






聚类Clustering
查看大量数据点,自动找到彼此相关或相似的数据点
K-means算法
原理
1.随机选择点,找聚类的中心位置。将点分配给簇质心
2.移动簇质心
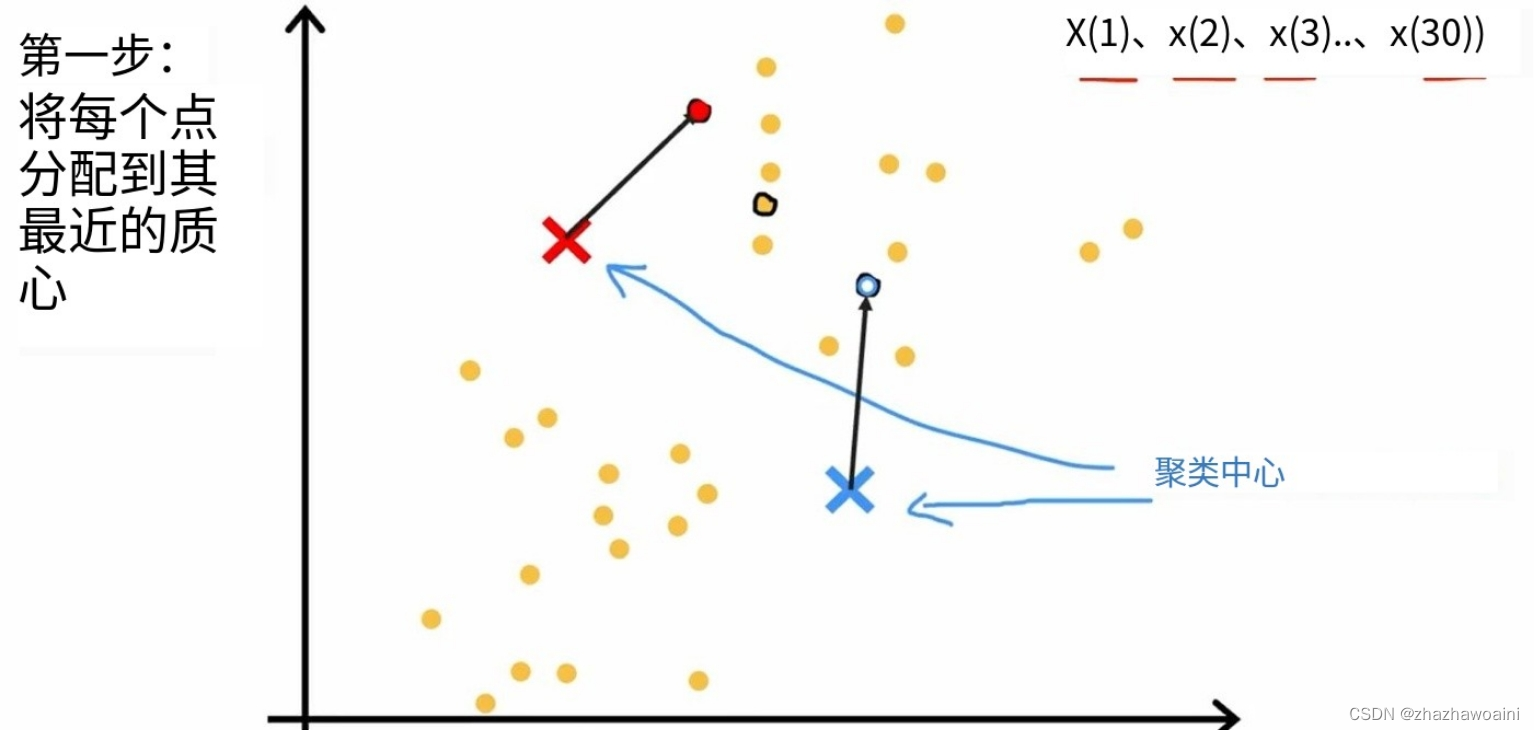
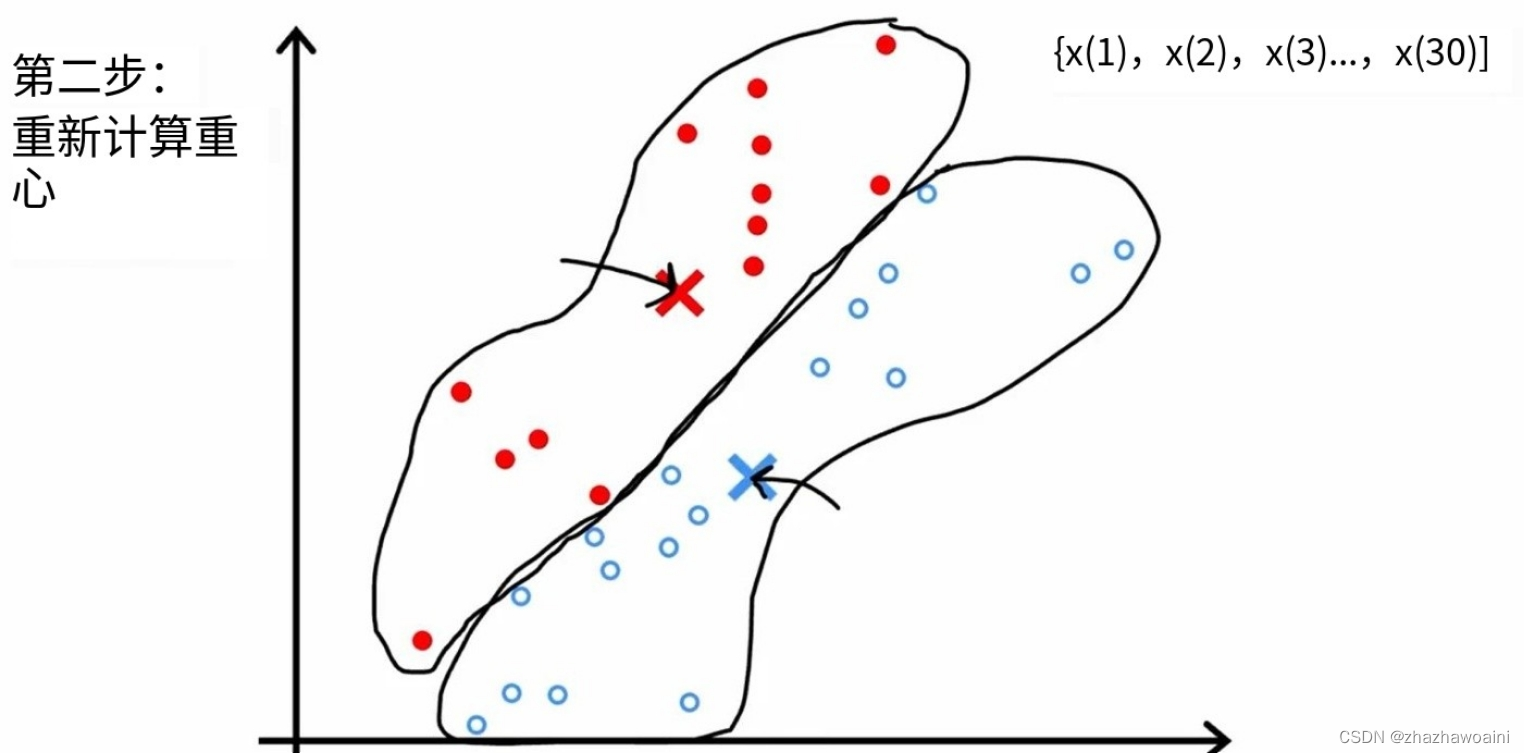
不断重复这两个步骤

