






目录
1.梯度问题:... 2
再结合就应该能理解:... 4
一. 批梯度下降算法... 4
二. 随机梯度下降算法... 6
2.Dropout详解:... 7
3.交叉熵:::::... 11
4.EM算法和LMS算法... 17
LMS算法:... 17
EM算法:... 18
5.正则化:... 39
tensorflow学习笔记(三十八):损失函数加上正则项... 39
tensorflow Regularizers. 39
如何创建一个正则方法函数... 39
应用正则化方法到参数上... 40
6.无人监督学习与监督学习... 41
定义wordembedding的维度::::... 46
I. 五十步笑百步... 46
II. 似非而是... 47
III. 从何而来... 48
7.MAP和MRR. 51
MAP(Mean Average Precision):... 51
NDCG(Normalized Discounted Cumulative Gain):... 51
MRR(Mean Reciprocal Rank):... 53
8.SVM支持向量机... 54
9联合概率分布... 58
10.内积与外积:... 59
点乘公式... 59
点乘几何意义... 60
叉乘几何意义... 62
11.方差和期望 权重可以设置,期望固定... 64
12.softmax分类器和logistic分类器... 65
Logistic 分类器与 softmax分类器... 65
Logistic 分类器... 65
softmax分类器... 67
注意:... 71
13.LSTM:... 73
14Kullback-Leibler Divergence. 74
1.梯度问题:
刚刚看完斯坦福大学机器学习第四讲(牛顿法),也对学习过程做一次总结吧。
一、误差准则函数与随机梯度下降:
数学一点将就是,对于给定的一个点集(X,Y),找到一条曲线或者曲面,对其进行拟合之。同时称X中的变量为特征(Feature),Y值为预测值。
如图:
一个典型的机器学习的过程,首先给出一组输入数据X,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计Y,也被称为构建一个模型。
我们用X1、X2...Xn 去描述feature里面的分量,用Y来描述我们的估计,得到一下模型:
我们需要一种机制去评价这个模型对数据的描述到底够不够准确,而采集的数据x、y通常来说是存在误差的(多数情况下误差服从高斯分布),于是,自然的,引入误差函数:
关键的一点是如何调整theta值,使误差函数J最小化。J函数构成一个曲面或者曲线,我们的目的是找到该曲面的最低点:
假设随机站在该曲面的一点,要以最快的速度到达最低点,我们当然会沿着坡度最大的方向往下走(梯度的反方向)
用数学描述就是一个求偏导数的过程:
这样,参数theta的更新过程描述为以下:
(α表示算法的学习速率)
二、不同梯度下降算法的区别:
· 梯度下降:梯度下降就是我上面的推导,要留意,在梯度下降中,对于θθ的更新,所有的样本都有贡献,也就是参与调整θθ.其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比较大的。如果样本不多的情况下,当然是这样收敛的速度会更快啦~
· 随机梯度下降:可以看到多了随机两个字,随机也就是说我用样本中的一个例子来近似我所有的样本,来调整θθ,因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,容易陷入到局部最优解中
· 批量梯度下降:其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是我1个指不定不太准,那我用个30个50个样本那比随机的要准不少了吧,而且批量的话还是非常可以反映样本的一个分布情况的。
再结合就应该能理解:
一. 批梯度下降算法
可以用以下式子表示一个样本:
θ表示X映射成Y的权重,x表示一次特征。假设x0=1,上式就可以写成:
分别使用x(j),y(j)表示第J个样本。我们计算的目的是为了让计算的值无限接近真实值y,即代价函数可以采用LMS算法
要获取J(θ)最小,即对J(θ)进行求导且为零:
当单个特征值时,上式中j表示系数(权重)的编号,右边的值赋值给左边θj从而完成一次迭代。
单个特征的迭代如下:
多个特征的迭代如下:
上式就是批梯度下降算法(batch gradientdescent),当上式收敛时则退出迭代,何为收敛,即前后两次迭代的值不再发生变化了。一般情况下,会设置一个具体的参数,当前后两次迭代差值小于该参数时候结束迭代。注意以下几点:
(1) a 即learning rate,决定的下降步伐,如果太小,则找到函数最小值的速度就很慢,如果太大,则可能会出现overshoot the minimum的现象;
(2) 初始点不同,获得的最小值也不同,因此梯度下降求得的只是局部最小值;
(3) 越接近最小值时,下降速度越慢;
(4) 计算批梯度下降算法时候,计算每一个θ值都需要遍历计算所有样本,当数据量的时候这是比较费时的计算。
批梯度下降算法的步骤可以归纳为以下几步:
(1)先确定向下一步的步伐大小,我们称为Learning rate ;
(2)任意给定一个初始值:θ向量,一般为0向量
(3)确定一个向下的方向,并向下走预先规定的步伐,并更新θ向量
(4)当下降的高度小于某个定义的值,则停止下降;
二. 随机梯度下降算法
因为每次计算梯度都需要遍历所有的样本点。这是因为梯度是J(θ)的导数,而J(θ)是需要考虑所有样本的误差和,这个方法问题就是,扩展性问题,当样本点很大的时候,基本就没法算了。所以接下来又提出了随机梯度下降算法(stochastic gradient descent )。随机梯度下降算法,每次迭代只是考虑让该样本点的J(θ)趋向最小,而不管其他的样本点,这样算法会很快,但是收敛的过程会比较曲折,整体效果上,大多数时候它只能接近局部最优解,而无法真正达到局部最优解。所以适合用于较大训练集的case。
LMS算法:
E{e2(n)}=E{[d(n)−y(n)]2}
其中,E{e2(n)}就是均方误差,d(n)表示滤波器输入x(n)时所期望得到的响应或者输出,y(n)表示输入x(n)经过滤波器后实际得到的滤波器的输出,e(n)表示输入x(n)时,滤波器的期望响应和实际输出之间的误差。
2.Dropout详解:
开篇明义,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
dropout是CNN中防止过拟合提高效果的一个大杀器,但对于其为何有效,却众说纷纭。在下读到两篇代表性的论文,代表两种不同的观点,特此分享给大家。
该论文从神经网络的难题出发,一步一步引出dropout为何有效的解释。大规模的神经网络有两个缺点:
· 费时
· 容易过拟合
这两个缺点真是抱在深度学习大腿上的两个大包袱,一左一右,相得益彰,额不,臭气相投。过拟合是很多机器学习的通病,过拟合了,得到的模型基本就废了。而为了解决过拟合问题,一般会采用ensemble方法,即训练多个模型做组合,此时,费时就成为一个大问题,不仅训练起来费时,测试起来多个模型也很费时。总之,几乎形成了一个死锁。
虽然直观上看dropout是ensemble在分类性能上的一个近似,然而实际中,dropout毕竟还是在一个神经网络上进行的,只训练出了一套模型参数。那么他到底是因何而有效呢?这就要从动机上进行分析了。论文中作者对dropout的动机做了一个十分精彩的类比:
在自然界中,在中大型动物中,一般是有性繁殖,有性繁殖是指后代的基因从父母两方各继承一半。但是从直观上看,似乎无性繁殖更加合理,因为无性繁殖可以保留大段大段的优秀基因。而有性繁殖则将基因随机拆了又拆,破坏了大段基因的联合适应性。
但是自然选择中毕竟没有选择无性繁殖,而选择了有性繁殖,须知物竞天择,适者生存。我们先做一个假设,那就是基因的力量在于混合的能力而非单个基因的能力。不管是有性繁殖还是无性繁殖都得遵循这个假设。为了证明有性繁殖的强大,我们先看一个概率学小知识。
比如要搞一次恐怖袭击,两种方式:
- 集中50人,让这50个人密切精准分工,搞一次大爆破。
- 将50人分成10组,每组5人,分头行事,去随便什么地方搞点动作,成功一次就算。
哪一个成功的概率比较大?显然是后者。因为将一个大团队作战变成了游击战。
那么,类比过来,有性繁殖的方式不仅仅可以将优秀的基因传下来,还可以降低基因之间的联合适应性,使得复杂的大段大段基因联合适应性变成比较小的一个一个小段基因的联合适应性。
dropout也能达到同样的效果,它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
个人补充一点:那就是植物和微生物大多采用无性繁殖,因为他们的生存环境的变化很小,因而不需要太强的适应新环境的能力,所以保留大段大段优秀的基因适应当前环境就足够了。而高等动物却不一样,要准备随时适应新的环境,因而将基因之间的联合适应性变成一个一个小的,更能提高生存的概率。
· 防止过拟合的方法:
· 提前终止(当验证集上的效果变差的时候)
· L1和L2正则化加权
· soft weight sharing
· dropout
· dropout率的选择
· 经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。
· dropout也可以被用作一种添加噪声的方法,直接对input进行操作。输入层设为更接近1的数。使得输入变化不会太大(0.8)
· 训练过程
· 对参数w的训练进行球形限制(max-normalization),对dropout的训练非常有用。
· 球形半径c是一个需要调整的参数。可以使用验证集进行参数调优
· dropout自己虽然也很牛,但是dropout、max-normalization、large decayinglearning rates and high momentum组合起来效果更好,比如max-normregularization就可以防止大的learning rate导致的参数blow up。
· 使用pretraining方法也可以帮助dropout训练参数,在使用dropout时,要将所有参数都乘以1/p。
· 部分实验结论
该论文的实验部分很丰富,有大量的评测数据。
· maxout 神经网络中得另一种方法,Cifar-10上超越dropout
· 文本分类上,dropout效果提升有限,分析原因可能是Reuters-RCV1数据量足够大,过拟合并不是模型的主要问题
· dropout与其他standerdregularizers的对比
· L2 weight decay
· lasso
· KL-sparsity
· max-norm regularization
· dropout
· 特征学习
· 标准神经网络,节点之间的相关性使得他们可以合作去fix其他节点中得噪声,但这些合作并不能在unseen data上泛化,于是,过拟合,dropout破坏了这种相关性。在autoencoder上,有dropout的算法更能学习有意义的特征(不过只能从直观上,不能量化)。
· 产生的向量具有稀疏性。
· 保持隐含节点数目不变,dropout率变化;保持激活的隐节点数目不变,隐节点数目变化。
· 数据量小的时候,dropout效果不好,数据量大了,dropout效果好
· 模型均值预测
· 使用weight-scaling来做预测的均值化
· 使用mente-carlo方法来做预测。即对每个样本根据dropout率先sample出来k个net,然后做预测,k越大,效果越好。
· Multiplicative Gaussian Noise
使用高斯分布的dropout而不是伯努利模型dropout
· dropout的缺点就在于训练时间是没有dropout网络的2-3倍。
3.交叉熵:::::
作者:CyberRep
链接:https://www.zhihu.com/question/41252833/answer/195901726
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
讨论这个问题需要从香农的信息熵开始。
小明在学校玩王者荣耀被发现了,爸爸被叫去开家长会,心里悲屈的很,就想法子惩罚小明。到家后,爸爸跟小明说:既然你犯错了,就要接受惩罚,但惩罚的程度就看你聪不聪明了。这样吧,我出一个题目,你猜答案,你每猜一次,不管对错,你就一个星期不能玩王者荣耀,当然,猜对,游戏停止,否则继续猜。同时,当你100%确定答案时,游戏也停止。
题目1:爸爸拿来一个箱子,跟小明说:里面有橙、紫、蓝及青四种颜色的小球任意个,各颜色小球的占比不清楚,现在我从中拿出一个小球,你猜我手中的小球是什么颜色?
