






这两个概念都是针对训练集的
欠拟合就是你构建的模型太不符合训练集了,导致训练误差很大
过拟合就是你构建的模型符合训练集(不一定哈),而不符合测试集,导致泛化误差(测试误差)很大
这两个误差都与模型的函数空间有关(注意不是样本空间哈)
试想一下,假如为构建模型
你使用模型来构建
你这样的函数空间一定小于最优的函数空间
你会发现你训练误差会很高,而且会随训练样本数增多而逐步增多(因为越接近真实,你的模型就越不合适)
这就是欠拟合
如果你用来构建
你会发现训练误差很低(因为参数很多,比较容易找到一种方案使所有点都在模型上,或者很靠近模型),但一旦换到测试样例,因为你不是专门针对测试样例构建的,那么某些你所构建的模型(毕竟系数很多,训练误差较低的模型可能不止一个)对于随机的可能情况,就可能表现的很差劲,如下图

模拟y=x^2
结果为:
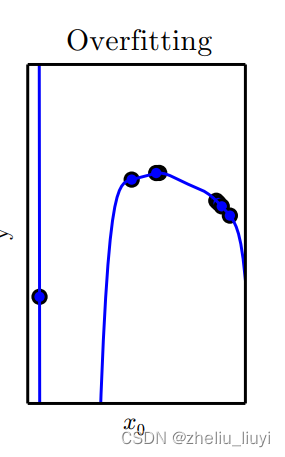
当然也并非是容量越小,也不容易出现过拟合情况,过拟合和欠拟合并非是对立的情况,当容量很小时,过拟合一样会出现,如:

由于现实情况可能产生噪声,即使最优的模型y=x^2也一样与真实的y存在误差,这种误差称为贝叶斯误差
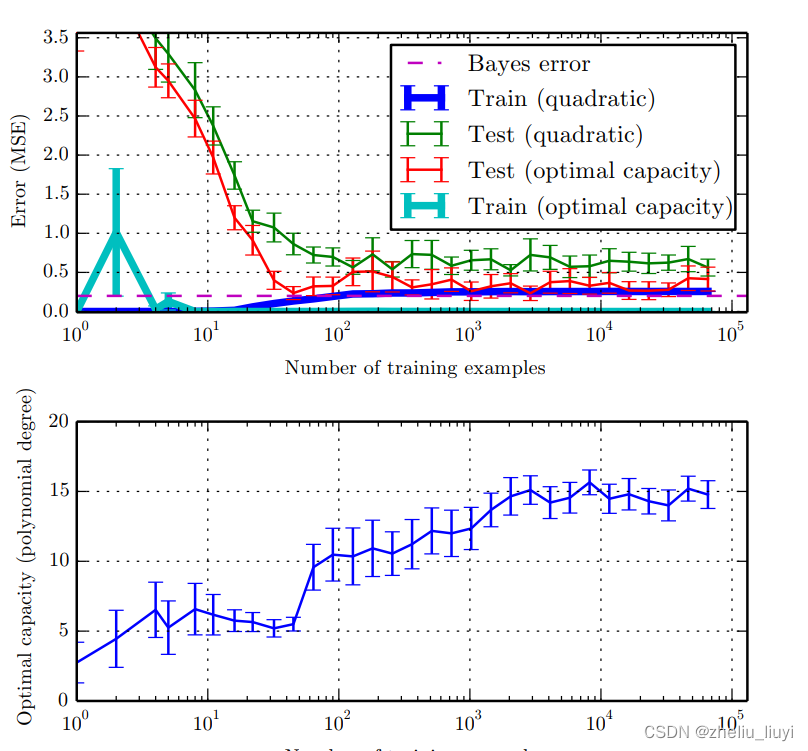
随着数据集的增大,对于低于最佳容量的模型,训练误差会逐渐增大(因为模型容量不足以反应其样例特点,其误差在样本很小时可能会被修正,但随着误差增大就越来越难找到一个满足所有的样例特定的模型了),最终趋近于贝叶斯误差(数据过大会对模型进行一定的修正),而其测试误差就高于贝叶斯误差,毕竟你不能很好反映测试样例的特点
而最佳容量的模型,会随着数据集增大,训练误差几乎趋近于0,因为模型容量足以反应其样例的特点,且对贝叶斯误差具有一定的修正(毕竟你是根据这些数据建的模型),测试误差接近贝叶斯误差,因为模型容量足以反应其特点,但对于贝叶斯误差却没办法;
请注意,最优模型阶数(或者说函数空间)其实并不固定,是随着样本空间增大,整体趋于增大的,而对于任何固定容量的模型(在这里指的是二次模型)的训练误差都至少增至贝叶斯误差。
如图:
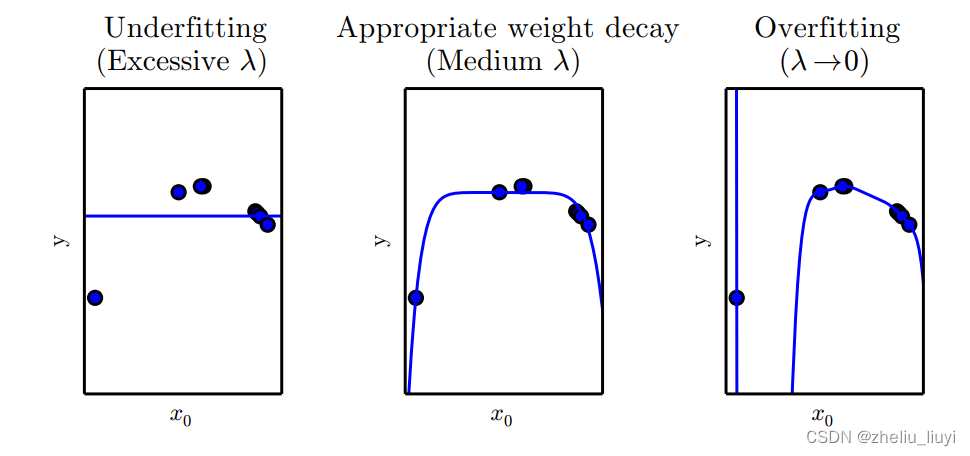
解决过拟合问题的一种思路:
添加偏好因素,在相同的误差下,更偏好于某些函数
如本题添加一个正则式,来进行调整
注意W的每一行表示不同阶数x向量的系数
当λ不等0时,会优先选取W整体较小的函数
效果:















 6006
6006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