优化目标

成本函数=失真函数distortion
在每次迭代中,失真成本函数应该下降或者保持不变
初始化K-means


在顶部选择不错的集群,不太优越的局部最小值在底部
和局部最小的个数有关,只要随机后跳出较小的局部最小域,就是一次优化
选择聚类数量K
Elbow method
使用各种K值运行K-means,将成本函数/失真函数J绘制为数字的函数集群
发现异常事件
异常检测算法会查看未标记的正常事件数据集,从而学会检测异常事件,发出危险信号

密度估计检测异常
为X的概率建立一个模型,找出具有高/低概率的特征X1和X2,

这种类型的欺诈检测既用于查找虚假账户,也经常使用这种算法来尝试识别金融欺诈,例如是否存在非常不寻常的购买模式。也用于制造业,监视集群和数据中心的计算机
高斯正态分布
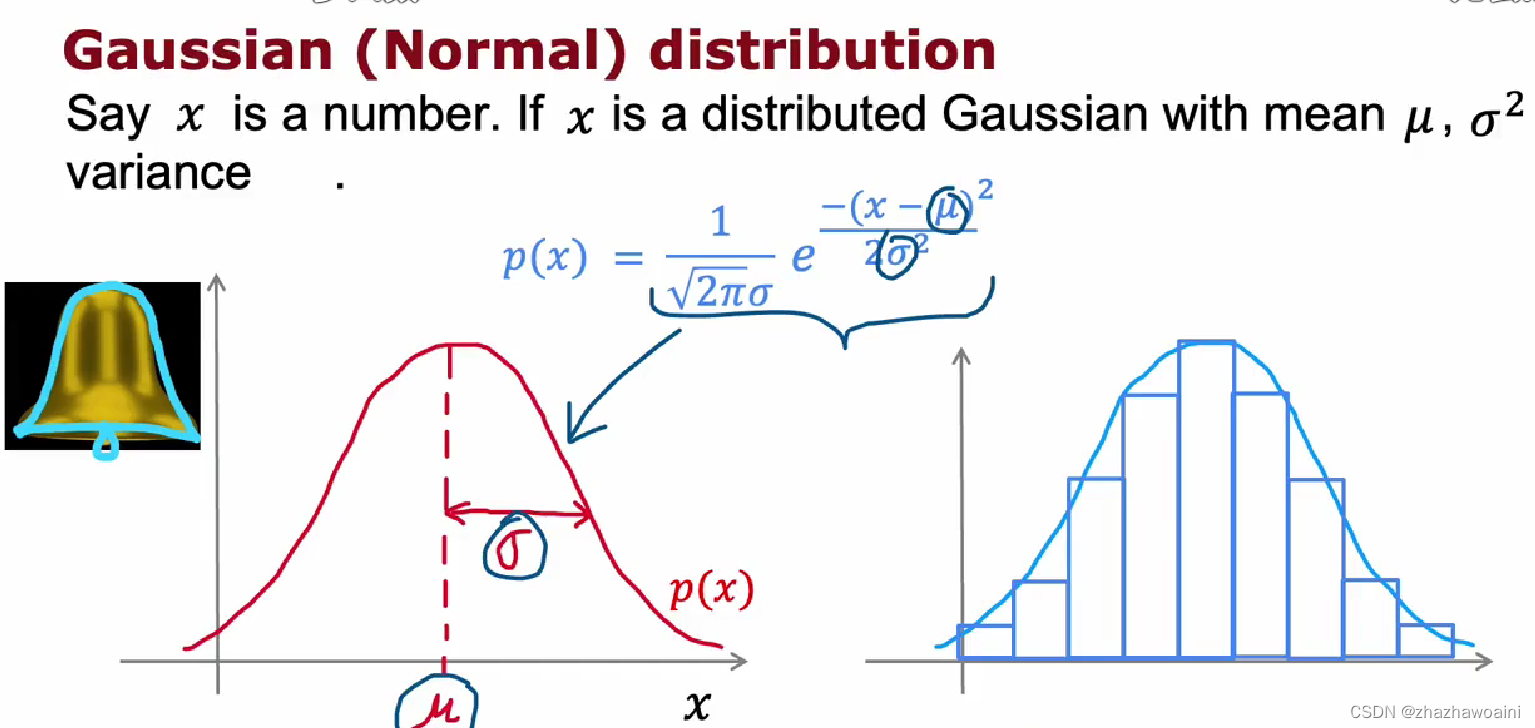
当一个特征或数量关系受到多个相关或不相关的因素共同影响时,它一定服从正态分布
异常检测算法
密度估计


开发与评估异常检测系统
实数评估
如果能以某种方式快速改变算法,比如改变特征或改变一个参数,并且有一种计算数字的方法可以告诉你算法是好是坏,那么它使决定是否坚持对算法的更改变得容易得多。
尽管主要讨论的是未标记数据,但稍微改变一下这个假设,并假设我们有些标记数据,通常包括少量以前观察到的异常。

相当于用无标注的训练集训练出一个特定均值和方差的正态分布,并默认两端的极值是不正常的。再通过测试集来调整阈值,使得阈值之上的都是正常的,阈值之外的都是不正常的。

这种替代方案的缺点是,在调整算法后,没有公平的方法来判断它在未来示例中的实际效果如何,因为没有测试集。但是当数据集很小的时候,特别是有异常的数量时,数据集很小,这可能是最好的选择

