







文章目录
前言
我们在对Hive进行升级的时候,需要对依赖hive的重要组件spark的兼容性进行调研。本文记录了我们调研的详细过程,主要包括:
- 在我们升级了hive以后,我们当前版本的Spark 2.x 是否依然能够正常工作
- 我们将hive进行了升级以后,HiveMetastor的client端接口部分是否有修改?如果有修改,Spark是否对这些修改兼容
- Spark如何实现在一个JVM内部对多个不同Hive版本的同时加载和使用的
详述
对Hive的基本调研
一直以来,线上环境都使用Cloudera Manager作为我们的集群管理器。但是我们对比Cloudera Manager可以看到,跟hortonworks的激进相比,Cloudera Manager对于bigdata components的版本更新上趋于保守,我们使用的2.6.3版本的Cloudera Manager, release的是1.1.0版本的hive。注意,这里的1.1.0版本的Hive是在apache-hive-1.1.0的基础上cherry pick了一些高版本的特性的,所以其实功能上会相当于稍高版本的apache-hive,但是2.x的高版本的一些东西在目前的cloudera-hive中依然不存在,比如:
- Cost-Based-Optimization Enhancemant: HIVE-9131
- 1.1.0版本的hive使用的是1.6版本的Spark Engine, 但是2.x版本的Spark却可以使用2.0版本的spark,因此Spark本身的版本提升会使得hive-on-spark的性能提升
- Live Long And Process (LLAP) functionality: HIVE-7926, LLAP
- HPL/SQL for procedural SQL: HIVE-11055
- Other improvements in release notes
对Hive In Spark的兼容性探究的起因
我们在进行版本升级的过程中,首先就是确认兼容性问题。其中,Hive的兼容性问题涉及到两个方面:
-
对hive有依赖关系的组件的兼容性问题
和hive有依赖关系的组件,主要依赖HiveMetastore Server,因此,当我们升级hive的时候,必须搞清楚诸如Spark/Impala/Presto/HUE等等组件与HiveMetastore之间的通信是否正常。但是HUE是个例外,与HiveServer进行通信,这里忽略。
-
hive本身的兼容性问题
hive本身的兼容性主要涉及到三种计算引擎和多种数据格式的混合型兼容问题,主要是一下的组合类型:
Text | Avro | JSON | ORC | RCFile | SequenceFile
---- | —
Hive On MR |
Hive On Spark |
Hive On Tez |
第一种兼容性测试最复杂和不可控,但是第二种类型的兼容性是封闭的,以Hive On Spark为例,Hive依赖的Spark是打包以后单独放到HDFS上的,因此,我们可以单独为这个高版本的Hive安装一个独立的、私有的Spark供其使用,不与其它组件发生交叉,只要这个版本的Spark能够与我们的2.6版本的Yarn兼容就没有问题。
我们把主要的注意力放在了集中测试Spark/Impala/Presto 和 HiveMetastore之间的兼容性测试。
通过一些基本的CRUD的测试,我们发现,我们的Spark 1.6、Impala 2.6.0 以及 Presto 0.179都和高版本的HiveMetastore 兼容,这说明高版本的Hive具有很好的backword compatibility. 由于我们的test case永远无法覆盖所有的case,所以,我们希望从代码层面确认一件事:是的,hive metastore的确是backward compatible的。
升级以后的Spark能否正常工作?
由于Spark作为hive客户端与hive metastore通信的时候,是通过hive metastore的thrift api来进行的,兼容问题主要由Hive Metastore 暴露出来的thrift api决定。所有的metastore客户端都实现了IMetaStoreClient接口,Spark也是用IMetastoreClient这个实现类来与HiveMetastore 之间的通信。
随着Hive 的升级,暴露给用户的接口IMetastoreClient可能会发生三种不同类型的变动:
- 接口被删除 如果Spark没有对这种删除操作有很好的兼容,那spark将无法正常工作
- 接口被修改 如果Spark没有对这种修改操作有对应的修改,那么spark也将无法工作
- 新增接口 新增接口对兼容性没有影响,也就是说spark即使没有这些新增接口,应该也能正常工作;但是,我们可以在代码层面确认spark是否对这些新增接口有
因此,我们对比了高低版本的hive的该接口IMetastoreClient,发现IMetastoreClient定义随着hive版本的提升,只有接口方法的增加,这就从客户端接口层面印证了hive metastore的向后兼容性。
那么,既然我们旧版本的Spark可以兼容高版本的Hive Metastore,但是,Spark有没有逐层往上升级客户端来支持更高版本的HiveMetastore的一些新的接口呢?答案是肯定的, 这种支持的方式就是下一节介绍的Shims
通过Shims来增量支持高版本的Hive 的接口变化
Spark对Hive版本支持的灵活配置
Spark内部集成的hive版本是1.2.1版本, 在spark中,叫做execution version。但是随着hive的升级,spark必须兼容高版本的hive客户端,从而保持与高版本的hive server的正常通信。
显然,想要完全匹配高版本的hive,比如,高版本的hive新增了部分接口,虽然我们在Spark中依然使用低版本的hive metastore client 也可以正常通信,但是,如果我们的确想要支持高版本的hive的新增接口从而使用其新增特性,我们必须停止使用默认Hive Metastore Client版本,而是向Spark提供对应版本的hive lib,同时提供给Spark对应版本的lib;
Spark用户通过配置HIVE_METASTORE_JARS 来决定如何管理hive多版本的jar包的依赖问题:
val HIVE_METASTORE_JARS = SQLConfigBuilder("spark.sql.hive.metastore.jars")
.doc(s"""
| Location of the jars that should be used to instantiate the HiveMetastoreClient.
