






目录
1. 对比【numpy】和【pytorch】程序,总结并陈述。
2.激活函数Sigmoid用PyTorch自带函数torch.sigmoid(),观察、总结并陈述。
3.激活函数Sigmoid改变为Relu,观察、总结并陈述。
4.损失函数MSE用PyTorch自带函数 t.nn.MSELoss()替代,观察、总结并陈述。
7.权值w1-w8初始值换为随机数,对比“指定权值”的结果,观察、总结并陈述。
前言
希望疫情快点过去吧,这几天都在和另一位同学收全年级的表和统计啥的,真的没有时间写,真累,幸亏之前写的点了
下边是bp算法的推到过程,代数计算和代码实现,虽然之前好多写过不止一次,但是这次我还是写的比较细,这次是真的感受到了回报,下边的推导我也是一步一步推的,可能有点乱,但是在所难免。
最后,希望老师,和各位大佬多教教我。

问题
- 过程推导 - 了解BP原理
- 数值计算 - 手动计算,掌握细节
- 代码实现 - numpy手推 + pytorch自动
过程推导、数值计算,以下三种形式可任选其一:
- 直接在博客用编辑器写
- 在电子设备手写,截图
- 在纸上写,拍照发图

一、过程推导 - 了解BP原理
先放一段我之前写在西瓜书上的注释和部分推导,详细的推导在下边,大家可以先按蒲公英书上的图和这个图对应着看一看,变量的对应,我会写在下边,包含了偏置的推导(上边这个网络没有),但是我感觉以后的网络大部分都是有偏置的。


我感觉咱们之后用的较多的,会是有偏置,并且每个网络节点的个数都是不确定的,所以更重要的是通项公式,所以我把每个都写成了通项公式的形式,下边就是,可能有点勾画,推导的过程在所难免。
说一下,变量的对应关系,也就是上图中的d=2,q=2,l=2,这样网络就对应上了,然后在变量上,w1、w2、w3、w4对应的就是,w5、w6、w7、w8对应的就是
,O1,O2对应就是y1、y2。
好了,看看下边的推导吧,可能有点勾抹,但是一点一点推的话真的再所难免。




如果你感觉上边的不够清楚的话看看南瓜书吧

二、数值计算 - 手动计算,掌握细节
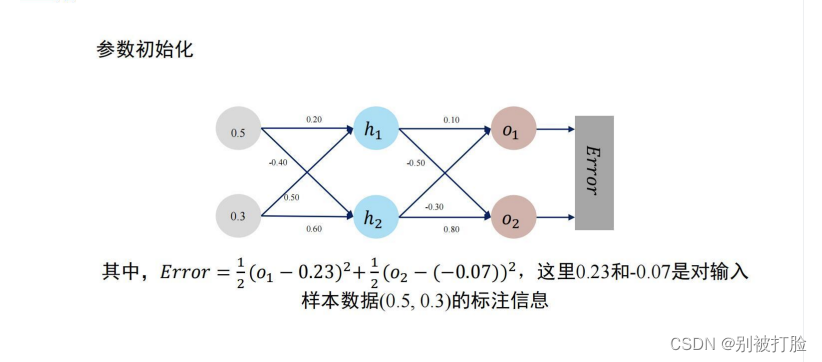
对上边的数值进行计算的过程,其实就是对上边推到出来的公式进行实践的过程,可以理解为将数据带入上式。
老师说这个八个都要手推一遍,所以我就认真一个一个算了了一遍,写在了下边。
公式上边的最后我都展开了,把数带进去就行,但是数是真的难算(呜呜呜)

三、 代码实现 - numpy手推 + pytorch自动
1. 对比【numpy】和【pytorch】程序,总结并陈述。
numpy版的(有点类似于我之前发过的numpy实现神经网络分类鸢尾花):
# coding=gbk
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
a = 1 / (1 + np.exp(-z))
return a
def forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8): # 正向传播
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2)
error = (1 / 2) * (out_o1 - y1) ** 2 + (1 / 2) * (out_o2 - y2) ** 2
return out_o1, out_o2, out_h1, out_h2, error
def back_propagate(out_o1, out_o2, out_h1, out_h2): # 反向传播
d_o1 = out_o1 - y1
d_o2 = out_o2 - y2
d_w5 = d_o1 * out_o1 * (1 - out_o1) * out_h1
d_w7 = d_o1 * out_o1 * (1 - out_o1) * out_h2
d_w6 = d_o2 * out_o2 * (1 - out_o2) * out_h1
d_w8 = d_o2 * out_o2 * (1 - out_o2) * out_h2
d_w1 = (d_w5 + d_w6) * out_h1 * (1 - out_h1) * x1
d_w3 = (d_w5 + d_w6) * out_h1 * (1 - out_h1) * x2
d_w2 = (d_w7 + d_w8) * out_h2 * (1 - out_h2) * x1
d_w4 = (d_w7 + d_w8) * out_h2 * (1 - out_h2) * x2
return d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8
def update_w(step,w1, w2, w3, w4, w5, w6, w7, w8): #梯度下降,更新权值
w1 = w1 - step * d_w1
w2 = w2 - step * d_w2
w3 = w3 - step * d_w3
w4 = w4 - step * d_w4
w5 = w5 - step * d_w5
w6 = w6 - step * d_w6
w7 = w7 - step * d_w7
w8 = w8 - step * d_w8
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
w1, w2, w3, w4, w5, w6, w7, w8 = 0.2, -0.4, 0.5, 0.6, 0.1, -0.5, -0.3, 0.8 # 可以给随机值,为配合PPT,给的指定值
x1, x2 = 0.5, 0.3 # 输入值
y1, y2 = 0.23, -0.07 # 正数可以准确收敛;负数不行。why? 因为用sigmoid输出,y1, y2 在 (0,1)范围内。
N = 10 # 迭代次数
step = 10 # 步长
print("输入值 x0, x1:", x1, x2)
print("输出值 y0, y1:", y1, y2)
