






Spark SQL是一个结构化数据处理的Spark模块。
DataSets和DataFrames
一个DataSet是一个分布式数据集合,类似于RDDs。可以构建于JVM对象,并用函数式transformation(map,flatMap,filter等)。Python没有DataSet API的支持。
一个DataFrame就是一个以命名列进行整合的DataSet。类似于关系型数据库中的表。
DataFrames可以通过多种数据源进行构建:结构化数据文件,Hive中的表,外部数据库,已有的RDD。
出发点:SparkSession
Spark程序的入口是SparkSession,一个SparkSession可以用来创建DataFrame,将DataFrame注册为表,在表上执行SQL,缓存表和读取parquet文件。只用SparkSession.builder就可以创建一个基本的SparkSession对象:
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.appName("PythonSQL")\
.config("spark.some.config.option", "some-value")\
.getOrCreate()
Spark2.0中的SparkSession提供对Hive特征的内部支持:用HiveQL写query语句,访问Hive UDFs,从Hive表中读取数据。为了只用这些操作支持,不需要安装Hive??。
创建DataDrames
有SparkSession对象后,应用就可以根据已有的RDD、Hive表或者Spark数据源创建DataFrame。
小栗子:
#根据一个json文件创建一个DataFrame
df= spark.read.json("examples/src/main/resources/people.json")
#在标准输出中显示DataFrame的内容
df.show()
Untyped Dataset Operations (aka DataFrame Operations)
DataFrames在python中为机构化数据处理提供了一个domain-specific语言。
在Python中,有两种方式来访问DataFrame的列:通过属性(df.age),通过索引(df['age'])。推荐使用后者,不会将列名、同时也是DataFrame类的属性混淆。
# spark is an existing SparkSession
# Create the DataFrame
df = spark.read.json("examples/src/main/resources/people.json")
# Show the content of the DataFrame
df.show()
## age name
## null Michael
## 30 Andy
## 19 Justin
# Print the schema in a tree format
df.printSchema()
## root
## |-- age: long (nullable = true)
## |-- name: string (nullable = true)
# Select only the "name" column
df.select("name").show()
## name
## Michael
## Andy
## Justin
# Select everybody, but increment the age by 1
df.select(df['name'], df['age'] + 1).show()
## name (age + 1)
## Michael null
## Andy 31
## Justin 20
# Select people older than 21
df.filter(df['age'] > 21).show()
## age name
## 30 Andy
# Count people by age
df.groupBy("age").count().show()
## age count
## null 1
## 19 1
## 30 1
执行SQL查询程序
SparkSession的sql函数可以运行SQL查询,结果以DataFrame的数据格式返回。
# spark is an existing SparkSession
df = spark.sql("SELECT * FROM table")
和RDDs互操作
Spark SQL有两种不同的方法将已存在的RDDs转换成DataSets。
1、使用反射来获取包含特定对象类型的RDD内的schema。
当已知schema的时,使用基于反射的方法会使得代码更简洁,效果更好。
2、通过编程接口创建schema,并将其应用到已有的RDD上。
当运行时才知道列和列类型的情况下,允许你创建DataSets。
使用反射获取schema
Spark SQL可以将Row对象格式的RDD转换成
DataFrame
,并推断其类型。Rows是通过向Row类传入一个key/value对列表作为关键字参数来构建。列表的keys定义了表的列名,通过抽样整个数据集来推断类型,类似于推断json文件。
步骤大致以下两步:
1、将原来的RDD转换成Row格式的RDD。
2、通过SparkSession提供的createDataFrame创建一个DataFrame。
之后就可以通过DataFrame的
createOrReplaceTempView("tablename")将其创建或者替换一个临时视图,即表tablename。
就可以用spark.sql方法在表tablename上运行SQL语句了。
# spark is an existing SparkSession.
from pyspark.sql import Row
sc = spark.sparkContext
# 加载一个text文件,并将每一行转换成一个Row对象。
lines = sc.textFile("examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
# parts.collect()
#输出:[[u'Michael', u' 29'], [u'Andy', u' 30'], [u'Justin', u' 19']]
people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
#people.collect()
#输出:[Row(age=29, name=u'Michael'), Row(age=30, name=u'Andy'), Row(age=19, name=u'Justin')]
# Infer the schema, and register the DataFrame as a table.
schemaPeople = spark.createDataFrame(people)#创建一个DataFrame
schemaPeople.createOrReplaceTempView("people")#用这个DataFrame创建或者替换一个临时视图people(可以认为people是一张表)