| This property can be one of three options: "
| 1. "builtin"
| Use Hive ${hiveExecutionVersion}, which is bundled with the Spark assembly when
| <code>-Phive</code> is enabled. When this option is chosen,
| <code>spark.sql.hive.metastore.version</code> must be either
| <code>${hiveExecutionVersion}</code> or not defined.
| 2. "maven"
| Use Hive jars of specified version downloaded from Maven repositories.
| 3. A classpath in the standard format for both Hive and Hadoop.
""".stripMargin)
.stringConf
.createWithDefault("builtin")
在代码层面,我们可以看到,HiveUtils.java创建HiveClientImpl的时候,会根据用户的配置(spark.sql.hive.metastore.jars),来决定依赖的加载方式:
protected[hive] def newClientForMetadata(
conf: SparkConf,
hadoopConf: Configuration,
configurations: Map[String, String]): HiveClient = {
val sqlConf = new SQLConf
sqlConf.setConf(SQLContext.getSQLProperties(conf))
val hiveMetastoreVersion = HiveUtils.hiveMetastoreVersion(sqlConf)
val hiveMetastoreJars = HiveUtils.hiveMetastoreJars(sqlConf)
val hiveMetastoreSharedPrefixes = HiveUtils.hiveMetastoreSharedPrefixes(sqlConf)
val hiveMetastoreBarrierPrefixes = HiveUtils.hiveMetastoreBarrierPrefixes(sqlConf)
val metaVersion = IsolatedClientLoader.hiveVersion(hiveMetastoreVersion)
val isolatedLoader = if (hiveMetastoreJars == "builtin") { // 使用内置的jar包
if (hiveExecutionVersion != hiveMetastoreVersion) {
throw new IllegalArgumentException(
"Builtin jars can only be used when hive execution version == hive metastore version. " +
s"Execution: $hiveExecutionVersion != Metastore: $hiveMetastoreVersion. " +
"Specify a vaild path to the correct hive jars using $HIVE_METASTORE_JARS " +
s"or change ${HIVE_METASTORE_VERSION.key} to $hiveExecutionVersion.")
}
// We recursively find all jars in the class loader chain,
// starting from the given classLoader.
def allJars(classLoader: ClassLoader): Array[URL] = classLoader match {
case null => Array.empty[URL]
case urlClassLoader: URLClassLoader =>
urlClassLoader.getURLs ++ allJars(urlClassLoader.getParent)
case other => allJars(other.getParent)
}
val classLoader = Utils.getContextOrSparkClassLoader
val jars = allJars(classLoader)
if (jars.length == 0) {
throw new IllegalArgumentException(
"Unable to locate hive jars to connect to metastore. " +
"Please set spark.sql.hive.metastore.jars.")
}
logInfo(
s"Initializing HiveMetastoreConnection version $hiveMetastoreVersion using Spark classes.")
new IsolatedClientLoader(
version = metaVersion, // 使用metaVersion 作为版本号
sparkConf = conf,
hadoopConf = hadoopConf,
execJars = jars.toSeq,
config = configurations,
isolationOn = true,
barrierPrefixes = hiveMetastoreBarrierPrefixes,
sharedPrefixes = hiveMetastoreSharedPrefixes)
} else if (hiveMetastoreJars == "maven") { // 使用maven来倒入用户设置的version
// TODO: Support for loading the jars from an already downloaded location.
logInfo(
s"Initializing HiveMetastoreConnection version $hiveMetastoreVersion using maven.")
IsolatedClientLoader.forVersion(
hiveMetastoreVersion = hiveMetastoreVersion, // 使用hiveMetastoreVersion 作为版本号
hadoopVersion = VersionInfo.getVersion,
sparkConf = conf,
hadoopConf = hadoopConf,
config = configurations,
barrierPrefixes = hiveMetastoreBarrierPrefixes,
sharedPrefixes = hiveMetastoreSharedPrefixes)
} else { // 既不是built-in,也不是maven,hiveMetastorejars中存放的直接是jar包的路径
// Convert to files and expand any directories.
val jars =
hiveMetastoreJars
.split(File.pathSeparator)
.flatMap {
case path if new File(path).getName == "*" =>
val files = new File(path).getParentFile.listFiles()
if (files == null) {
logWarning(s"Hive jar path '$path' does not exist.")