print("输入值:x1, x2;",x1, x2, "输出值:y1, y2:", y1, y2)
eli = []
lli = []
for i in range(N):
print("=====第" + str(i) + "轮=====")
# 正向传播
out_o1, out_o2, out_h1, out_h2, error = forward_propagate(x1, x2, y1, y2, w1, w2, w3, w4, w5, w6, w7, w8)
print("正向传播:", round(out_o1, 5), round(out_o2, 5))
print("损失函数:", round(error, 2))
# 反向传播
d_w1, d_w2, d_w3, d_w4, d_w5, d_w6, d_w7, d_w8 = back_propagate(out_o1, out_o2, out_h1, out_h2)
# 梯度下降,更新权值
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(step,w1, w2, w3, w4, w5, w6, w7, w8)
eli.append(i)
lli.append(error)
plt.plot(eli, lli)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()pytorch实现的:
import torch
x = [0.5, 0.3] # x0, x1 = 0.5, 0.3
y = [0.23, -0.07] # y0, y1 = 0.23, -0.07
print("输入值 x0, x1:", x[0], x[1])
print("输出值 y0, y1:", y[0], y[1])
w = [torch.Tensor([0.2]), torch.Tensor([-0.4]), torch.Tensor([0.5]), torch.Tensor(
[0.6]), torch.Tensor([0.1]), torch.Tensor([-0.5]), torch.Tensor([-0.3]), torch.Tensor([0.8])] # 权重初始值
for i in range(0, 8):
w[i].requires_grad = True
print("权值w0-w7:")
for i in range(0, 8):
print(w[i].data, end=" ")
def forward_propagate(x): # 计算图
in_h1 = w[0] * x[0] + w[2] * x[1]
out_h1 = torch.sigmoid(in_h1)
in_h2 = w[1] * x[0] + w[3] * x[1]
out_h2 = torch.sigmoid(in_h2)
in_o1 = w[4] * out_h1 + w[6] * out_h2
out_o1 = torch.sigmoid(in_o1)
in_o2 = w[5] * out_h1 + w[7] * out_h2
out_o2 = torch.sigmoid(in_o2)
print("正向计算,隐藏层h1 ,h2:", end="")
print(out_h1.data, out_h2.data)
print("正向计算,预测值o1 ,o2:", end="")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
def loss(x, y): # 损失函数
y_pre = forward_propagate(x) # 前向传播
loss_mse = (1 / 2) * (y_pre[0] - y[0]) ** 2 + (1 / 2) * (y_pre[1] - y[1]) ** 2 # 考虑 : t.nn.MSELoss()
print("损失函数(均方误差):", loss_mse.item())
return loss_mse
if __name__ == "__main__":
for k in range(1):
print("\n=====第" + str(k+1) + "轮=====")
l = loss(x, y) # 前向传播,求 Loss,构建计算图
l.backward() # 反向传播,求出计算图中所有梯度存入w中. 自动求梯度,不需要人工编程实现。
print("w的梯度: ", end=" ")
for i in range(0, 8):
print(round(w[i].grad.item(), 2), end=" ") # 查看梯度
step = 1 # 步长
for i in range(0, 8):
w[i].data = w[i].data - step * w[i].grad.data # 更新权值
w[i].grad.data.zero_() # 注意:将w中所有梯度清零
print("\n更新后的权值w:")
for i in range(0, 8):
print(w[i].data, end=" ")其实对于numpy实现的我之前就发过并且那个更负责一代点,但是现在再看,那个不太系统,对于pytorch实现,我感觉其实有点像搭积木,它都是封装好的,只需要把需要的东西搭上去就行了,所以它的代码量较少,但是如果只学框架不学原理的话,就像我之前说的,老师说过,如果人工智能专业的,不懂原理的话,那么和其他专业有啥区别的,我感觉非常对。
下边从结果上看一下(注意由于数值原因从第0轮开始)
numpy的结果为:
10轮
=====第10轮=====
正向传播: 0.26348 0.11236
损失函数: 0.02
100轮
=====第100轮=====
正向传播: 0.23242 0.04219
损失函数: 0.01
1000轮
=====第1000轮=====
正向传播: 0.23038 0.00954
损失函数: 0.0
pytorch的结果为:
10轮
=====第10轮=====
