







数据集CPED介绍
昨天思考自己的小论文idea(md,到现在还没有idea,555,研一玩了一整年,后悔死,555),然后看到了一个中文对话数据集,觉得很不错,记录一下
数据集名称:
CPED 数据集大小:包含了来自40个TV shows的392位说话者的12K多段对话。这里K应该是千的意思吧,不是很确定。
数据集属性:
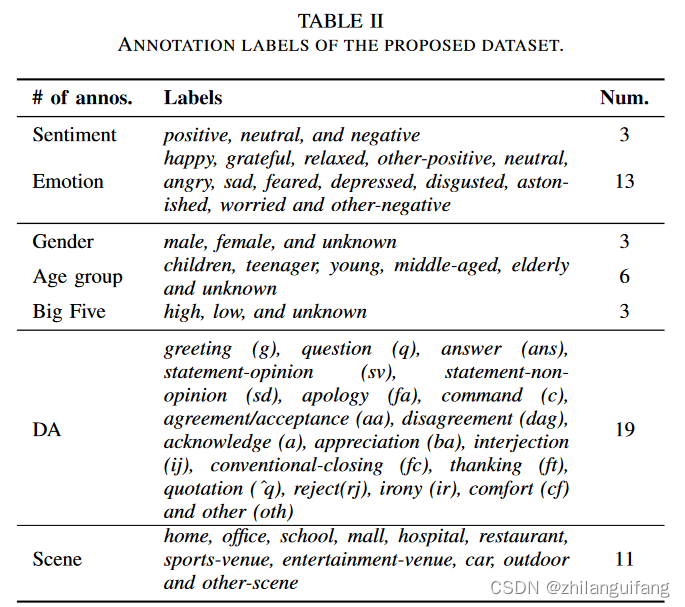
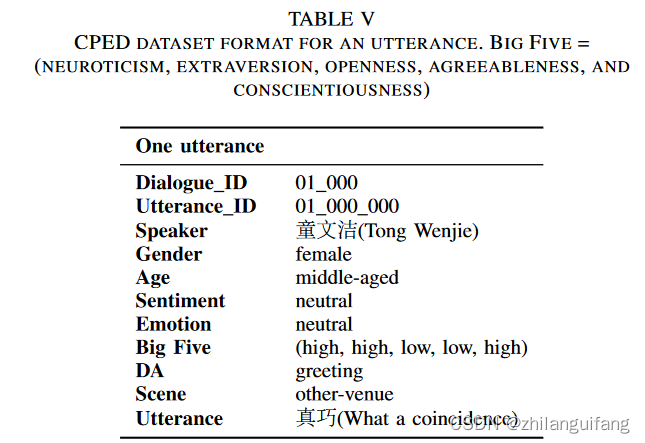
TV_ID,Dialogue_ID,Utterance_ID,Speaker,Gender,Age,Neuroticism,Extraversion,Openness,Agreeableness,Conscientiousness,Scene,FacePosition_LU,FacePosition_RD,Sentiment,Emotion,DA,Utterance。还挺多的(大体上分为三类:话语,情绪等特征、话语属于哪个对话等特征)
数据属性解释:
- TV_ID:当前话语属于哪个电视节目
- Dialogue_ID:当前话语属于那段对话
