







这里直接讨论数据的建模和评估。
租金预测
目前观察的是Zip 邮政编码和卧室个数 与公寓租金的关系。
数据su_lt_two
Rent Beds Baths Sqft Floor Zip
0 1750 1 1.0 NaN NaN 10035
1 3000 2 2.0 1016 2 10031
2 2300 0 1.0 NaN NaN 10028
3 2500 2 1.0 NaN 6 10035
4 2800 2 1.0 NaN NaN 10012
。。。。
。。。。
import patsy
import statsmodels.api as sm
f = 'Rent ~ Zip + Beds'
y, X = patsy.dmatrices(f, su_lt_two, return_type='dataframe')
results = sm.OLS(y, X).fit()
print(results.summary())显示Prob (F-statistic): 1.21e-10
<<0.05
线性回归有效
下面是区号为10002,两个卧室的公寓租金预测
to_pred_idx = X.iloc[0].index
to_pred_zeros = np.zeros(len(to_pred_idx))
tpdf = pd.DataFrame(to_pred_zeros, index=to_pred_idx, columns=['value'])
tpdf['value'] = 0
tpdf.loc['Intercept'] = 1
tpdf.loc['Beds'] = 2
tpdf.loc['Zip[T.10002]'] = 1
results.predict(tpdf['value'])输出
2651.1763504369078
低价飞机票
通过BeautifulSoup库 获得的数据
通过聚类,希望找到明显偏离聚类中心的最低价飞机票.如果找到的最低价飞机票没有明显偏离聚类中心,则不是要找的飞机票。
price
0 656.000000
1 656.000000
2 656.000000
3 656.000000
4 656.000000
5 656.000000
6 656.000000
7 656.000000
8 656.000000
9 656.000000
10 656.000000
11 656.000000
12 656.000000
13 656.000000
14 656.000000
15 656.000000
16 656.000000
17 656.000000
18 656.000000
19 656.000000
20 656.000000
21 656.000000
22 656.000000
23 656.000000
24 656.000000
25 656.000000
26 656.000000
27 656.000000
28 656.000000
29 656.000000
30 699.820040
31 726.832393
32 699.820040
33 726.832393
34 703.821870
35 699.820040
36 751.843831
37 699.820040
38 741.038890
39 699.820040
40 703.821870
41 703.821870
42 699.820040
43 751.843831
44 699.820040
45 751.843831
46 699.820040
47 728.833308
48 728.833308
49 699.820040
50 829.879518
51 829.879518
52 829.879518
53 806.868995
54 806.868995
55 806.868995
56 829.879518
57 829.879518
58 829.879518
59 983.949977
先看看散点图
fig,ax = plt.subplots(figsize=(10,6))
plt.scatter(np.arange(len(fares['price'])),fares['price']);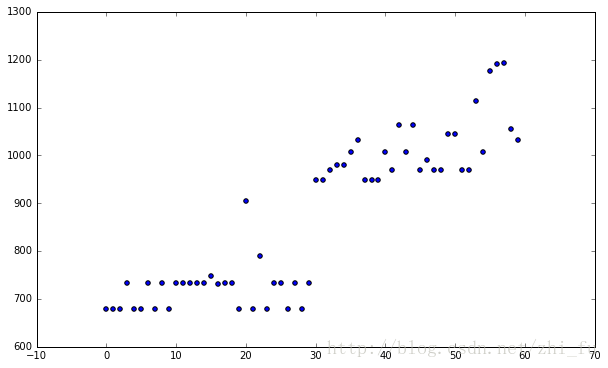
这里介绍的DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。DBSCAN算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类。但是由于它直接对整个数据库进行操作且进行聚类时使用了一个全局性的表征密度的参数,因此也具有两个比较明显的弱点:
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差。
DBSCAN算法基于一个事实:一个聚类可以由其中的任何核心对象唯一确定。等价可以表述为:任一满足核心对象条件的数据对象p,数据库D中所有从p密度可达的数据对象o所组成的集合构成了一个完整的聚类C,且p属于C。
算法的具体聚类过程如下:
扫描整个数据集,找到任意一个核心点,对该核心点进行扩充。扩充的方法是寻找从该核心点出发的所有密度相连的数据点(注意是密度相连)。遍历该核心点的邻域内的所有核心点(因为边界点是无法扩充的),寻找与这些数据点密度相连的点,直到没有可以扩充的数据点为止。最后聚类成的簇的边界节点都是非核心数据点。之后就是重新扫描数据集(不包括之前寻找到的簇中的任何数据点),寻找没有被聚类的核心点,再重复上面的步骤,对该核心点进行扩充直到数据集中没有新的核心点为止。数据集中没有包含在任何簇中的数据点就构成异常点。
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
In [324]:
px = [x for x in fares['price']]
ff = pd.DataFrame(px, columns=['fare']).reset_index()
In [325]:
X = StandardScaler().fit_transform(ff)
db = DBSCAN(eps=.5, min_samples=1).fit(X)
labels = db.labels_
clusters = len(set(labels))
unique_labels = set(labels)
colors = plt.cm.Spectral(np.linspace(0,
1, len(unique_labels)))
plt.subplots(figsize=(12,8))
for k, c in zip(unique_labels, colors):
class_member_mask = (labels == k)
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o',
markerfacecolor=c,
markeredgecolor='k',
markersize=14)
plt.title("Total Clusters: {}".format(clusters),
fontsize=14, y=1.01)显示的结果
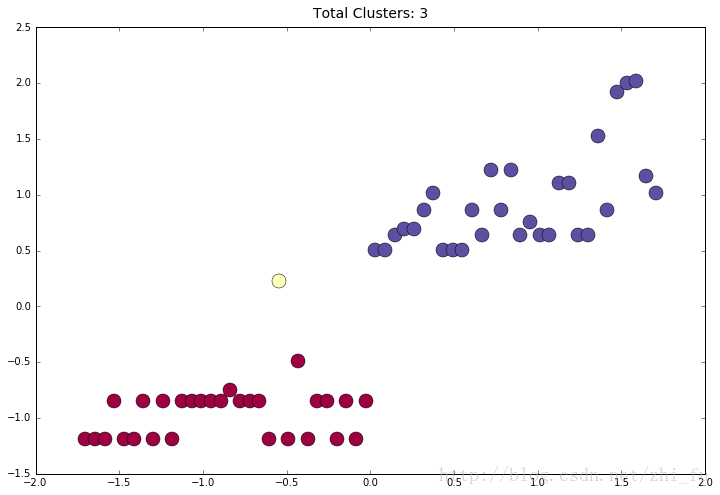
可以看到分为三个聚类
这里增加一个可以改变eps,改变某个样本数据的函数
def test_clusters(data_series, eps_val, swap_index, swap_value):
data_series[swap_index] = swap_value
ff = pd.DataFrame(data_series, columns=['fare']).reset_index()
X = StandardScaler().fit_transform(ff)
db = DBSCAN(eps=eps_val, min_samples=1).fit(X)
labels = db.labels_
clusters = len(set(labels))
unique_labels = set(labels)
colors = plt.cm.Spectral(np.linspace(0,
1, len(unique_labels)))
plt.subplots(figsize=(12,8))
for k, c in zip(unique_labels, colors):
class_member_mask = (labels == k)
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o',
markerfacecolor=c,
markeredgecolor='k',
markersize=14)
plt.title("Total Clusters: {}".format(clusters), fontsize=14, y=1.01)这里将eps设为1.55,index为55的样本价格数据变为700
test_clusters(px, 1.5, 55, 700)
ff = pd.DataFrame(px, columns=['fare']).reset_index()
In [360]:
X = StandardScaler().fit_transform(ff)
db = DBSCAN(eps=1.5, min_samples=1).fit(X)
labels = db.labels_
clusters = len(set(labels))
unique_labels = set(labels)
colors = plt.cm.Spectral(np.linspace(0,
1, len(unique_labels)))
plt.subplots(figsize=(12,8))
for k, c in zip(unique_labels, colors):
class_member_mask = (labels == k)
xy = X[class_member_mask]
plt.plot(xy[:, 0], xy[:, 1], 'o',
markerfacecolor=c,
markeredgecolor='k',
markersize=14)
plt.title("Total Clusters: {}".format(clusters),
fontsize=14, y=1.01)可以看到分为两个聚类
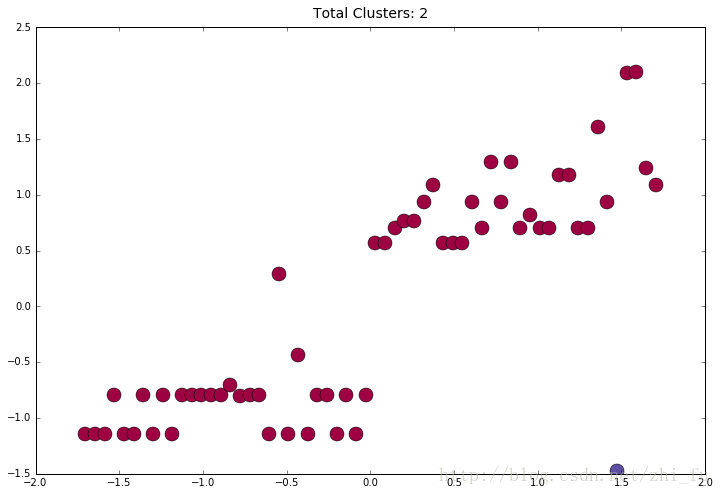
最后下面代码的逻辑是
每隔一小时检查低价飞机票,规则是
(1)聚类数目大于1个
(2)目标机票的聚类最小值等于所有机票的最小值。
(3)目标机票的聚类数目必须小于10%的机票数目
(4)目标机票的聚类最小值小于相邻聚类最小值100美元
(5)目标机票为所在聚类的最小值
将机票数据发送到maker.ifttt.com
触发邮件,短信或其他的通信服务
# cluster min must be equal to lowest price fare
# cluster size must be less than 10th percentile
# cluster must be $100 less the next lowest-priced cluster
import sys
import pandas as pd
import numpy as np
import requests
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
import schedule
import time
def check_flights():
URL="https://www.google.com/flights/explore/#explore;f=JFK,EWR,LGA;t=HND,NRT,TPE,HKG,KIX;s=1;li=8;lx=12;d=2017-06-01"
driver = webdriver.PhantomJS(PJS_PATH)
