







 本文介绍了点云Transformer(PCT),这是一种针对点云数据的深度学习框架。PCT借鉴了Transformer在自然语言处理中的成功,通过偏移注意力模块捕捉点云的局部上下文,同时利用点邻近嵌入增强局部特征表示。实验表明,PCT在形状分类、法线估计和分割任务上达到最先进的性能,且其计算效率和内存需求较低,适合移动设备部署。
本文介绍了点云Transformer(PCT),这是一种针对点云数据的深度学习框架。PCT借鉴了Transformer在自然语言处理中的成功,通过偏移注意力模块捕捉点云的局部上下文,同时利用点邻近嵌入增强局部特征表示。实验表明,PCT在形状分类、法线估计和分割任务上达到最先进的性能,且其计算效率和内存需求较低,适合移动设备部署。
基于深度学习方法的点云算法4——PCT: Point Cloud Transformer(点云分类分割)
请点点赞,会持续更新!!!
基于深度学习方法的点云算法1——PointNetLK(点云配准)
基于深度学习方法的点云算法2——PointNet(点云分类分割)
基于深度学习方法的点云算法3——PointNet++(点云分类分割)
文章目录
摘要
不规则域和缺乏有序性使得设计用于点云处理的深层神经网络具有挑战性。提出了一种新的点云学习框架Point Cloud Transformer(PCT)。Transformer在自然语言处理方面取得了巨大的成功,在图像处理方面显示出巨大的潜力。它在处理点序列时具有固有的置换不变性,因此非常适合点云学习。为了更好地捕获点云中的局部上下文,我们通过最远点采样( farthest point sampling)和最近邻搜索(nearest neighbor search)来增强输入嵌入。大量实验表明,PCT在形状分类、零件分割、语义分割和正常估计任务上都达到了最先进的性能。
一、Introduction
点云的应用背景及近期研究概述
在机器人技术、自动驾驶、增强现实等应用中,直接从点云中提取语义是一项迫切的需求。与2D图像不同,点云是无序和非结构化的,因此设计神经网络来处理点云是一项挑战。Qi等人开创性的设计了PointNet来学习点云的特征,通过使用多层感知器(MLP)、max pooling和rigid transformation来确保在置换和旋转下的不变性。受卷积神经网络(CNN)在图像处理领域取得的巨大进展的启发,许多最近的工作都考虑定义卷积算子,以聚合点云的局部特征。这些方法要么对输入点序列重新排序,要么对点云进行体素化,以获得卷积的规范域。
介绍了Transformer的原理和结构
每个单词的输出特征与所有输入特征相关,因此它能够学习全局上下文。Transformer的所有操作都是可并行和顺序独立的。理论上,它可以代替卷积神经网络中的卷积运算,具有更好的通用性。
