







 本文详细介绍了OpenCV中的正态贝叶斯分类器,区别于朴素贝叶斯,正态贝叶斯不需要特征间独立的假设,适用范围更广。文章首先讲解了朴素贝叶斯分类器的原理,包括概率模型、极大似然估计、平滑处理等,然后重点阐述了正态贝叶斯分类器的工作机制,涉及均值向量、协方差矩阵的计算。最后,通过实例展示了如何使用OpenCV实现正态贝叶斯分类器进行性别预测。
本文详细介绍了OpenCV中的正态贝叶斯分类器,区别于朴素贝叶斯,正态贝叶斯不需要特征间独立的假设,适用范围更广。文章首先讲解了朴素贝叶斯分类器的原理,包括概率模型、极大似然估计、平滑处理等,然后重点阐述了正态贝叶斯分类器的工作机制,涉及均值向量、协方差矩阵的计算。最后,通过实例展示了如何使用OpenCV实现正态贝叶斯分类器进行性别预测。
一、原理
OpenCV实现的贝叶斯分类器不是我们所熟悉的朴素贝叶斯分类器(Naïve Bayes Classifier),而是正态贝叶斯分类器(Normal Bayes Classifier),两者虽然英文名称很相似,但它们是不同的贝叶斯分类器。前者在使用上有一个限制条件,那就是变量的特征之间要相互独立,而后者没有这个苛刻的条件,因此它的适用范围更广。为了保持理论的系统性和完整性,我们还是先介绍朴素贝叶斯分类器,然后再介绍正态贝叶斯分类器。
1、朴素贝叶斯分类器
朴素贝叶斯分类器是一种基于贝叶斯理论的简单的概率分类器,而朴素的含义是指输入变量的特征属性之间具有很强的独立性。尽管这种朴素的设计和假设过于简单,但朴素贝叶斯分类器在许多复杂的实际情况下具有很好的表现,并且在综合性能上,该分类器要优于提升树(boosted trees)和随机森林(random forests)。
在许多实际应用中,对于朴素贝叶斯模型的参数估计往往使用的是极大似然法,因此我们可以这么认为,在不接受贝叶斯概率或不使用任何贝叶斯方法的前提下,我们仍然可以应用朴素贝叶斯模型对事物进行分类。
朴素贝叶斯分类器特别适用于输入变量的维数很高的情况,并且它只需要极少量的训练数据就可以估计出分类所需的参数。
抽象地说,朴素贝叶斯是一种条件概率模型:我们要对一个个体进行分类,该个体用代表n个特征(相互独立的变量)的n维向量表示,即x = (x1,…,xn)T,则分配给该个体的概率为:
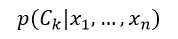
该式表示K个可能输出或分类中第k个分类的概率,Ck表示第k个响应输出,即分类结果。
如果个体的特征数量n很大,或者某个特征有大量的数值,则应用式1对个体进行分类是不可行。因此我们应用贝叶斯理论,把条件概率进行分解,使其更利于操作:
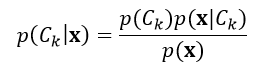
基于认识论的解释,概率是一种置信程度的度量。贝叶斯理论把某个事件在考虑证据之前和之后的置信程度关联了起来。回到式2,p(Ck)表示在不考虑个体x的情况下,第k个分类的概率,我们把它定义为先验概率,而p(Ck|x)表示在考虑个体x的情况下,第k个分类的概率,我们把它定义为后验概率,p(x| Ck)定义为似然度,p(x)定义为标准化常量。
在实际应用中,我们仅仅关心的是式2分式中的分子部分,这是因为分母部分不依赖于分类结果C,并且个体的特征属性Fi是给定的,所以分母是一个常数。
我们再来看式2中的分子部分,它是联合概率模型p(Ck, x1,…,xn)。基于链式法则,并重复应用条件概率的定义,这个联合概率模型可以重写为:
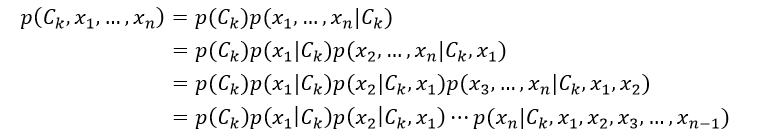
由于是“朴素”的贝叶斯,对于分类Ck来说,特征Fi是有条件的独立于特征Fj的,i≠j。因此,这意味着p(xi|Ck,xj) = p(xi|Ck),p(xi|Ck,xj,xq) = p(xi|Ck),p(xi|Ck,xj,xq,xl)= p(xi|Ck),以此类推,其中i≠j,q, l。则式2又可重写为:
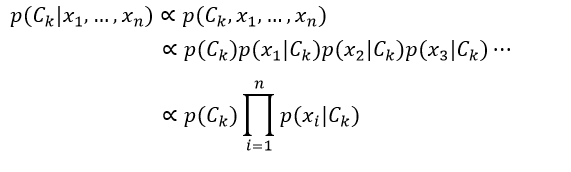
到目前为止我们得到了特征相互独立的朴素贝叶斯概率模型,我们利用该模型就可以得到具备决策规则的朴素贝叶斯分类器。应用得最普遍的决策规则是最大后验概率(MAP),即选择最可能的假设。则贝叶斯分类器所指定的分类结果为:
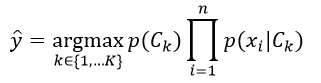
训练朴素贝叶斯分类器的任务是估计两组参数:先验概率p(Ck)和条件概率p(xi| Ck)。
我们先来计算条件概率p(xi | Ck),它分为两种情况:一种是样本数据都是离散的形式,即样本的特征是离散的形式;另一种是样本数据都是连续的数值形式,即样本的特征是数值的形式。
当样本的特征是离散的形式时,条件概率p(xi | Ck)的估计为
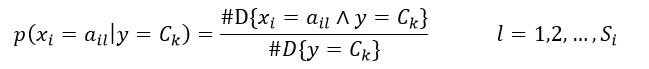
式中,ail表示第i个特征可能取的第l个值,Si表示第i个特征可能选取的所有值的数量,#D{X}表示在由N个训练样本构成的集合D中,满足条件X的样本的数量,因此分式中分母的含义是响应值为Ck的样本数,分子的含义是样本具有ail值并且响应值为Ck的数量。
式6给出了特征值为ail并且响应值为Ck的条件概率估计,该方法称为极大似然估计。但该方法可能会出现所要估计的概率值为0的情况,这时会影响到后验概率的计算结果,使分类产生偏差。采用平滑估计可以解决这个问题,即增加一个平滑系数λ,则条件概率为:
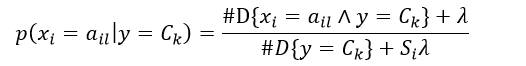
式中,λ≥ 0,显然λ = 0为极大似然估计,当λ = 1时,该平滑方法又称为拉普拉斯平滑。
当样本的特征是数值的形式时,条件概率的分布可以被认为是高斯分布,多项式分布或伯努利分布,则它们的朴素贝叶斯分别被称为高斯朴素贝叶斯,多项式朴素贝叶斯和伯努利朴素贝叶斯。在这里我们只介绍高斯朴素贝叶斯方法
高斯朴素贝叶斯方法是假设对每一个可能的响应值Ck,特征xi是满足高斯正态分布的,即
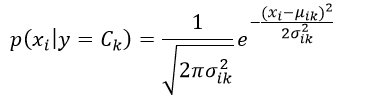
因此我们必须估计出该高斯分布的均值μik和方差σik2:
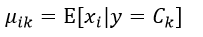
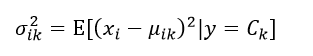
这里一共有2nK个参数,这些参数都需要独立的去估计。估计的方法仍然可以采用极大似然估计。均值μik的极大似然估计为:
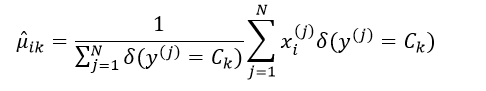
式中上标j表示全部N个训练样本中的第j个样本,函数δ(y = Ck)表示:
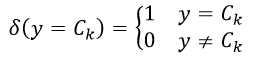
函数δ的作用就是选择那些响应值为Ck的训练样本。
方差σik2的极大似然估计为:
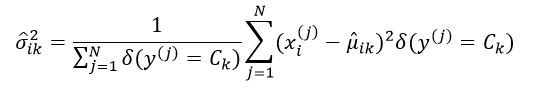
采用极大似然估计得到的方差是有偏估计,因此往往采用最小方差无偏估计(MVUE)来取代极大似然估计,则此时的σik2估计为:
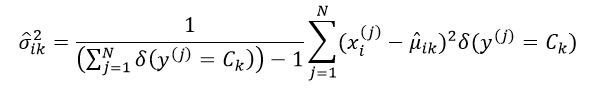
我们再来讨论先验概率。贝叶斯分类器只能处理分类问题,即分类结果C具有离散的K个值,因此先验概率p(Ck)的估计相对较简单。当我们已知所有的分类结果出现的概率都是相等的话(如投骰子),则先验概率p(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









