下图为主要介绍的几个聚类方法: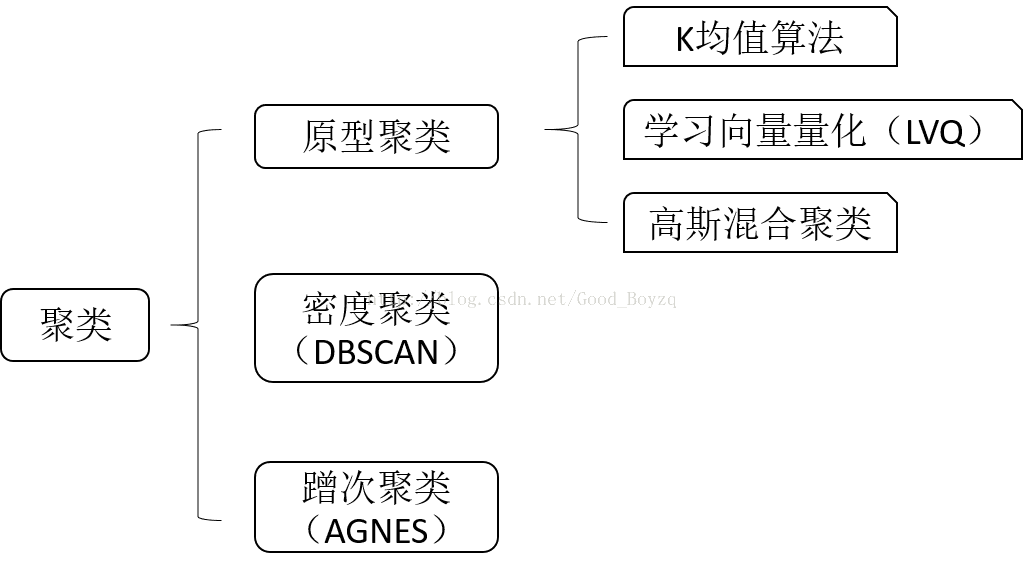
1、 k均值(K-means)
▲在指定n个类别后,最小化类别中样本到类别均值样本的距离,公式如下:
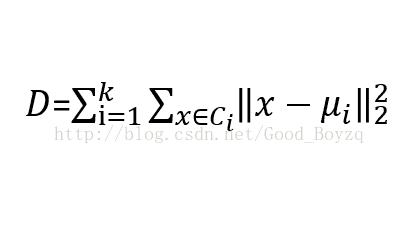
其中,Ci为划分,ui为每个划分的均值向量,k=n。K-均值是相当于一个小、 全等、 对角协方差矩阵的期望最大化算法。
▲该方法有以下缺点:
- 有个前提:集群是凸和各向同性的。对长条形、流行以及不规则形的集群响应不好。
- 惯性不是归一化的度量:仅仅知道值越低越好。但是在高维空间中,欧几里得距离会有所变化。因此在使用k均值方法前,可以利用PCA算法对数据降维,不仅可缓解这一问题,而且还可以加快计算。
▲k均值的算法如下:(参考周志华老师的《机器学习》:203)
***********************************************************
输入:样本集D={x1,x2,x3,…,xm}
聚类簇数:k
过程:
从D中随机选择k个样本{u1,u2,u3,…,uk}
repeat
令Ci={}(1<=i<=k)
计算每个样本到{u1,u2,u3,…,uk}的距离,将距离最近的加入对应的集合中
计算对应集合的均值向量
更新随机选择的k个样本
until 当前均值样本向量均未更新
输出:划分
***********************************************************
▲理论上k-均值总会收敛(可能收敛于一个局部最小值),这依赖于初始化的质心。因此k-均值算法常常会以不同初始化的质心计算几次。在sklearn中可设置init=kmeans++解决这一问题。
▲n_jobs参数可以实现并行处理。通常需要计算机有多的处理器,当n_jobs=-1时,表示使用全部的处理器,-2时减少一个,以此类推。处理器使用的越多内存消耗越大。
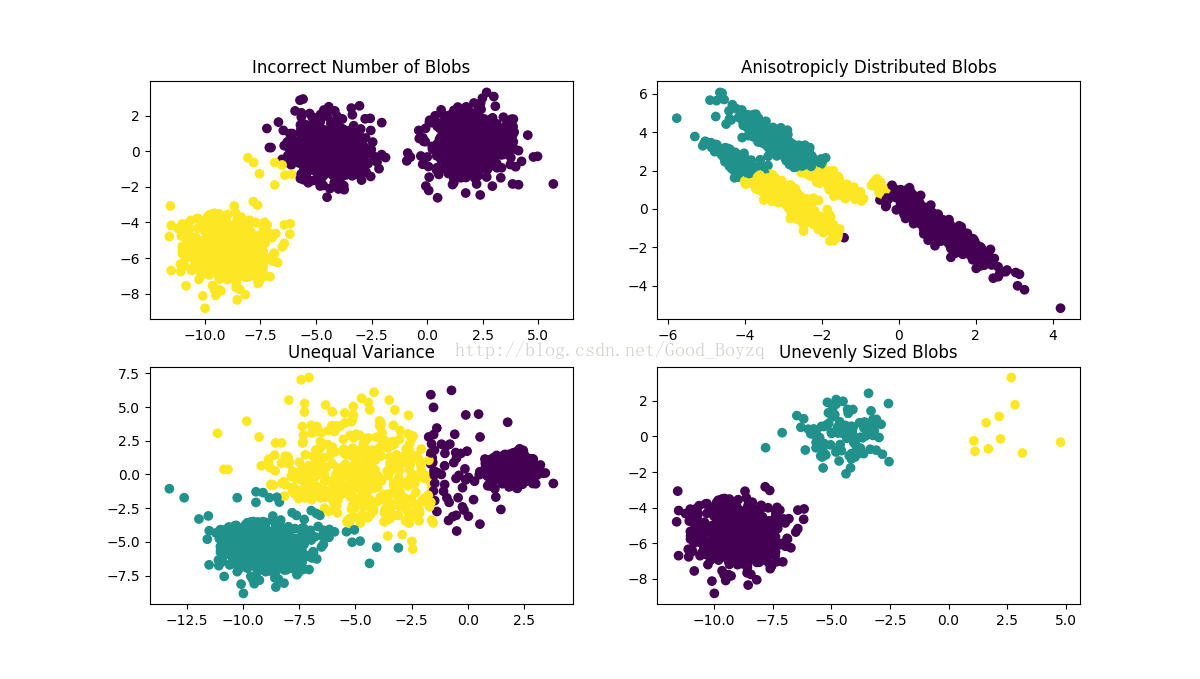
▲下面的例子为:k均值算法在不同数据集上的表现,其中前三个为输入数据不符合前提假设,最后一个为每个集群大小不应的情况。如下图:
相关代码如下:
-
-
-
-
-
-
- import numpy as np
- import matplotlib.pyplot as plt
-
- from sklearn.cluster import KMeans
- from sklearn.datasets import make_blobs
-
- plt.figure(figsize=(12,12))
-
- n_samples = 1500
- random_state = 170
- X,y = make_blobs(n_samples=n_samples,random_state=random_state)
-
-
- y_pred = KMeans(n_clusters=2,random_state=random_state).fit_predict(X)
- plt.subplot(221)
- plt.scatter(X[:,0],X[:,1],c=y_pred)
- plt.title("Incorrect Number of Blobs")
-
-
- transformation = [[0.60834549,-0.63667341],[-0.40887718,0.85253229]]
