






 本文介绍了深度学习中线性回归的概念,通过最小化均方误差(MSE)来确定权重向量w,利用梯度下降法优化模型。线性回归模型的目标是找到最佳权重,使得预测值与真实值之间的差距最小。MSE被选用为衡量指标,因为它同时考虑了偏差和方差。
本文介绍了深度学习中线性回归的概念,通过最小化均方误差(MSE)来确定权重向量w,利用梯度下降法优化模型。线性回归模型的目标是找到最佳权重,使得预测值与真实值之间的差距最小。MSE被选用为衡量指标,因为它同时考虑了偏差和方差。
本文主要总结一下深度学习Deep Learning一书中关于线性回归的解释:
我们希望构建一个这样的函数
其中中的每个元素为对每个xi的一个对应系数,也就是一个权重,x中的每个元素和其权重的乘积加和得到y的预测值
我们希望对于测试集能够得到较好的效果,也就是
最小(最小二乘法)
我们没有可我们构建时是拿训练集来构建w的呀
因此我们拿
来代替上述的公式
为求其最小值,我们对其关于w求导(向量求导),并令其等于0,获取对应的w
进一步替换:
![]()
请注意
![]() 是一个向量
是一个向量
因此其2范式为转置和其的乘积,即:(常数省略了)
![]()
展开:
对其3部分求导:
第一部分满足:
由于为对称矩阵(任何一个矩阵的
都为对称矩阵),则结果为
第二部分满足:
结果为:

最后一部分与w无关,为0
我们得到了
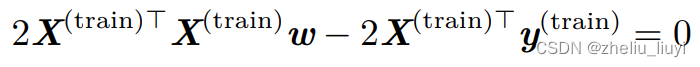 即:
即:

这样,我们就构建了一个线性回归模型了
线性回归的扩展:

补充:
为啥选定了MSE作为衡量指标呢?
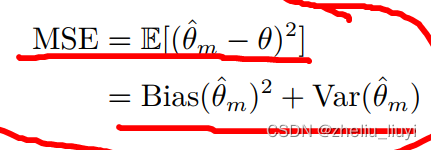
因为MSE既能体现偏差Bias,又能体现方差Var















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