# SQL can be run over DataFrames that have been registered as a table.
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
# The results of SQL queries are RDDs and support all the normal RDD operations.
teenNames = teenagers.map(lambda p: "Name: " + p.name)
for teenName in teenNames.collect():
print(teenName)
# 官网说SQL查询结果是RDDs,可以用所有RDD的操作,但是我这里查询结果是DataFrame:
>>> type(teenagers)
<class 'pyspark.sql.dataframe.DataFrame'>
但当调用map时说DataFrame没有这个map方法。
>>> teenagers.collect()
[Row(name=u'Justin')]
可以看出,teenagers的元素类型是Row,
for t in teenagers.collect():
... print(t['name'])
输出Justin。
通过编程接口指定schema
当一个dictionary关键字参数不能被提前定义(如,records结构被编码成string,或者解析一个text数据集且根据不同用户划分不同fields),可通过以下三步创建一个
DataFrame
:
1、基于原来的RDD创建一个tuples或lists的RDD。
2、创建与RDD中tuples或lists结构相匹配的StructType,通过该StructType创建表示RDD的schema。
3、通过SparkSession提供的createDataFrame方法将schema应用到RDD创建一个DataFrame。
之后就可以通过DataFrame的
createOrReplaceTempView("tablename")将其创建或者替换一个临时视图,即表tablename。
就可以用spark.sql方法在表tablename上运行SQL语句了。
# Import SparkSession and data types
from pyspark.sql.types import *
# spark is an existing SparkSession.
sc = spark.sparkContext
# Load a text file and convert each line to a tuple.
lines = sc.textFile("examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: (p[0], p[1].strip()))
# The schema is encoded in a string.
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
schema = StructType(fields)
# Apply the schema to the RDD.
schemaPeople = spark.createDataFrame(people, schema)#创建一个DataFrame
# Creates a temporary view using the DataFrame
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table.
results = spark.sql("SELECT name FROM people")
# The results of SQL queries are DataFrame
for name in results.collect():
print name
数据源
Spark SQL通过DataFrame接口支持多种数据源的操作。一个DataFrame可以进行relational转换,也可以注册为临时表后执行SQL查询操作。
常用的加载/保存函数
Spark SQL默认数据源是parquet格式的。
df = spark.read.load("examples/src/main/resources/users.parquet")
df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
手动指定选项
当数据源格式不是parquet时,需手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),但如果数据源是内置格式,只需指定简称(json,parquet,jdbc)。通过指定数据源格式,可以对DataFrames进行类型转换操作。
df = spark.read.load("examples/src/main/resources/people.json", format="json")
df.select("name", "age").write.save("namesAndAges.parquet", format="parquet")
直接在文件上执行SQL
除了使用read API将文件加载成DataFrame并执行查询,也可以直接在文件上用SQL执行查询。
df= spark.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")
存储模式
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。需要注意的是,这些保存模式不使用任何锁定,不是原子操作。此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。
SaveMode详细介绍如下表:

通过使用saveAsTable命令,可以将DataFrames持久化到表中。已有的Hive部署不需要使用这个特性,Spark将会创建一个默认的本地Hive 元数据库。和createOrRepalceTempView不同的是,saveAsTable会实体化DataFrame的内容,并且会在Hive 元数据库中创建一个指针指向该数据。只要维护与同一个元数据库的连接,即使你重启Spark程序,那个持久化的表仍然会存在。通过使用SparkSession的table方法,并以表名为参数,就可以创建一个和DataFrame一样的持久化表。
默认情况下,saveAsTable方法将创建一个“managed table”,意味着数据的位置受元数据库控制。当表被删除后,managed table也会删除存储的数据。
Parquet文件
Parquet是多种数据处理系统支持的列式数据格式。该文件保留了原始数据的模式,Spark SQL提供了parquet文件的读写操作。
读取Parquet文件
例子:
例子:
schemaPeople.write.parquet("people.parquet")#schemaPeople是上边例子创建的DataFrame,parquet方法将DataFrame内容以Parquet的格式进行保存,维持着schema信息。
