS);
}
});
}
/**
* 设置对应的路径权限为770,这样,只有文件的owner以及同组用户可以访问对应文件
*/
private boolean checkExists(FileSystem fs, Path path, FsPermission fsPerm)
throws IOException {
boolean exists = true;
try {
FileStatus appDirStatus = fs.getFileStatus(path);
if (!APP_DIR_PERMISSIONS.equals(appDirStatus.getPermission())) {
fs.setPermission(path, APP_DIR_PERMISSIONS); // 设置权限为770
}
} catch (FileNotFoundException fnfe) {
exists = false;
}
return exists;
}
上面也讲过,这个权限控制的含义是:只有Application Owner(在我们的例子中为spark),或者这个文件所属的group(这里是supergroup) 中的用户才能够读写这个Application的日志,Application Owner和supergroup以外的用户没有任何权限。所以,为了能让Job History Server能够读取Application的日志,需要将用户yarn加入到supergroup中。















 9411
9411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