Nil
} else {
files.filter(_.getName.toLowerCase.endsWith(".jar"))
}
case path =>
new File(path) :: Nil
}
.map(_.toURI.toURL)
logInfo(
s"Initializing HiveMetastoreConnection version $hiveMetastoreVersion " +
s"using ${jars.mkString(":")}")
new IsolatedClientLoader(
version = metaVersion,
sparkConf = conf,
hadoopConf = hadoopConf,
execJars = jars.toSeq,
config = configurations,
isolationOn = true,
barrierPrefixes = hiveMetastoreBarrierPrefixes,
sharedPrefixes = hiveMetastoreSharedPrefixes)
}
isolatedLoader.createClient()
}
我们可以看到hiveExecutionVersion使用的是hard code 的1.2.1版本,这个版本就是spark集成的hive版本,也是SparkThriftServer的版本:
/** The version of hive used internally by Spark SQL. */
val hiveExecutionVersion: String = "1.2.1"
val HIVE_METASTORE_VERSION = SQLConfigBuilder("spark.sql.hive.metastore.version")
.doc("Version of the Hive metastore. Available options are " +
s"<code>0.12.0</code> through <code>$hiveExecutionVersion</code>.")
.stringConf
.createWithDefault(hiveExecutionVersion)
从代码可以看到, spark给我们提供了三种jar包依赖的管理方式:
- builtin 在这种模式下,用户的metastore版本必须与hiveExecutionVersion版本即spark内置的metastore版本一致,否则抛出异常,因此,在该模式下,如果用户显式配置了
spark.sql.hive.metastore.version,那么必须是1.2.1 - maven 在这种模式下,会通过用户配置的metastore版本, 到maven上下载对应的metastore版本。这时候,会使用独立的
IsolatedClientLoader对象来管理这个版本的hive metastore; - other: 在这种模式下,
spark.sql.hive.metastore.version不在存放了版本号,而是一系列的jar包路径,,spark会解析出这些path,然后加载这些jar包
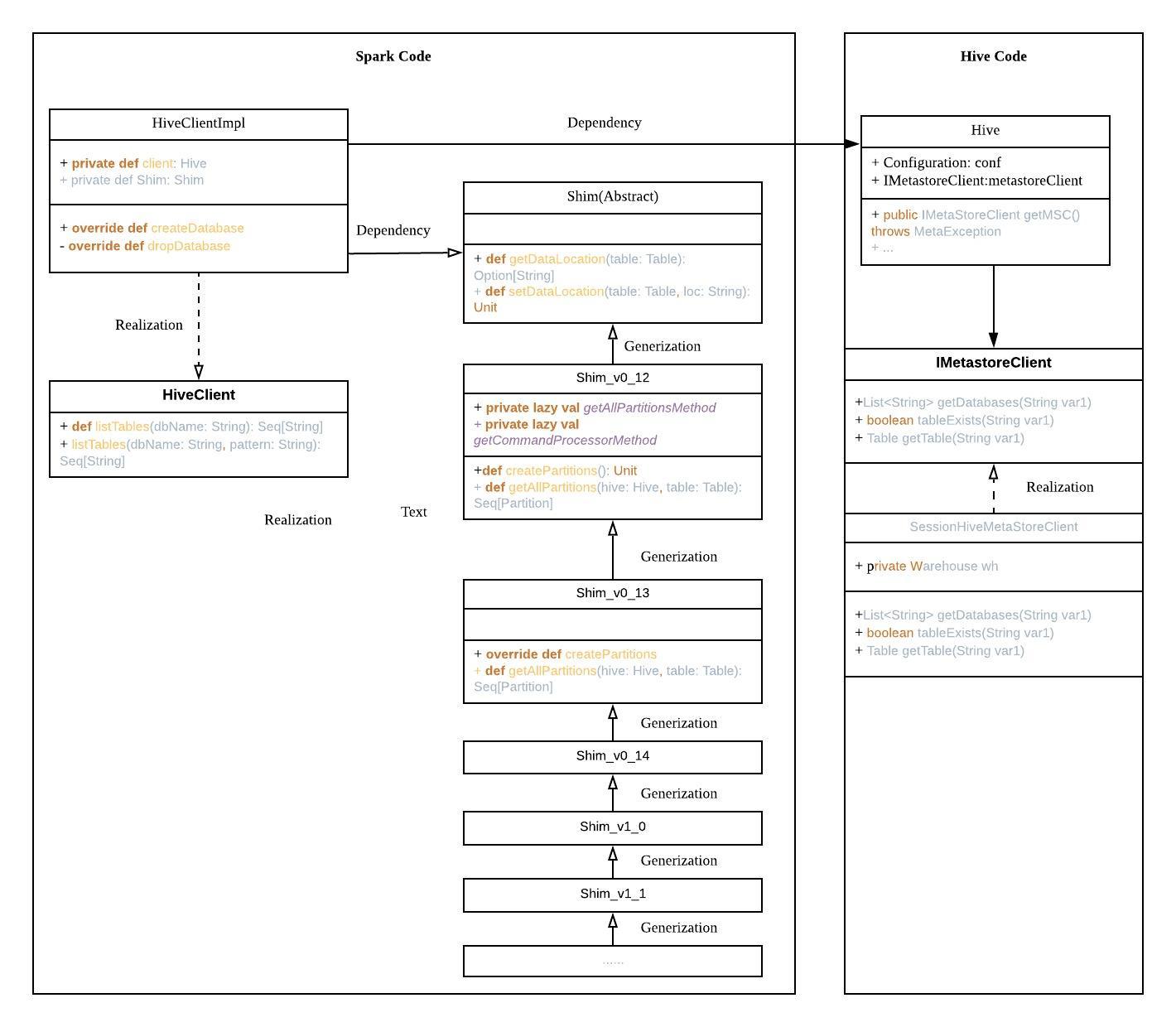
这是HiveClientImpl对HIveMetastore Client相关调用的类图, 我们可以看到Spark中关于Hive客户端的相关依赖的代码层关系:
[外链图片转存失败(img-IzeYOmIv-1563094185456)(https://raw.githubusercontent.com/VicoWu/leetcode/master/src/main/resources/images/spark/spark_uml.jpeg)]
从类图中可以看到,HiveClientImpl实际上含有了两个成员变量, 即client和shim两个成员变量来调用HiveMetastore的接口
client变量的定义为:
// HiveClientImpl中的部分hive 调用使用client,另外一部分hive调用使用shim
private def client: Hive = {
if (clientLoader.cachedHive != null) {
clientLoader.cachedHive.asInstanceOf[Hive]
} else {
val c = Hive.get(conf)
clientLoader.cachedHive = c
c
}
}
这里的client变量用来负责直接调用一些长期不变因此没有兼容性问题的接口,包括:
override def createDatabase(
database: CatalogDatabase,
ignoreIfExists: Boolean)
override def dropDatabase(
name: String,
ignoreIfNotExists: Boolean,
cascade: Boolean): Unit
override def alterDatabase(database: CatalogDatabase)
override def getDatabase(dbName: String)
override def databaseExists(dbName: String):
override def listDatabases(pattern: String):
override def tableExists(dbName: String, tableName: String):
override def getTableOption(
dbName: String,
tableName: String)
override def createTable(table: CatalogTable, ignoreIfExists: Boolean):