- X_aniso = np.dot(X,transformation)
- y_pred = KMeans(n_clusters=3,random_state=random_state).fit_predict(X_aniso)
- plt.subplot(222)
- plt.scatter(X_aniso[:,0],X_aniso[:,1],c=y_pred)
- plt.title("Anisotropicly Distributed Blobs")
-
-
- X_varied,y_varied = make_blobs(n_samples=n_samples,
- cluster_std=[1.0,2.5,0.5],
- random_state=random_state)
- y_pred = KMeans(n_clusters=3,random_state=random_state).fit_predict(X_varied)
-
- plt.subplot(223)
- plt.scatter(X_varied[:,0],X_varied[:,1],c=y_pred)
- plt.title("Unequal Variance")
-
- X_filtered = np.vstack((X[y==0][:500],X[y==1][:100],X[y==2][:10]))
- y_pred = KMeans(n_clusters=3,random_state=random_state).fit_predict(X_filtered)
- plt.subplot(224)
- plt.scatter(X_filtered[:,0],X_filtered[:,1],c=y_pred)
- plt.title("Unevenly Sized Blobs")
- plt.show()
1.1、Mini Batch K-Means
▲MiniBatchKMeans为k均值算法的变种,可减少收敛时间,但是其结果与标准的k均值算法较差。每次迭代中选取的数据集为原始数据集的子集。
▲该算法主要分为两步:
- 在原始数据集中选取b个样本作为小批量,并将其分配到最近的质心(质心的选取不太清楚,有两种可能,1随机在样本集中选取,2在小批量中选取。不清楚)
- 更新质心
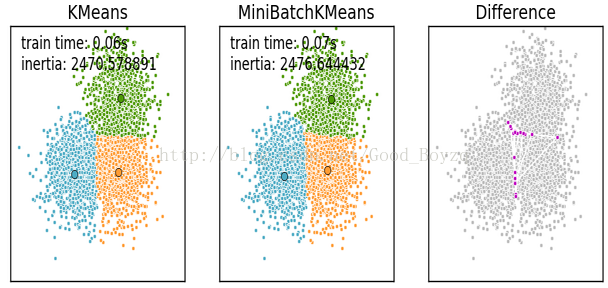
▲虽然说MiniBatchKmeans不如标准的K均值算法,但是其差异很小,如下例子:相关代码可查询http://scikit-learn.org/stable/auto_examples/cluster/plot_mini_batch_kmeans.html
2、 层次聚类(Hierarchical clustering)
▲该聚类算法试图在不同层次对数据集进行划分,从而形成树形的聚类结构。划分方法可采用自上而下和自下而上的方法。
▲AgglomerativeClustering采用自下而上的方法。首先将每个样本作为一个类,然后按照距离度量的方法将其合并到需要的聚类数。根据距离度量方法可分为:Ward方差和最小(距离最小)、complete聚类中最大或最小距离、average平均距离。
▲下面的例子说明了这三个方法的优缺点,该聚类方法具有一定的富集性,选择其中的average较好。如下图:http://scikit-learn.org/stable/auto_examples/cluster/plot_digits_linkage.html

