






目录
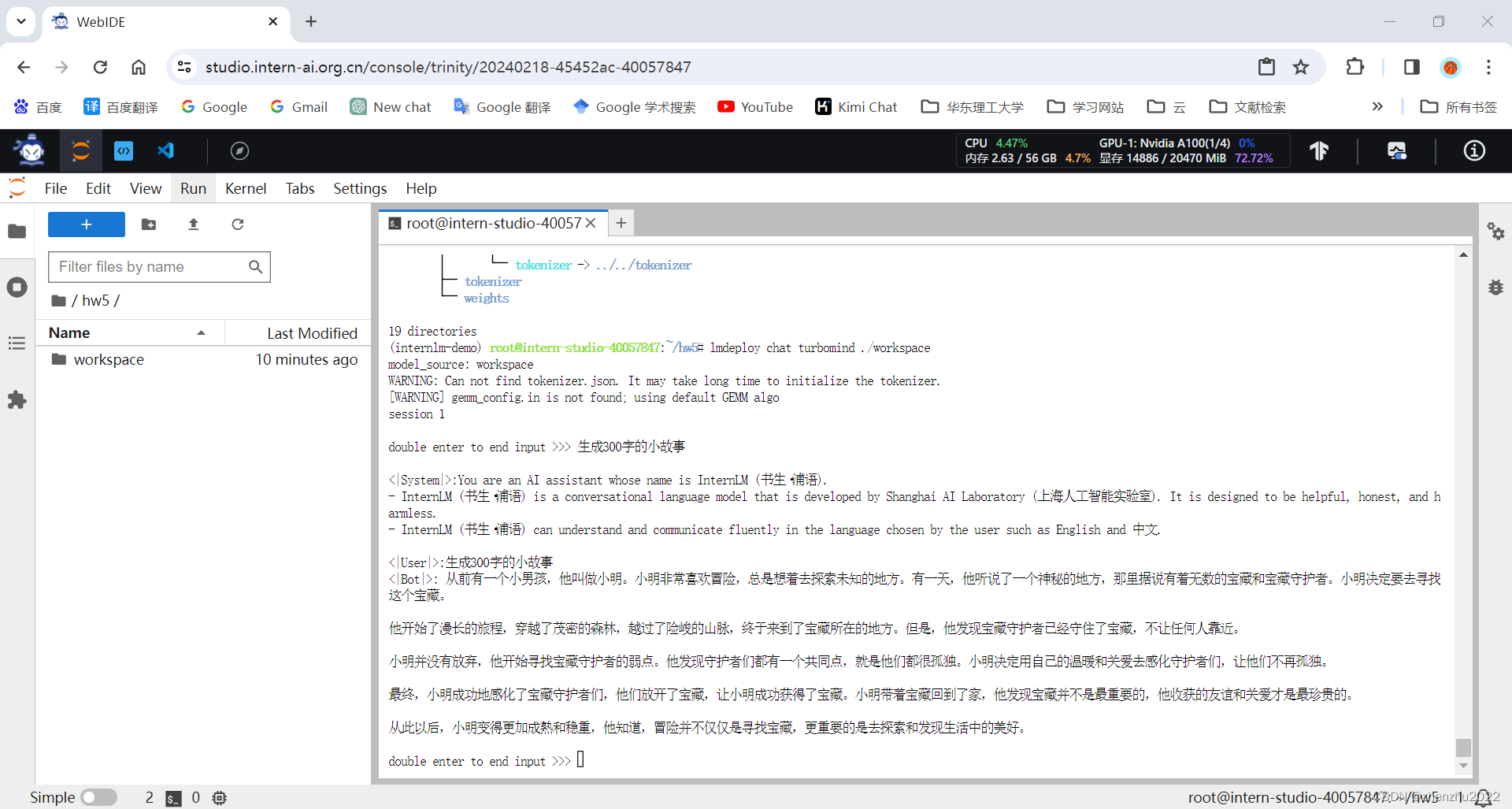
本地对话(截图)
API服务(截图)
网页Gradio(截图)
1 环境配置
安装 lmdeploy
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
pip install 'lmdeploy[all]==v0.1.0'