正向计算,隐藏层h1 ,h2:tensor([0.5809]) tensor([0.4857])
正向计算,预测值o1 ,o2:tensor([0.4109]) tensor([0.3647])
损失函数(均方误差): 0.11082295328378677
w的梯度: -0.02 0.0 -0.01 0.0 0.03 0.06 0.02 0.05
更新后的权值w:
tensor([0.3273]) tensor([-0.4547]) tensor([0.5764]) tensor([0.5672]) tensor([-0.1985]) tensor([-1.2127]) tensor([-0.5561]) tensor([0.1883])
100轮
=====第100轮=====
正向计算,隐藏层h1 ,h2:tensor([0.6863]) tensor([0.5281])
正向计算,预测值o1 ,o2:tensor([0.2378]) tensor([0.0736])
损失函数(均方误差): 0.010342842899262905
w的梯度: -0.0 -0.0 -0.0 -0.0 0.0 0.01 0.0 0.01
更新后的权值w:
tensor([0.9865]) tensor([-0.2037]) tensor([0.9719]) tensor([0.7178]) tensor([-0.8628]) tensor([-2.8459]) tensor([-1.0866]) tensor([-1.1112])
1000轮
=====第1000轮=====
正向计算,隐藏层h1 ,h2:tensor([0.7750]) tensor([0.5920])
正向计算,预测值o1 ,o2:tensor([0.2296]) tensor([0.0098])
损失函数(均方误差): 0.003185197012498975
w的梯度: -0.0 -0.0 -0.0 -0.0 -0.0 0.0 -0.0 0.0
更新后的权值w:
tensor([1.6515]) tensor([0.1770]) tensor([1.3709]) tensor([0.9462]) tensor([-0.7798]) tensor([-4.2741]) tensor([-1.0236]) tensor([-2.1999])
从上边可以看出,两个方法都可以令损失函数趋于零,但是根据昨天和老师商量的经验,这个应该是到达了,全局最优解。
2.激活函数Sigmoid用PyTorch自带函数torch.sigmoid(),观察、总结并陈述。
先说一下这个函数,因为之前其实说过,还做过对比,这个其实和torch.nn.functuonal.sigmoid差不多只是,后边那个要弃用了,所以大家还是用这个,并且在参数的设置上还是有很大区别的。
这个要注意,pytorch中好多函数,都是一个类的封装方式,和咱们写的是有区别的,咱们写的只有数值的计算,虽然大致差不多,但是最好注意一下。
下边是pytorch的官方文档大家看一下吧(注意这个别名叫下边的函数)

这个是真的学到到了,没想到别名叫这个,真的学到了,这个是官方文档,大家一定要多看官方文档。
结果大家可以看一下
10轮
=====第10轮=====
正向计算,隐藏层h1 ,h2:tensor([0.5809]) tensor([0.4857])
正向计算,预测值o1 ,o2:tensor([0.4109]) tensor([0.3647])
损失函数(均方误差): 0.11082295328378677
w的梯度: -0.02 0.0 -0.01 0.0 0.03 0.06 0.02 0.05
更新后的权值w:
tensor([0.3273]) tensor([-0.4547]) tensor([0.5764]) tensor([0.5672]) tensor([-0.1985]) tensor([-1.2127]) tensor([-0.5561]) tensor([0.1883])
100轮
=====第100轮=====
正向计算,隐藏层h1 ,h2:tensor([0.6863]) tensor([0.5281])
正向计算,预测值o1 ,o2:tensor([0.2378]) tensor([0.0736])
损失函数(均方误差): 0.010342842899262905
w的梯度: -0.0 -0.0 -0.0 -0.0 0.0 0.01 0.0 0.01
更新后的权值w:
tensor([0.9865]) tensor([-0.2037]) tensor([0.9719]) tensor([0.7178]) tensor([-0.8628]) tensor([-2.8459]) tensor([-1.0866]) tensor([-1.1112])
1000轮
=====第1000轮=====
正向计算,隐藏层h1 ,h2:tensor([0.7750]) tensor([0.5920])
正向计算,预测值o1 ,o2:tensor([0.2296]) tensor([0.0098])
损失函数(均方误差): 0.003185197012498975
w的梯度: -0.0 -0.0 -0.0 -0.0 -0.0 0.0 -0.0 0.0
更新后的权值w:
tensor([1.6515]) tensor([0.1770]) tensor([1.3709]) tensor([0.9462]) tensor([-0.7798]) tensor([-4.2741]) tensor([-1.0236]) tensor([-2.1999])
从中可以看出,几乎没有变化,但是torch中封装好的直接调用,一定会提高时间效率。
3.激活函数Sigmoid改变为Relu,观察、总结并陈述。
直接看官方文档吧,没有比官方文档,更好的东西给了


看一下输出的结果:
10轮
=====第10轮=====
正向计算,隐藏层h1 ,h2:tensor([0.5652]) tensor([0.4948])
正向计算,预测值o1 ,o2:tensor([0.4106]) tensor([0.])