# Read in the Parquet file created above. Parquet files are self-describing so the schema is preserved.
# The result of loading a parquet file is also a DataFrame.
parquetFile = spark.read.parquet("people.parquet")
#Parquet文件也可以用来创建一个临时的view,然后用于SQL语句中
parquetFile.createOrReplaceTempView("parquetFile");
teenagers = spark.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
for teenName in teenNames.collect():
print(teenName)
分区解析
在类似于Hive的系统中,对表进行分区是对数据进行优化的方式之一。在一个分区的表中,数据通过分区列将数据存储在不同的目录下。Parquet数据源现在能够自动发现并解析分区信息。例如,对人口数据进行分区存储,分区列为gender和country,使用下面的目录结构:
在类似于Hive的系统中,对表进行分区是对数据进行优化的方式之一。在一个分区的表中,数据通过分区列将数据存储在不同的目录下。Parquet数据源现在能够自动发现并解析分区信息。例如,对人口数据进行分区存储,分区列为gender和country,使用下面的目录结构:
path
└── to
└── table
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...
通过将path/to/table传递给SparkSession.read.parquet或SparkSession.read.load,Spark SQL可以根据路径自动解析分区信息。返回的DataFrame的schema如下:
root
|-- name: string (nullable = true)
|-- age: long (nullable = true)
|-- gender: string (nullable = true)
|-- country: string (nullable = true)
需要注意的是,分区列的数据类型是自动解析的。当前支持数值类型和string类型。有时用户不希望自动解析分区列的数据类型,自动解析分区类型的参数为:park.sql.sources.partitionColumnTypeInference.enabled,
默认值为true。如果想关闭该功能,直接将该参数设置为disabled。此时,分区列数据格式将被默认设置为string类型,不再进行类型解析。
从Spark1.6开始,分区解析只有在默认给定的路径下才会发现分区。对于上面的例子,如果用户将path/to/table/gender=male传给SparkSession.read.parquet或SparkSession.read.load,gender不会被当做分区列。如果用户需要指定分区解析开始的基本路径,可以在数据源
options中设置basePath。例如,当path/to/table/gender=male是数据的路径时,用户设置basePath的值为path/to/table/,那么gender就会成为分区列。
Schema合并
像ProtocolBuffer、Avro和Thrift,Parquet也支持schema evolution(schema演变)。用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。现在Parquet数据源能自动检测这种情况,并合并这些文件的schemas。
因为schema合并是一个高消耗的操作,很多情况下是不需要的,所以从1.5开始
默认关闭了这个功能。可以通过以下两种方式开启:
1、当数据源是Parquet文件时,将数据源选项mergeSchema设置为true(如下面的例子)。
2、将全局SQL选项spark.sql.parquet.mergeSchema设置为true。
# spark from the previous example is used in this example.
# Create a simple DataFrame, stored into a partition directory
df1 = spark.createDataFrame(sc.parallelize(range(1, 6))\
.map(lambda i: Row(single=i, double=i * 2)))
df1.write.parquet("data/test_table/key=1")
# Create another DataFrame in a new partition directory,
# adding a new column and dropping an existing column
df2 = spark.createDataFrame(sc.parallelize(range(6, 11))
.map(lambda i: Row(single=i, triple=i * 3)))
df2.write.parquet("data/test_table/key=2")
# Read the partitioned table
df3 = spark.read.option("mergeSchema", "true").parquet("data/test_table")
df3.printSchema()