受Transformer在视觉和NLP任务方面的成功启发,基于传统Transformer的原理,提出了一种新的点云学习框架PCT。PCT的核心思想是利用Transformer固有的顺序不变性之一特性,避免定义点云数据的顺序,并通过注意机制进行特征学习。
点云和自然语言是完全不同的数据类型,因此PCT框架必须进行一些调整。其中包括:
Coordinate-based input embedding module
在Transformer中,使用位置编码模块来表示自然语言中的词序。这可以区分不同位置的同一个单词,并反映单词之间的位置关系。但是,点云没有固定的顺序。在PCT框架中,将原始位置编码和输入嵌入合并到一个基于坐标的输入嵌入模块中 。它可以生成可区分的特征,因为每个点都有表示其空间位置的唯一坐标。
Optimized offset-attention module
我们提出的偏移注意力模块(offset-attention module) 是对原有自我注意的有效升级。它的工作原理是用自我注意模块的输入和注意特征之间的偏移量替换注意特征。这有两个优点。首先,刚性变换可以使同一物体的绝对坐标完全不同。因此,相对坐标通常更可靠。其次,拉普拉斯矩阵(度矩阵和邻接矩阵之间的偏移量)已被证明在图卷积学习中非常有效。从这个角度来看,我们将点云视为一个以“浮动”邻接矩阵作为注意图的图形(graph)。此外,我们工作中的注意力图将按所有行的总和缩放为1。因此,度矩阵可以理解为单位矩阵。因此,偏移注意优化过程可以大致理解为拉普拉斯过程,将在第3.3节详细讨论。此外,我们已经做了充分的对比实验,如第4节所介绍的,关于偏移注意和自我注意,以证明其有效性。
Neighbor embedding module
显然,句子中的每个单词都包含基本的语义信息。然而,这些点的独立输入坐标与语义内容的相关性很弱。注意机制在捕获全局特征方面是有效的,但它可能会忽略局部几何信息,而局部几何信息对于点云学习也是必不可少的 。为了解决这个问题,使用**邻居嵌入策略(Neighbor embedding strategy)**来改进点嵌入。它还通过考虑包含语义信息的局部点组之间的注意来辅助注意模块。
通过上述调整,PCT变得更适合于点云特征学习,并在形状分类、零件分割和法线估计任务上实现了最先进的性能。
本文的主要贡献总结如下:
1、提出了一种新的基于转换器的点云学习框架PCT,该框架非常适合于非结构化、无序的不规则域点云数据。
2、提出了使用隐式拉普拉斯算子和归一化细化的偏移注意(offset-attention),与Transformer中的原始自注意(self-attention)模块相比,它具有固有的置换不变性,更适合点云学习。
3、大量的实验表明,具有显式局部上下文增强的PCT在形状分类、零件分割和正常估计任务上达到了最先进的性能。
二、Related Work
2.1 Transformer in NLP
