







字典树
首先看下百度百科的定义.
字典树 是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。 —— [百度百科 ]
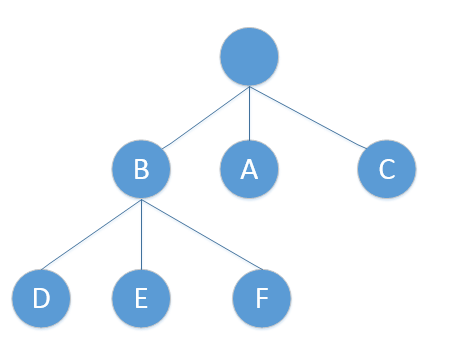
一个典型的字典树可以如上图所示。
字典树的性质
字典树主要有以下性质:
- 根结点不包含字符
- 每个节点的所有子节点包含字符不相同
- 根节点到某一节点,路径上经过的所有字符拼起来,为该节点对应的字符串
字典树的实现
数据结构
根据上面的思路我可以简单清晰的定义出字典树的数据结构,如下:
class TrieNode
{
public:
TrieNode *next[26];
bool is_word;
int num;
TrieNode(bool b = false)
{
memset(next, 0, sizeof(next));
is_word = b;
num=0;
}
};num可以方便的统计该节点表示的字符串出现的次数(频率),这个直接在构建字典树的过程中就可以实现;is_word用来标示该节点表示的字符串是一个完整的单词还是仅是一个单词的前缀;next数组用来存储该节点的子节点。
字典树的构建
void build(string s)
{
TrieNode *p = root;
for(int i=0;i<s.size();i++)
{
temp = s[i]-'a';
if(p->child[temp] == NULL)//判断是否存在对应的子节点
{
p->child[temp] = new TrieNode();
}
p = p->child[temp];
p->num ++;
}
p -> is_word = true;//标示是一个单词
}创建的思路很简单,每来一个单词,便将单词插入到已有的字典树中,途中记录词频数,插入完成后,记得将单词标示设置为true。给定单词集:A,B,C,BD,BE,BF。将创建出如上图所示的字典树。
字典树的使用
字典树最常见的操作就是给定一个新的单词,查找该单词是否在字典树中,返回他的词频(搜索引擎的词频统计);或者查找是否有以该单词为前缀的字符串。
TrieNode* find(string key)//根据输入单词返回对应的节点
{
TrieNode *p = root;
for(int i = 0; i < key.size() && p != NULL; ++ i)
p = p -> next[key[i] - 'a'];
return p;
}
// 返回该单词是否在字典树中
bool search(string key)
{
TrieNode *p = find(key);
return p != NULL && p -> is_word;
}
//返回词频
int search(string key)
{
TrieNode *p = find(key);
return (p != NULL && p -> is_word) ? p->num : 0;
}
//返回是否有以该单词为前缀的字符串
bool startsWith(string prefix)
{
return find(prefix) != NULL;
}上述操作中find(查找)是核心方法,每次都是从根节点开始搜索,取要查找单词的第一个字母,根据该字母选择对应的子节点(树)并转到该子树继续进行搜索,这样一直迭代下去,最终会返回表示该单词的节点或者NULL(不存在这个单词)。
字典树的结构以及实现不难,自己通过简单的代码编写就可以掌握。除了搜索引擎的词频统计,字典树的具体应用也是多变的,之前在leetcode上看到过一个跟字典树相关的题目,之后会补充到博客中。















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