override def alterTable(tableName: String, table: CatalogTable)
可以看到,这些接口都是非常简单通用的、随着hive 的升级也不会发生变化的接口。
但是对于那些随着hive的不断升级会发生变化的接口怎么办呢?这就需要shims了。
和其它所有依赖HiveMetastore的系统一样,Spark也是用一个叫做 Shims.scala一样的类去逐步兼容不断升级的HiveMetastore的API. Shims在英文里面指的是“用来填充在木板之间的小垫片”,顾名思义,这里Shims.scala类就仿佛是垫在不同版本的Metastore API之间的小垫片,让这些不同的版本能够相互吻合,稳定工作。
HiveMetastore的版本在不断升级时,Spark通过不断地开发新的shims,来支持新版本的API,为上层业务(Spark的计算框架)隐藏这种兼容性,因此上层代码不需要有任何修改。
在Spark内部,对Hadoop的兼容性也是采用一样的模式。
Spark使用HiveClientImpl来封装了不同的metastore client接口,隐藏了不同版本之间的细微差异,但是对上层暴露出来的还是同一不便的接口。在1.x版本的Spark中,这个类叫做HiveClientWrapper而不是HiveClientImpl, 我们现在只讨论Spark 2.1版本中的HiveClientImpl实现:
private[hive] class HiveClientImpl(
override val version: HiveVersion,
sparkConf: SparkConf,
hadoopConf: Configuration,
extraConfig: Map[String, String],
initClassLoader: ClassLoader,
val clientLoader: IsolatedClientLoader)
extends HiveClient
with Logging {
// 根据传入的版本号,选择使用那个版本的Shim implement
private val shim = version match {
case hive.v12 => new Shim_v0_12()
case hive.v13 => new Shim_v0_13()
case hive.v14 => new Shim_v0_14()
case hive.v1_0 => new Shim_v1_0()
case hive.v1_1 => new Shim_v1_1()
case hive.v1_2 => new Shim_v1_2()
}
同时,我们可以看到match表达式中hive.v12, hive.v12等等对应的hive版本:
private[client] abstract class HiveVersion(
val fullVersion: String,
val extraDeps: Seq[String] = Nil,
val exclusions: Seq[String] = Nil)
// scalastyle:off
private[hive] object hive {
case object v12 extends HiveVersion("0.12.0")
case object v13 extends HiveVersion("0.13.1")
// Hive 0.14 depends on calcite 0.9.2-incubating-SNAPSHOT which does not exist in
// maven central anymore, so override those with a version that exists.
//
// The other excluded dependencies are also nowhere to be found, so exclude them explicitly. If
// they're needed by the metastore client, users will have to dig them out of somewhere and use
// configuration to point Spark at the correct jars.
case object v14 extends HiveVersion("0.14.0",
extraDeps = Seq("org.apache.calcite:calcite-core:1.3.0-incubating",
"org.apache.calcite:calcite-avatica:1.3.0-incubating"),
exclusions = Seq("org.pentaho:pentaho-aggdesigner-algorithm"))
case object v1_0 extends HiveVersion("1.0.0",
exclusions = Seq("eigenbase:eigenbase-properties",
"org.pentaho:pentaho-aggdesigner-algorithm",
"net.hydromatic:linq4j",
"net.hydromatic:quidem"))
// The curator dependency was added to the exclusions here because it seems to confuse the ivy
// library. org.apache.curator:curator is a pom dependency but ivy tries to find the jar for it,
// and fails.