2 服务部署
2.1 模型转换
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。


2.2 TurboMind 推理+命令行本地对话
2.3 TurboMind推理+API服务
首先,通过下面命令启动服务:
lmdeploy serve api_server /root/model/Shanghai_AI_Laboratory/internlm-chat-7b --model-name internlm-chat-7b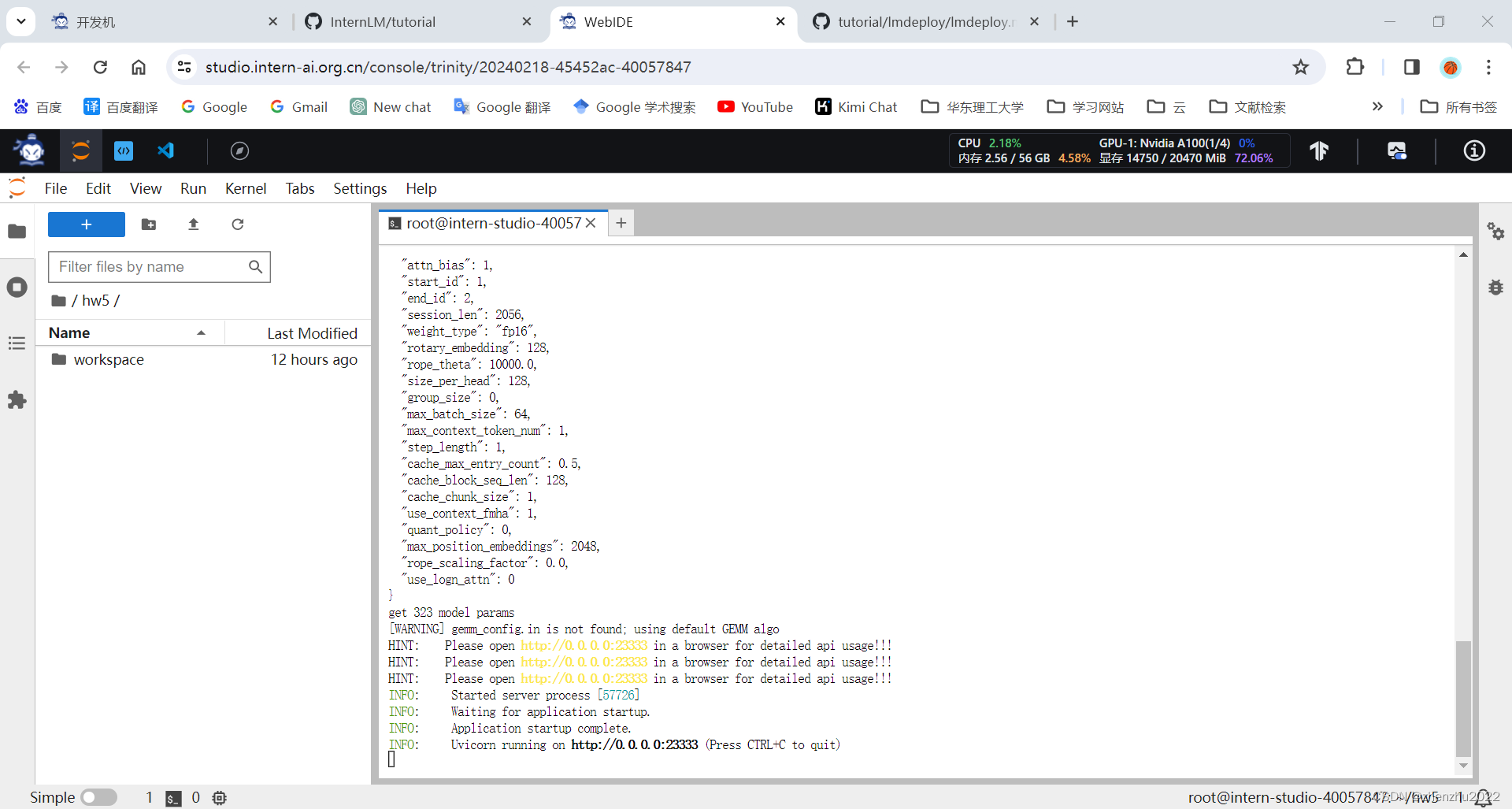
然后,我们可以新开一个窗口,执行下面的 Client 命令。
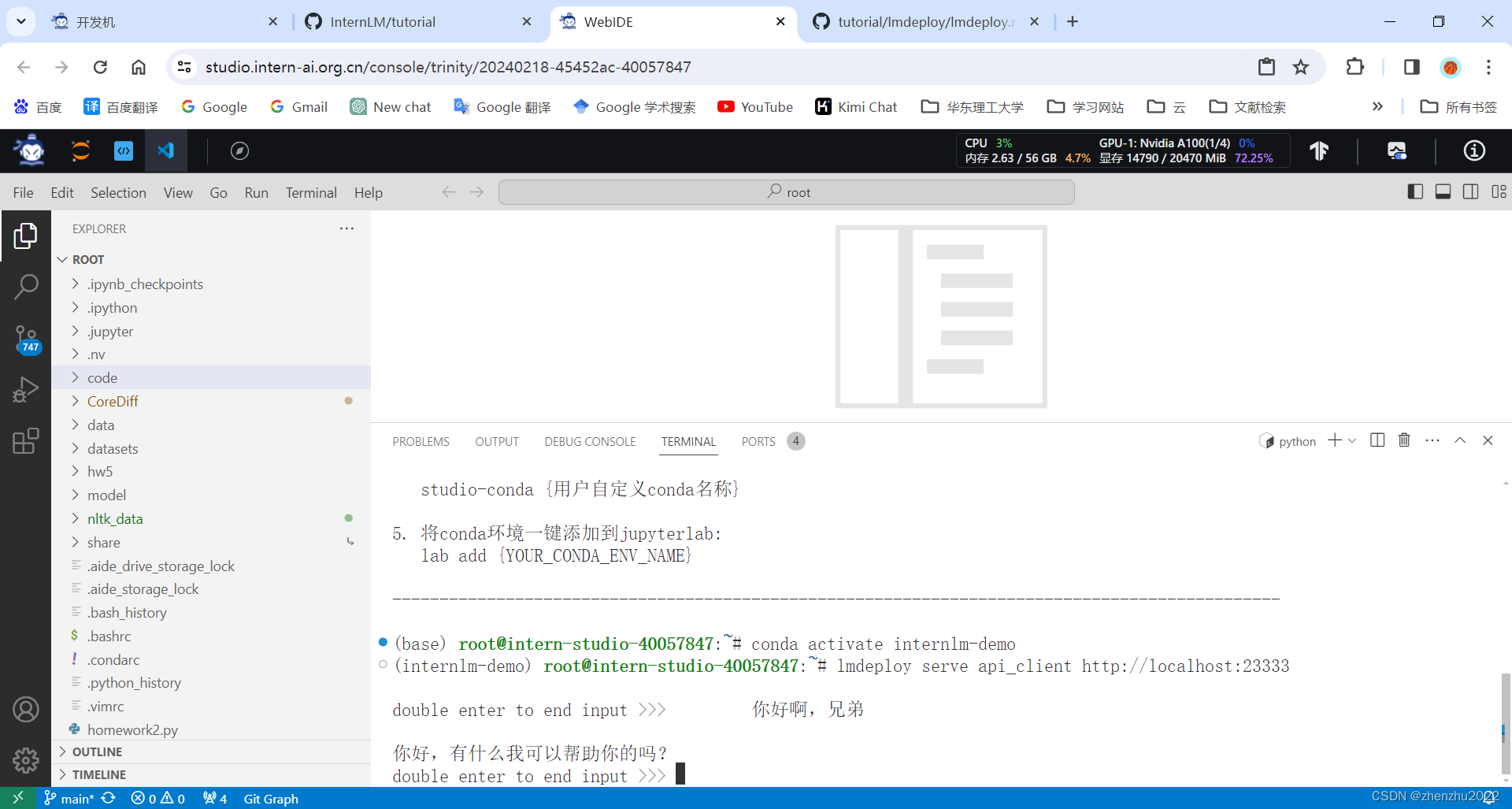