3、DBSCAN
▲该算法通过样本的紧密程度来确定样本的分布,该算法可适用于集群在任何形状的情况下。DBSCAN算法中一个重要的概念为核心样本(具有较高的紧密度)。该算法有两个参数min_samples和eps,高min_samples或者低eps代表着在形成聚类时,需要较高的紧密度。
▲该算法简单的描述:先任意选择数据集中的一个核心对象为“种子”,在由此出发确定相应的聚类簇,在根据给定的领域参数(min_samples,eps)找出所有核心对象,在以任意一个核心对象出发,找出由其密度可达的样本生产聚类簇,直到所有核心对象均被访问为止。(更多参考周志华老师《机器学习》P212)
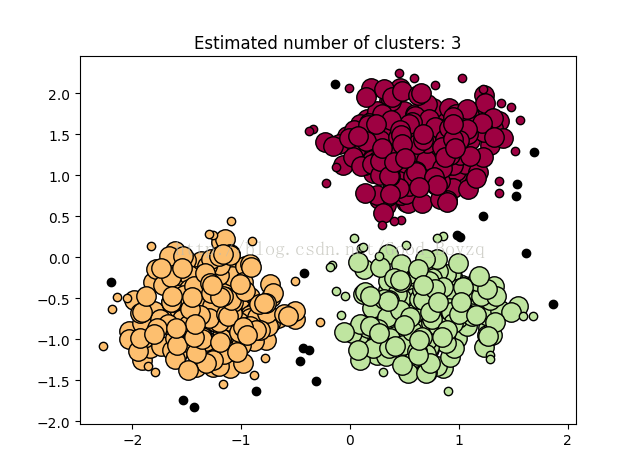
▲下图为一个例子:使用DBSCAN算法,大圈为找到了核心样本,带颜色的小点位非核心样本,黑色的为异常值。
- 相关代码:
-
-
-
-
-
-
-
- import numpy as np
- import matplotlib.pyplot as plt
-
- from sklearn.cluster import DBSCAN
- from sklearn import metrics
- from sklearn.datasets.samples_generator import make_blobs
- from sklearn.preprocessing import StandardScaler
-
-
- centers = [[1,1],[-1,-1],[1,-1]]
- X,labels_true = make_blobs(n_samples=750,
- centers=centers,
- cluster_std=0.4,
- random_state=0)
-
- X = StandardScaler().fit_transform(X)
-
-
- db = DBSCAN(eps=0.3,min_samples=10).fit(X)
- core_samples_mask = np.zeros_like(db.labels_,dtype=bool)
- core_samples_mask[db.core_sample_indices_] = True
- labels = db.labels_
-
- n_clusters_ = len(set(labels))-(1 if -1 in labels else 0)
-
- unique_labels = set(labels)
- colors = plt.cm.Spectral(np.linspace(0,1,len(unique_labels)))
- for k,col in zip(unique_labels,colors):
- if k == -1:
- col = 'k'
- class_member_mask = (labels == k)
- xy = X[class_member_mask & core_samples_mask]
- plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=col,
- markeredgecolor='k', markersize=14)
-
- xy = X[class_member_mask & ~core_samples_mask]
- plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=col,
- markeredgecolor='k', markersize=6)
-
- plt.title('Estimated number of clusters: %d' % n_clusters_)
- plt.show()
补充:用聚类进行图像分割

- 相关代码:
-
-
-
-
-
-
-
- import time
- import scipy as sp
- import numpy as np
- import matplotlib.pyplot as plt
-
- from sklearn.feature_extraction import image
- from sklearn.cluster import spectral_clustering
- from sklearn.utils.testing import SkipTest
- from sklearn.utils.fixes import sp_version
-
- if sp_version < (0,12):
- raise SkipTest("Skipping because SciPy version earlier than 0.12.0 and "
- "thus does not include the scipy.misc.face() image.")
- face = sp.misc.face(gray=True)
-
-
- face = sp.misc.imresize(face,0.10)/255
-
- graph = image.img_to_graph(face)
-
-
- beta = 5
- eps = 1e-6
- graph.data = np.exp(-beta*graph.data/graph.data.std())+eps
-
- N_REGIONS = 25
- for assign_labels in ('kmeans','discretize'):
- t0 = time.time()
- labels = spectral_clustering(graph,n_clusters=N_REGIONS,
- assign_labels=assign_labels,random_state=1)
- t1 = time.time()
- labels = labels.reshape(face.shape)
-
- plt.figure(figsize=(5,5))
- plt.imshow(face,cmap=plt.cm.gray)
- for l in range(N_REGIONS):
- plt.contour(labels==l,contours=1,
- colors = [plt.cm.spectral(l/float(N_REGIONS))])
- plt.xticks(())
- plt.yticks(())
- title = 'Spectral clustering: %s, %.2fs' % (assign_labels,(t1-t0))
- print(title)
- plt.title(title)
- plt.show()

























 2340
2340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