Bahdanau等人提出了一种带有注意机制的神经机器翻译方法,其中通过RNN的隐藏状态计算注意权重。Lin等人提出了自我注意,以可视化和解释句子嵌入。在此基础上,Vaswani等人提出了用于机器翻译的变压器;它完全基于自我注意,没有任何循环或卷积算子。Devlin等人提出了双向Transformers(BERT)方法,这是NLP领域最强大的模型之一。最近,诸如XLNet、Transformer XL和BioBERT等语言学习网络进一步扩展了Transformer框架。
然而,在自然语言处理中,输入是有序的,单词具有基本语义,而点云是无序的,单个点一般没有语义。
2.2 Transformer for vision
许多框架将注意力引入到愿景任务中。Wang等人提出了一种利用堆叠注意模块进行图像分类的残差注意方法。 Hu等人提出了一种新的空间编码单元SE块,其思想源自注意机制。Zhang el al.设计了SAGAN,它使用自我关注来生成图像。将Transformer作为优化神经网络的模块也有越来越多的趋势。Wu等人提出了视觉Transformer,将Transformer应用于视觉任务特征图中基于标记的图像。最近,Dosovitskiy提出了一种基于补丁编码和Transformer的图像识别网络ViT,表明在足够的训练数据下,Transformer比传统的卷积神经网络具有更好的性能。Carion等人提出了一种端到端检测转换器,它将CNN特征作为输入,并使用Transformer编码器-解码器生成边界框。
受ViT中使用的局部补丁结构和语言词中的基本语义信息的启发,我们提出了一个邻近嵌入模块(neighbor embedding module),该模块从点的局部邻域中聚合特征,从而捕获局部信息并获取语义信息。
2.3 Point-based deep learning
PointNet开创了点云学习。随后,Qi等人提出了PointNet++,它使用查询球分组和分层点网来捕获局部结构。随后的几项工作考虑了如何在点云上定义卷积运算。一种主要方法是将点云转换为常规体素阵列,以允许卷积操作。Tchapmi等人提出了用于逐点分割的SEGCloud。它使用三线性插值将三维体素的卷积特征映射到点云,并通过完全连通的条件随机场保持全局一致性。Atzmon等人提出了PCNN框架,其中包含扩展和限制操作符,用于在基于点的表示和基于体素的表示之间进行映射。对体素进行体积卷积以提取点特征。Hermosilla等人的MCCNN允许非均匀采样点云;卷积被视为蒙特卡罗积分问题。类似地,在Wu等人提出的PointConv中,通过蒙特卡罗估计和重要性抽样执行3D卷积。
另一种方法是重新定义卷积以对不规则点云数据进行运算。Li等人介绍了一种点云卷积网络PointCNN,其中训练了χ-变换以确定卷积的1D点顺序。Tatarchenko等人提出了切线卷积(tangent convolution),它可以从投影的虚拟切线图像中学习曲面几何特征。Landrieu等人提出的SPG将扫描的场景划分为相似的元素,并建立一个超点图结构(superpoint graph structure)来学习对象部分之间的上下文关系。Pan等人使用并行框架将CNN从传统领域扩展到弯曲的二维流形。然而,它需要密集的三维网格数据作为输入,因此不适用于三维点云。Wang等人为动态图(dynamic graphs)设计了EdgeConv操作符,允许通过恢复局部拓扑进行点云学习。