- Utterance_ID:当前话语的标识
- Speaker:当前话语的说话者名字
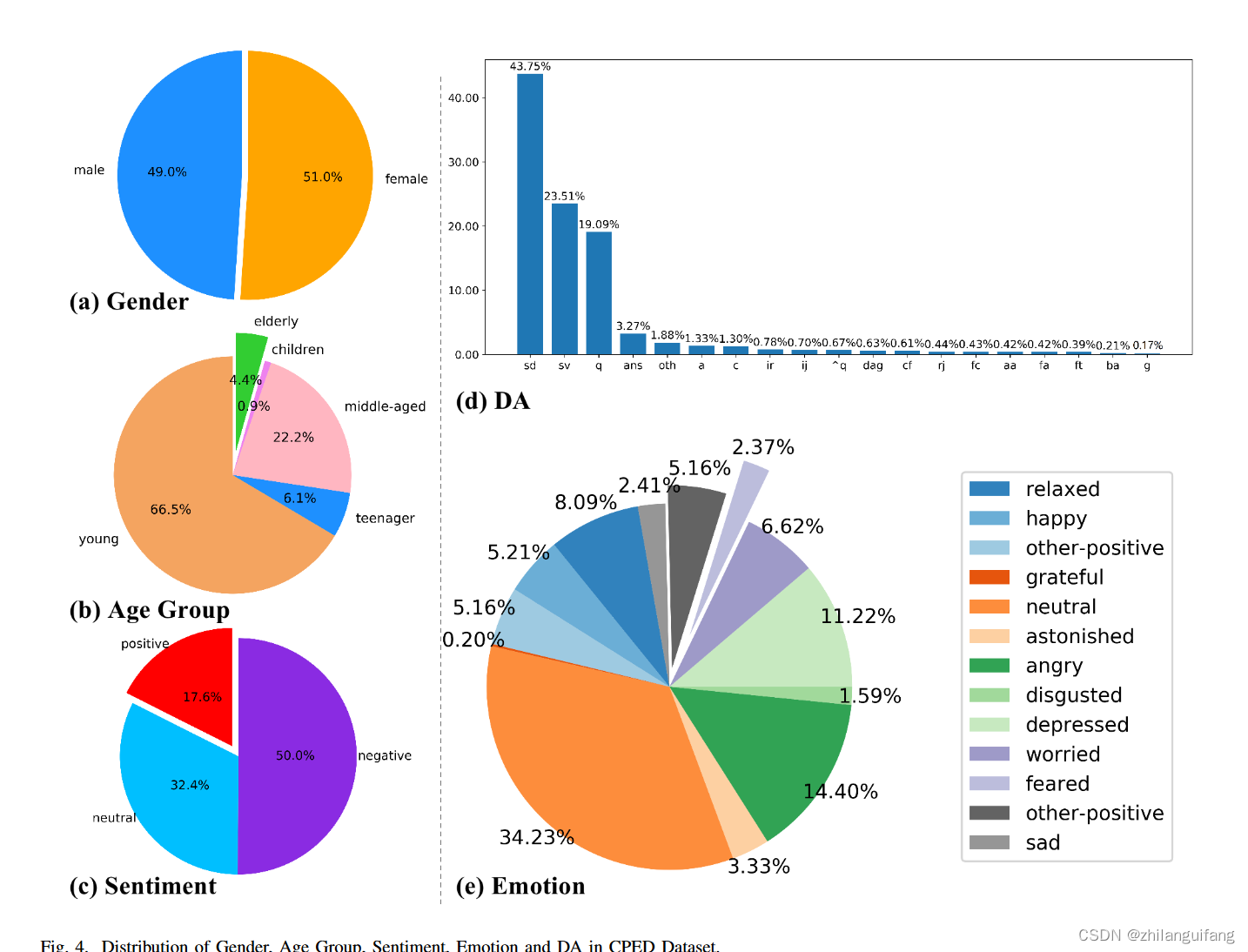
- Gender:说话者性别(共3种:)
- Age:说话者年龄类别(共6种:)
- Neuroticism:神经质
- Extraversion:外倾性
- Openness:经验开放性
- Agreeableness:宜人性
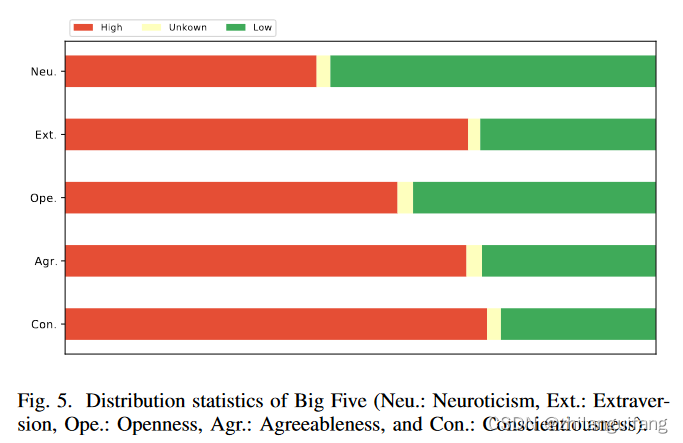
- Conscientiousness:认真性 这5个属于大5(5种人格特征,我也不太了解)
- Scene:当前对话属于什么情景(共11种:)
- FacePosition_LU:脸部位置(??这个标签我也没有看明白,)
- FacePosition_RD:脸部位置(??这个标签我也没有看明白,)
- Sentiment:当前话语属于哪个情感类别(共3类:中性、消极、积
- Emotion:当前话语属于哪个情绪类别(共13类:)
- DA:当前话语属于哪个对话行为类别(共19种:)
- Utterance:当前话语文本(中文)