为了使被罚时间最短,小明发挥出最强王者的智商,瞬间就想到了以最小的代价猜出答案,简称策略1,小明的想法是这样的。
<imgsrc="https://pic2.zhimg.com/50/v2-97e76bd3402b6d765bfc1934d4c75f75_hd.png"data-rawwidth="300" data-rawheight="213"class="content_image" width="300">
在这种情况下,小明什么信息都不知道,只能认为四种颜色的小球出现的概率是一样的。所以,根据策略1,1/4概率是橙色球,小明需要猜两次,1/4是紫色球,小明需要猜两次,其余的小球类似,所以小明预期的猜球次数为:
H = 1/4 * 2 + 1/4 * 2 + 1/4 * 2 + 1/4 * 2 = 2
题目2:爸爸还是拿来一个箱子,跟小明说:箱子里面有小球任意个,但其中1/2是橙色球,1/4是紫色球,1/8是蓝色球及1/8是青色球。我从中拿出一个球,你猜我手中的球是什么颜色的?
小明毕竟是最强王者,仍然很快得想到了答案,简称策略2,他的答案是这样的。
<img src="https://pic3.zhimg.com/50/v2-cf726dcdabded7b9539955f2250fa916_hd.png"data-rawwidth="300" data-rawheight="231"class="content_image" width="300">
在这种情况下,小明知道了每种颜色小球的比例,比如橙色占比二分之一,如果我猜橙色,很有可能第一次就猜中了。所以,根据策略2,1/2的概率是橙色球,小明需要猜一次,1/4的概率是紫色球,小明需要猜两次,1/8的概率是蓝色球,小明需要猜三次,1/8的概率是青色球,小明需要猜三次,所以小明预期的猜题次数为:
H = 1/2 * 1 + 1/4 * 2 + 1/8 * 3 + 1/8 * 3= 1.75
题目3:其实,爸爸只想让小明意识到自己的错误,并不是真的想罚他,所以拿来一个箱子,跟小明说:里面的球都是橙色,现在我从中拿出一个,你猜我手中的球是什么颜色?
最强王者怎么可能不知道,肯定是橙色,小明需要猜0次。
上面三个题目表现出这样一种现象:针对特定概率为p的小球,需要猜球的次数 = ,例如题目2中,1/4是紫色球, = 2 次,1/8是蓝色球, = 3次。那么,针对整个整体,预期的猜题次数为: ,这就是信息熵,上面三个题目的预期猜球次数都是由这个公式计算而来,第一题的信息熵为2,第二题的信息熵为1.75,最三题的信息熵为1 * = 0 。那么信息熵代表着什么含义呢?
信息熵代表的是随机变量或整个系统的不确定性,熵越大,随机变量或系统的不确定性就越大。上面题目1的熵 > 题目2的熵 > 题目3的熵。在题目1中,小明对整个系统一无所知,只能假设所有的情况出现的概率都是均等的,此时的熵是最大的。题目2中,小明知道了橙色小球出现的概率是1/2及其他小球各自出现的概率,说明小明对这个系统有一定的了解,所以系统的不确定性自然会降低,所以熵小于2。题目3中,小明已经知道箱子中肯定是橙色球,爸爸手中的球肯定是橙色的,因而整个系统的不确定性为0,也就是熵为0。所以,在什么都不知道的情况下,熵会最大,针对上面的题目1~~题目3,这个最大值是2,除此之外,其余的任何一种情况,熵都会比2小。
所以,每一个系统都会有一个真实的概率分布,也叫真实分布,题目1的真实分布为(1/4,1/4,1/4,1/4),题目2的真实分布为(1/2,1/4,1/8,1/8),而根据真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性,而这个代价大小就是信息熵,记住,信息熵衡量了系统的不确定性,而我们要消除这个不确定性,所要付出的【最小努力】(猜题次数、编码长度等)的大小就是信息熵。具体来讲,题目1只需要猜两次就能确定任何一个小球的颜色,题目2只需要猜测1.75次就能确定任何一个小球的颜色。
现在回到题目2,假设小明只是钻石段位而已,智商没王者那么高,他使用了策略1,即
<img src="https://pic2.zhimg.com/50/v2-97e76bd3402b6d765bfc1934d4c75f75_hd.png"data-rawwidth="300" data-rawheight="213"class="content_image" width="300">
爸爸已经告诉小明这些小球的真实分布是(1/2,1/4, 1/8,1/8),但小明所选择的策略却认为所有的小球出现的概率相同,相当于忽略了爸爸告诉小明关于箱子中各小球的真实分布,而仍旧认为所有小球出现的概率是一样的,认为小球的分布为(1/4,1/4,1/4,1/4),这个分布就是非真实分布。此时,小明猜中任何一种颜色的小球都需要猜两次,即1/2 * 2 + 1/4 * 2 + 1/8 * 2 + 1/8 * 2 = 2。
很明显,针对题目2,使用策略1是一个坏的选择,因为需要猜题的次数增加了,从1.75变成了2,小明少玩了1.75的王者荣耀呢。因此,当我们知道根据系统的真实分布制定最优策略去消除系统的不确定性时,我们所付出的努力是最小的,但并不是每个人都和最强王者一样聪明,我们也许会使用其他的策略(非真实分布)去消除系统的不确定性,就好比如我将策略1用于题目2(原来这就是我在白银的原因),那么,当我们使用非最优策略消除系统的不确定性,所需要付出的努力的大小我们该如何去衡量呢?
这就需要引入交叉熵,其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
正式的讲,交叉熵的公式为: ,其中 表示真实分布, 表示非真实分布。例如上面所讲的将策略1用于题目2,真实分布 , 非真实分布 ,交叉熵为 ,比最优策略的1.75来得大。
因此,交叉熵越低,这个策略就越好,最低的交叉熵也就是使用了真实分布所计算出来的信息熵,因为此时 ,交叉熵 = 信息熵。
这也是为什么在机器学习中的分类算法中,我们总是最小化交叉熵,因为交叉熵越低,就证明由算法所产生的策略最接近最优策略,也间接证明我们算法所算出的非真实分布越接近真实分布。
最后,我们如何去衡量不同策略之间的差异呢?这就需要用到相对熵,其用来衡量两个取值为正的函数或概率分布之间的差异,即:
KL(f(x) || g(x)) =
现在,假设我们想知道某个策略和最优策略之间的差异,我们就可以用相对熵来衡量这两者之间的差异。即,相对熵 = 某个策略的交叉熵 - 信息熵(根据系统真实分布计算而得的信息熵,为最优策略),公式如下:
KL(p || q) = H(p,q) - H(p) =
所以将策略1用于题目2,所产生的相对熵为2 -1.75 = 0.25.