损失函数(均方误差): 0.018752072006464005
w的梯度: -0.0 -0.0 -0.0 -0.0 0.02 0.0 0.02 0.0
更新后的权值w:
tensor([0.2193]) tensor([-0.3982]) tensor([0.5116]) tensor([0.6011]) tensor([-0.1951]) tensor([-0.6480]) tensor([-0.5578]) tensor([0.6700])
100轮
=====第100轮=====
正向计算,隐藏层h1 ,h2:tensor([0.5785]) tensor([0.5173])
正向计算,预测值o1 ,o2:tensor([0.2466]) tensor([0.])
损失函数(均方误差): 0.0025875307619571686
w的梯度: -0.0 -0.0 -0.0 -0.0 0.0 0.0 0.0 0.0
更新后的权值w:
tensor([0.2985]) tensor([-0.2684]) tensor([0.5591]) tensor([0.6790]) tensor([-0.8873]) tensor([-0.6480]) tensor([-1.1704]) tensor([0.6700])
1000轮
=====第1000轮=====
正向计算,隐藏层h1 ,h2:tensor([0.5812]) tensor([0.5209])
正向计算,预测值o1 ,o2:tensor([0.2300]) tensor([0.])
损失函数(均方误差): 0.0024500000290572643
w的梯度: -0.0 -0.0 -0.0 -0.0 0.0 0.0 0.0 0.0
更新后的权值w:
tensor([0.3140]) tensor([-0.2478]) tensor([0.5684]) tensor([0.6913]) tensor([-0.9666]) tensor([-0.6480]) tensor([-1.2413]) tensor([0.6700])
通过结果就可以看出在到达最优解的速度上,relu函数相较于sigmoid函数来说是较快的,并且在精度上也是较好的
后边说一些查找到的资料,我综合了一下 链接 这个挺好的
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
并且sigmoid的导数只有在0附近的时候有比较好的激活性,在正负饱和区的梯度都接近于0,所以这会造成梯度弥散,而relu函数在大于0的部分梯度为常数,所以不会产生梯度弥散现象。第二,relu函数在负半区的导数为0 ,所以一旦神经元激活值进入负半区,那么梯度就会为0,也就是说这个神经元不会经历训练,即所谓的稀疏性。第三,relu函数的导数计算更快,程序实现就是一个if-else语句,而sigmoid函数要进行浮点四则运算。综上,relu是一个非常优秀的激活函数
4.损失函数MSE用PyTorch自带函数 t.nn.MSELoss()替代,观察、总结并陈述。
首先,说一个之前说过的问题,nn生成的是一个类似于迭代器的东西(这个我在上一篇博客中说过了,大家可以去看一看),所以大家直接改的话是会报错的。
因为,如果去看官方文档的话,会发现是没有输入数据的参数的,所以只能先生成一个迭代器,有点类似于类的用法。官方文档如下:

所以进行如下的更改,也就是
def loss_fuction(x1, x2, y1, y2):
y1_pred, y2_pred = forward_propagate(x1, x2)
lossfuction = torch.nn.MSELoss()
loss1=lossfuction(y1_pred,y1)
loss2=lossfuction(y2_pred,y2)
loss = loss1 + loss2
print("损失函数(均方误差):", loss.item())
return loss同时也要注意修改变量,输入的变量和标签,进行如下修改:
x1, x2 = torch.Tensor([0.5]), torch.Tensor([0.3])
y1, y2 = torch.Tensor([0.23]), torch.Tensor([-0.07])
print("=====输入值:x1, x2;真实输出值:y1, y2=====")
print(x1, x2, y1, y2)
w1, w2, w3, w4, w5, w6, w7, w8 = torch.Tensor([0.2]), torch.Tensor([-0.4]), torch.Tensor([0.5]), torch.Tensor(
[0.6]), torch.Tensor([0.1]), torch.Tensor([-0.5]), torch.Tensor([-0.3]), torch.Tensor([0.8]) # 权重初始值
w1.requires_grad = True
w2.requires_grad = True
w3.requires_grad = True
w4.requires_grad = True
w5.requires_grad = True
w6.requires_grad = True
w7.requires_grad = True
w8.requires_grad = True运行结果为:
10轮
=====第10轮=====
正向计算:o1 ,o2
tensor([0.3609]) tensor([0.2613])
损失函数(均方误差): 0.1268753707408905
grad W: -0.03 -0.01 -0.02 -0.0 0.04 0.08 0.03 0.06
更新后的权值
tensor([0.4696]) tensor([-0.4351]) tensor([0.6618]) tensor([0.5790]) tensor([-0.4145]) tensor([-1.6882]) tensor([-0.7343]) tensor([-0.2040])