# The final schema consists of all 3 columns in the Parquet files together
# with the partitioning column appeared in the partition directory paths.
# root
# |-- single: int (nullable = true)
# |-- double: int (nullable = true)
# |-- triple: int (nullable = true)
# |-- key : int (nullable = true)
Hive metastore Parquet表转换
当向Hive metastore读写Parquet表时,为了更好地性能,Spark SQL将使用自带的Parquet SerDe,而不用Hive的SerDe(SerDe:Serialize/Deserialize的简称,目的是用于序列化和反序列化)。这个优化的配置参数为spark.sql.hive.convertMetastoreParquet,默认是开启的。
Hive/Parquet Schema反射(Reconciliation)
从表schema处理的角度来看,Hive和Parquet有两个主要区别:
1、Hive不区分大小写(
is case insensitive),而Parquet区分大小写。
2、Hive允许所有列为空,而Parquet中的空是有重要意义的。
由于这两个区别,当我们将Hive metastore Parquet表转换成Spark SQL Parquet表时,需要将Hive metastore schema 和Parquet schema一致化,一致化规则如下:
1、两个schema中同名的字段必须具有相同的数据类型。一致化后的字段必须为Parquet的字段类型,所以空值是很重要的(
nullability is respected)。
2、一致化后的schema只包含那些在Hive metastore schema中定义的字段。
(1)在一致化后的schema中忽略只出现在Parquet schema的字段。
(2)将只出现在Hive metastore schema的字段设为nullable字段,并加到一致化后的schema中。
元数据刷新
为了更好的性能,Spark SQL 缓存了Parquet 元数据。当Hive metastore Parquet表转换是enabled时,那些转换后的表的元数据也能够被缓存。当表被Hive或其他工具更新后,为了保证元数据的一致性,需要手动刷新元数据。示例:
# spark is an existing HiveContext
spark.refreshTable("my_table")
配置
可以使用SparkSession的setConf方法来配置Parquet,或者使用SQL执行SET key==value命令。
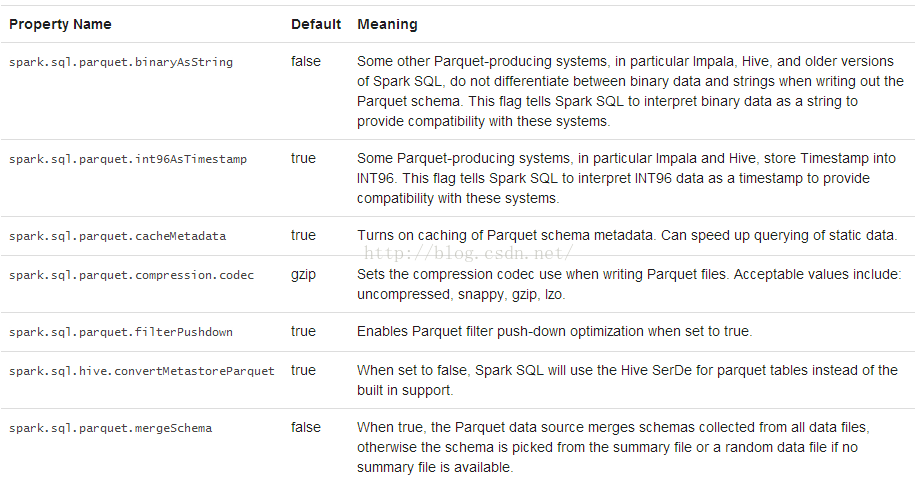
JSON 数据集
Spark SQL可以自动解析JSON数据集的schema,读取JSON数据集为DataFrame格式。读取JSON文件可以用SparkSession.read.json方法。
需要注意的是,这里的JSON文件不是常规的JSON文件。JSON文件每一行必须包含一个独立有效的JSON对象。所以,如果读取的是多行描述一个JSON对象的文件,就会导致出错。

示例如下:
# spark is an existing SparkSession.
# A JSON dataset is pointed to by path.
# The path can be either a single text file or a directory storing text files.
people = spark.read.json("examples/src/main/resources/people.json")
# The inferred schema can be visualized using the printSchema() method.
people.printSchema()
# root
# |-- age: long (nullable = true)
# |-- name: string (nullable = true)
# Creates a temporary view using the DataFrame.
people.createOrReplaceTempView("people")