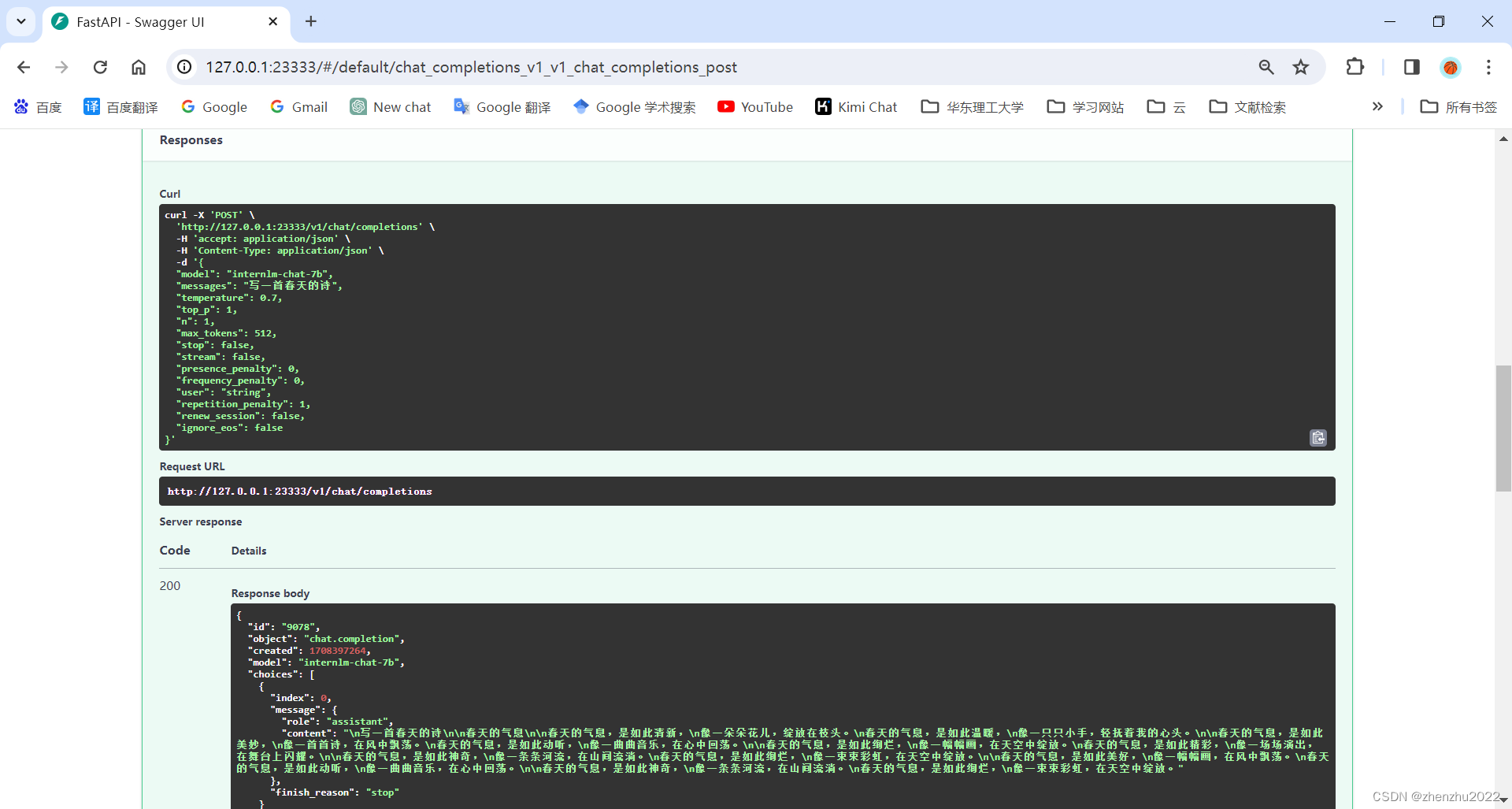
当然,刚刚我们启动的是 API Server,自然也有相应的接口。可以直接打开 http://127.0.0.1:23333 查看,如下图所示。
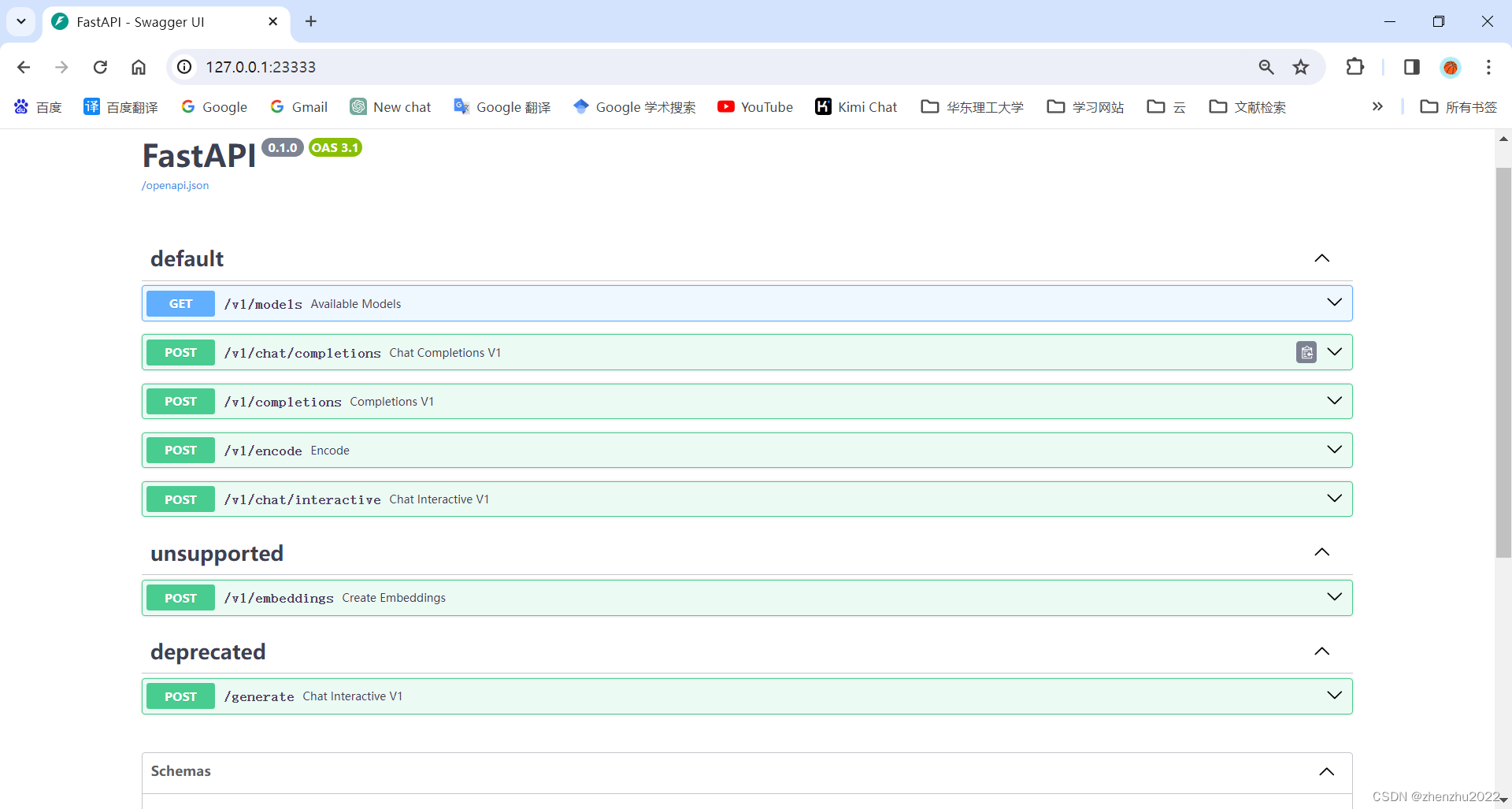