100轮
=====第100轮=====
正向计算:o1 ,o2
tensor([0.2280]) tensor([0.0412])
损失函数(均方误差): 0.012363419868052006
grad W: -0.0 -0.0 -0.0 -0.0 -0.0 0.01 -0.0 0.0
更新后的权值
tensor([1.1885]) tensor([-0.1073]) tensor([1.0931]) tensor([0.7756]) tensor([-0.8715]) tensor([-3.3002]) tensor([-1.0941]) tensor([-1.4604])
1000轮
=====第1000轮=====
正向计算:o1 ,o2
tensor([0.2298]) tensor([0.0050])
损失函数(均方误差): 0.005628134589642286
grad W: -0.0 -0.0 -0.0 -0.0 -0.0 0.0 -0.0 0.0
更新后的权值
tensor([1.8441]) tensor([0.3147]) tensor([1.4865]) tensor([1.0288]) tensor([-0.7469]) tensor([-4.6932]) tensor([-0.9992]) tensor([-2.5217])
从结果可以看出,这个手写的函数的效果会比直接调库的效果要好,但是我感觉调库的时间效率较高,但是不知道为什么会让精度下降,希望各位大佬给解读一下。
5.损失函数MSE改变为交叉熵,观察、总结并陈述。
同样还是我说过的问题,我在上一篇博客中说过的问题,nn生成的都是一个迭代器,都需要提前生成迭代器,才能进行赋值。
还是直接看官方文档吧,越来越感觉官方文档是真的吊呀,拜一拜。

这里的loss函数为:
def loss_fuction(x1, x2, y1, y2):
y1_pred, y2_pred = forward_propagate(x1, x2)
lossfuction = torch.nn.CrossEntropyLoss()
y_pred = torch.stack([y1_pred, y2_pred], dim=1)
y = torch.stack([y1, y2], dim=1)
loss = lossfuction(y_pred)
print("损失函数(均方误差):", loss.item())
return loss
一定要是这个形式,这里要注意一个问题,直接更改的话会报错
IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)
为什么呢,查了查好多之后发现, 这是维度不一致的原因,而stack的函数在之前的博客中就写过,功能:沿一个新维度对输入张量序列进行连接,序列中所有张量应为相同形状。
运行结果为:
10轮
=====第10轮=====
正向计算:o1 ,o2
tensor([0.5249]) tensor([0.4794])
损失函数(均方误差): 0.1041153073310852
grad W: -0.0 0.0 -0.0 0.0 -0.02 0.02 -0.02 0.02
更新后的权值
tensor([0.2364]) tensor([-0.4437]) tensor([0.5218]) tensor([0.5738]) tensor([0.3117]) tensor([-0.7117]) tensor([-0.1158]) tensor([0.6158])
100轮
=====第100轮=====
正向计算:o1 ,o2
tensor([0.8455]) tensor([0.1529])
损失函数(均方误差): 0.016428470611572266
grad W: -0.01 -0.0 -0.0 -0.0 -0.01 0.01 -0.01 0.01
更新后的权值
tensor([0.9026]) tensor([-0.3255]) tensor([0.9216]) tensor([0.6447]) tensor([1.7590]) tensor([-2.1559]) tensor([1.0382]) tensor([-0.5358])
1000轮
=====第1000轮=====
正向计算:o1 ,o2
tensor([0.9929]) tensor([0.0072])
损失函数(均方误差): -0.018253758549690247
grad W: -0.0 -0.0 -0.0 -0.0 -0.0 0.0 -0.0 0.0
更新后的权值
tensor([2.2809]) tensor([0.6580]) tensor([1.7485]) tensor([1.2348]) tensor([3.8104]) tensor([-4.2013]) tensor([2.5933]) tensor([-2.0866])
首先,说一下出现负数的情况,充分说明了,交叉熵损失函数适用于分类的特性,把交叉熵损失函数和分类时一样,用sigmoid转化即可。
6.改变步长,训练次数,观察、总结并陈述。
调参的话,这次要好好调一调了,之前要不是问了问老师,总是不敢放手调参。





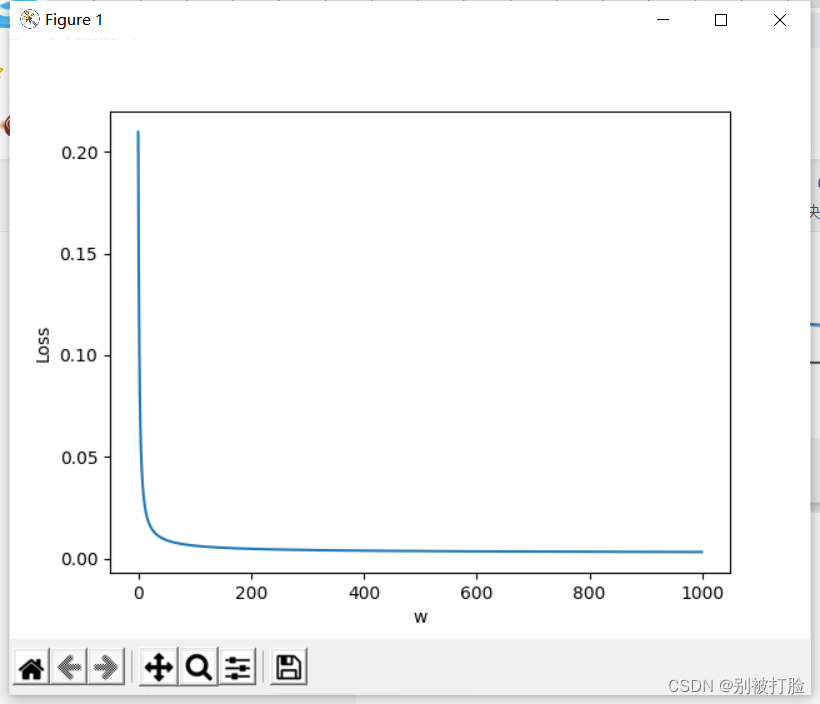











通过结果可以看出step=5时,在10轮左右就出现最优值,但是并且最优值和其他两个step到达最优值的时候结果是一致的,而在step=1时,在10轮左右就出现最优值,但是并且最优值和其他两个step到达最优值的时候结果是一致的,但是会发现step=0.01时,迭代了1000次也没有达到最优质
我又不死心试了一下0.01,结果仍然证明效果并不好,这样的结果证明了,老师,和我说的,step与数据集有很大的关系,从中可以知道,不能以经验来取step,就是要一点一点试。
我们从上边可以得到的结论是,如果选取合适的step并不会影响最优解的取得,反而会减少迭代的次数,提高时间效率。