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36")
driver = webdriver.PhantomJS(desired_capabilities=dcap, executable_path=PJS_PATH)
driver.implicitly_wait(20)
driver.get(URL)
wait = WebDriverWait(driver, 20)
wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, "span.FTWFGDB-v-c")))
s = BeautifulSoup(driver.page_source, "lxml")
best_price_tags = s.findAll('div', 'FTWFGDB-w-e')
# check if scrape worked - alert if it fails and shutdown
if len(best_price_tags) < 4:
print('Failed to Load Page Data')
requests.post('https://maker.ifttt.com/trigger/fare_alert/with/key/MY_SECRET_KEY',\
data={ "value1" : "script", "value2" : "failed", "value3" : "" })
sys.exit(0)
else:
print('Successfully Loaded Page Data')
best_prices = []
for tag in best_price_tags:
best_prices.append(int(tag.text.replace('$','')))
best_price = best_prices[0]
best_height_tags = s.findAll('div', 'FTWFGDB-w-f')
best_heights = []
for t in best_height_tags:
best_heights.append(float(t.attrs['style']\
.split('height:')[1].replace('px;','')))
best_height = best_heights[0]
# price per pixel of height
pph = np.array(best_price)/np.array(best_height)
cities = s.findAll('div', 'FTWFGDB-w-o')
hlist=[]
for bar in cities[0]\
.findAll('div', 'FTWFGDB-w-x'):
hlist.append(float(bar['style']\
.split('height: ')[1].replace('px;','')) * pph)
fares = pd.DataFrame(hlist, columns=['price'])
px = [x for x in fares['price']]
ff = pd.DataFrame(px, columns=['fare']).reset_index()
# begin the clustering
X = StandardScaler().fit_transform(ff)
db = DBSCAN(eps=1.5, min_samples=1).fit(X)
labels = db.labels_
clusters = len(set(labels))
pf = pd.concat([ff,pd.DataFrame(db.labels_,
columns=['cluster'])], axis=1)
rf = pf.groupby('cluster')['fare'].agg(['min','count']).sort_values('min', ascending=True)
# set up our rules
# must have more than one cluster
# cluster min must be equal to lowest price fare
# cluster size must be less than 10th percentile
# cluster must be $100 less the next lowest-priced cluster
if clusters > 1 and ff['fare'].min() == rf.iloc[0]['min']\
and rf.iloc[0]['count'] < rf['count'].quantile(.10)\
and rf.iloc[0]['fare'] + 100 < rf.iloc[1]['fare']:
city = s.find('span','FTWFGDB-v-c').text
fare = s.find('div','FTWFGDB-w-e').text
r = requests.post('https://maker.ifttt.com/trigger/fare_alert/with/key/MY_SECRET_KEY',\
data={ "value1" : city, "value2" : fare, "value3" : "" })
else:
print('no alert triggered')
# set up the scheduler to run our code every 60 min
schedule.every(60).minutes.do(check_flights)
while 1:
schedule.run_pending()
time.sleep(1)















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