参考:
《数学之美》吴军
还有,小明同学,我帮你分析得这么清楚,快带我上王者。
还有:::
作者:Noriko Oshima
链接:https://www.zhihu.com/question/41252833/answer/108777563
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
熵的本质是香农信息量( )的期望。
现有关于样本集的2个概率分布p和q,其中p为真实分布,q非真实分布。按照真实分布p来衡量识别一个样本的所需要的编码长度的期望(即平均编码长度)为:H(p)= 。如果使用错误分布q来表示来自真实分布p的平均编码长度,则应该是:H(p,q)= 。因为用q来编码的样本来自分布p,所以期望H(p,q)中概率是p(i)。H(p,q)我们称之为“交叉熵”。
比如含有4个字母(A,B,C,D)的数据集中,真实分布p=(1/2, 1/2, 0, 0),即A和B出现的概率均为1/2,C和D出现的概率都为0。计算H(p)为1,即只需要1位编码即可识别A和B。如果使用分布Q=(1/4, 1/4, 1/4, 1/4)来编码则得到H(p,q)=2,即需要2位编码来识别A和B(当然还有C和D,尽管C和D并不会出现,因为真实分布p中C和D出现的概率为0,这里就钦定概率为0的事件不会发生啦)。
可以看到上例中根据非真实分布q得到的平均编码长度H(p,q)大于根据真实分布p得到的平均编码长度H(p)。事实上,根据Gibbs' inequality可知,H(p,q)>=H(p)恒成立,当q为真实分布p时取等号。我们将由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为“相对熵”:D(p||q)=H(p,q)-H(p)= ,其又被称为KL散度(Kullback–Leiblerdivergence,KLD) Kullback–Leibler divergence。它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0。注意,KL散度的非对称性。
比如TD-IDF算法就可以理解为相对熵的应用:词频在整个语料库的分布与词频在具体文档中分布之间的差异性。
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
PS:通常“相对熵”也可称为“交叉熵”,因为真实分布p是固定的,D(p||q)由H(p,q)决定。当然也有特殊情况,彼时2者须区别对待。
4.EM算法和LMS算法:
LMS算法:
LMS(Least mean square)算法,即最小均方误差算法。由美国斯坦福大学的B Widrow和M E Hoff于1960年在研究自适应理论时提出,由于其容易实现而很快得到了广泛应用,成为自适应滤波的标准算法。
在滤波器优化设计中,采用某种最小代价函数或者某个性能指标来衡量滤波器的好坏,而最常用的指标就是均方误差,也把这种衡量滤波器好坏的方法叫做均方误差准则。用公式表示如下:
E{e2(n)}=E{[d(n)−y(n)]2}
其中,E{e2(n)}就是均方误差,d(n)表示滤波器输入x(n)时所期望得到的响应或者输出,y(n)表示输入x(n)经过滤波器后实际得到的滤波器的输出,e(n)表示输入x(n)时,滤波器的期望响应和实际输出之间的误差。
将y(n)表示成抽头权值输入向量x(n)和抽头权值向量h(n)内积的形式,然后代入上式中,可知上式是以h(n)为多维自变量的函数,由于自变量是多维的,所以该函数对应图形是一个超抛物面(可以想象成碗的样子)且是衡正的,该超抛物面就是误差性能曲面。超抛物面有一个总体的最小值,该最小值就是最小均方误差。如前面所述,均方误差是衡量滤波器好坏的一个常用指标。当均方误差达到最小值时,该滤波器性能达到最优,即误差性能曲面上取值为最小的点对应的坐标就是最优滤波器系数向量(即最期望的滤波器抽头权值向量)。
EM算法:
从最大似然到EM算法浅解
机器学习十大算法之一:EM算法。能评得上十大之一,让人听起来觉得挺NB的。什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题。神为什么是神,因为神能做很多人做不了的事。那么EM算法能解决什么问题呢?或者说EM算法是因为什么而来到这个世界上,还吸引了那么多世人的目光。
我希望自己能通俗地把它理解或者说明白,但是,EM这个问题感觉真的不太好用通俗的语言去说明白,因为它很简单,又很复杂。简单在于它的思想,简单在于其仅包含了两个步骤就能完成强大的功能,复杂在于它的数学推理涉及到比较繁杂的概率公式等。如果只讲简单的,就丢失了EM算法的精髓,如果只讲数学推理,又过于枯燥和生涩,但另一方面,想把两者结合起来也不是件容易的事。所以,我也没法期待我能把它讲得怎样。希望各位不吝指导。
一、最大似然
扯了太多,得入正题了。假设我们遇到的是下面这样的问题:
假设我们需要调查我们学校的男生和女生的身高分布。你怎么做啊?你说那么多人不可能一个一个去问吧,肯定是抽样了。假设你在校园里随便地活捉了100个男生和100个女生。他们共200个人(也就是200个身高的样本数据,为了方便表示,下面,我说“人”的意思就是对应的身高)都在教室里面了。那下一步怎么办啊?你开始喊:“男的左边,女的右边,其他的站中间!”。然后你就先统计抽样得到的100个男生的身高。假设他们的身高是服从高斯分布的。但是这个分布的均值u和方差∂2我们不知道,这两个参数就是我们要估计的。记作θ=[u, ∂]T。
用数学的语言来说就是:在学校那么多男生(身高)中,我们独立地按照概率密度p(x|θ)抽取100了个(身高),组成样本集X,我们想通过样本集X来估计出未知参数θ。这里概率密度p(x|θ)我们知道了是高斯分布N(u,∂)的形式,其中的未知参数是θ=[u, ∂]T。抽到的样本集是X={x1,x2,…,xN},其中xi表示抽到的第i个人的身高,这里N就是100,表示抽到的样本个数。
由于每个样本都是独立地从p(x|θ)中抽取的,换句话说这100个男生中的任何一个,都是我随便捉的,从我的角度来看这些男生之间是没有关系的。那么,我从学校那么多男生中为什么就恰好抽到了这100个人呢?抽到这100个人的概率是多少呢?因为这些男生(的身高)是服从同一个高斯分布p(x|θ)的。那么我抽到男生A(的身高)的概率是p(xA|θ),抽到男生B的概率是p(xB|θ),那因为他们是独立的,所以很明显,我同时抽到男生A和男生B的概率是p(xA|θ)* p(xB|θ),同理,我同时抽到这100个男生的概率就是他们各自概率的乘积了。用数学家的口吻说就是从分布是p(x|θ)的总体样本中抽取到这100个样本的概率,也就是样本集X中各个样本的联合概率,用下式表示:
这个概率反映了,在概率密度函数的参数是θ时,得到X这组样本的概率。因为这里X是已知的,也就是说我抽取到的这100个人的身高可以测出来,也就是已知的了。而θ是未知了,则上面这个公式只有θ是未知数,所以它是θ的函数。这个函数放映的是在不同的参数θ取值下,取得当前这个样本集的可能性,因此称为参数θ相对于样本集X的似然函数(likehood function)。记为L(θ)。
这里出现了一个概念,似然函数。还记得我们的目标吗?我们需要在已经抽到这一组样本X的条件下,估计参数θ的值。怎么估计呢?似然函数有啥用呢?那咱们先来了解下似然的概念。
直接举个例子:
某位同学与一位猎人一起外出打猎,一只野兔从前方窜过。只听一声枪响,野兔应声到下,如果要你推测,这一发命中的子弹是谁打的?你就会想,只发一枪便打中,由于猎人命中的概率一般大于这位同学命中的概率,看来这一枪是猎人射中的。
这个例子所作的推断就体现了极大似然法的基本思想。
再例如:下课了,一群男女同学分别去厕所了。然后,你闲着无聊,想知道课间是男生上厕所的人多还是女生上厕所的人比较多,然后你就跑去蹲在男厕和女厕的门口。蹲了五分钟,突然一个美女走出来,你狂喜,跑过来告诉我,课间女生上厕所的人比较多,你要不相信你可以进去数数。呵呵,我才没那么蠢跑进去数呢,到时还不得上头条。我问你是怎么知道的。你说:“5分钟了,出来的是女生,女生啊,那么女生出来的概率肯定是最大的了,或者说比男生要大,那么女厕所的人肯定比男厕所的人多”。看到了没,你已经运用最大似然估计了。你通过观察到女生先出来,那么什么情况下,女生会先出来呢?肯定是女生出来的概率最大的时候了,那什么时候女生出来的概率最大啊,那肯定是女厕所比男厕所多人的时候了,这个就是你估计到的参数了。
从上面这两个例子,你得到了什么结论?
回到男生身高那个例子。在学校那么男生中,我一抽就抽到这100个男生(表示身高),而不是其他人,那是不是表示在整个学校中,这100个人(的身高)出现的概率最大啊。那么这个概率怎么表示?哦,就是上面那个似然函数L(θ)。所以,我们就只需要找到一个参数θ,其对应的似然函数L(θ)最大,也就是说抽到这100个男生(的身高)概率最大。这个叫做θ的最大似然估计量,记为:
有时,可以看到L(θ)是连乘的,所以为了便于分析,还可以定义对数似然函数,将其变成连加的:
好了,现在我们知道了,要求θ,只需要使θ的似然函数L(θ)极大化,然后极大值对应的θ就是我们的估计。这里就回到了求最值的问题了。怎么求一个函数的最值?当然是求导,然后让导数为0,那么解这个方程得到的θ就是了(当然,前提是函数L(θ)连续可微)。那如果θ是包含多个参数的向量那怎么处理啊?当然是求L(θ)对所有参数的偏导数,也就是梯度了,那么n个未知的参数,就有n个方程,方程组的解就是似然函数的极值点了,当然就得到这n个参数了。
最大似然估计你可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而最大似然估计是已经知道了结果,然后寻求使该结果出现的可能性最大的条件,以此作为估计值。比如,如果其他条件一定的话,抽烟者发生肺癌的危险时不抽烟者的5倍,那么如果现在我已经知道有个人是肺癌,我想问你这个人抽烟还是不抽烟。你怎么判断?你可能对这个人一无所知,你所知道的只有一件事,那就是抽烟更容易发生肺癌,那么你会猜测这个人不抽烟吗?我相信你更有可能会说,这个人抽烟。为什么?这就是“最大可能”,我只能说他“最有可能”是抽烟的,“他是抽烟的”这一估计值才是“最有可能”得到“肺癌”这样的结果。这就是最大似然估计。
好了,极大似然估计就讲到这,总结一下:
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一。说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
求最大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求;
二、EM算法
好了,重新回到上面那个身高分布估计的问题。现在,通过抽取得到的那100个男生的身高和已知的其身高服从高斯分布,我们通过最大化其似然函数,就可以得到了对应高斯分布的参数θ=[u, ∂]T了。那么,对于我们学校的女生的身高分布也可以用同样的方法得到了。
再回到例子本身,如果没有“男的左边,女的右边,其他的站中间!”这个步骤,或者说我抽到这200个人中,某些男生和某些女生一见钟情,已经好上了,纠缠起来了。咱们也不想那么残忍,硬把他们拉扯开。那现在这200个人已经混到一起了,这时候,你从这200个人(的身高)里面随便给我指一个人(的身高),我都无法确定这个人(的身高)是男生(的身高)还是女生(的身高)。也就是说你不知道抽取的那200个人里面的每一个人到底是从男生的那个身高分布里面抽取的,还是女生的那个身高分布抽取的。用数学的语言就是,抽取得到的每个样本都不知道是从哪个分布抽取的。
这个时候,对于每一个样本或者你抽取到的人,就有两个东西需要猜测或者估计的了,一是这个人是男的还是女的?二是男生和女生对应的身高的高斯分布的参数是多少?