7.权值w1-w8初始值换为随机数,对比“指定权值”的结果,观察、总结并陈述。
代码为:
只需将赋值变为torch.rand函数即可
# coding=gbk
import torch
x1, x2 = torch.Tensor([0.5]), torch.Tensor([0.3])
y1, y2 = torch.Tensor([0.23]), torch.Tensor([-0.07])
print("=====输入值:x1, x2;真实输出值:y1, y2=====")
print(x1, x2, y1, y2)
w1, w2, w3, w4, w5, w6, w7, w8 = torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1), torch.randn(1, 1) #权重初始值
w1.requires_grad = True
w2.requires_grad = True
w3.requires_grad = True
w4.requires_grad = True
w5.requires_grad = True
w6.requires_grad = True
w7.requires_grad = True
w8.requires_grad = True
def sigmoid(z):
a = 1 / (1 + torch.exp(-z))
return a
def forward_propagate(x1, x2):
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1) # out_h1 = torch.sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2) # out_h2 = torch.sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1) # out_o1 = torch.sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2) # out_o2 = torch.sigmoid(in_o2)
print("正向计算:o1 ,o2")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
def loss_fuction(x1, x2, y1, y2):
y1_pred, y2_pred = forward_propagate(x1, x2)
lossfuction = torch.nn.CrossEntropyLoss()
y_pred = torch.stack([y1_pred, y2_pred], dim=1)
y = torch.stack([y1, y2], dim=1)
loss = lossfuction(y_pred,y)
print("损失函数(均方误差):", loss.item())
return loss
def update_w(w1, w2, w3, w4, w5, w6, w7, w8):
# 步长
step = 1
w1.data = w1.data - step * w1.grad.data
w2.data = w2.data - step * w2.grad.data
w3.data = w3.data - step * w3.grad.data
w4.data = w4.data - step * w4.grad.data
w5.data = w5.data - step * w5.grad.data
w6.data = w6.data - step * w6.grad.data
w7.data = w7.data - step * w7.grad.data
w8.data = w8.data - step * w8.grad.data
w1.grad.data.zero_() # 注意:将w中所有梯度清零
w2.grad.data.zero_()
w3.grad.data.zero_()
w4.grad.data.zero_()
w5.grad.data.zero_()
w6.grad.data.zero_()
w7.grad.data.zero_()
w8.grad.data.zero_()
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
print("=====更新前的权值=====")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)
for i in range(10):
print("=====第" + str(i+1) + "轮=====")
L = loss_fuction(x1, x2, y1, y2) # 前向传播,求 Loss,构建计算图
L.backward() # 自动求梯度,不需要人工编程实现。反向传播,求出计算图中所有梯度存入w中
print("\tgrad W: ", round(w1.grad.item(), 2), round(w2.grad.item(), 2), round(w3.grad.item(), 2),
round(w4.grad.item(), 2), round(w5.grad.item(), 2), round(w6.grad.item(), 2), round(w7.grad.item(), 2),
round(w8.grad.item(), 2))
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(w1, w2, w3, w4, w5, w6, w7, w8)
print("更新后的权值")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)
运行结果为:
10轮
=====第10轮=====
正向计算:o1 ,o2
tensor([5.1180]) tensor([0.])