case object v1_1 extends HiveVersion("1.1.0",
exclusions = Seq("eigenbase:eigenbase-properties",
"org.apache.curator:*",
"org.pentaho:pentaho-aggdesigner-algorithm",
"net.hydromatic:linq4j",
"net.hydromatic:quidem"))
case object v1_2 extends HiveVersion("1.2.1",
exclusions = Seq("eigenbase:eigenbase-properties",
"org.apache.curator:*",
"org.pentaho:pentaho-aggdesigner-algorithm",
"net.hydromatic:linq4j",
"net.hydromatic:quidem"))
}
从这个类可以清晰的看到不同的hive版本号,同时可以通过上面的match表达式知道这个对应的hive版本在spark中所对应的shims。
HiveClientImpl通过Shim的接口来定义和封装隐藏了背后的不同hive 版本。从Shim_v0_12开始实现接口,显然,由于Shim是接口,因此 Shim_v0_12必须实现这个接口的所有方法。然后,当Hive有版本更新并且Spark需要兼容和支持这种新版本的时候,Spark就会定义一个新的Shim的实现,这个实现不需要完整实现原始的Shim接口,只需要扩展或者修改与自己临近的一个比较旧的接口即可:
[外链图片转存失败(img-tUcJdBiP-1563094185457)(https://raw.githubusercontent.com/VicoWu/leetcode/master/src/main/resources/images/spark/Spark_Hive_Metastor_shims.jpg)]
每一个shim都会继承与自己相邻的上一个shim,比如Shim_v1_2 extends Shim_v1_1,Shim_v1_1 extends Shim_v1_0, Shim_v1_0 extends Shim_v0_14等等,从而对上一个Shims进行扩展;
以loadDynamicPartitioins方法来了解Shims
为了便于读者更直观了解Shims的实现机制,我们以loadDynamicPartitions这个HiveClient接口为例, 来讲解Spark如何通过Shims来增量支持高版本的Hive中该接口定义的变化的。
这个方法在Hive 0.14和 Hive 1.2中的定义发生了变化,我们可以通过查看相应的github代码查看其不同版本的定义:
Hive 0.14版本的 Hive.loadDynamicPartitions()方法的定义,这是源代码连接:
public Map<Map<String, String>, Partition> loadDynamicPartitions(Path loadPath,
String tableName, Map<String, String> partSpec, boolean replace,
int numDP, boolean holdDDLTime, boolean listBucketingEnabled, boolean isAcid)
throws HiveException {
Hive 1.2.1版本的 Hive.loadDynamicPartitions()方法的定义,这是源代码连接:
public Map<Map<String, String>, Partition> loadDynamicPartitions(Path loadPath,
String tableName, Map<String, String> partSpec, boolean replace,
int numDP, boolean holdDDLTime, boolean listBucketingEnabled, boolean isAcid, long txnId)
throws HiveException {
可以看到两个方法的定义已经发生了改变,那么如果我们的spark需要连接着两个版本的Hive, 那么久必须通过Shims来进行兼容。
我们来看Shim_v1_2中loadDynamicPartitioins方法的实现:
Spark中首先调用HiveClientImpl中的loadDynamicPartitions()方法:
def loadDynamicPartitions(
loadPath: String,
dbName: String,
tableName: String,
partSpec: java.util.LinkedHashMap[String, String],
replace: Boolean,
numDP: Int,
holdDDLTime: Boolean): Unit = withHiveState {
val hiveTable = client.getTable(dbName, tableName, true /* throw exception */)
shim.loadDynamicPartitions(
client,
new Path(loadPath),
s"$dbName.$tableName",
partSpec,
replace,
numDP,
holdDDLTime,
listBucketingEnabled = hiveTable.isStoredAsSubDirectories)
}
可以看到,HiveClientImpl实际上是调用对应的shim.loadDynamicPartitions();
如果这里对应的Shims实现是Shim_v0_14,通过上面的match表达式和我们的HiveVersion代码,知道这里对应了0.14的Hive版本。那么我们来看Shim_v0_14中对于该方法的定义:
private[client] class Shim_v0_14 extends Shim_v0_13 {
private lazy val loadDynamicPartitionsMethod =
findMethod(
classOf[Hive],
"loadDynamicPartitions",
classOf[Path],
classOf[String],
classOf[JMap[String, String]],
JBoolean.TYPE,
JInteger.TYPE,
JBoolean.TYPE,
JBoolean.TYPE,
JBoolean.TYPE)
override def loadDynamicPartitions(
hive: Hive,
loadPath: Path,
tableName: String,
partSpec: JMap[String, String],
replace: Boolean,
numDP: Int,
holdDDLTime: Boolean,
listBucketingEnabled: Boolean): Unit = {
loadDynamicPartitionsMethod.invoke(hive, loadPath, tableName, partSpec, replace: JBoolean,
numDP: JInteger, holdDDLTime: JBoolean, listBucketingEnabled: JBoolean, JBoolean.FALSE)
}
如果这里的Shims对应的是Shim_v1_2,所以根据上文提到的forVersion()方法,这里的hive版本肯定是1.2.1, 这时候系统中无论通过builtin还是maven的方式,会帮我们load进来1.2.1版本的hive,然后通过反射的方式加载这个方法,然后,在Shim_v1_2中对这个方法进行调用;
Hive.java(必须是Shim_v1_2即1.2.1版本的hive 的lib中是Hive.java) 中 loadDynamicPartitions(...) 定义:
private[client] class Shim_v1_2 extends Shim_v1_1 {
private lazy val loadDynamicPartitionsMethod =
findMethod(
classOf[Hive],
"loadDynamicPartitions",
classOf[Path],
classOf[String],
classOf[JMap[String, String]],
JBoolean.TYPE,
JInteger.TYPE,
JBoolean.TYPE,
JBoolean.TYPE,
JBoolean.TYPE,
JLong.TYPE)
override def loadDynamicPartitions(
hive: Hive,
loadPath: Path,
tableName: String,
partSpec: JMap[String, String],
replace: Boolean,
numDP: Int,
holdDDLTime: Boolean,
listBucketingEnabled: Boolean): Unit = {
loadDynamicPartitionsMethod.invoke(hive, loadPath, tableName, partSpec, replace: JBoolean,
numDP: JInteger, holdDDLTime: JBoolean, listBucketingEnabled: JBoolean, JBoolean.FALSE,
0L: JLong)
}
显然,如果用户让Spark进行load的Hive的jar包的版本和用户实际告知Hive的jar包的版本不一致,那么在通过shims进行调用的时候就可能因此参数不一致而出现MethodNotFound 的异常;
可以看到,Shim_v0_14和Shim_v1_2中对方法loadDynamicPartitions的实现是不同的,这是因为对应版本的Hive中对于该方法的接口已经发生了改变。通过这种方式,实现了对不同版本的hive的兼容;
所以,对于2.X版本的Hive能够支持的最高版本的Hive,或者说,我们看到某个新版本的hive相对于旧版本的hive新增或者修改了某个接口,那么,我们可以通过查看HiveClientImpl对应的shims中是否已经添加了对应接口的支持。如果没有,读完本文,我们自己添加对应接口也不是特别困难的事。
Spark用户的正确使用姿势:
简单来讲,Spark用户需要配置好两件事:
- 配置好spark依赖的hive jar包的来源
- 告诉Spark对应的hive的版本,这里的版本需要与我们配置的jar包的版本一致
首先,我们需要通过spark.sql.hive.metastore.jars配置spark对应hive的jar包的加载方式:
- builtin(默认) 在这种模式下,用户的metastore版本必须与hiveExecutionVersion版本即spark内置的metastore版本一致,否则抛出异常,因此,在该模式下,如果用户显式配置了
spark.sql.hive.metastore.version,那么必须是1.2.1 - maven 在这种模式下,会通过用户配置的metastore版本, 到maven上下载对应的metastore版本。这时候,会使用独立的
IsolatedClientLoader对象来管理这个版本的hive metastore; - other: 在这种模式下,
spark.sql.hive.metastore.version不在存放了版本号,而是一系列的jar包路径,,spark会解析出这些path,然后加载这些jar包
由于spark.sql.hive.metastore.jars的默认值是builtin, 因此,如果就像大多数用户做的那样,没有配置spark.sql.hive.metastore.jars,或者将spark.sql.hive.metastore.jars的默认值显式配置为builtin, 那么spark将使用内置的hive metastore版本作为客户端,这时候我们的 spark.sql.hive.version和spark.sql.hive.metastore.version都允许再进行显式配置,如果配置,必须全部配置为1.2.1,这个从代码可以看出:
/** The version of hive used internally by Spark SQL. */
val hiveExecutionVersion: String = "1.2.1"
val HIVE_METASTORE_VERSION = SQLConfigBuilder("spark.sql.hive.metastore.version")
.doc("Version of the Hive metastore. Available options are " +
s"<code>0.12.0</code> through <code>$hiveExecutionVersion</code>.")
.stringConf
.createWithDefault(hiveExecutionVersion)
val HIVE_EXECUTION_VERSION = SQLConfigBuilder("spark.sql.hive.version")
.doc("Version of Hive used internally by Spark SQL.")
.stringConf
.createWithDefault(hiveExecutionVersion)
如果spark.sql.hive.metastore.jars = maven, 我们需要通过spark.sql.hive.metastore.version来配置对应的hive版本,同时自动帮我们下载对应的hive版本
如果spark.sql.hive.metastore.jar既不是配置成bultiin也不是maven, 而是将配置为以逗号分割的文件路径,Spark会自动帮我们加载对应的spark的jar包, 同时我们通过spark.sql.hive.metastore.version来配置我们所提供的hive metastore的jar包的版本号。这种方式比较适合我们对spark所依赖的hive版本进行了二次开发,此时我们可以通过自开发的对应版本的hive来提供给spark使用;
通过自定义ClassLoader实现多版本的hive client共存
由于我们在一个Spark Application中可以创建任意多个不同的Spark Session,因此在我们的Spark Application执行过程中可能出现一个Driver进程中存在访问多个并且版本不同的hive metastore的需求,然而,访问这些MetaStore却都是使用HiveClient这个接口来进行了,因此,Spark需要自己实现特殊的ClassLoader机制来保证同一个class有多个不同版本并存于一个JVM中。
关于SparkSession的创建,我们可以参考这里:SparkSession — The Entry Point to Spark SQL
IsolatedClientLoader是一个用来构造HiveClientImpl背后具体的不同的Hive版本的工厂类,每一个IsolatedClientLoader对象,封装了某个版本的HiveClient的实现,包括:
- 版本号
- 所有的jar
通过提供自定义的独立的ClassLoader, 用来支持在同一个jvm 中同时使用多个不同版本的HiveMetastore,这是由于Spark本身默认绑定的built-in的hive 版本是1.2.1,因此,如果我们需要使用其他高版本的HiveClient,就有可能存在同一个Spark JVM里面并存多个不同版本的hive client,这需要使用不同的ClassLoader对象来实现, 每一个IsolatedClientLoader负责一个hive version.