只有当我们知道了哪些人属于同一个高斯分布的时候,我们才能够对这个分布的参数作出靠谱的预测,例如刚开始的最大似然所说的,但现在两种高斯分布的人混在一块了,我们又不知道哪些人属于第一个高斯分布,哪些属于第二个,所以就没法估计这两个分布的参数。反过来,只有当我们对这两个分布的参数作出了准确的估计的时候,才能知道到底哪些人属于第一个分布,那些人属于第二个分布。
这就成了一个先有鸡还是先有蛋的问题了。鸡说,没有我,谁把你生出来的啊。蛋不服,说,没有我,你从哪蹦出来啊。(呵呵,这是一个哲学问题。当然了,后来科学家说先有蛋,因为鸡蛋是鸟蛋进化的)。为了解决这个你依赖我,我依赖你的循环依赖问题,总得有一方要先打破僵局,说,不管了,我先随便整一个值出来,看你怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终就会收敛到一个解。这就是EM算法的基本思想了。
不知道大家能否理解其中的思想,我再来啰嗦一下。其实这个思想无处在不啊。
例如,小时候,老妈给一大袋糖果给你,叫你和你姐姐等分,然后你懒得去点糖果的个数,所以你也就不知道每个人到底该分多少个。咱们一般怎么做呢?先把一袋糖果目测的分为两袋,然后把两袋糖果拿在左右手,看哪个重,如果右手重,那很明显右手这代糖果多了,然后你再在右手这袋糖果中抓一把放到左手这袋,然后再感受下哪个重,然后再从重的那袋抓一小把放进轻的那一袋,继续下去,直到你感觉两袋糖果差不多相等了为止。呵呵,然后为了体现公平,你还让你姐姐先选了。
EM算法就是这样,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM的意思是“Expectation Maximization”,在我们上面这个问题里面,我们是先随便猜一下男生(身高)的正态分布的参数:如均值和方差是多少。例如男生的均值是1米7,方差是0.1米(当然了,刚开始肯定没那么准),然后计算出每个人更可能属于第一个还是第二个正态分布中的(例如,这个人的身高是1米8,那很明显,他最大可能属于男生的那个分布),这个是属于Expectation一步。有了每个人的归属,或者说我们已经大概地按上面的方法将这200个人分为男生和女生两部分,我们就可以根据之前说的最大似然那样,通过这些被大概分为男生的n个人来重新估计第一个分布的参数,女生的那个分布同样方法重新估计。这个是Maximization。然后,当我们更新了这两个分布的时候,每一个属于这两个分布的概率又变了,那么我们就再需要调整E步……如此往复,直到参数基本不再发生变化为止。
这里把每个人(样本)的完整描述看做是三元组yi={xi,zi1,zi2},其中,xi是第i个样本的观测值,也就是对应的这个人的身高,是可以观测到的值。zi1和zi2表示男生和女生这两个高斯分布中哪个被用来产生值xi,就是说这两个值标记这个人到底是男生还是女生(的身高分布产生的)。这两个值我们是不知道的,是隐含变量。确切的说,zij在xi由第j个高斯分布产生时值为1,否则为0。例如一个样本的观测值为1.8,然后他来自男生的那个高斯分布,那么我们可以将这个样本表示为{1.8, 1, 0}。如果zi1和zi2的值已知,也就是说每个人我已经标记为男生或者女生了,那么我们就可以利用上面说的最大似然算法来估计他们各自高斯分布的参数。但是它们未知,因此我们只能用EM算法。
咱们现在不是因为那个恶心的隐含变量(抽取得到的每个样本都不知道是从哪个分布抽取的)使得本来简单的可以求解的问题变复杂了,求解不了吗。那怎么办呢?人类解决问题的思路都是想能否把复杂的问题简单化。好,那么现在把这个复杂的问题逆回来,我假设已经知道这个隐含变量了,哎,那么求解那个分布的参数是不是很容易了,直接按上面说的最大似然估计就好了。那你就问我了,这个隐含变量是未知的,你怎么就来一个假设说已知呢?你这种假设是没有根据的。呵呵,我知道,所以我们可以先给这个给分布弄一个初始值,然后求这个隐含变量的期望,当成是这个隐含变量的已知值,那么现在就可以用最大似然求解那个分布的参数了吧,那假设这个参数比之前的那个随机的参数要好,它更能表达真实的分布,那么我们再通过这个参数确定的分布去求这个隐含变量的期望,然后再最大化,得到另一个更优的参数,……迭代,就能得到一个皆大欢喜的结果了。
这时候你就不服了,说你老迭代迭代的,你咋知道新的参数的估计就比原来的好啊?为什么这种方法行得通呢?有没有失效的时候呢?什么时候失效呢?用到这个方法需要注意什么问题呢?呵呵,一下子抛出那么多问题,搞得我适应不过来了,不过这证明了你有很好的搞研究的潜质啊。呵呵,其实这些问题就是数学家需要解决的问题。在数学上是可以稳当的证明的或者得出结论的。那咱们用数学来把上面的问题重新描述下。(在这里可以知道,不管多么复杂或者简单的物理世界的思想,都需要通过数学工具进行建模抽象才得以使用并发挥其强大的作用,而且,这里面蕴含的数学往往能带给你更多想象不到的东西,这就是数学的精妙所在啊)
三、EM算法推导
假设我们有一个样本集{x(1),…,x(m)},包含m个独立的样本。但每个样本i对应的类别z(i)是未知的(相当于聚类),也即隐含变量。故我们需要估计概率模型p(x,z)的参数θ,但是由于里面包含隐含变量z,所以很难用最大似然求解,但如果z知道了,那我们就很容易求解了。
对于参数估计,我们本质上还是想获得一个使似然函数最大化的那个参数θ,现在与最大似然不同的只是似然函数式中多了一个未知的变量z,见下式(1)。也就是说我们的目标是找到适合的θ和z让L(θ)最大。那我们也许会想,你就是多了一个未知的变量而已啊,我也可以分别对未知的θ和z分别求偏导,再令其等于0,求解出来不也一样吗?
本质上我们是需要最大化(1)式(对(1)式,我们回忆下联合概率密度下某个变量的边缘概率密度函数的求解,注意这里z也是随机变量。对每一个样本i的所有可能类别z求等式右边的联合概率密度函数和,也就得到等式左边为随机变量x的边缘概率密度),也就是似然函数,但是可以看到里面有“和的对数”,求导后形式会非常复杂(自己可以想象下log(f1(x)+ f2(x)+ f3(x)+…)复合函数的求导),所以很难求解得到未知参数z和θ。那OK,我们可否对(1)式做一些改变呢?我们看(2)式,(2)式只是分子分母同乘以一个相等的函数,还是有“和的对数”啊,还是求解不了,那为什么要这么做呢?咱们先不管,看(3)式,发现(3)式变成了“对数的和”,那这样求导就容易了。我们注意点,还发现等号变成了不等号,为什么能这么变呢?这就是Jensen不等式的大显神威的地方。
Jensen不等式:
设f是定义域为实数的函数,如果对于所有的实数x。如果对于所有的实数x,f(x)的二次导数大于等于0,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的,那么f是凸函数。如果只大于0,不等于0,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么:E[f(X)]>=f(E[X])
特别地,如果f是严格凸函数,当且仅当X是常量时,上式取等号。
如果用图表示会很清晰:
图中,实线f是凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。(就像掷硬币一样)。X的期望值就是a和b的中值了,图中可以看到E[f(X)]>=f(E[X])成立。
当f是(严格)凹函数当且仅当-f是(严格)凸函数。
Jensen不等式应用于凹函数时,不等号方向反向。
回到公式(2),因为f(x)=log x为凹函数(其二次导数为-1/x2<0)。
(2)式中的期望,(考虑到E(X)=∑x*p(x),f(X)是X的函数,则E(f(X))=∑f(x)*p(x)),又,所以就可以得到公式(3)的不等式了(若不明白,请拿起笔,呵呵):
OK,到这里,现在式(3)就容易地求导了,但是式(2)和式(3)是不等号啊,式(2)的最大值不是式(3)的最大值啊,而我们想得到式(2)的最大值,那怎么办呢?
现在我们就需要一点想象力了,上面的式(2)和式(3)不等式可以写成:似然函数L(θ)>=J(z,Q),那么我们可以通过不断的最大化这个下界J,来使得L(θ)不断提高,最终达到它的最大值。
见上图,我们固定θ,调整Q(z)使下界J(z,Q)上升至与L(θ)在此点θ处相等(绿色曲线到蓝色曲线),然后固定Q(z),调整θ使下界J(z,Q)达到最大值(θt到θt+1),然后再固定θ,调整Q(z)……直到收敛到似然函数L(θ)的最大值处的θ*。这里有两个问题:什么时候下界J(z,Q)与L(θ)在此点θ处相等?为什么一定会收敛?
首先第一个问题,在Jensen不等式中说到,当自变量X是常数的时候,等式成立。而在这里,即:
再推导下,由于(因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),则:
至此,我们推出了在固定参数θ后,使下界拉升的Q(z)的计算公式就是后验概率,解决了Q(z)如何选择的问题。这一步就是E步,建立L(θ)的下界。接下来的M步,就是在给定Q(z)后,调整θ,去极大化L(θ)的下界J(在固定Q(z)后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
EM算法(Expectation-maximization):
期望最大算法是一种从不完全数据或有数据丢失的数据集(存在隐含变量)中求解概率模型参数的最大似然估计方法。
EM的算法流程:
初始化分布参数θ;
重复以下步骤直到收敛:
E步骤:根据参数初始值或上一次迭代的模型参数来计算出隐性变量的后验概率,其实就是隐性变量的期望。作为隐藏变量的现估计值:
M步骤:将似然函数最大化以获得新的参数值:
这个不断的迭代,就可以得到使似然函数L(θ)最大化的参数θ了。那就得回答刚才的第二个问题了,它会收敛吗?
感性的说,因为下界不断提高,所以极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。理性分析的话,就会得到下面的东西:
具体如何证明的,看推导过程参考:Andrew Ng《The EM algorithm》
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
四、EM算法另一种理解
坐标上升法(Coordinate ascent):
图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
这犹如在x-y坐标系中找一个曲线的极值,然而曲线函数不能直接求导,因此什么梯度下降方法就不适用了。但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。对应到EM上,E步:固定θ,优化Q;M步:固定Q,优化θ;交替将极值推向最大。
五、EM的应用
EM算法有很多的应用,最广泛的就是GMM混合高斯模型、聚类、HMM等等。具体可以参考JerryLead的cnblog中的Machine Learning专栏:
混合高斯模型(Mixtures of Gaussians)和EM算法
K-means聚类算法
5.正则化:
tensorflow学习笔记(三十八):损失函数加上正则项
原创 2017年04月20日 16:02:32
· 5189
tensorflow Regularizers
在损失函数上加上正则项是防止过拟合的一个重要方法,下面介绍如何在TensorFlow中使用正则项.
tensorflow中对参数使用正则项分为两步:
1. 创建一个正则方法(函数/对象)
2. 将这个正则方法(函数/对象),应用到参数上
如何创建一个正则方法函数
tf.contrib.layers.l1_regularizer(scale,scope=None)
返回一个用来执行L1正则化的函数,函数的签名是func(weights).
参数:
· scale: 正则项的系数.
· scope: 可选的scopename
tf.contrib.layers.l2_regularizer(scale,scope=None)
返回一个执行L2正则化的函数.
tf.contrib.layers.sum_regularizer(regularizer_list,scope=None)
返回一个可以执行多种(个)正则化的函数.意思是,创建一个正则化方法,这个方法是多个正则化方法的混合体.
参数:
regularizer_list: regulizer的列表
已经知道如何创建正则化方法了,下面要说明的就是如何将正则化方法应用到参数上
应用正则化方法到参数上
tf.contrib.layers.apply_regularization(regularizer,weights_list=None)
先看参数
· regularizer:就是我们上一步创建的正则化方法
· weights_list: 想要执行正则化方法的参数列表,如果为None的话,就取GraphKeys.WEIGHTS中的weights.
函数返回一个标量Tensor,同时,这个标量Tensor也会保存到GraphKeys.REGULARIZATION_LOSSES中.这个Tensor保存了计算正则项损失的方法.
tensorflow中的Tensor是保存了计算这个值的路径(方法),当我们run的时候,tensorflow后端就通过路径计算出Tensor对应的值
现在,我们只需将这个正则项损失加到我们的损失函数上就可以了.