损失函数(CrossEntropyLoss): -0.3573055565357208
grad W: -0.08 -0.07 -0.05 -0.04 -0.09 0.0 -0.08 0.0
100轮
=====第100轮=====
正向计算:o1 ,o2
tensor([6998288.5000]) tensor([0.])
损失函数(CrossEntropyLoss): -489880.1875
grad W: -93.3 -77.44 -55.98 -46.46 -108.81 0.0 -90.31 0.0
500轮
=====第500轮=====
正向计算:o1 ,o2
tensor([1.2854e+34]) tensor([0.])
损失函数(CrossEntropyLoss): -8.997903731118773e+32
grad W: -3998669581844480.0 -3318942688870400.0 -2399201749106688.0 -1991365747539968.0 -4663210812637184.0 0.0 -3870519032020992.0 0.0
更新后的权值
tensor([1.0596e+17]) tensor([8.7951e+16]) tensor([6.3578e+16]) tensor([5.2771e+16]) tensor([1.2357e+17]) tensor([-0.0035]) tensor([1.0257e+17]) tensor([-0.1931])
从中可已看出,这个有很大的随机性,如果生成的初始值较好就会,较快达到收敛,如果初始值较不好时,极端情况下甚至不会达到收敛。这种情况下,可以考虑类似于k-means++的那种一样,有倾向性的去挑选初始值。
8.权值w1-w8初始值换为0,观察、总结并陈述。
代码为:
只需要将tensor中的数全部换为0即可
# coding=gbk
import torch
x1, x2 = torch.Tensor([0.5]), torch.Tensor([0.3])
y1, y2 = torch.Tensor([0.23]), torch.Tensor([-0.07])
print("=====输入值:x1, x2;真实输出值:y1, y2=====")
print(x1, x2, y1, y2)
w1, w2, w3, w4, w5, w6, w7, w8 = torch.Tensor([0]), torch.Tensor([0]), torch.Tensor([0]), torch.Tensor(
[0]), torch.Tensor([0]), torch.Tensor([0]), torch.Tensor([0]), torch.Tensor([0]) # 权重初始值
w1.requires_grad = True
w2.requires_grad = True
w3.requires_grad = True
w4.requires_grad = True
w5.requires_grad = True
w6.requires_grad = True
w7.requires_grad = True
w8.requires_grad = True
def sigmoid(z):
a = 1 / (1 + torch.exp(-z))
return a
def forward_propagate(x1, x2):
in_h1 = w1 * x1 + w3 * x2
out_h1 = sigmoid(in_h1) # out_h1 = torch.sigmoid(in_h1)
in_h2 = w2 * x1 + w4 * x2
out_h2 = sigmoid(in_h2) # out_h2 = torch.sigmoid(in_h2)
in_o1 = w5 * out_h1 + w7 * out_h2
out_o1 = sigmoid(in_o1) # out_o1 = torch.sigmoid(in_o1)
in_o2 = w6 * out_h1 + w8 * out_h2
out_o2 = sigmoid(in_o2) # out_o2 = torch.sigmoid(in_o2)
print("正向计算:o1 ,o2")
print(out_o1.data, out_o2.data)
return out_o1, out_o2
def loss_fuction(x1, x2, y1, y2):
y1_pred, y2_pred = forward_propagate(x1, x2)
lossfuction = torch.nn.CrossEntropyLoss()
y_pred = torch.stack([y1_pred, y2_pred], dim=1)
y = torch.stack([y1, y2], dim=1)
loss = lossfuction(y_pred,y)
print("损失函数(均方误差):", loss.item())
return loss
def update_w(w1, w2, w3, w4, w5, w6, w7, w8):
# 步长
step = 1
w1.data = w1.data - step * w1.grad.data
w2.data = w2.data - step * w2.grad.data
w3.data = w3.data - step * w3.grad.data
w4.data = w4.data - step * w4.grad.data
w5.data = w5.data - step * w5.grad.data