IsolatedClientLoader使用forVersion()静态方法来创建并保存不同的hive版本对应的自己(IsolatedClientLoader)的实例。
def forVersion(
hiveMetastoreVersion: String,
hadoopVersion: String,
sparkConf: SparkConf,
hadoopConf: Configuration,
config: Map[String, String] = Map.empty,
ivyPath: Option[String] = None,
sharedPrefixes: Seq[String] = Seq.empty,
barrierPrefixes: Seq[String] = Seq.empty): IsolatedClientLoader = synchronized {
val resolvedVersion = hiveVersion(hiveMetastoreVersion)
// We will first try to share Hadoop classes. If we cannot resolve the Hadoop artifact
// with the given version, we will use Hadoop 2.4.0 and then will not share Hadoop classes.
var sharesHadoopClasses = true
val files = if (resolvedVersions.contains((resolvedVersion, hadoopVersion))) {
resolvedVersions((resolvedVersion, hadoopVersion))
} else {
val (downloadedFiles, actualHadoopVersion) = // 下载对应版本的hive
try {
(downloadVersion(resolvedVersion, hadoopVersion, ivyPath), hadoopVersion)
} catch {
case e: RuntimeException if e.getMessage.contains("hadoop") =>
// If the error message contains hadoop, it is probably because the hadoop
// version cannot be resolved (e.g. it is a vendor specific version like
// 2.0.0-cdh4.1.1). If it is the case, we will try just
// "org.apache.hadoop:hadoop-client:2.4.0". "org.apache.hadoop:hadoop-client:2.4.0"
// is used just because we used to hard code it as the hadoop artifact to download.
logWarning(s"Failed to resolve Hadoop artifacts for the version ${hadoopVersion}. " +
s"We will change the hadoop version from ${hadoopVersion} to 2.4.0 and try again. " +
"Hadoop classes will not be shared between Spark and Hive metastore client. " +
"It is recommended to set jars used by Hive metastore client through " +
"spark.sql.hive.metastore.jars in the production environment.")
sharesHadoopClasses = false
(downloadVersion(resolvedVersion, "2.4.0", ivyPath), "2.4.0")
}
// 将对应版本的hive依赖保存起来,这样可以下次直接使用
resolvedVersions.put((resolvedVersion, actualHadoopVersion), downloadedFiles)
resolvedVersions((resolvedVersion, actualHadoopVersion))
}
关于classloader的基本知识以及ContextClassLoader的使用场景,我们客户参考这篇技术博客:ClassLoaders in Java; 所有的ContextClassLoader只能在当前线程中有效;对于每一个线程,我们都可以通过Thread.currentThread().getContextClassLoader() 来获取当前线程的classloader,同时,可以通过Thread.currentThread().setContextClassLoader();来修改当前线程的classloader;
IsolatedClientLoader通过提供的createClient方法来帮助我们设置ContextClassLoader,使用ContextClassLoader来加载对应的hive并创建隔离的HiveClientImpl,同时在Hive加载完成以后恢复当前线程的ContextClassLoader:
/** The isolated client interface to Hive. */
private[hive] def createClient(): HiveClient = {
if (!isolationOn) { // 是否需要隔离,如果不需要,则直接创建对象,即使用默认的Classloader来加载class
return new HiveClientImpl(version, sparkConf, hadoopConf, config, baseClassLoader, this)
}
// Pre-reflective instantiation setup.
logDebug("Initializing the logger to avoid disaster...")