异常检测与监督学习对比

本质区别:一个反向排除,一个正向学习
异常检测试图找到全新的正面示例,这些示例可能与以前见过的任何东西都不一样
监督学习会查看正面示例,并尝试确定未来示例是否与已经看到的正面示例相似
选择使用什么特征
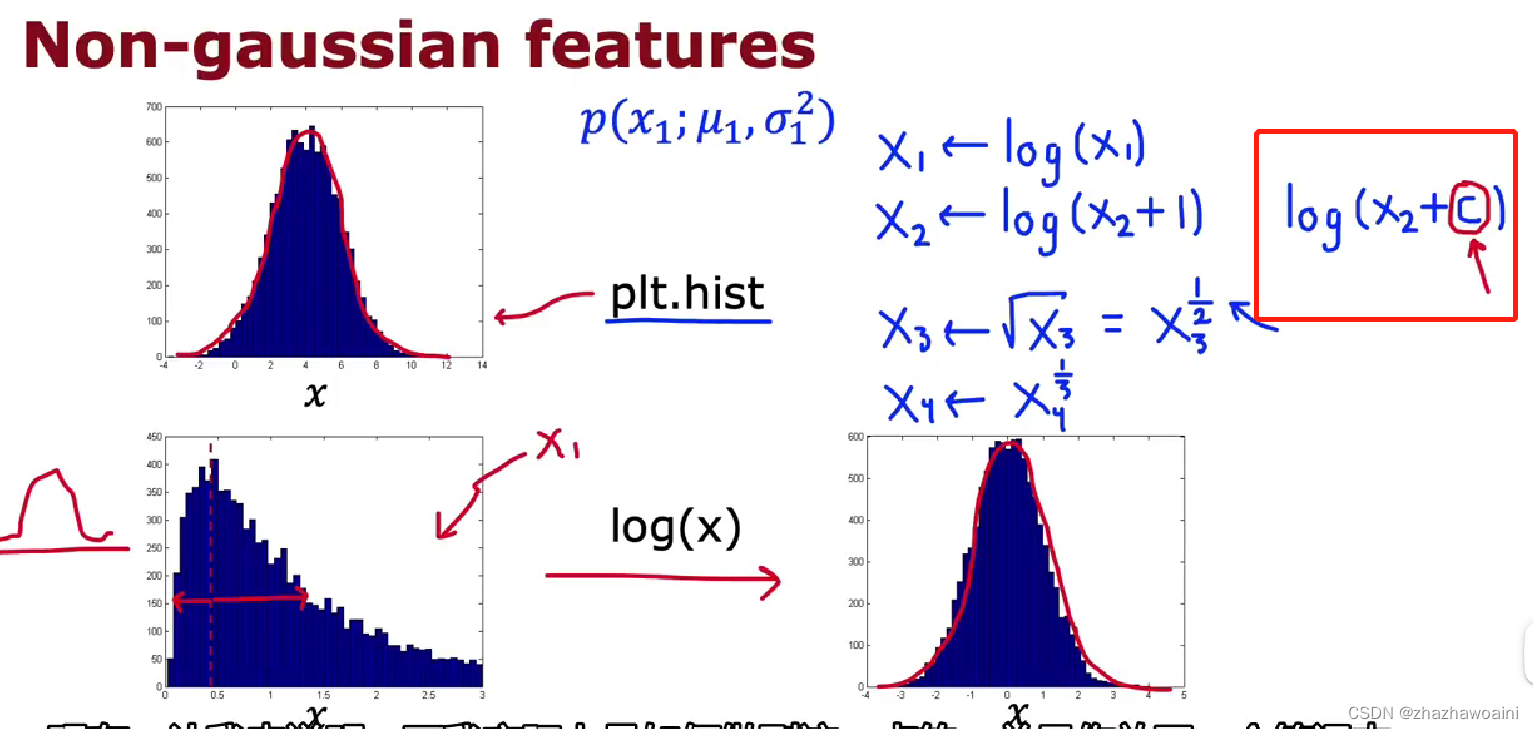
非高斯分布→高斯分布
对训练集转换后,交叉验证和测试集数据也应用相同的转化
训练模型,再查看算法未能检测到交叉验证集中的哪些异常















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