# SQL statements can be run by using the sql methods provided by `spark`.
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
# Alternatively, a DataFrame can be created for a JSON dataset represented by
# an RDD[String] storing one JSON object per string.
anotherPeopleRDD = sc.parallelize([
'{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}'])
anotherPeople = spark.jsonRDD(anotherPeopleRDD)该行会报错:'SparkSession' object has no attribute 'jsonRDD'
应该是没有这个方法。
Hive表
Spark SQL也支持读写Hive中的数据。然后,Hive有大量的依赖包,这些依赖包在Spark distribution中是没有的。如果Hive的依赖可以在classpath中搜索到,Spark可以自动加载。注意,这些依赖也必须分布到所有的worker节点上,因为为了能够访问Hive中的数据,节点会调用Hive的序列化和反序列化库(SerDes)。
Hive的配置文件是conf/目录下的hive-site.xml,core-site.xml
(for security configuration)和hdfs-site.xml(for HDFS configuration)。
操作Hive时,必须实例化一个Hive支持的SparkSession对象,连接着一个持久化的mHive metastore,支持Hive serdes和Hive的用户自定义函数。即使用户没有现有的Hive部署,也能够使Hive支持。当没有通过hive-site.xml配置时,context会自动在当前目录下创建metastore_db,同时创建一个由spark.sql.warehouse.dir指定的目录,默认为当前目录下的spark-warehouse目录,这是spark应用开始的地方。注意,从Spark2.0.0开始hive-site.xml文件中的hive.metastore.warehouse.dir属性被弃用。用spark.sql.warehouse.dir来指定数据仓库中数据库的位置。也许需要给那个启动spark应用的用户授予写权限。
# spark is an existing SparkSession
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
spark.sql("LOAD DATA LOCAL INPATH 'file:///opt/spark/spark-2.0.0-bin-hadoop2.7/examples/src/main/resources/kv1.txt' INTO TABLE src")
# Queries can be expressed in HiveQL.
results = spark.sql("FROM src SELECT key, value").collect()
和不同版本的Hive metastore交互
Spark SQL提供的Hive支持最重要一点是可以和Hive metastore进行交互,使得Spark SQL能够访问Hive表的元数据。从Spark1.4.0开始,Spark SQL只需下面简单的配置,就支持各版本Hive metastore的访问。注意,涉及到metastore时Spar SQL忽略了Hive的版本。Spark SQL内部将Hive反编译至Hive 1.2.1版本,Spark SQL的内部操作(serdes, UDFs, UDAFs, etc)都调用Hive 1.2.1版本的class。版本配置项见下面表格:

JDBC To Other Databases
Spark SQL通过JDBC访问其他数据库。当使用JDBC访问其他数据库时,应该首选JdbcRDD(scala)。这是因为结果是以DataFrame的格式返回的,且Spark SQL处理DataFrame会很容易,也会很方便的添加其他数据源。因为JDBC数据源不需要用户提供ClassTag,所以很适合使用Java或Python进行操作(注意,这和允许其他应用使用Spark SQL执行查询操作的Spark SQL JDBC server是不同的)。
使用JDBC访问数据源,需要在spark classpath添加JDBC driver配置。例如,为了从Spark Shell连接postgres,需要运行下面的命令:
bin/spark-shell --driver-class-path postgresql-9.4.1207.jar --jars postgresql-9.4.1207.jar
通过调用数据源API,远程数据库的表可以被加载为DataFrame或Spark SQL临时表。下面的选项是支持的:

df = spark.read.format('jdbc').options(url='jdbc:postgresql:dbserver', dbtable='schema.tablename').load()
故障排除
1、在客户端 session和所有的executors上,JDBC driver类必须对启动类加载器(primordial class loader)是visible。这是因为当创建一个connection时,Java的DriverManager类会执行安全验证,安全认证将忽略所有对启动类加载器为非visible的driver。一个方便的解决办法是修改所有worker节点上的compute_classpath.sh脚本,将driver JARs添加至脚本。
2、有些数据库(如H2)将所有名字转换为大写,所以在Spark SQL中也需要将名字全部大写。
性能调优
通过缓存数据至内存或开启某些选项,可以提升一些作业负荷的性能。
缓存数据至内存
Spark SQL可以通过调用spark.cacheTable('tableName')或dataFrame.cache(),使用一种柱状格式将表缓存到内存中。然后Spark SQL在执行查询任务时,只需扫描必须的列,还可以自动调节压缩,从而达到最小化内存使用率和降低GC压力的目的。可以调用spark.uncacheTable("tableName")将表从内存中移除。
可通过两种配置方式开启缓存数据功能:
1、使用SparkSession的setConf方法
2、执行SQL的SET key=value命令

其他配置选项
下面的选项也可以用来调整查询执行的性能。在将来的版本中,这些选项有可能会被弃用,会增强自动调优功能。

分布式SQL引擎(
待看
)
使用Spark SQL的JDBC/ODBC或者CLI,可以将Spark SQL作为一个分布式查询引擎。终端用户或应用不需要编写额外的代码,可以直接使用Spark SQL执行SQL查询。
运行Thrift JDBC/ODBC服务
这里运行的Thrift JDBC/ODBC服务与Hive 1.2.1中的HiveServer2一致。可以在Spark目录下执行如下命令来启动JDBC/ODBC服务:
./sbin/start-thriftserver.sh
这个命令接收所有
bin/spark-submit 命令行参数,添加一个
--hiveconf 参数来指定Hive的属性。详细的参数说明请执行命令
./sbin/start-thriftserver.sh --help 。
服务默认监听端口为localhost:10000。有两种方式修改默认监听端口:
1、修改环境变量:
export HIVE_SERVER2_THRIFT_PORT=<listening-port>
export HIVE_SERVER2_THRIFT_BIND_HOST=<listening-host>
./sbin/start-thriftserver.sh \
--master <master-uri> \
...