其他各种方法也使用attention和Transformer。Yan等人提出了PointASNL来处理点云处理中的噪声,使用自注意机制来更新局部点组的特征。Hertz等人提出了PointGMM,用于多层感知器(MLP)分割和注意力分割的形状插值。
与上述方法不同,PCT基于Transformer,而不是将自注意作为辅助模块。Wang等人的一个框架使用Transformer优化点云配准,而我们的PCT是一个更通用的框架,可用于各种点云任务。
三、Transformer for Point Cloud Representation
在本节中,首先展示如何将PCT学习到的点云表示应用于点云处理的各种任务,包括点云分类、零件分割和法线估计。之后,详细介绍了PCT的设计。首先介绍了一种简单版本的PCT,它将原始Transformer直接应用于点云。然后,解释了完整PCT及其特殊注意机制,以及能提供增强的局部信息的邻近聚合模块。
3.1 Point Cloud Processing with PCT
Encoder
PCT的总体架构如下图所示。PCT旨在将输入点转换(编码)到一个新的高维特征空间,该空间可以表征点之间的语义相似度,作为各种点云处理任务的基础。PCT的编码器(encoder)首先将输入坐标嵌入(Input Embedding (灰色模块))到新的特征空间中。嵌入的特征随后被输入到4个堆叠的注意(Attention(黄色模块))模块中,学习每个点的语义丰富且有区别的表示,然后是一个线性层来生成输出特征。总的来说,PCT的编码器与原始Transformer的设计理念几乎相同,只是放弃了位置嵌入,因为点的坐标已经包含此信息。后文将进一步解释输入嵌入(Input Embedding (灰色模块))和注意(Attention(黄色模块))的各种实现。
为了提取表示点云的有效全局特征向量,选择在学习的逐点特征表示上串联两个池化操作符的输出:最大池化(MP)和平均池化(AP)。
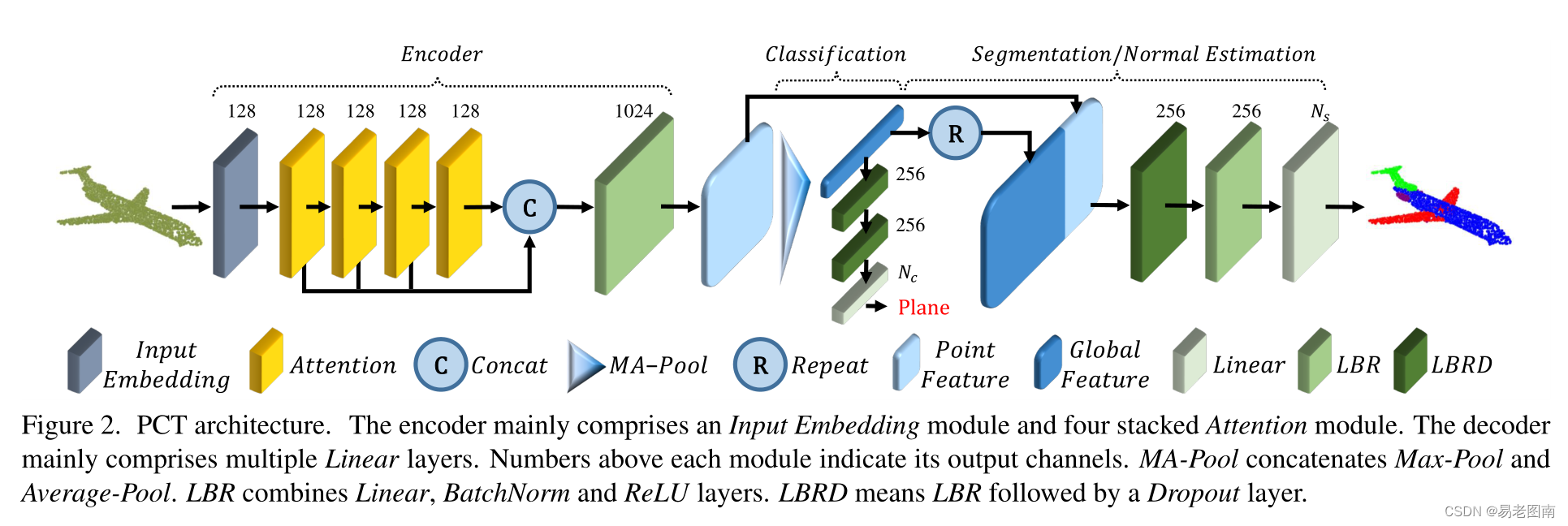
Classification
结构非常常规,见上图,以及上图的题注。
Segmentation
结构非常常规,见上图,以及上图的题注。
注意:作者将将一个 one-hot 对象类别向量编码为64维特征,并将其与全局特征连接起来。
Normal estimation
对于法线估计任务,我们使用与分割中相同的架构,设置Ns=3,不使用对象类别编码,并将输出的逐点得分视为预测法线,
3.2 Naive PCT
