一、代码
from scipy.cluster.hierarchy import dendrogram, ward
from sklearn.cluster import KMeans, AgglomerativeClustering
from sklearn import preprocessing
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('Mall_Customers.csv', encoding='gbk')
train_x = data[["Gender","Age","Annual Income (k$)", "Spending Score (1-100)"]]
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train_x['Gender'] = le.fit_transform(train_x['Gender'])
"""
model = AgglomerativeClustering(linkage='ward', n_clusters=3)
y = model.fit_predict(train_x)
print(y)
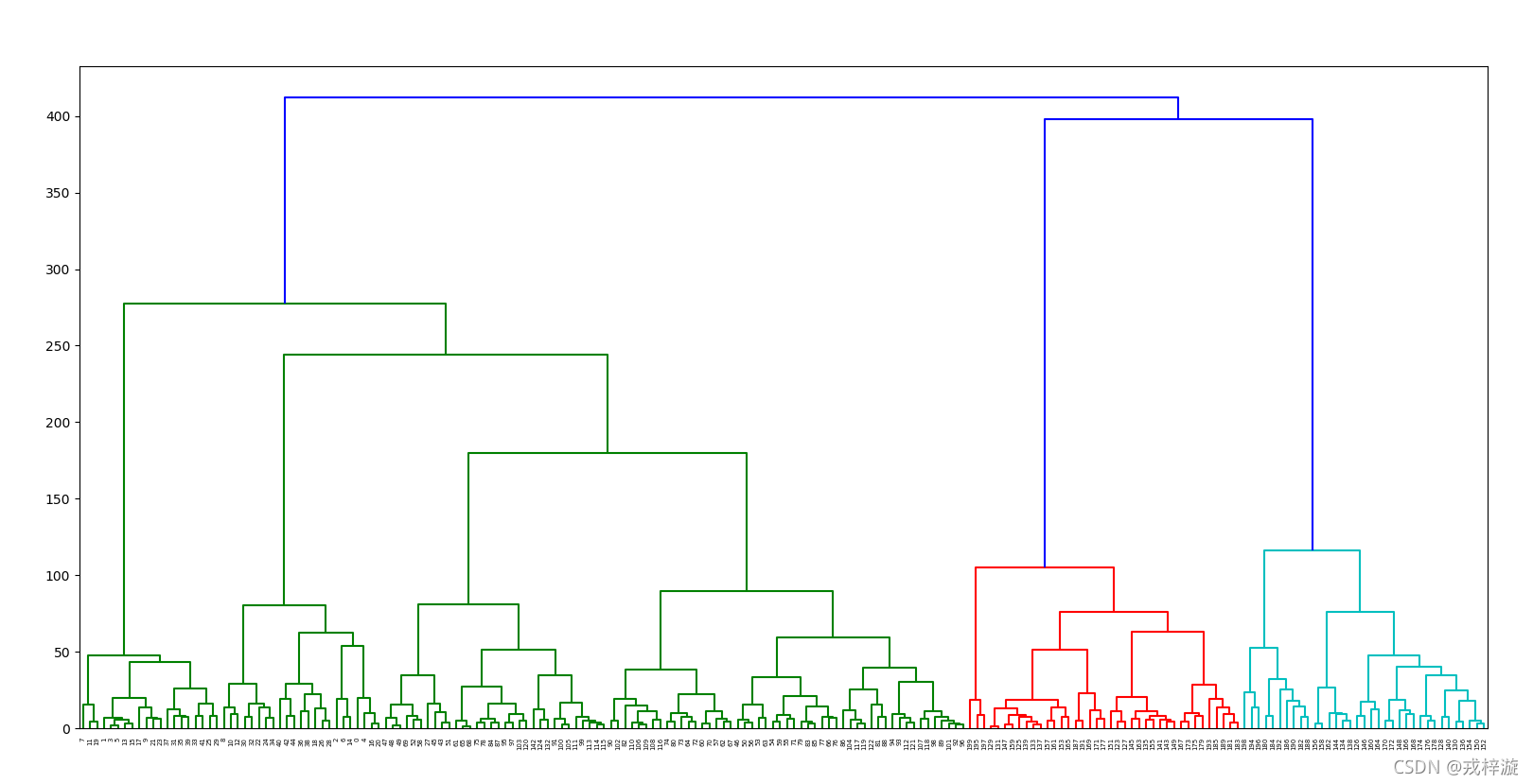
linkage_matrix = ward(train_x)
dendrogram(linkage_matrix)
plt.show()
二、运行结果
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 1 2 1 2 1 2 0 2 1 2 1 2 1 2 1 2 0 2 1 2 1 2
1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1
2 1 2 1 2 1 2 1 2 1 2 1 2 1 2]






















 7694
7694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









