







使用Python中的BeautifulSoup(bs4)包抓取暴走漫画网站中的热门帖子中的图片。
首先附上参考资料,之前在OSC上有人写了个抓取豆瓣妹子图片的帖子,参考人家的代码,自己重新弄了一下,当然不能像豆瓣妹子那样直接搜索所有的<img>标签啦,因为网页中含有广告啊,头像啊,表情之类的,我只想抓取热门中的内容图片嘛。
这时候就要充分的利用BeautifulSoup啦,先附上参考资料
首先分析暴走漫画网站的html,发现所有的热门内容的<img>标签都在class为img-wrap的<div>中,这样就好办了,完全避免了抓取除了这个div之外的图片,首先需要获取页面中class为‘img-wrap’的所有<div>,使用以下代码:
my_girl = soup.find_all('div',class_='img-wrap')for girl in my_girl:
jokes = girl.find('img')
link = jokes.get('src')在这里要提醒以下,find_all与find是不同的,千万不要用混了,find_all是返回的list对象,而find只是返回第一个,找到了就返回,所以在find_all之后,一定要用for循环遍历一遍,这样就可以啦。
整体的实现思路如下:
1. 首先创建文件夹,取名“暴走漫画”,就在当前目录下,存在的话就不重新创建了
2. 然后写一个函数,def,起名叫page_loop,默认page是1
3. 定义url,page就是url中分页的参数,当然了,url也可以函数传进来或者是系统读取进来,后期改进吧,使用BeautifulSoup打开URL
4. 然后就是上面的找标签操作了,如果要获取其他的网页中的其他信息,一定要好好地分析下网页的结构
5. 获取<img>标签的<src>属性之后,把这个连接取出来,使用with,把链接中的图片存到文件夹中
6. page+1,递归函数,获取下一页的图片
短短的二三十行代码,很有效,4不4.你也可以使用py2exe将程序转成Windows上可执行的,然后发给盆友吧,我就是这么做的。
需要改进的地方:
1. Shao说,最好可以手输URL或者读取配置文件的URL,获取图片,要是文件夹名称可以自己定义就更好了,可以弄
2. 页面结束判断没有做啊,到时候页面不存在就会报404,程序也会退出了,需改进
3. 在存储图片的时候,取的是原图的7位名称(src中URL后11位),如果不够7位就会报错,我之前的做法是用当前时间+随机字母+文件名后一位作为新的图片的文件名,但是这么操作也有问题,就是如果我重新爬的话,图片会重复,有待商榷
4. 如果用上多线程抓取和分布式抓取,就更好了,效率更高
5. 抓取的频率也不要太快,如果被检测了,就抓不到了,最好写个延时
需要注意的地方:
Python对缩进是非常非常非常之敏感的,如果你的编码过程中出现以下提示