修改Transformer以用于点云的最简单方法是将整个点云视为一个句子,将每个点视为一个单词,现在介绍这种方法。这种简单的PCT是通过实现一种基于坐标的点嵌入,并用原始的自注意(self-attention)实例化注意层来实现的。
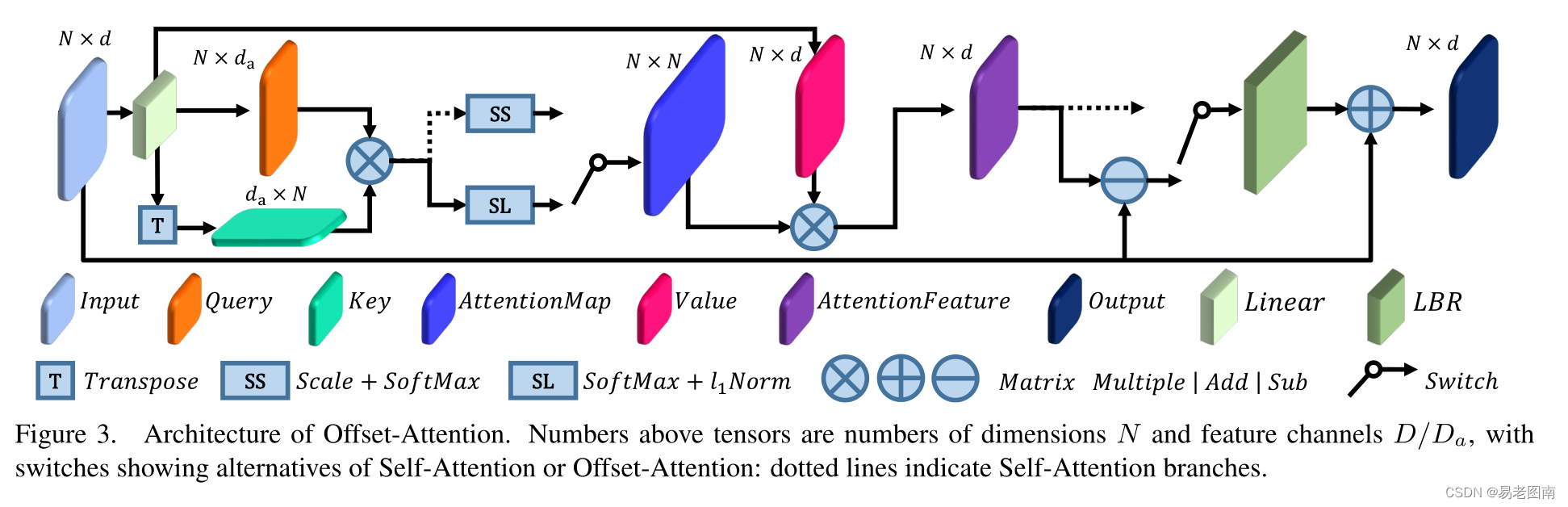
注意:图中虚线表示自注意(self-attention),实线表示偏移注意(offset-attention)。
首先,我们考虑一个简单的点嵌入,它忽略了点之间的相互作用。与NLP中的单词嵌入一样,点嵌入的目的是在语义更相似的情况下,使点在嵌入空间的位置靠的更近。具体来说,就是将一个点云嵌入到一个 d e d_e de维的特征 F e F_e Fe,这里使用的是由两个级联LBR组成的共享神经网络,每个LBR具有 d e d_e de维输出。我们根据经验将 d e d_e de设置为128,是为一个相对较小的值,以提高计算效率。只需使用点的3D坐标作为其输入特征描述(即 d p d_p dp=3)(因为这样做仍优于其他方法),但也可以使用额外的点的信息作为输入,如点法线。
对于PCT的简单实现,我们采用了原始Transformer中引入的自注意(SA)。自注意,也称为内部注意(intra-attention),是一种计算数据序列中不同项目之间语义关系的机制。SA层的体系结构如图3所示中的切换到点式数据流。按照Transformer中的术语,Q、K、V分别是通过输入特征的线性变换生成的查询矩阵、键矩阵和值矩阵 (query, key and value)。
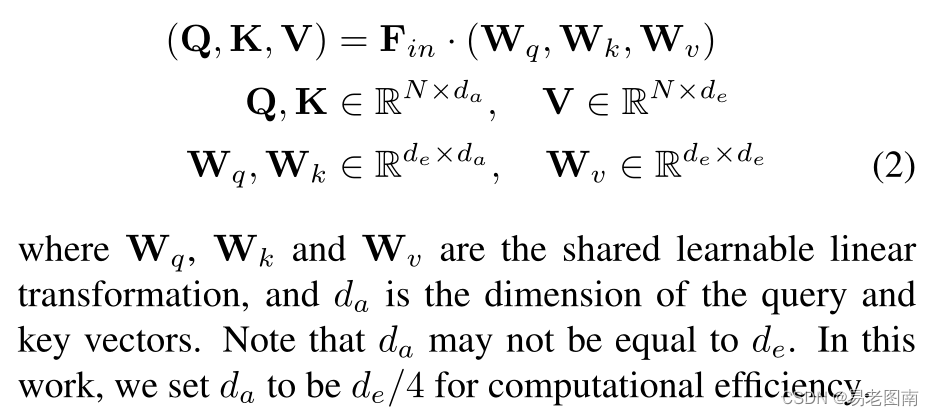
首先,可以使用查询矩阵(Q)和关键矩阵(K),通过矩阵点积计算注意权重(attention weights):

然后将权重归一化(上图中的SS模块):
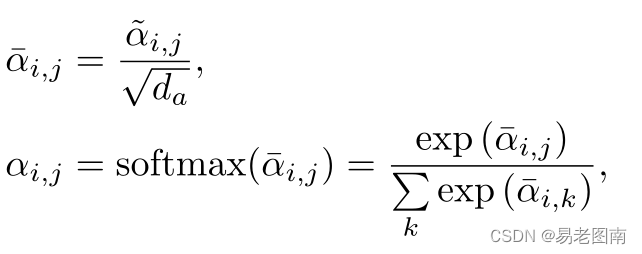
自注意输出特征
F
s
a
F_{sa}
Fsa是相应注意权重与值向量的加权和:

因为Q,K和V矩阵是由共享的对应线性变换矩阵和输入特征
F
i
n
F_{in}
Fin确定的,所以它们都与点的顺序无关。此外,softmax和加权和都是置换无关的算子。因此,整个自注意过程是排列不变的,这使得它非常适合点云呈现的无序、不规则区域。关于此处的理解可以看Transformer的self-attention的解释,可参考Self-Attention
最后,输出特征由输入特征和自注意特征组合得到:
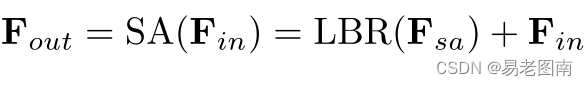
3.3 Offset-Attention
图卷积网络(graph convolution networks,GCN)展示了使用拉普拉斯矩阵
L
=
D
−
E
L=D-E
L=D−E来替代邻接矩阵(adjacency matrix)
E
E
E的好处,其中
D
D
D是对角度矩阵(diagonal degree matrix)。