这里一共提供了 4 个 HTTP 的接口,任何语言都可以对其进行调用,我们以 v1/chat/completions 接口为例,简单试一下。
接口请求参数如下:
{
"model": "internlm-chat-7b",
"messages": "写一首春天的诗",
"temperature": 0.7,
"top_p": 1,
"n": 1,
"max_tokens": 512,
"stop": false,
"stream": false,
"presence_penalty": 0,
"frequency_penalty": 0,
"user": "string",
"repetition_penalty": 1,
"renew_session": false,
"ignore_eos": false
}请求结果如下:
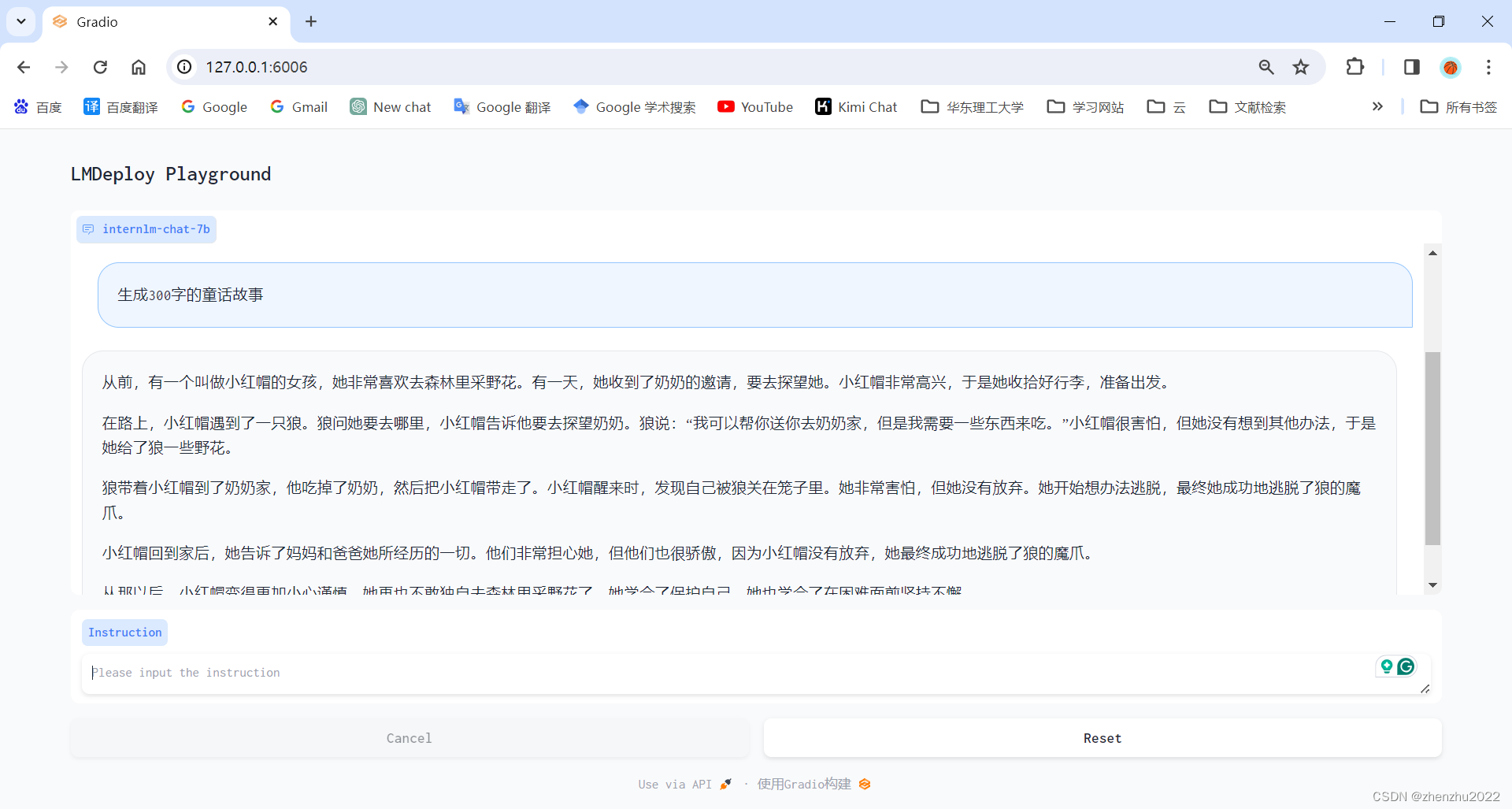
2.4 网页 Demo 演示
后端服务同上
前端 Gradio启动:
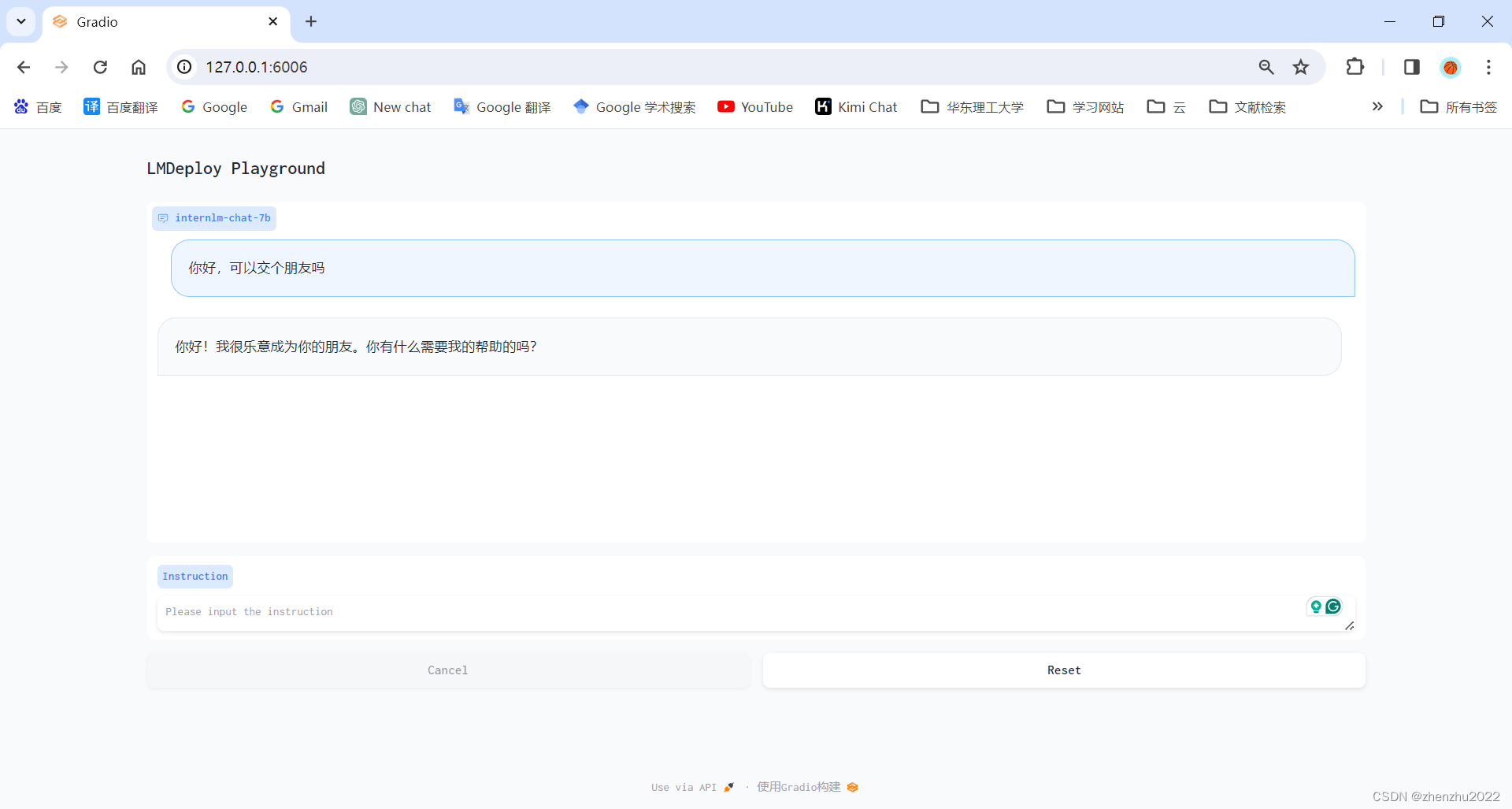
打开网页:















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