2、修改系统属性
./sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=<listening-port> \
--hiveconf hive.server2.thrift.bind.host=<listening-host> \
--master <master-uri>
...
使用
beeline 来测试Thrift JDBC/ODBC服务:
./bin/beeline
连接到Thrift JDBC/ODBC服务
beeline> !connect jdbc:hive2://localhost:10000
在非安全模式下,只需要输入机器上的一个用户名即可,无需密码。在安全模式下,beeline会要求输入用户名和密码。
配置Hive需要替换
conf/ 目录下的
hive-site.xml。
Thrift JDBC服务也支持通过HTTP传输发送thrift RPC messages。开启HTTP模式需要将下面的配参数配置到系统属性或
conf/: 下的
hive-site.xml中
hive.server2.transport.mode - Set this to value: http
hive.server2.thrift.http.port - HTTP port number fo listen on; default is 10001
hive.server2.http.endpoint - HTTP endpoint; default is cliservice
测试http模式,可以使用beeline链接JDBC/ODBC服务:
beeline> !connect jdbc:hive2://<host>:<port>/<database>?
hive.server2.transport.mode=http;
hive.server2.thrift.http.path=<http_endpoint>
运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。需要注意的是,Spark SQL CLI不能与Thrift JDBC服务交互。
在Spark目录下执行如下命令启动Spark SQL CLI:
./bin/spark-sql
配置Hive需要替换
conf/ 下的
hive-site.xml 。执行
./bin/spark-sql --help 可查看详细的参数说明。
与Hive的兼容
Spark SQL与Hive Metastore,SerDes,UDFs兼容。当前Hive SerDes和UDFs是基于Hive1.2.1,Spark SQL兼容Hive Metastore从0.12到1.2.1的所有版本。
在Hive Warehouses中部署Spark SQL
Spark SQL Thrift JDBC服务与Hive相兼容,在已存在的Hive上部署Spark SQL Thrift服务不需要对已存在的Hive Metastore做任何修改,也不需要对数据做任何改动。
Spark SQL支持的Hive特性
Spark SQL支持大多数Hive特性,如:
Hive查询语句,包括:
SELECT
GROUP BY
ORDER BY
CLUSTER BY
SORT BY
所有Hive运算符,包括
比较操作符(=, ⇔, ==, <>, <, >, >=, <=, etc)
算术运算符(+, -, *, /, %, etc)
逻辑运算符(AND, &&, OR, ||, etc)
复杂类型构造器
数学函数(sign,ln,cos,etc)
字符串函数(instr,length,printf,etc)
用户自定义函数(UDF)
用户自定义聚合函数(UDAF)
用户自定义序列化格式器(SerDes)
窗口函数
Joins
JOIN
{LEFT|RIGHT|FULL} OUTER JOIN
LEFT SEMI JOIN
CROSS JOIN
Unions
子查询
SELECT col FROM ( SELECT a + b AS col from t1) t2
Sampling
Explain
表分区,包括动态分区插入
视图
所有的Hive DDL函数,包括:
CREATE TABLE
CREATE TABLE AS SELECT
ALTER TABLE
大部分的Hive数据类型,包括:
TINYINT
SMALLINT
INT
BIGINT
BOOLEAN
FLOAT
DOUBLE
STRING
BINARY
TIMESTAMP
DATE
ARRAY<>
MAP<>
STRUCT<>
Spark SQL不支持的Hive特性
下面是当前不支持的Hive特性,其中大部分特性在实际的Hive使用中很少用到。
Major Hive Features