类似地,作者发现,如果将Transformer应用于点云时,用偏移注意(OA)模块替换原始的自注意(SA)模块来增强PCT,可以获得更好的网络性能。如上图所示,偏移注意层通过元素减法计算自我注意(SA)特征和输入特征之间的偏移(差)。然后将该偏移量输入LBR网络,以代替简单版本中使用的SA。具体而言,方程如下:
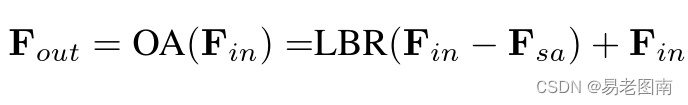
进一步的证明:
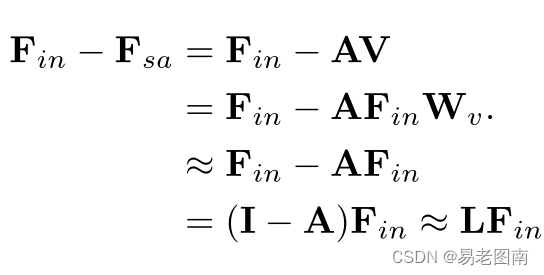
其中,
W
v
W_v
Wv因为是线性层的权重矩阵,因此可以忽略。
I
I
I是单位阵,可以类比拉普拉斯矩阵中的
D
D
D,A是注意矩阵,可以类比拉普拉斯矩阵中的
E
E
E。
在增强版PCT中,还修改完善了归一化(SL模块),如下所示:
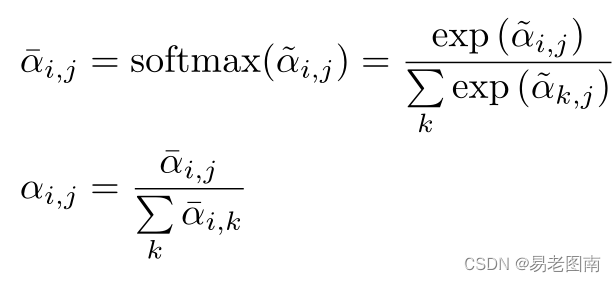
在这里,在第一维度上使用softmax操作符,在第二维度上使用
l
1
l_1
l1范数来规范化注意图。 传统的Transformer将第一个维度缩放
1
/
d
a
1/\sqrt{d_a}
1/da并使用softmax规范化第二个维度。然而,作者提出的偏移注意会 提高注意权重并减少噪声的影响(这里注意softmax作用在矩阵的每一列上,而原始的Transformer中softmax作用在矩阵的每一行上,然后这里对每一行的归一化采用了
l
1
l_1
l1范数,因为softmax的特性,使得不同点的特征差距变大,因此起到了提高注意权重并减少噪声的作用) ,这对下游任务有利。图1显示了偏移注意图的示例。可以看出,不同查询点的注意图差别很大,但通常在语义上有意义。我们在实验中将这种改进的PCT,即具有点嵌入和OA层的PCT称为简单PCT(SPCT)。
3.4 Neighbor Embedding for Augmented Local Feature Representation
点嵌入PCT是一种有效的全局特征提取网络。然而,它忽略了在点云学习中同样重要的局部邻域信息。我们借鉴PointNet++[22]和DGCNN[29]的思想,设计了一种局部邻居聚合策略,邻居嵌入,以优化点嵌入,增强PCT的局部特征提取能力。如图4所示,邻居嵌入模块包括两个LBR层和两个SG(采样和分组)层。LBR层作为第3.2节中嵌入的基点。在特征聚合过程中,我们使用两个级联的SG层来逐渐扩大感受野,就像在CNN中所做的那样。在点云采样过程中,SG层使用欧几里德距离为通过k-NN搜索分组的每个点聚合来自本地邻居的特征。采用了最远点采样(farthest point sampling,FPS)算法来选取邻域中心点。
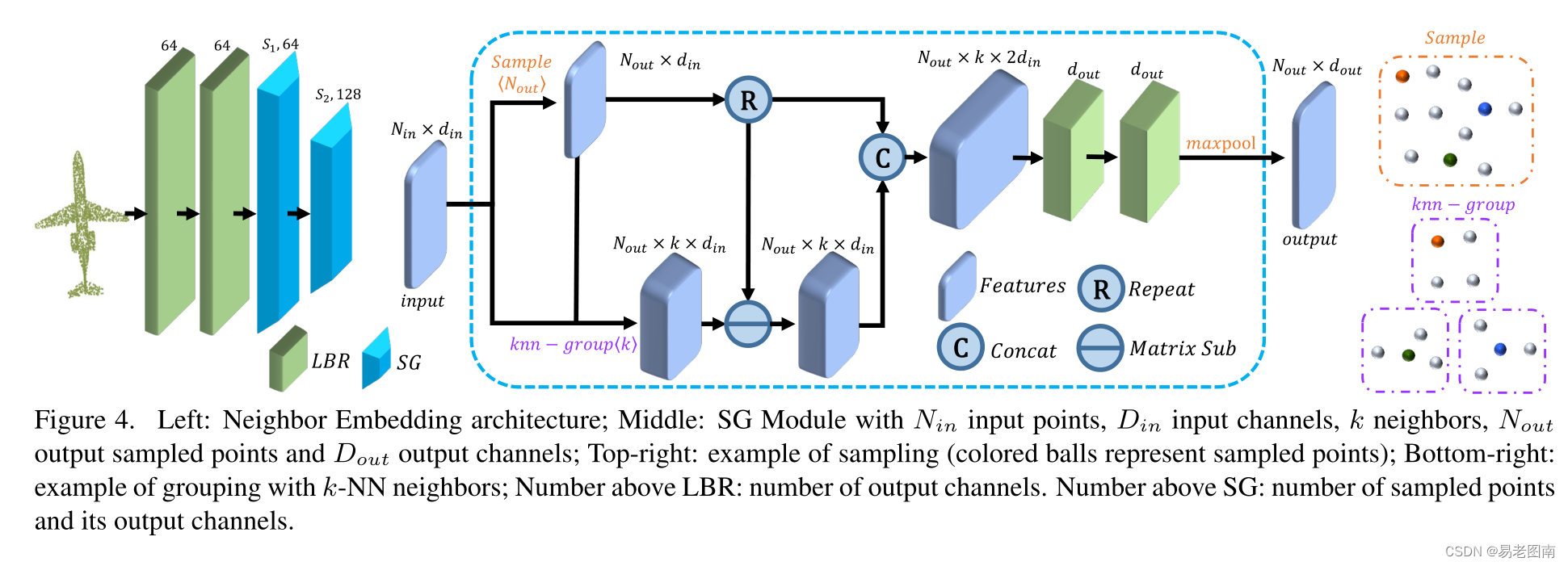
输出特征
F
s
F_s
Fs通过下式计算:
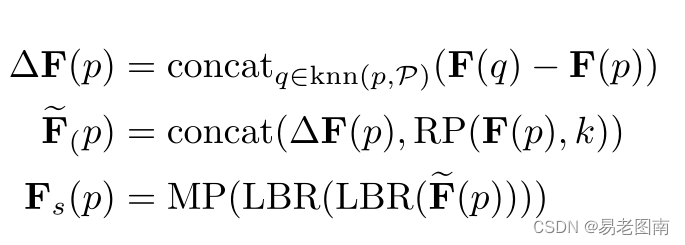