如果是自己手动定义weight的话,需要手动将weight保存到GraphKeys.WEIGHTS中,但是如果使用layer的话,就不用这么麻烦了,别人已经帮你考虑好了.(最好自己验证一下tf.GraphKeys.WEIGHTS中是否包含了所有的weights,防止被坑)
其它
在使用tf.get_variable()和tf.variable_scope()的时候,你会发现,它们俩中有regularizer形参.如果传入这个参数的话,那么variable_scope内的weights的正则化损失,或者weights的正则化损失就会被添加到GraphKeys.REGULARIZATION_LOSSES中.
示例:
importtensorflowastf
fromtensorflow.contribimportlayers
regularizer = layers.l1_regularizer(0.1)
withtf.variable_scope('var', initializer=tf.random_normal_initializer(),
regularizer=regularizer):weight = tf.get_variable('weight', shape=[8], initializer=tf.ones_initializer())
withtf.variable_scope('var2', initializer=tf.random_normal_initializer(),
regularizer=regularizer):weight2 = tf.get_variable('weight', shape=[8], initializer=tf.ones_initializer())
regularization_loss = tf.reduce_sum(tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
6.无人监督学习与监督学习
作者:王丰
链接:https://www.zhihu.com/question/23194489/answer/25028661
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这个问题可以回答得很简单:是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习,没标签则为无监督学习。
但根据知乎惯例,答案还是要继续扩展的。
首先看什么是学习(learning)?一个成语就可概括:举一反三。此处以高考为例,高考的题目在上考场前我们未必做过,但在高中三年我们做过很多很多题目,懂解题方法,因此考场上面对陌生问题也可以算出答案。机器学习的思路也类似:我们能不能利用一些训练数据(已经做过的题),使机器能够利用它们(解题方法)分析未知数据(高考的题目)?
最简单也最普遍的一类机器学习算法就是分类(classification)。对于分类,输入的训练数据有特征(feature),有标签(label)。所谓的学习,其本质就是找到特征和标签间的关系(mapping)。这样当有特征而无标签的未知数据输入时,我们就可以通过已有的关系得到未知数据标签。
在上述的分类过程中,如果所有训练数据都有标签,则为有监督学习(supervised learning)。如果数据没有标签,显然就是无监督学习(unsupervisedlearning)了,也即聚类(clustering)。
目前分类算法的效果还是不错的,但相对来讲,聚类算法就有些惨不忍睹了。确实,无监督学习本身的特点使其难以得到如分类一样近乎完美的结果。这也正如我们在高中做题,答案(标签)是非常重要的,假设两个完全相同的人进入高中,一个正常学习,另一人做的所有题目都没有答案,那么想必第一个人高考会发挥更好,第二个人会发疯。
这时各位可能要问,既然分类如此之好,聚类如此之不靠谱,那为何我们还可以容忍聚类的存在?因为在实际应用中,标签的获取常常需要极大的人工工作量,有时甚至非常困难。例如在自然语言处理(NLP)中,Penn Chinese Treebank在2年里只完成了4000句话的标签……
<imgsrc="https://pic1.zhimg.com/50/4b92820e4df9ab2ed4d56243d981cdcc_hd.jpg"data-rawwidth="302" data-rawheight="237"class="content_image" width="302">
这时有人可能会想,难道有监督学习和无监督学习就是非黑即白的关系吗?有没有灰呢?Good idea。灰是存在的。二者的中间带就是半监督学习(semi-supervisedlearning)。对于半监督学习,其训练数据的一部分是有标签的,另一部分没有标签,而没标签数据的数量常常极大于有标签数据数量(这也是符合现实情况的)。隐藏在半监督学习下的基本规律在于:数据的分布必然不是完全随机的,通过一些有标签数据的局部特征,以及更多没标签数据的整体分布,就可以得到可以接受甚至是非常好的分类结果。(此处大量忽略细节)
因此,learning家族的整体构造是这样的:
有监督学习(分类,回归)
↕
半监督学习(分类,回归),transductive learning(分类,回归)
↕
半监督聚类(有标签数据的标签不是确定的,类似于:肯定不是xxx,很可能是yyy)
↕
无监督学习(聚类)
参考文献:
[1] 各种教材
[2] Semi-Supervised Learning Tutorial, http://pages.cs.wisc.edu/~jerryzhu/pub/sslicml07.pdf
另附:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
作者:赵杨
链接:https://www.zhihu.com/question/23194489/answer/75555668
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
机器(计算机)学习分为有监督和无监督两个类,基本上可以从他们会不会得到一个特定的标签(label)输出来区分。
这里标签指的是用来描述某一个物体属性的话语。比如人类有两种,我们要区分这两种人,就根据生理特征,分别对两种人打上标签,一种是[男人],另一种是[女人]。
有监督学习(Supervised Learning):
先来问题化地解释一下有监督学习:你有一些问题和他们的答案,你要做的有监督学习就是学习这些已经知道答案的问题。然后你就具备了经验了,这就是学习的成果。然后在你接受到一个新的不知道答案的问题的时候,你可以根据学习得到的经验,得出这个新问题的答案。(试想一下高考不正是这样,好的学习器就能有更强的做题能力,考好的分数,上好的大学.....)。
我们有一个样本数据集,如果对于每一个单一的数据根据它的特征向量我们要去判断它的标签(算法的输出值),那么就是有监督学习。通俗的说,有监督学习就是比无监督学习多了一个可以表达这个数据特质的标签。
我们再来看有监督学习,分为两个大类:
1.回归分析(RegressionAnalysis):回归分析,其数据集是给定一个函数和它的一些坐标点,然后通过回归分析的算法,来估计原函数的模型,求出一个最符合这些已知数据集的函数解析式。然后它就可以用来预估其它未知输出的数据了,你输入一个自变量它就会根据这个模型解析式输出一个因变量,这些自变量就是特征向量,因变量就是标签。而且标签的值是建立在连续范围的。 2.分类(Classification):其数据集,由特征向量和它们的标签组成,当你学习了这些数据之后,给你一个只知道特征向量不知道标签的数据,让你求它的标签是哪一个?其和回归的主要区别就是输出结果是离散的还是连续的。
无监督学习(Unsupervised Learning):
“Because we don't give it the answer, it's unsupervised learning”。
还是先来问题化地解释一下无监督学习:我们有一些问题,但是不知道答案,我们要做的无监督学习就是按照他们的性质把他们自动地分成很多组,每组的问题是具有类似性质的(比如数学问题会聚集在一组,英语问题会聚集在一组,物理........)。
所有数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,本质是一个相似的类型的会聚集在一起。把这些没有标签的数据分成一个一个组合,就是聚类(Clustering)。比如Google新闻,每天会搜集大量的新闻,然后把它们全部聚类,就会自动分成几十个不同的组(比如娱乐,科技,政治......),每个组内新闻都具有相似的内容结构。
无监督学习还有一个典型的例子就是鸡尾酒会问题(声音的分离),在这个酒会上有两种声音,被两个不同的麦克风在不同的地方接收到,而可以利用无监督学习来分离这两种不同的声音。注意到这里是无监督学习的原因是,事先并不知道这些声音中有哪些种类(这里的种类就是标签的意思)。
而且鸡尾酒问题的代码实现只要一行,如下:
<imgsrc="https://pic2.zhimg.com/50/7e068f0b467e9f928572937e39be1ae1_hd.png"data-rawwidth="1222" data-rawheight="52"class="origin_image zh-lightbox-thumb" width="1222"data-original="https://pic2.zhimg.com/7e068f0b467e9f928572937e39be1ae1_r.png">
[注]:内容参考吴恩达在Coursera上的机器学习课程。
定义wordembedding的维度::::
词向量,英文名叫WordEmbedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。
这一切,还得从onehot说起...
I. 五十步笑百步
onehot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,onehot就是给这六个字分别用一个0-1编码:
科[1,0,0,0,0,0]学[0,1,0,0,0,0]空[0,0,1,0,0,0]间[0,0,0,1,0,0]不[0,0,0,0,1,0]错[0,0,0,0,0,1]
那么,如果表示“科学”这个词,那么就可以用矩阵
(100000010000)
大家可能感觉到问题了,有多少个字,就得有多少维向量,假如有1万字,那么每个字向量就是1万维(常用的字可能不多,几千个左右,但是按照词的概念来看,常用的词可能就有十几万了)。于是就出来了连续向量表示,比如用100维的实数向量来表示一个字,这样就大大降低了维度,降低了过拟合的风险,等等。初学者是这样说的,不少专家也是这样说的。
然而事实是:放屁!放屁!放屁!重要的事情说三遍。
给大家出道题大家给明白了:给两个任意实数型的100阶矩阵让你算它们的乘积,可能没几个人能够算出来;可是,给你两个1000阶的矩阵,但其中一个是one hot型(每一行只有一个元素为1,其它都是0)的矩阵,让你相乘,你很快就能算出来了,不信你就试试。
看出问题来了吧?onehot矩阵是庞大,但是人家好算,你那个什么鬼实数矩阵,虽然维度小,但是算起来还麻烦呢(虽然这点计算量对于计算机来说算不了什么)!当然,更深刻的原因还在下面。
II. 似非而是
我们真的去算一次
(100000010000)(w11w12w13w21w22w23w31w32w33w41w42w43w51w52w53w61w62w63)=(w11w12w13w21w22w23)
左边的形式表明,这是一个以2x6的one hot矩阵的为输入、中间层节点数为3的全连接神经网络层,但你看右边,不就相当于在wij这个矩阵中,取出第1、2行,这不是跟所谓的字向量的查表(从表中找出对应字的向量)是一样的吗?事实上,正是如此!这就是所谓的Embedding层,Embedding层就是以onehot为输入、中间层节点为字向量维数的全连接层!而这个全连接层的参数,就是一个“字向量表”!从这个层面来看,字向量没有做任何事情!它就是one hot,别再嘲笑one hot的问题了,字向量就是onehot的全连接层的参数!
