






第一章:项目概述
概述:处理的是APP的数据,处理一些用户行为(登录、登出),通过app的服务打点记录下来的数据用于商业分析。
第二章:项目架构
-
APP的服务器肯定是多台的,webserver产生很多日志,通过对用户行为进行打点,日志会落到约定的目录下,eg: /data/2019-06-12/…
-
通过flume、filebeat组件收集到hadoop集群,在hdfs上就是一个目录,/apps/hive/warehouse/2019-06-12
-
经过一个spark job 把这些作业生成Hive表、Spark SQL表,后续的数据分析都是基于表来做的,直接通过SQL来完成,HiveSQL、Spark SQL。
-
HiveSQL、SparkSQL:结果肯定是要回到Hive表。
eg、分析用户登录数据,登录一次,把这次登录信息就下来,在Hive、Spark SQL处就会生成登录表,分析登录次数… -
我们做离线处理,结果肯定是展示在报表上的;web页面不能直接对接Hive、SparkSQL表,要把分析结果存储到MySQL,ES。
业内比较通用的离线处理架构(顶多就是组件选型不太一样):
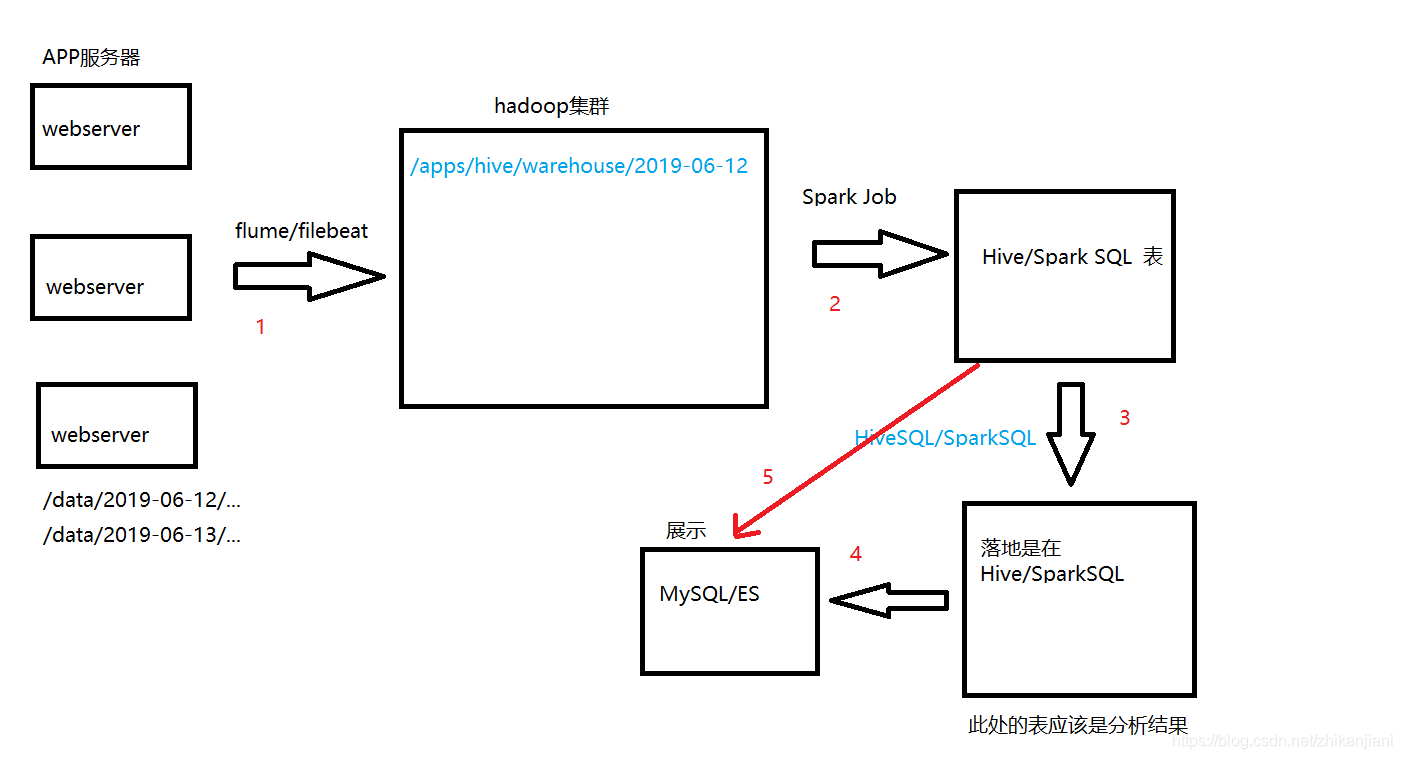
思考:为什么不能把第3、4步直接省略,直接走第5步?为什么还要写HiveSQL、SparkSQL,离线处理结果最后都是通过报表展示,我们从分析结果到MySQL的数据是不变的。涉及架构最优解
2.1 技术选型
1、采集工具直接使用flume;
2、数据采集到hdfs上;
3、在(2)过程上开发一个spark作业,数据落到Spark SQL表上;
4、通过(3)的数据分析变成Spark SQL表;
5、分析结果的数据导出到MySQL。
2.2 架构选型会遇到的问题
数据采集遇到的问题:
第一点:日志格式
- /data/2019-06-12/…
login-1.txt
login-2.txt
logout-1.txt
logout-2.txt
/data/2019-06-13/…
login-1.txt
login-2.txt
logout-1.txt
logout-2.txt
问题一:多层文件夹…(牵扯到递归)
问题二:flume上两个表… 对应到hdfs上就是两个目录
/app/hive/warehouse/login /app/hive/warehouse
注意:日期不一定准,是flume生成的
问题三:收集的选型:
我们保证flume上的每一条记录都是原子的,每条记录要么不写,要么直接写完,不能追加(由埋点的开发来考虑的)。这个选型对应的是第1步,taildir -> memory/file -> avro ,avro -> memory/file -> hdfs
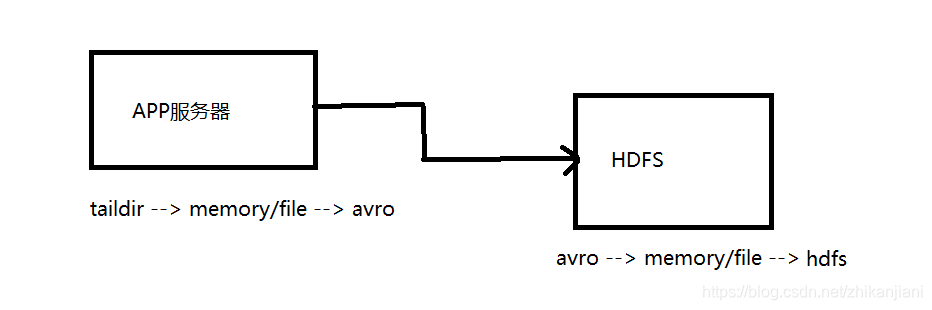
问题四:sink到hdfs遇到的问题:
- 数据延迟(落地时间和数据时间不一致)
sink到hdfs上的路径如下所示:
/app/hive/warehouse/login/2019-06-12/13:00
1.txt
2.txt
/app/hive/warehouse/login/2019-06-12/14:00
1.txt
2.txt
每个批次的最后数据很有可能到下个批次的第一、二个文件。
flume监控需要我们自己去做。
Spark Job ETL遇到的问题:
a.分区字段(String操作)
b.字段的解析(ip解析 --> 转换为国家、省、市)
c.转列式
d.数据质量…