数据集的部分特征(图片展示)
原始数据

数据集标注的特征
big five特征分布统计
一个话语示例
该数据集的部分特征分布
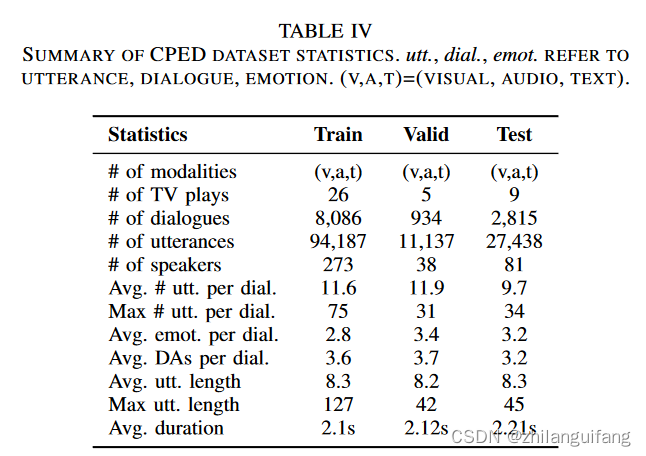
该数据集的统计特征
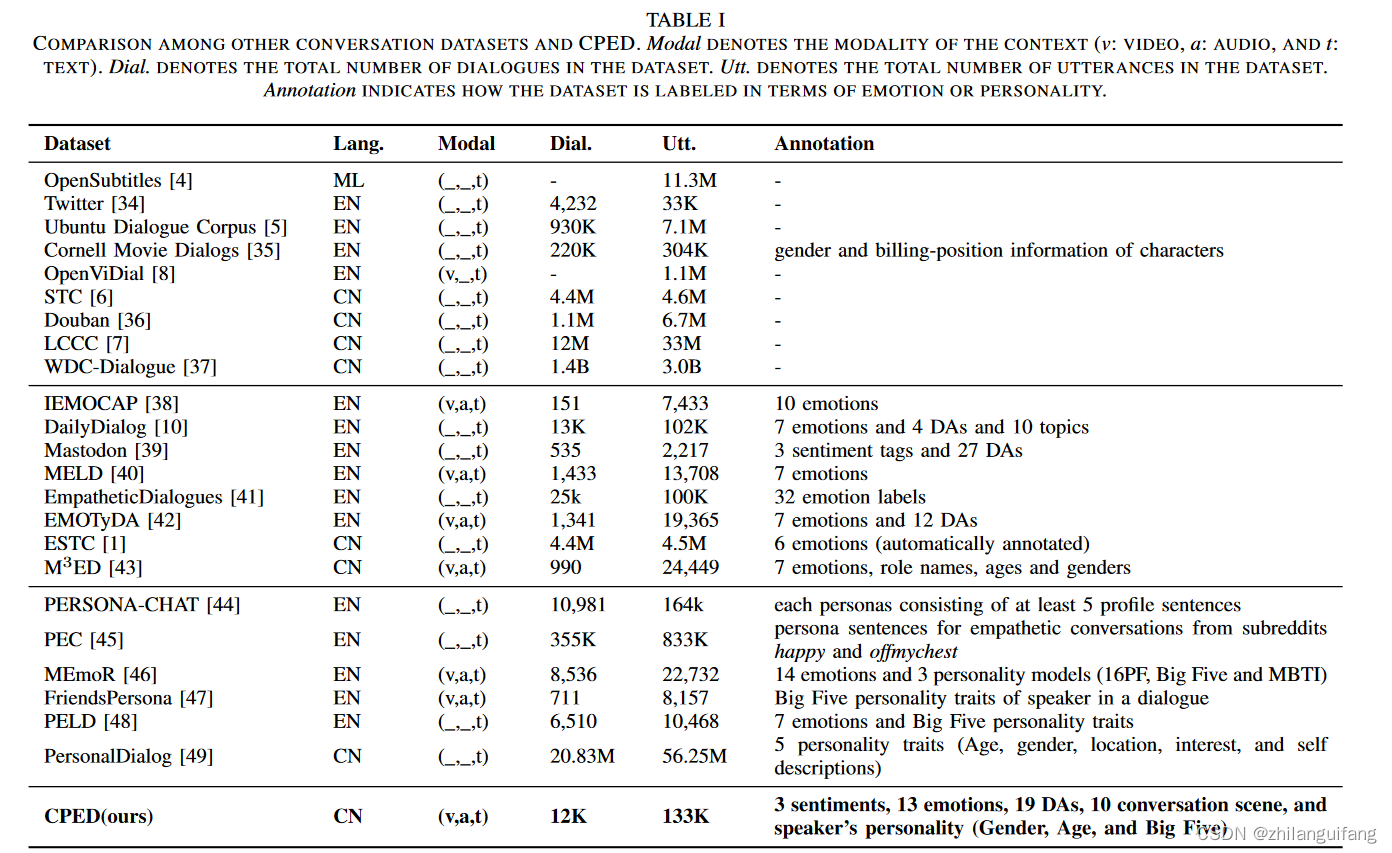
其他常用对话数据集的特征
论文链接
论文:https://paperswithcode.com/paper/cped-a-large-scale-chinese-personalized-and-1
GitHub:https://github.com/scutcyr/CPED/tree/main/data/CPED
其他说明
作者还利用该数据集进行了对话情绪识别、人格识别、对话生成等实验,我这里就不介绍了,感兴趣自己看论文;
作者说可以通过话语ID获得音频和视频数据,不过我目前还不知道如何获取这两个模态的数据,感兴趣的话自己看论文(如果有大佬知道如何获取,可以指点我一下吗,谢谢了~~)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