那么,字向量、词向量这些,真的没有任何创新了吗?有的,从运算上来看,基本上就是通过研究发现,onehot型的矩阵相乘,就像是相当于查表,于是它直接用查表作为操作,而不写成矩阵再运算,这大大降低了运算量。再次强调,降低了运算量不是因为词向量的出现,而是因为把one hot型的矩阵运算简化为了查表操作。这是运算层面的。思想层面的,就是它得到了这个全连接层的参数之后,直接用这个全连接层的参数作为特征,或者说,用这个全连接层的参数作为字、词的表示,从而得到了字、词向量,最后还发现了一些有趣的性质,比如向量的夹角余弦能够在某种程度上表示字、词的相似度。
对了,有人诟病,Word2Vec只是一个三层的模型,算不上“深度”学习,事实上,算上one hot的全连接层,就有4层了,也基本说得上深度了。
III. 从何而来
等等,如果把字向量当做全连接层的参数(这位读者,我得纠正,不是“当做”,它本来就是),那么这个参数你还没告诉我怎么得到呢!答案是:我也不知道怎么得来呀。神经网络的参数不是取决你的任务吗?你的任务应该问你自己呀,怎么问我来了?你说Word2Vec是无监督的?那我再来澄清一下。
严格来讲,神经网络都是有监督的,而Word2Vec之类的模型,准确来说应该是“自监督”的,它事实上训练了一个语言模型,通过语言模型来获取词向量。所谓语言模型,就是通过前n个字预测下一个字的概率,就是一个多分类器而已,我们输入one hot,然后连接一个全连接层,然后再连接若干个层,最后接一个softmax分类器,就可以得到语言模型了,然后将大批量文本输入训练就行了,最后得到第一个全连接层的参数,就是字、词向量表,当然,Word2Vec还做了大量的简化,但是那都是在语言模型本身做的简化,它的第一层还是全连接层,全连接层的参数就是字、词向量表。
这样看,问题就比较简单了,我也没必要一定要用语言模型来训练向量吧?对呀,你可以用其他任务,比如文本情感分类任务来有监督训练。因为都已经说了,就是一个全连接层而已,后面接什么,当然自己决定。当然,由于标签数据一般不会很多,因此这样容易过拟合,因此一般先用大规模语料无监督训练字、词向量,降低过拟合风险。注意,降低过拟合风险的原因是可以使用无标签语料预训练词向量出来(无标签语料可以很大,语料足够大就不会有过拟合风险),跟词向量无关,词向量就是一层待训练参数,有什么本事降低过拟合风险?
最后,解释一下为什么这些字词向量会有一些性质,比如向量的夹角余弦、向量的欧氏距离都能在一定程度上反应字词之间的相似性?这是因为,我们在用语言模型无监督训练时,是开了窗口的,通过前n个字预测下一个字的概率,这个n就是窗口的大小,同一个窗口内的词语,会有相似的更新,这些更新会累积,而具有相似模式的词语就会把这些相似更新累积到可观的程度。我举个例子,“忐”、“忑”这两个字,几乎是连在一起用的,更新“忐”的同时,几乎也会更新“忑”,因此它们的更新几乎都是相同的,这样“忐”、“忑”的字向量必然几乎是一样的。“相似的模式”指的是在特定的语言任务中,它们是可替换的,比如在一般的泛化语料中,“我喜欢你”中的“喜欢”,以及一般语境下的“喜欢”,替换为“讨厌”后还是一个成立的句子,因此“喜欢”与“讨厌”必然具有相似的词向量,但如果词向量是通过情感分类任务训练的,那么“喜欢”与“讨厌”就会有截然不同的词向量
可以帮助理解的问题:“”
楼主你好,我没有用什么语言模型,就看了IMDB的例子代码。请问embedding的代码实现里one-hot乘的这个w字向量矩阵,是随机的一些数还是某个有语义的pre-define在keras里的向量阵?
· 第6层苏剑林 发表于 September 30th,2017
全连接层怎么做,它就怎么做,因为它就是一个全连接层:随机初始化,然后训练过程中更新
· 第7层全都是泡沫 发表于 October 7th, 2017
如果我输入的是token过得纯文本,然后网络输出是不同的类预测结果。
其中的embedding层没用像word2vec和glove的预训练词向量嵌入。
那么随机初始化的这些向量经过训练更新后能理解为是一种特殊的语义向量吗?
不用任何预训练的词向量嵌入,有道理吗?
我用pretrained emeddings的结果没有randominitialized embedding好,
但是random initialed很快就overfit了。
不是很明白,这是embedding的代码https://github.com/fchollet/keras/blob/master/keras/layers/embeddings.py#L11
或者我可以理解为训练更新后的weights可以作为一种词向量?
· 第8层苏剑林 发表于 October 7th, 2017
embedding层的本质就是onehot全连接,参数量很大,直接让它在训练过程中更新,自然是容易过拟合的。至于效果是不是一定会比pretrained的要好或者差,则得结合任务来看,不一定的。
至于你说的,随机初始化后经过训练得到的embedding,的确就是一种特殊的词向量了。事实上这跟word2vec的更新原理是一样的,只不过word2vec的更新目标(loss)不一样罢了。
最后,必须明确的是,使用pretrained的词向量,目的一般有两个(取其一):
1、如果在模型训练的时候,不微调词向量,那么就是为了获得标注数据集以外的泛化能力,因为无监督pretrained相对标注数据集来说,也许能补充很多标注集没有的词语;
2、如果在模型训练的时候,微调词向量(先固定词向量训练模型到饱和,然后降低学习率,放开词向量再训练),那么pretrained词向量的目的就是为了获得更好的初始化点。
上面我们提到,input word和output word都会被我们进行one-hot编码。仔细想一下,我们的输入被one-hot编码以后大多数维度上都是0(实际上仅有一个位置为1),所以这个向量相当稀疏,那么会造成什么结果呢。如果我们将一个1 x 10000的向量和10000 x 300的矩阵相乘,它会消耗相当大的计算资源,为了高效计算,它仅仅会选择矩阵中对应的向量中维度值为1的索引行(这句话很绕),看图就明白。
我们来看一下上图中的矩阵运算,左边分别是1 x 5和5 x 3的矩阵,结果应该是1 x 3的矩阵,按照矩阵乘法的规则,结果的第一行第一列元素为0 x 17 + 0 x 23 + 0 x 4 + 1 x 10 + 0 x 11 = 10,同理可得其余两个元素为12,19。如果10000个维度的矩阵采用这样的计算方式是十分低效的。
为了有效地进行计算,这种稀疏状态下不会进行矩阵乘法计算,可以看到矩阵的计算的结果实际上是矩阵对应的向量中值为1的索引,上面的例子中,左边向量中取值为1的对应维度为3(下标从0开始),那么计算结果就是矩阵的第3行(下标从0开始)—— [10, 12, 19],这样模型中的隐层权重矩阵便成了一个”查找表“(lookup table),进行矩阵计算时,直接去查输入向量中取值为1的维度下对应的那些权重值。隐层的输出就是每个输入单词的“嵌入词向量”。
7.MAP和MRR
MAP(Mean Average Precision):
单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。主集合的平均准确率(MAP)是每个主题的平均准确率的平均值。MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(rank越高),MAP就可能越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。”
NDCG(Normalized Discounted Cumulative Gain):
计算相对复杂。对于排在结位置n处的NDCG的计算公式如下图所示:
在MAP中,四个文档和query要么相关,要么不相关,也就是相关度非0即1。NDCG中改进了下,相关度分成从0到r的r+1的等级(r可设定)。当取r=5时,等级设定如下图所示:
(应该还有r=1那一级,原文档有误,不过这里不影响理解)
例如现在有一个query={abc},返回下图左列的Ranked List(URL),当假设用户的选择与排序结果无关(即每一级都等概率被选中),则生成的累计增益值如下图最右列所示:
考虑到一般情况下用户会优先点选排在前面的搜索结果,所以应该引入一个折算因子(discountingfactor): log(2)/log(1+rank)。这时将获得DCG值(Discounted Cumulative Gain)如下如所示:
最后,为了使不同等级上的搜索结果的得分值容易比较,需要将DCG值归一化的到NDCG值。操作如下图所示,首先计算理想返回结果List的DCG值:
然后用DCG/MaxDCG就得到NDCG值,如下图所示:
MRR(Mean Reciprocal Rank):
是把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。相对简单,举个例子:有3个query如下图所示:
(黑体为返回结果中最匹配的一项)
可计算这个系统的MRR值为:(1/3 + 1/2 + 1)/3= 11/18=0.61。
8.SVM支持向量机
作者:简之
链接:https://www.zhihu.com/question/21094489/answer/86273196
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么是SVM?
当然首先看一下wiki.
Support Vector Machines are learning models used forclassification: which individuals in a population belong where? So… how do SVMand the mysterious “kernel” work?
好吧,故事是这样子的:
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
<img src="https://pic2.zhimg.com/50/5aff2bcdbe23a8c764a32b1b5fb13b71_hd.png"data-rawwidth="300" data-rawheight="225"class="content_image" width="300">
于是大侠这样放,干的不错?
