







原始LSH算法算法原理是将特征逐维映转成01串,之后进行hash(随机选bit),将空间中中相近的点hash到同一个桶;这样在查询中,只在同一个桶内暴力搜索即可,相较于在整个数据库中暴力查找,无疑减少了两两比较的次数,减少检索时间。
算法实现中,如果真的逐维把特征值展开成01串,对于高维特征(维度几千),那么这个展开的“串”将特别的长,例如4000维特征,特征类型uchar,那么其转换成的串的长度为:255**4000,既占用存储空间,又浪费时间。原论文中提到了一个trick来避免转成“串”的这个过程,下面我试着解释一下这个trick。
假设特征为[4,2,5],特征最大值为5,那么将特征逐维度展开后的01“串”为:
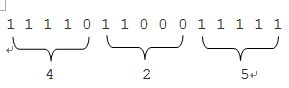
假设hash函数随机选取的bit位为:[2,3,6,8,10],那么提取出来的value为11101,这是展开成“串”的做法,下面我们换一种思路。
提取出的bit位 bits=[2,3,6,8,10]实质上分别作用于原始特征[4,2,5]的某一维:bits0 =[2,3]提取第一维(4)展开的串,bits1=[6,8]提取第二维(2)站看的串,bits2=[10]提取第三维(5)展开的串,提取出对应的bit值后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