Tables with buckets:bucket是在一个Hive表分区内进行hash分区。Spark SQL当前不支持。
Esoteric Hive Features
UNION type
Unique join
Column statistics collecting:当期Spark SQL不智齿列信息统计,只支持填充Hive Metastore的sizeInBytes列。
Hive Input/Output Formats
File format for CLI: 这个功能用于在CLI显示返回结果,Spark SQL只支持TextOutputFormat
Hadoop archive
Hive优化
部分Hive优化还没有添加到Spark中。没有添加的Hive优化(比如索引)对Spark SQL这种in-memory计算模型来说不是特别重要。下列Hive优化将在后续Spark SQL版本中慢慢添加。
1、块级别位图索引和虚拟列(用于建立索引)
2、自动检测joins和groupbys的reducer数量:当前Spark SQL中需要使用“
SET spark.sql.shuffle.partitions=[num_tasks];
”控制post-shuffle的并行度,3、不能自动检测。
4、仅元数据查询:对于可以通过仅使用元数据就能完成的查询,当前Spark SQL还是需要启动任务来计算结果。
数据倾斜标记:当前Spark SQL不遵循Hive中的数据倾斜标记。
5、join中STREAMTABLE提示:当前Spark SQL不遵循STREAMTABLE提示。
6、查询结果包含多个小文件时合并小文件:如果查询结果包含多个小文件,Hive能合并小文件为几个大文件,避免HDFS metadata溢出。当前Spark SQL不支持这个功能。
Reference
数据类型
Spark SQL和DataFrames支持的数据格式如下:
•数值类型
•ByteType: 代表1字节有符号整数. 数值范围: -128 到 127.
•ShortType: 代表2字节有符号整数. 数值范围: -32768 到 32767.
•IntegerType: 代表4字节有符号整数. 数值范围: -2147483648 t到 2147483647.
•LongType: 代表8字节有符号整数. 数值范围: -9223372036854775808 到 9223372036854775807.
•FloatType: 代表4字节单精度浮点数。
•DoubleType: 代表8字节双精度浮点数。
•DecimalType: 表示任意精度的有符号十进制数。内部使用java.math.BigDecimal.A实现。
•BigDecimal由一个任意精度的整数非标度值和一个32位的整数组成。
•String类型
•StringType: 表示字符串值。
•Binary类型
•BinaryType: 代表字节序列值。
•Boolean类型
•BooleanType: 代表布尔值。
•Datetime类型
•TimestampType: 代表包含的年、月、日、时、分和秒的时间值
•DateType: 代表包含的年、月、日的日期值
•复杂类型
•ArrayType(elementType, containsNull): 代表包含一系列类型为elementType的元素。如果在一个将ArrayType值的元素可以为空值,containsNull指示是否允许为空。
•MapType(keyType, valueType, valueContainsNull): 代表一系列键值对的集合。key不允许为空,valueContainsNull指示value是否允许为空
•StructType(fields): 代表带有一个StructFields(列)描述结构数据。
•StructField(name, dataType, nullable): 表示StructType中的一个字段。name表示列名、dataType表示数据类型、nullable指示是否允许为空。
Spark SQL所有的数据类型在
org.apache.spark.sql.types 包内。Python中通过下面的命令进行访问:from pyspark.sql.types import *

NaN 语义
当处理float或double类型时,如果类型不符合标准的浮点语义,则使用专门的处理方式NaN。需要注意的是:
1、NaN = NaN 返回 true
2、可以对NaN值进行聚合操作
3、在join操作中,key为NaN时,NaN值与普通的数值处理逻辑相同
4、NaN值大于所有的数值型数据,在升序排序中排在最后
参考文章:官方文档














 1171
1171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