<imgsrc="https://pic2.zhimg.com/50/3dbf3ba8f940dfcdaf877de2d590ddd1_hd.png"data-rawwidth="300" data-rawheight="225"class="content_image" width="300">
然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
<imgsrc="https://pic4.zhimg.com/50/0b2d0b26ec99ee40fd14760350e957af_hd.png"data-rawwidth="300" data-rawheight="225"class="content_image" width="300">
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
<imgsrc="https://pic2.zhimg.com/50/4b9e8a8a87c7982c548505574c13dc05_hd.png"data-rawwidth="300" data-rawheight="225"class="content_image" width="300">
现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。
<img src="https://pic4.zhimg.com/50/7befaafc45763b9c4469abf245dc98cb_hd.png"data-rawwidth="300" data-rawheight="225"class="content_image" width="300">
然后,在SVM 工具箱中有另一个更加重要的trick。魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。
<img src="https://pic4.zhimg.com/50/558161d10d1f0ffd2d7f9a46767de587_hd.png"data-rawwidth="300" data-rawheight="225"class="content_image" width="300">
现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。<imgsrc="https://pic4.zhimg.com/50/55d7ad2a6e23579b17aec0c3c9135eb3_hd.png"data-rawwidth="300" data-rawheight="167"class="content_image" width="300">
现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。
<imgsrc="https://pic3.zhimg.com/50/e5d5185561a4d5369f36a9737fc849c6_hd.png"data-rawwidth="300" data-rawheight="225"class="content_image" width="300">
再之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
如何求解:https://www.zhihu.com/question/21094489
9联合概率分布
联合概率分布到底是什么意思?:
联合概率分布二维随机变量
设E是一个随机试验,它的样本空间是S={e}。设X=X(e)和Y=Y(e)是定义在S上的随机变量,由它们构成的一个响亮(X,Y),叫做二维随机向量或二维随机变量。
二维随机变量(X,Y)的性质不仅与X及Y有关,而且还依赖于这两个随机变量的相互关系。因此,逐个地来研究X或Y的性质是不够的,还需将(X,Y)作为一个整体来进行研究。
联合概率分布定义
设(X,Y)是二维随机变量,对于任意实数x,y,二元函数:
F(x,y) = P{(X<=x) 交 (Y<=y)} => P(X<=x, Y<=y)
称为二维随机变量(X,Y)的分布函数,或称为随机变量X和Y的联合分布函数。
联合概率分布几何意义
如果将二维随机变量(X,Y)看成是平面上随机点的坐标,那么分布函数F(x,y)在(x,y)处的函数值就是随机点(X,Y)落在以点(x,y)为顶点而位于该点左下方的无穷矩形域内的概率。
联合概率分布离散情况
离散型随机变量的联合概率分布。
联合概率分布连续情况
连续型随机变量的联合概率分布
10.内积与外积:
向量是由n个实数组成的一个n行1列(n*1)或一个1行n列(1*n)的有序数组;
向量的点乘,也叫向量的内积、数量积,对两个向量执行点乘运算,就是对这两个向量对应位一一相乘之后求和的操作,点乘的结果是一个标量。
点乘公式
对于向量a和向量b:
a和b的点积公式为:
要求一维向量a和向量b的行列数相同。
点乘几何意义
点乘的几何意义是可以用来表征或计算两个向量之间的夹角,以及在b向量在a向量方向上的投影,有公式:
推导过程如下,首先看一下向量组成:
定义向量:
根据三角形余弦定理有:
根据关系c=a-b(a、b、c均为向量)有:
即:
向量a,b的长度都是可以计算的已知量,从而有a和b间的夹角θ:
根据这个公式就可以计算向量a和向量b之间的夹角。从而就可以进一步判断这两个向量是否是同一方向,是否正交(也就是垂直)等方向关系,具体对应关系为:
a·b>0 方向基本相同,夹角在0°到90°之间
a·b=0 正交,相互垂直
a·b<0 方向基本相反,夹角在90°到180°之间
叉乘公式
两个向量的叉乘,又叫向量积、外积、叉积,叉乘的运算结果是一个向量而不是一个标量。并且两个向量的叉积与这两个向量组成的坐标平面垂直。
对于向量a和向量b:
a和b的叉乘公式为:
其中:
根据i、j、k间关系,有:
叉乘几何意义
在三维几何中,向量a和向量b的叉乘结果是一个向量,更为熟知的叫法是法向量,该向量垂直于a和b向量构成的平面。
在3D图像学中,叉乘的概念非常有用,可以通过两个向量的叉乘,生成第三个垂直于a,b的法向量,从而构建X、Y、Z坐标系。如下图所示:
在二维空间中,叉乘还有另外一个几何意义就是:aXb等于由向量a和向量b构成的平行四边形的面积。
向量的内积是一标量:
a · b = |a|*|b|cos.
向量的外积是一矢量:
它的大小=|a × b| = |a|*|b|sin.
它的方向规定为:与a、b均垂直,并且使(a,b,a × b)构成右手系。
(说明:这里a,b等是矢量,上面的箭头无法打出。)
11.方差和期望 权重可以设置,期望固定
一句话,均值是随机变量,随机变量,随机变量(具有概率特性)!(重要的话说三遍),期望是常数,是常数,是常数(不具有概率特性)!(这两个完全是两码事,楼里有些回答自己都没搞清楚)
随机变量只是“事件”到“实数”的一个映射,如楼主,我也可以说正面=5,背面=7,这样期望就是6,因为事件具有概率性,故随机变量具有概率性。
方差是随机变量到期望值距离的期望,随机变量最有可能落在“期望值”附近,不信你算算D(X)=1(D(X)=E((X-E(X))^2)和E((X-1)^2)=2和E((X+1)^2)=2。不管你信不信,从数学上讲,老子就是最有可能取值为0。这也说明了根据数学期望做决策也存在一定的不合理的因素。
观测n个的随机变量Xi(i=1,2,..., n)(观测n次),n次观测值的平均值概率收敛于n个随机变量期望的均值(大数定律)。
n个随机变量和的分布的极限分布是正态分布(中心极限定理)。
某城市有10万个家庭,没有孩子的家庭有1000个,有一个孩子的家庭有9万个,有两个孩子的家庭有6000个,有3个孩子的家庭有3000个。
则此城市中任一个家庭中孩子的数目是一个随机变量,记为X。它可取值0,1,2,3。
其中,X取0的概率为0.01,取1的概率为0.9,取2的概率为0.06,取3的概率为0.03。
则,它的数学期望
,即此城市一个家庭平均有小孩1.11个
平均数:
(n表示这组数据个数,x1、x2、x3……xn表示这组数据具体数值)
方差公式:
12.softmax分类器和logistic分类器
Logistic 分类器与 softmax分类器
首先说明啊:logistic分类器是以Bernoulli(伯努利)分布为模型建模的,它可以用来分两种类别;而softmax分类器以多项式分布(Multinomial Distribution)为模型建模的,它可以分多种互斥的类别。
补充:
什么是伯努利分布?伯努利分布[2] 是一种离散分布,有两种可能的结果。1表示成功,出现的概率为p(其中0<p<1)。0表示失败,出现的概率为q=1-p。
什么是二项分布?二项分布即重复多次的伯努利分布哦;
什么是多项式分布?即它把两种状态推广到了多种状态,是二项分布的推广;
Logistic 分类器
要解决什么样的问题呢??假设有一训练样本集合X ={x1, x2, x3, ……},其中样本xi 由一系列的属性表示即,xi = (a1,a2, a3,……),并且对于样本集合X中的样本要么属于类别0,要么属于类别1.
现在呢,我们有一个测试样本x,我们根椐上面的知识来推断:样本x属于类别0 还是类别1呢??
下面来解决这个问题哦:
1,首先引入参数θ=(θ1,θ2,θ3,……),对于样本中的属性进行加权,得到:θTx
2,引入logistic函数(sigmoid函数):g(z) = 1 / (1 + e-z),该函数常作为神经网络里的激活函数的;构建这么一个式子(待会就会明白它的含义):
logistic函数的图像为:
我们发现呢,它总是介于0-1之间呢,所以呢,我们可以让 hθ(x) 函数作为一种概率估计哦,如,我们可以让它表示样本 x 属于类别1的概率,即P(y = 1 | x; θ) = hθ(x) 。其实一开始可能不那么容易理解,不过你这么想想,给定了样本 x , 当θTx的值大于0时,则hθ(x)大于0.5,表示样本为类别1的概率超过了50%,而如果当θTx的值小于0时,则hθ(x)大、小于0.5,表示样本为类别1的概率不会超过50%,那么它属于类别0的概率超过了50%了啊,所以呢,hθ(x)函数作为样本 x 属于哪种类别的概率估计很好啊,关键问题就是根椐训练样本求出合适的参数θ。
3.现在我们有: P(y = 1 | x; θ) = hθ(x),与 P(y = 0 | x; θ) = 1 - hθ(x),那么呢,我们把它俩联合起来,得到:P(y | x; θ) = {hθ(x)}y{(1-hθ(x)}1-y.
4. 现在,我们有了P(y | x; θ) ,它的含义就是在给定样本 x 与参数 θ 时,标签为y的概率;然后我们还有一个训练样本集合(已经每个样本的标签)。现在我们假设每一个训练样本是独立的,我们写出它们联合概率密度:
注意:上式中,对应的 y(i) 是已经知道的了哦。其实上式中未知的参数就是θ 。
其实呢,我们写的上面的公式就是似然函数啦,我们现在要把它最大化。(什么意思呢?这里就要看你对拟然函数的理解了。就是说,随机事件已经发生了,即把每一个样本对应的标签作为随机事件的话,我们已经知道了它们的具体标签,我们就就认为已经发生的事件即是概率最大的事件,所以呢,公式中唯一确定的就是参数θ 了,我们要需要选择合适的参数θ使似然函数最大化)
4,最大化似然函数,求出合适的参数θ。
把上面的式子变形为:
然后,我们利用梯度下降法来求参数θ 。
过程大致是这样的,先对参数θ的求导,即得到梯度,然后呢,再利用梯度下降法的更新原则来更新参数θ就可以了。
求的梯度(注意哦,参数θ=(θ1,θ2,θ3,……)):
更新法则:
5.现在我们已经得到了参θ了,我们就相当于得到了hθ(x),然后呢,我们就可以用它进行对测试样本进行分类啦。
softmax分类器
它要解决的问题和上面的差不多,唯一的区别就是类别不局限于两类,而是多类了。
要解决什么样的问题呢??假设有一训练样本集合X ={x1, x2, x3, ……},其中样本xi 由一系列的属性表示即,xi = (a1,a2, a3,……),并且对于样本集合X中的样本属于类别C ={c1, c2, c3, ……}中的一种。
现在呢,我们有一个测试样本x,我们根椐上面的知识来推断:样本x属于哪种类别呢?
现在开始:
首先说一下指数布族,我也没有花太多的精力放上面哦。
一种形如如下公式的分布即为指数分布族:
第二提一下,一个广义线性模型,其实很多时候,我们很多常见的各种分布都可以用广义线性模型来概括。在一个分布为指数族分布时,我们如何来定义出一个广义线性模型呢?作出三个假设:
1,在给定x 与参数θ时,y|x 服从以 η 为变量的指数族的分布:
2,给定x 时,我们的目标是来预测T(y)的值。不过在很多时候,T(y) = y;
3,参数 η =θTx; (为什么呢?它就是这么设计的,广义线性模型哦)
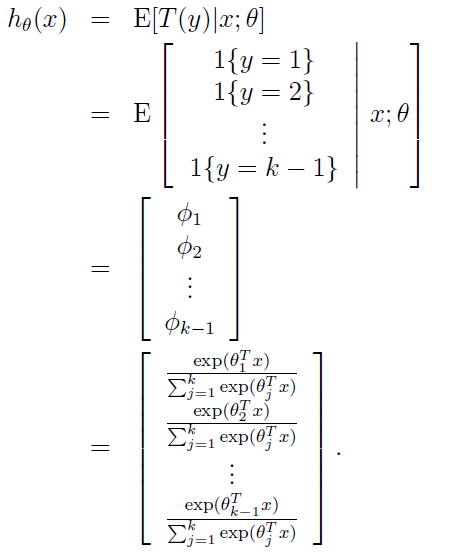
下面正式推一下softmax回归(可以用它用分类器的哦)
上面已经说了,对于给定的测试样本x , 它的输出有k种可能(即可以分为k类),我们分别φ1,φ2,φ3,φ4,……,然后呢,我们定义T(y)如下:
并且定义一个运算I{真} = 1,I{假} = 0; 所以呢,有:
1,上面的(T(y))i = I{y = i} ,其中(T(y))i 表示T(y)的第i个元素);
2,E[(T(y))i]= P(y = i) = φi.