其中
F
(
p
)
F(p)
F(p)是采样点(邻域中心点)
p
p
p的输入特征,
F
s
(
p
)
F_s(p)
Fs(p)是采样点(邻域中心点)
p
p
p的输出特征,
M
P
MP
MP是最大池化,
R
P
(
x
,
k
)
RP(x,k)
RP(x,k)是将向量x复制k次,将采样点及其相邻点之间的特征连接起来的想法来自EdgeConv。
使用不同的体系结构来完成点云分类、分割和法线估计的任务。对于点云分类,我们只需要预测所有点的全局类,因此点云的大小在两个SG层内分别减少到512和256个点。
对于点云分割或法线估计,我们需要确定逐点零件标签或法线,因此上述过程仅用于局部特征提取,而不减少点云大小,这可以通过将每个阶段的输出设置为大小仍然为N来实现。
四、Experiments
现在,我们在两个公共数据集ModelNet40和ShapeNet上评估了naive PCT(NPCT,具有点嵌入和自注意)、simple PCT(SPCT,具有点嵌入和偏移注意)和full PCT(具有邻域嵌入和偏移注意)的性能,并与其他方法进行了综合比较。在每种情况下,采用软交叉熵损失函数(soft cross-entropy loss)和动量为0.9的随机梯度下降(SGD)优化器进行训练。其他训练参数,包括学习率、批量大小和输入格式,是每个特定数据集特有的,稍后给出。
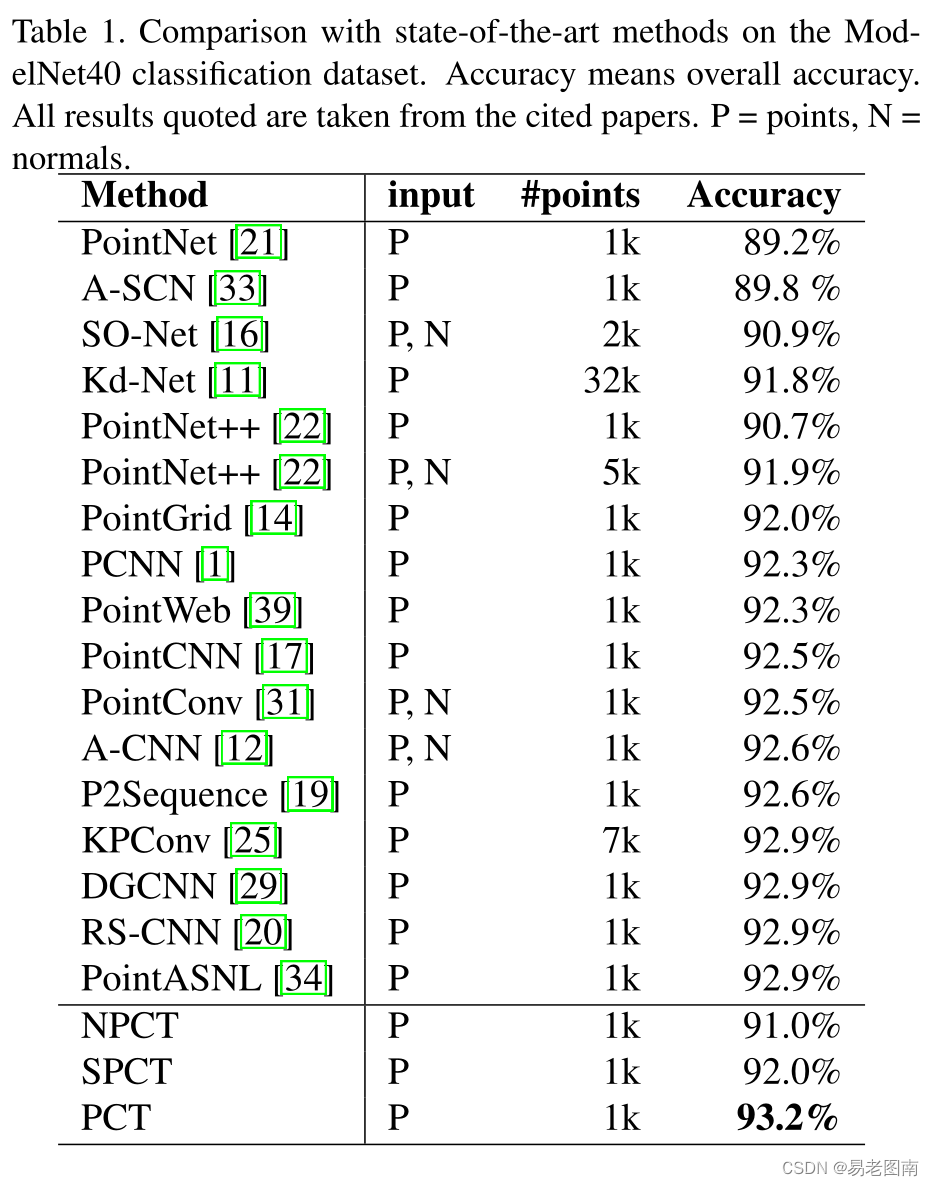
4.1 Classification on ModelNet40 dataset
ModelNet40包含40个对象类别中的12311个CAD模型;它广泛应用于点云形状分类和曲面法线估计基准测试。为了进行公平比较,我们使用了官方划分,9843个对象用于培训,2468个对象用于评估。采用与PointNet中相同的采样策略,对每个对象均匀采样1024个点。在训练期间,采用在[−0.2,0.2]上的随机平移,在[0.67,1.5]上的随机各向异性缩放和随机输入丢弃来扩充输入数据。在测试过程中,未使用数据扩充或投票方法。对于所有三个模型,批量大小为32,使用250个训练时段,初始学习率为0.01,并使用余弦退火计划调整每个时段的学习率。
实验结果如下表所示。与PointNet和NPCT相比,SPCT分别提高了2.8%和1.0%。PCT达到了93.2%总体准确率的最佳结果。请注意,我们的网络目前没有将法线作为输入,原则上可以进一步提高网络性能。
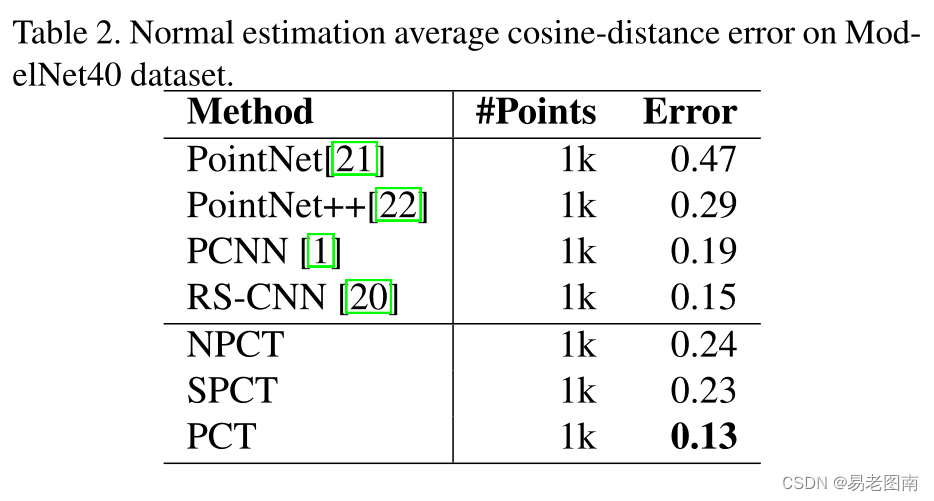
4.2 Normal estimation on ModelNet40 dataset