val origLoader = Thread.currentThread().getContextClassLoader
Thread.currentThread.setContextClassLoader(classLoader)
// 如果有类隔离需求,则需要使用独立的classloader来初始化类和对象
try {
// 传入version,创建HiveClientImpl对象,HiveClientImpl中封装了不同版本的client的具体实现
classLoader
.loadClass(classOf[HiveClientImpl].getName)
.getConstructors.head
.newInstance(version, sparkConf, hadoopConf, config, classLoader, this)
.asInstanceOf[HiveClient]
} catch {
case e: InvocationTargetException =>
if (e.getCause().isInstanceOf[NoClassDefFoundError]) {
val cnf = e.getCause().asInstanceOf[NoClassDefFoundError]
throw new ClassNotFoundException(
s"$cnf when creating Hive client using classpath: ${execJars.mkString(", ")}\n" +
"Please make sure that jars for your version of hive and hadoop are included in the " +
s"paths passed to ${HiveUtils.HIVE_METASTORE_JARS.key}.", e)
} else {
throw e
}
} finally {
Thread.currentThread.setContextClassLoader(origLoader)
}
}
在创建对应的HiveClient的时候,判断逻辑是:
- isolation是否关闭,如果关闭,意味着我们根本不需要处理任何多版本共存的场景,因此直接
new HiveClientImpl(), 即使用默认的classloader来加载类- 如果isolation没有关闭,那么就使用我们自定义的
ContextClassLoader来加载这个HiveClientImpl, 即,先把当前线程的ContextClassLoader设置成我们自定义的ClassLoader即IsolatedClientLoader
- 如果isolation没有关闭,那么就使用我们自定义的
- 类加载完成以后,我们把当前线程的
ContextClassLoader重新还原成原来的默认的classloader
/**
* The classloader that is used to load an isolated version of Hive.
* This classloader is a special URLClassLoader that exposes the addURL method.
* So, when we add jar, we can add this new jar directly through the addURL method
* instead of stacking a new URLClassLoader on top of it.
*/
private[hive] val classLoader: MutableURLClassLoader = {
val isolatedClassLoader =
if (isolationOn) {
new URLClassLoader(allJars, rootClassLoader) {
override def loadClass(name: String, resolve: Boolean): Class[_] = {
// 判断当前这个classLoader对象是否已经加载了这个class对象,如果已经加载了,则直接返回
val loaded = findLoadedClass(name)
if (loaded == null) doLoadClass(name, resolve) else loaded
}
def doLoadClass(name: String, resolve: Boolean): Class[_] = {
val classFileName = name.replaceAll("\\.", "/") + ".class"
if (isBarrierClass(name)) {
// For barrier classes, we construct a new copy of the class.
val bytes = IOUtils.toByteArray(baseClassLoader.getResourceAsStream(classFileName))
logDebug(s"custom defining: $name - ${util.Arrays.hashCode(bytes)}")
defineClass(name, bytes, 0, bytes.length)
} else if (!isSharedClass(name)) {
logDebug(s"hive class: $name - ${getResource(classToPath(name))}")
super.loadClass(name, resolve)
} else {
// For shared classes, we delegate to baseClassLoader, but fall back in case the
// class is not found.
logDebug(s"shared class: $name")
try {
baseClassLoader.loadClass(name) // 如果是shared class,没必要使用新的classloader, 直接使用当前的Context classloader来加载
} catch {
case _: ClassNotFoundException =>
super.loadClass(name, resolve)
}
}
}
}
} else {
baseClassLoader
}
// Right now, we create a URLClassLoader that gives preference to isolatedClassLoader
// over its own URLs when it loads classes and resources.
// We may want to use ChildFirstURLClassLoader based on
// the configuration of spark.executor.userClassPathFirst, which gives preference
// to its own URLs over the parent class loader (see Executor's createClassLoader method).
new NonClosableMutableURLClassLoader(isolatedClassLoader)
}
可以看到,这个自定义的ClassLoader继承了URLClassLoader,最重要的,重写了loadClass()方法,基本逻辑是:
- 检查自己是否已经加载过这个class,如果已经加载过,则直接返回这个Class。这里的Class指的是我们指定的metastore版本以后下载的jar包中的所有class。由于使用了新的
ClassLoader对象,因此这些Class虽然与Sparkbuilt-in的class具有相同的包名,但是却可以同时存在于一个jvm中。 - 如果没有加载过这个
Class,则调用自定义的doLoadClass()来进行类的加载。可以看到,其判断规则为:- 如果是barrier class,则需要使用当前新的classLoader进行加载,这时候会生成这个class对应的字节数组的拷贝,然后调用
difineClass()生成对应的类文件; - 如果不是barrier class, 也不是shared class, 则使用默认的classloader来加载,即URLClassLoader来加载
- 如果是shared class, 则使用系统的当前线程的默认的ContextClassLoad而来加载,如果加载失败,则使用URLClassLoader来加载
- 如果是barrier class,则需要使用当前新的classLoader进行加载,这时候会生成这个class对应的字节数组的拷贝,然后调用
/**
* 将用户制定的meta版本,聚合对应到某一个版本,因为有些小版本之间的差异可以忽略
* @param version
* @return
*/
def hiveVersion(version: String): HiveVersion = version match {
case "12" | "0.12" | "0.12.0" => hive.v12
case "13" | "0.13" | "0.13.0" | "0.13.1" => hive.v13
case "14" | "0.14" | "0.14.0" => hive.v14
case "1.0" | "1.0.0" => hive.v1_0
case "1.1" | "1.1.0" => hive.v1_1
case "1.2" | "1.2.0" | "1.2.1" => hive.v1_2
}
当IsolatedClientLoader为我们完成了不同版本的hive metastore的加载,但是spark会将这种接口差异隐藏起来,持续提供统一的接口。
结论
Spark对Hive版本的兼容以及通过多ClassLoader实现了在相同jvm里面同时加载不同版本的hive client,设计思想都非常经典,非常值得我们在代码层面学习;















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}