下面为推导过程:假设以已经φ的情况,把 p(y; φ)写出指数分布族的形式,如下所示:
注意上面的η是K-1维的哦,我们现在规定ηk = log(φk/φk) = 0。所以呢, ηi = log(φi / φk),其中i =1,2,……,k)
然后呢,
所以呢,推出:
上面我们假设的φi 已经知道了,其实我们不知道哦,现在我们就推出了怎么去求φi了。上面的式子表示了怎么由ηi去求θi,这就是softmax函数。对于上式的ηi = θiT x.(应用上面的第三个假设)。还因为ηk=0,所以呢,我们又规定了θk= 0。(所以,这里一定注意,θk还是未知数哈,待会用得到这一点)。
其实到这里基本已经完了,因为我们所关心的φi已经知道怎么去求了。
接下来呢,我们来预测T(y)的值哈(看假设的广义线性模型中的第二点哦)
到这里就剩下最后一步了,求拟合参数θ1,θ2,……,θk-1。可能会问什么没有θk呢,因为我们上面规定了θk=0.追根到底是因为:φk =1-(φ1+φ2+ ……+φk-1).
如何求呢,我们写出它的似然函数,然后就可以转变为:用梯主下降或牛顿法等求最值的问题了。它的拟然函数为:
现在呢,我们把参数已经求出来了,可以解决我们的问题了,即给定了一个测试样本,我们估计它属于哪一类。方法是我们分别求出对应的φi,哪个最大,它就属于哪一类了。
注意:
最后针对这里我们推出的softmax函数中的公式为:
要说明一点,这里的未知数的个数为θ1,θ2,……,θk-1,而 θk = 0,因为我们只需要求出φ1,φ2,……,φk-1的值来,我们就能求出φk的值。
而在很多用于分类的神经网络中,最后加的softmax的分类器,它是这样:公式是相同的,但是呢,把θ1,θ2,……,θk-1,θk作为参数,这样有一个什么问题呢,那就是过度参数化了(根本用不着这么多参数嘛),过度参数化会怎样啊?假如我们对每一个参数θi 减去一个相同的数,变为θi-ψ,然后呢,
发现了,完全不影响假设函数的预测结果哦。
什么意思呢???
所以,在现实中,我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决softmax 回归的参数冗余所带来的数值问题。
13.LSTM:
一个叫做“输入门限层”的sigmoid层决定哪些值需要更新。接下来,一个tanh层创建一个向量
长短期记忆网络——通常简称“LSTMs”——是一种特殊的RNN,能够学习长期依赖关系。它们由Hochreiter和Schmidhuber (1997)提出,在后期工作中又由许多人进行了调整和普及(除了原始作者之外,许多人为现代LSTM做出了贡献,不完全统计:Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustian Gomez, Matteo Gagliolo 和 Alex Graves)。它们在大量问题上效果异常出色,现在正在广泛使用。
LSTMs明确设计成能够避免长期依赖关系问题。记住信息很长一段时间几乎是它们固有的行为,而不是努力去学习!
14Kullback-Leibler Divergence
KL距离全称为Kullback-LeiblerDivergence,也被称为相对熵。公式为:
感性的理解,KL距离可以解释为在相同的事件空间P(x)中两个概率P(x)和Q(x)分布的差异情况。
从其物理意义上分析:可解释为在相同事件空间里,概率分布P(x)的事件空间,若用概率分布Q(x)编码时,平均每个基本事件(符号)编码长度增加了多少比特。
如上面展开公式所示,前面一项是在P(x)概率分布下的熵的负数,而熵是用来表示在此概率分布下,平均每个事件需要多少比特编码。这样就不难理解上述物理意义的编码的概念了。
但是KL距离并不是传统意义上的距离。传统意义上的距离需要满足三个条件:1)非负性;2)对称性(不满足);3)三角不等式(不满足)。但是KL距离三个都不满足。反例可以看参考资料中的例子。
KL距离,是Kullback-Leibler差异(Kullback-LeiblerDivergence)的简称,也叫做相对熵(RelativeEntropy)。它衡量的是相同事件空间里的两个概率分布的差异情况。其物理意义是:在相同事件空间里,概率分布P(x)的事件空间,若用概率分布Q(x)编码时,平均每个基本事件(符号)编码长度增加了多少比特。我们用D(P||Q)表示KL距离,计算公式如下:
当两个概率分布完全相同时,即P(x)=Q(X),其相对熵为0。我们知道,概率分布P(X)的信息熵为:
其表示,概率分布P(x)编码时,平均每个基本事件(符号)至少需要多少比特编码。通过信息熵的学习,我们知道不存在其他比按照本身概率分布更好的编码方式了,所以D(P||Q)始终大于等于0的。虽然KL被称为距离,但是其不满足距离定义的三个条件:1)非负性;2)对称性(不满足);3)三角不等式(不满足)。
我们以一个例子来说明,KL距离的含义。
假如一个字符发射器,随机发出0和1两种字符,真实发出概率分布为A,但实际不知道A的具体分布。现在通过观察,得到概率分布B与C。各个分布的具体情况如下:
A(0)=1/2,A(1)=1/2
B(0)=1/4,B(1)=3/4
C(0)=1/8,C(1)=7/8
那么,我们可以计算出得到如下:
也即,这两种方式来进行编码,其结果都使得平均编码长度增加了。我们也可以看出,按照概率分布B进行编码,要比按照C进行编码,平均每个符号增加的比特数目少。从分布上也可以看出,实际上B要比C更接近实际分布。
如果实际分布为C,而我们用A分布来编码这个字符发射器的每个字符,那么同样我们可以得到如下:
再次,我们进一步验证了这样的结论:对一个信息源编码,按照其本身的概率分布进行编码,每个字符的平均比特数目最少。这就是信息熵的概念,衡量了信息源本身的不确定性。另外,可以看出KL距离不满足对称性,即D(P||Q)不一定等于D(Q||P)。
当然,我们也可以验证KL距离不满足三角不等式条件。
上面的三个概率分布,D(B||C)=1/4log2+3/4log(6/7)。可以得到:D(A||C) -(D(A||B)+ D(B||C)) =1/2log2+1/4log(7/6)>0,这里验证了KL距离不满足三角不等式条件。所以KL距离,并不是一种距离度量方式,虽然它有这样的学名。
其实,KL距离在信息检索领域,以及统计自然语言方面有重要的运用。我们将会把它留在以后的章节中介绍。















 4446
4446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










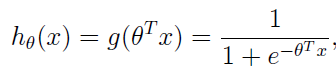{kind=link}
{kind=link}
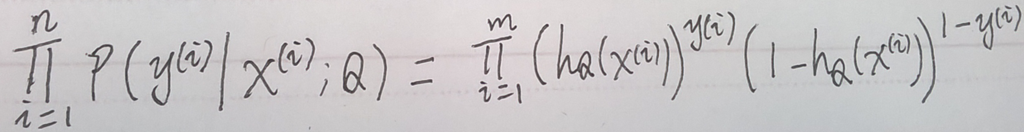{kind=link}
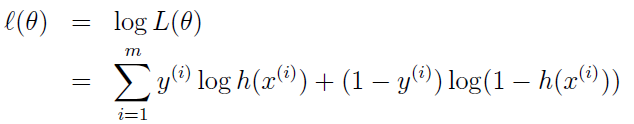{kind=link}
{kind=link}
{kind=link}
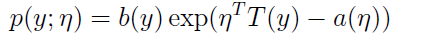{kind=link}
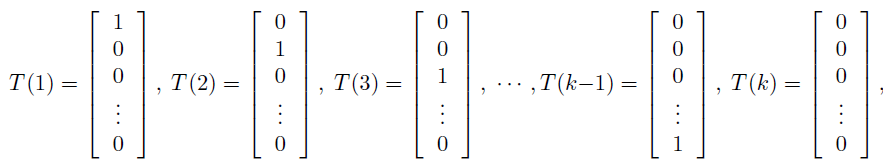{kind=link}
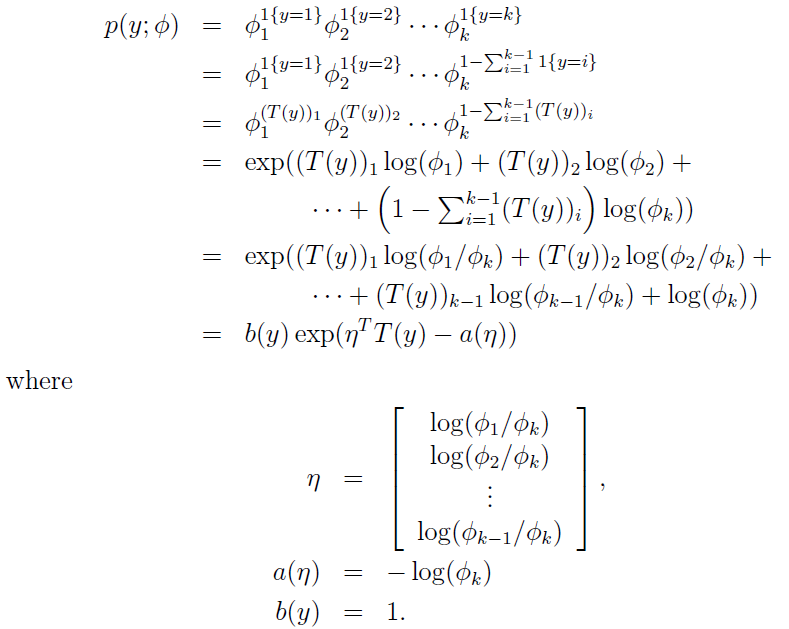{kind=link}
{kind=link}
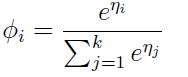{kind=link}
{kind=link}
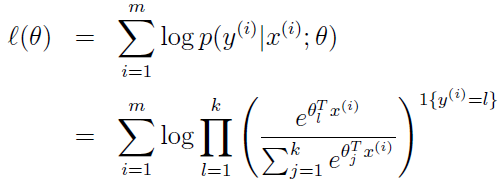{kind=link}
{kind=link}
{kind=link}
{kind=link}