比如后面所有操作都是基于user_name来的,但是这条数据都没有打进来。
问题1、落地时间和数据时间不一致,如何保证每一个批次的数据都能被正确的ETL?
14:00还在读取13:00批次的数据,14:00读取13:57分~13:59分的数据。
-
write.partitionBy(d,h).savemode.append.save(hdfs路径) 不考虑修数据(作业全是正常的)
-
修数据需要重跑的时候又该怎么办,overwrite也会出现很多问题。
问题2、Spark ETL这个地方一定会存在小文件的问题,注意:生产过程中很多情况都不会产生shuffle,此时不做计算,计算是在3这个过程中做的。
- 小文件的处理:
问题3、1中存储到的是hdfs路径怎么刷新元数据?
a.alter table add partition… (d=…,h=…) //如何高效率的拿到分区的值
b.msck repair table… (生产上不能用,刷全部的耗时久)
经过2后的SparkSQL原始表可能是ORC、PARQUET格式的。
SparkSQL数据分析遇到的问题
1、小文件
2、幂等性
3、造成数据倾斜 ***
全看SQL写的好不好
4、资源(抖晚8 9点的抖音访问量)
SparkSQL表、Hive表导入到MySQL/ES
1、导出效率 datax sparksql(datasource)
2、幂等性
set … = insert into partiiton(…) select …
五、统计指标(业务)
登录、登出、注册、购买
login、logout、register、order
1、登陆情况,在线时长
2、留存,注册之后的活跃情况
3、付费情况,前一天注册的,当天或者今天付费的
第三章:采集部分
Spooling Directory Source:
Taildir Source:1、断点续传 (文件收集肯定选这个)
Exec Source:
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
| property name | description |
|---|---|
| filegroups | Space-separated list of file groups. Each file group indicates a set of files to be tailed. |
描述:以空格分隔的文件组列表。每个文件组表示要跟踪的一组文件。
其实就是 g1 g2(以空格分割)
Example for agent named a1:
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups.f2=/var/log/test2/.*log* //只要是日志中带log的都要进行收集
修改taildirsource:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/2019-06-12/01/.txt //这个场景的目录应该是:/data/*/*/.*txt
多层文件夹递归,正则表达式只能用于filename,/data///.*txt这个是不生效的。
3.1 查看flume源码
首先要把flume源码导入到IDEA编辑器中:
https://blog.csdn.net/zhikanjiani/article/details/100678368















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