曲面法线估计是确定每个点的法线方向。估计曲面法线在渲染等领域有着广泛的应用。这项任务很有挑战性,因为它需要完全理解密集回归的形状的方法。我们再次使用ModelNet40作为基准,并使用平均余弦距离来测量真实值和预测法线之间的差异。对于这三个模型,batch size 为32,epochs 为200。初始学习率也设置为0.01,使用余弦退火计划调整每个轮次的学习率。如下表所示,与PointNet相比,我们的NPCT和SPCT都有显著的改进,PCT的平均余弦距离最低。
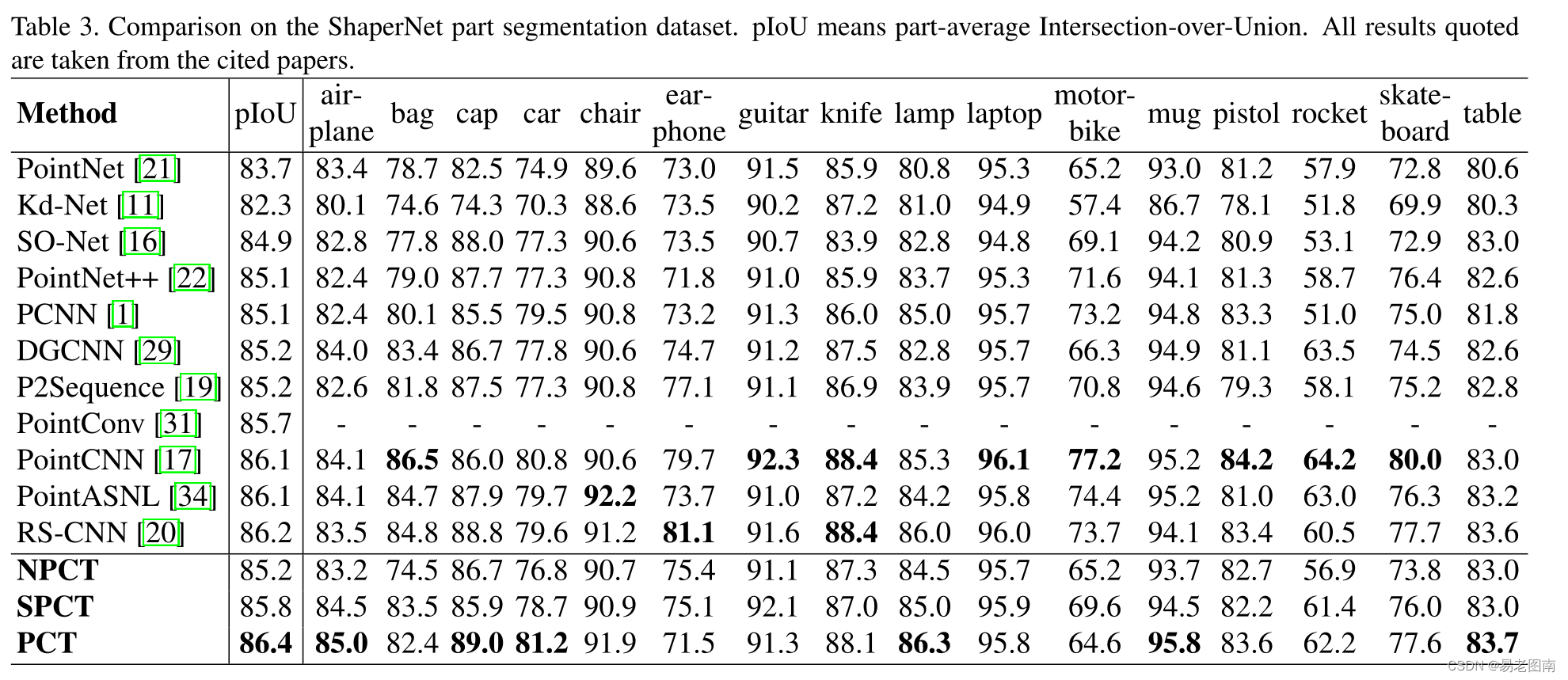
4.3 Segmentation task on ShapeNet dataset
点云分割是一项具有挑战性的任务,其目的是将三维模型划分为多个有意义的部分。我们对ShapeNet零件数据集[37]进行了实验评估,该数据集包含16880个3D模型,训练测试分割为14006到2874。它有16个对象类别和50个零件标签;每个实例包含不少于两个部分。在PointNet之后,所有模型都被降采样到2048个点,保留逐点零件注释。训练期间,采用在[−0.2,0.2]上的随机平移,在[0.67,1.5]上的随机各向异性缩放和随机输入丢弃来扩充输入数据。。在测试过程中,我们使用了多尺度测试策略,其中尺度在[0.7,1.4]中设置,步长为0.1。对于这三个模型,批量大小、训练时间和学习率都设置为与法线估计任务的训练相同。
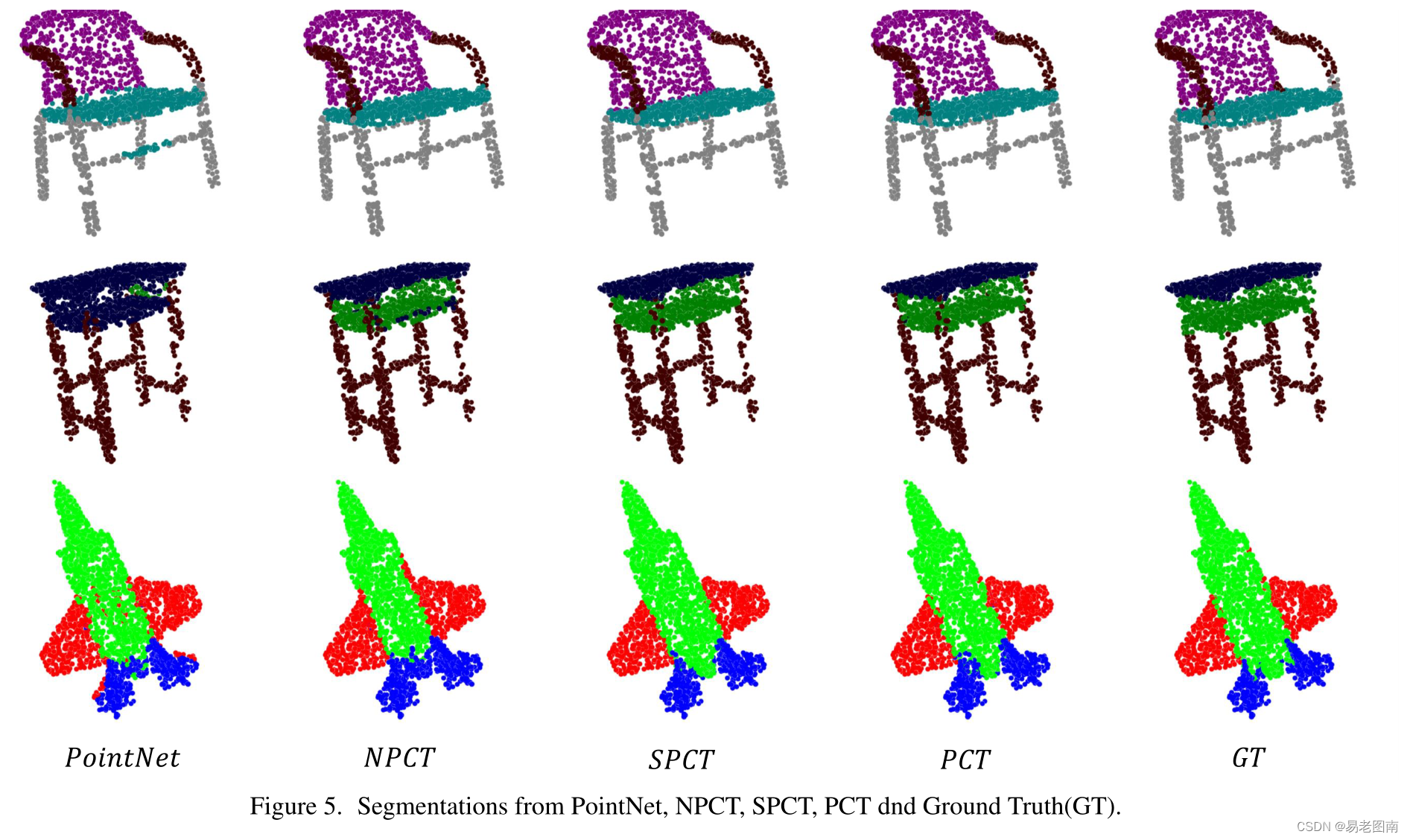
下表显示了按类划分的结果。使用的评估指标是“部件平均交并比”(part average Intersection-over-Union),并针对总体和每个对象类别给出。结果表明,我们的SPCT比PointNet和NPCT分别提高了2.1%和0.6%。PCT以86.4%的“部件平均交并比”获得最佳结果。下图显示了PointNet、NPCT、SPCT和PCT提供的进一步细分示例。
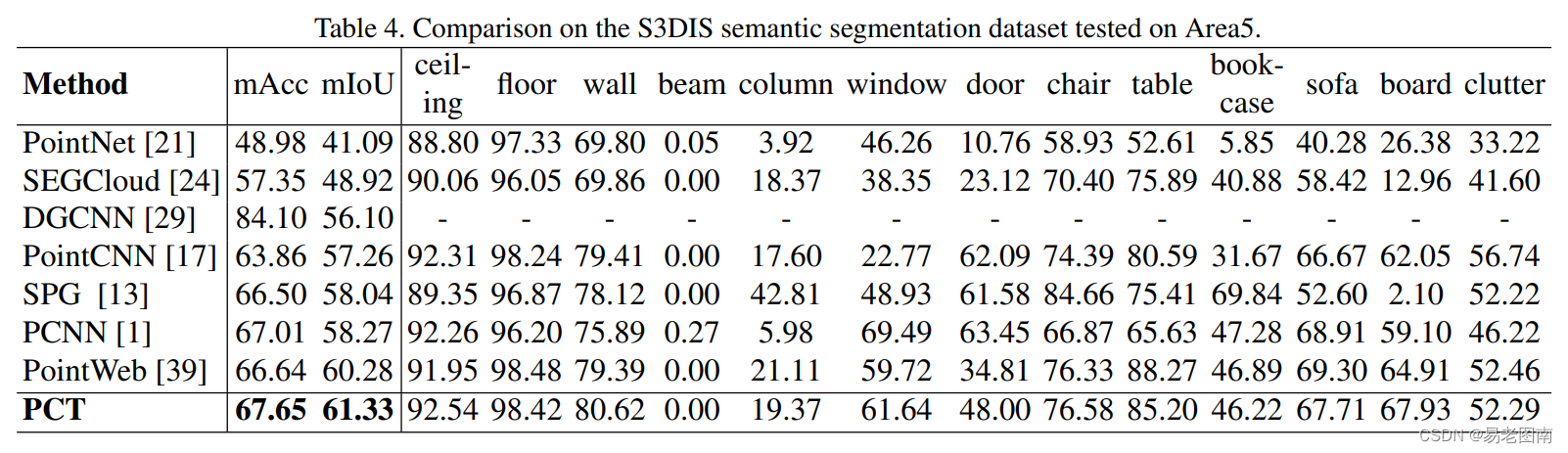
4.4 Semantic segmentation task on S3DIS dataset
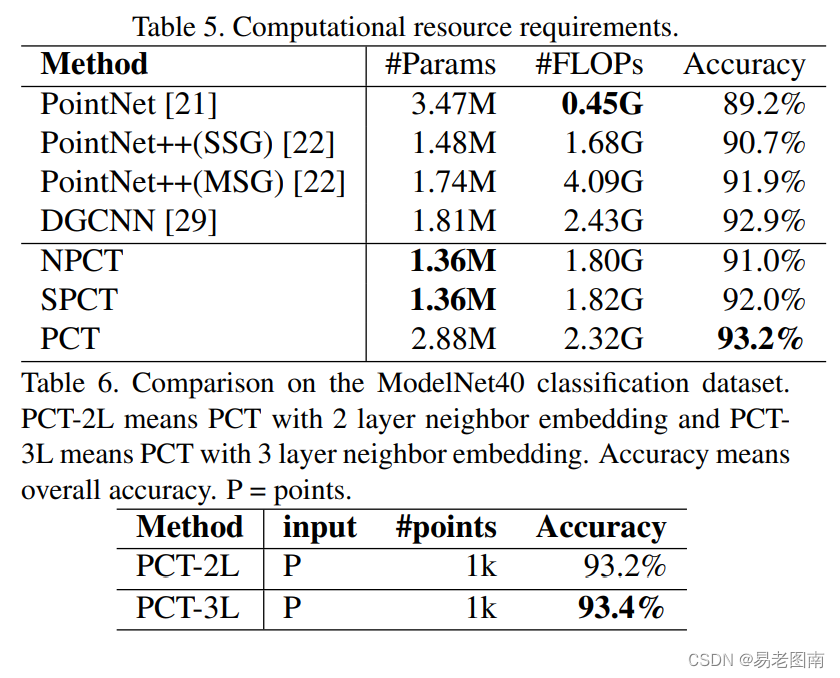
4.5 Computational requirements analysis
现在,我们通过比较下表中所需的浮点运算(FLOPs)和参数数量(Params),来考虑NPCT、SPCT、PCT和其他几种方法的计算要求。SPCT的内存需求最低,只有1.36M的参数,而且处理器的负载也很低,只有1.82 GFLOPs,但可以提供高度准确的结果。这些特性使其适合部署在移动设备上。PCT具有最好的性能,但对计算和内存的要求适中。如果我们追求更高的性能而忽略计算量和参数,我们可以在输入嵌入模块中添加一个邻域嵌入层( neighbor embedding layer)。三层嵌入PCT的结果如表6和表7所示。


















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