那就是说明你空格和Tab用混了,不要慌不要急,按照以下方法来:全选——Alt+F5,轻松搞定
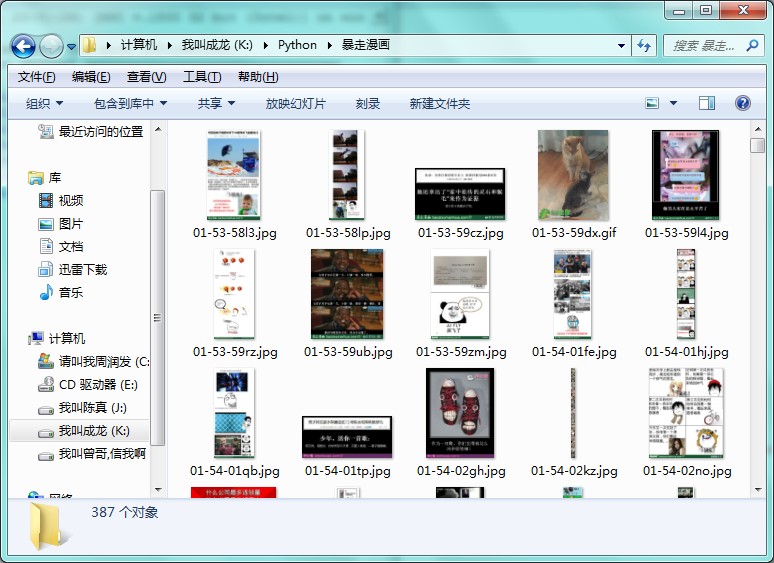
然后附上豆瓣妹子和暴走漫画的抓取结果吧,暴漫的话,留着自己慢慢看,也可以放到自己的网站里,豆瓣妹子嘛,还在犹豫什么宅男们,赶快收藏吧:
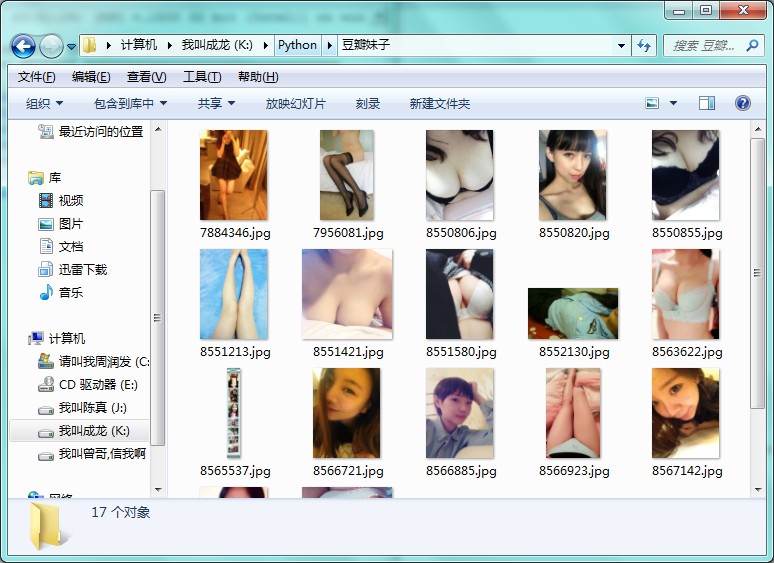
最后的最后,附上豆瓣妹子和暴走漫画的代码:
暴走漫画:
# -*- coding:utf8 -*-
# 2013.12.36 19:41 wnlo-c209
# 抓取dbmei.com的图片。
from bs4 import BeautifulSoup
import os, sys, urllib2,time,random
# 创建文件夹,昨天刚学会
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,u'暴走漫画')
if not os.path.isdir(new_path):
os.mkdir(new_path)
def page_loop(page=1):
url = 'http://baozoumanhua.com/all/hot/page/%s?sv=1389537379' % page
content = urllib2.urlopen(url)
soup = BeautifulSoup(content)
my_girl = soup.find_all('div',class_='img-wrap')
for girl in my_girl:
jokes = girl.find('img')
link = jokes.get('src')
flink = link
print flink
content2 = urllib2.urlopen(flink).read()
#with open(u'暴走漫画'+'/'+time.strftime('%H-%M-%S')+random.choice('qwertyuiopasdfghjklzxcvbnm')+flink[-5:],'wb') as code: #在OSC上现学的
with open(u'暴走漫画'+'/'+flink[-11:],'wb') as code:
code.write(content2)
page = int(page) + 1
print u'开始抓取下一页'
print 'the %s page' % page
page_loop(page)
page_loop()
豆瓣妹子:
# -*- coding:utf8 -*-
# 2013.12.36 19:41 wnlo-c209
# 抓取dbmei.com的图片。
from bs4 import BeautifulSoup
import os, sys, urllib2
# 创建文件夹,昨天刚学会
path = os.getcwd() # 获取此脚本所在目录
new_path = os.path.join(path,u'豆瓣妹子')
if not os.path.isdir(new_path):
os.mkdir(new_path)
def page_loop(page=0):
url = 'http://www.dbmeizi.com/?p=%s' % page
content = urllib2.urlopen(url)
soup = BeautifulSoup(content)
my_girl = soup.find_all('img')
# 加入结束检测,写的不好....
if my_girl ==[]:
print u'已经全部抓取完毕'
sys.exit(0)
print u'开始抓取'
for girl in my_girl:
link = girl.get('src')
flink = 'http://www.dbmeizi.com/' + link
print flink
content2 = urllib2.urlopen(flink).read()
with open(u'豆瓣妹子'+'/'+flink[-11:],'wb') as code:#在OSC上现学的
code.write(content2)
page = int(page) + 1
print u'开始抓取下一页'
print 'the %s page' % page
page_loop(page)
page_loop()















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