w6.data = w6.data - step * w6.grad.data
w7.data = w7.data - step * w7.grad.data
w8.data = w8.data - step * w8.grad.data
w1.grad.data.zero_() # 注意:将w中所有梯度清零
w2.grad.data.zero_()
w3.grad.data.zero_()
w4.grad.data.zero_()
w5.grad.data.zero_()
w6.grad.data.zero_()
w7.grad.data.zero_()
w8.grad.data.zero_()
return w1, w2, w3, w4, w5, w6, w7, w8
if __name__ == "__main__":
print("=====更新前的权值=====")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)
for i in range(1000):
print("=====第" + str(i+1) + "轮=====")
L = loss_fuction(x1, x2, y1, y2) # 前向传播,求 Loss,构建计算图
L.backward() # 自动求梯度,不需要人工编程实现。反向传播,求出计算图中所有梯度存入w中
print("\tgrad W: ", round(w1.grad.item(), 2), round(w2.grad.item(), 2), round(w3.grad.item(), 2),
round(w4.grad.item(), 2), round(w5.grad.item(), 2), round(w6.grad.item(), 2), round(w7.grad.item(), 2),
round(w8.grad.item(), 2))
w1, w2, w3, w4, w5, w6, w7, w8 = update_w(w1, w2, w3, w4, w5, w6, w7, w8)
print("更新后的权值")
print(w1.data, w2.data, w3.data, w4.data, w5.data, w6.data, w7.data, w8.data)运行的结果为:
10轮
=====第10轮=====
正向计算:o1 ,o2
tensor([0.5417]) tensor([0.4583])
损失函数(均方误差): 0.0985325276851654
grad W: -0.0 -0.0 -0.0 -0.0 -0.02 0.02 -0.02 0.02
100轮
=====第100轮=====
正向计算:o1 ,o2
tensor([0.8406]) tensor([0.1594])
损失函数(均方误差): 0.01783166080713272
grad W: -0.01 -0.01 -0.0 -0.0 -0.01 0.01 -0.01 0.01
1000轮
=====第1000轮=====
正向计算:o1 ,o2
tensor([0.9932]) tensor([0.0068])
损失函数(均方误差): -0.018344268202781677
grad W: -0.0 -0.0 -0.0 -0.0 -0.0 0.0 -0.0 0.0
更新后的权值
tensor([1.7782]) tensor([1.7782]) tensor([1.0669]) tensor([1.0669]) tensor([3.2392]) tensor([-3.2392]) tensor([3.2392]) tensor([-3.2392])
可以认为,在这次中都取零比随机取,一般要好一点,但是和随机去相比可以发现,最一开始的
前100轮内的损失上升,但是最后当到达1000轮时的最优值时相同的。
9.全面总结反向传播原理和编码实现,认真写心得体会。
首先,之前写的那么细,感觉终于有了回报,以前都是感觉是值得的,现在的感受就是,那就是值得的,因为好多人在写nn的函数的时候,好多人都直接去代数,都出现了问题,而我在上一张博客中就说了,他是生成一个类似于迭代器的东西。
其次,是终于不在一调参就往0.01调了,真的理解了,老师给我说的,调参与数据集有关的概念,这次大量的调参真的学到了好多,虽然最后也试了一次0.01,但是那是为了证明0.01的不行。
其次,是感觉对神经网络又理解了好多,以前都是会推bp算法,但是这次是,代数计算,并且还是带了8个数,感觉真的熟悉了过程,以前推只是会推了,有点背过的感觉,这次带了带数,还是有些不确定的地方,感觉代数计算真的有用,强烈推荐8个都算一遍。
其次,是感觉又了解了了解框架的使用,以前的时候,使用框架有点生搬硬套的感觉,都是照着别人的架子,自己搭,但是这次numpy与pytorch对用感觉真理解了好多,感觉又熟练了一点。
其次,是有了解了好多函数的性质,以前有的的看过网课,但是那没有讲得这么细,那只是一个很泛泛的东西,没有实际操作这么细过,没有这么考虑过,只是一种很空泛的感觉,但是这次以后感觉真的明白了好多。
其次,是感觉真的累,公式一点一点推,数一代一点算,这个真的费劲,包括后边的改代码,但是我相信这都是值得的。
最后,希望疫情快点过去吧,我和其她一位同学,这几天在收全年级的表啥的,做统计啥的,真的累,而且真的没有时间,大块大块的时间来写作业,幸亏之前就开始写了,要不真不见的这会能交上
最后,当然是谢谢魏老师,感谢魏老师在学习和生活上的关心,希望大家做好防护,共盼春来。















 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









