






很开心和大家分享一下我们最近的工作,和清华小学弟姚欢晋在多模态大语言模型(Multimodal Large Language Model, 以下简称 MLLM)方面进行了一些探索。
论文内容和标题《Dense Connector for MLLMs》一样简单,我们提出一个简单有效、即插即用的视觉语言连接器 Dense Connector(DC),简单地利用多层视觉离线特征来增强现有的多模态大语言模型,且不引入额外的计算量。思路简单,所以实现也很简单,核心代码仅三行!

论文链接:
https://arxiv.org/pdf/2405.13800
项目链接:
https://github.com/HJYao00/DenseConnector
DC 能直接应用于不同分辨率的多模态大语言模型(比如 LLaVA-1.5,Mini-Gemini)带来明显提升,与不同视觉骨架模型、不同预训练数据、不同参数的大语言模型(从 2B→70B)都能兼容。我们在 11 个图像评测集都取得不错效果,无需训练直接拓展到视频上也能在 8 个视频指标上也取得领先的表现。
Dense Connector 很荣幸被大 V(推特)AK 转发,被 HuggingFace 选为 Daily Papers,欢迎大家的关注与批评指正。我们也希望 DC 能成为未来多模态大语言模型的基础模块。
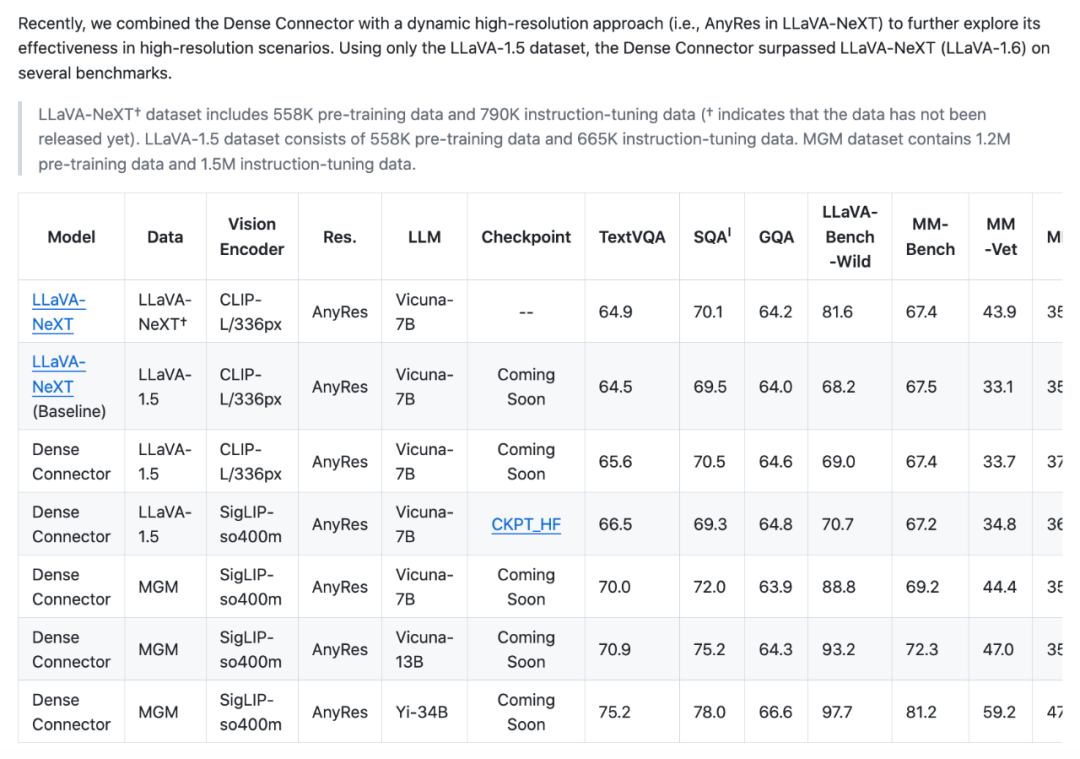
**Dense Connector 已适配 LLaVA-NeXT!**通过将 Dense Connector 与动态高分辨率技术(即 LLaVA-NeXT 中的 AnyRes 技术)结合,我们进一步提升了模型性能,并展示了 Dense Connector 在更广泛应用领域的表现。仅使用 LLaVA-1.5 数据集,Dense Connector 在多个基准测试中超越了 LLaVA-NeXT(指令微调训练数据未开源)。欢迎查看 ModelZoo 中的性能表现!

背景
自从 ChatGPT 引领了一波大语言模型(LLM)的热潮,引入视觉等信息的多模态大语言模型(MLLMs)的研究也如火如荼。目前几个常用的提升 MLLMs 的方式是:使用更多更高质量的图像-文本数据集(预训练数据+指令微调数据)、增加大语言模型的参数量、提高图像分辨率、增加视觉骨干网络的数量等方面来增强 MLLM 的理解能力。
然而,对现有视觉编码器的更有效利用的探索相对较少,目前的主流方法往往使用冻结的视觉编码器来获取高层视觉特征(比如 CLIP ViT-L 的第 24 层特征)以此作为最终的视觉表示。然而,这种方式真的充分利用了视觉特征吗?除了最高层特征,冻结的视觉编码器的各层特征其实都蕴含不尽相同的视觉信息,为何不充分使用这些“免费的午餐”呢?
进一步思考,为了与现有 MLLMs 完全兼容性,有没有一种既简单、又高效、又不引入额外参数的方式来充分利用离线视觉特征呢?于是,我们提出了 Dense Connector,一个即插即用的视觉语言连接器来增强现有的 MLLMs。
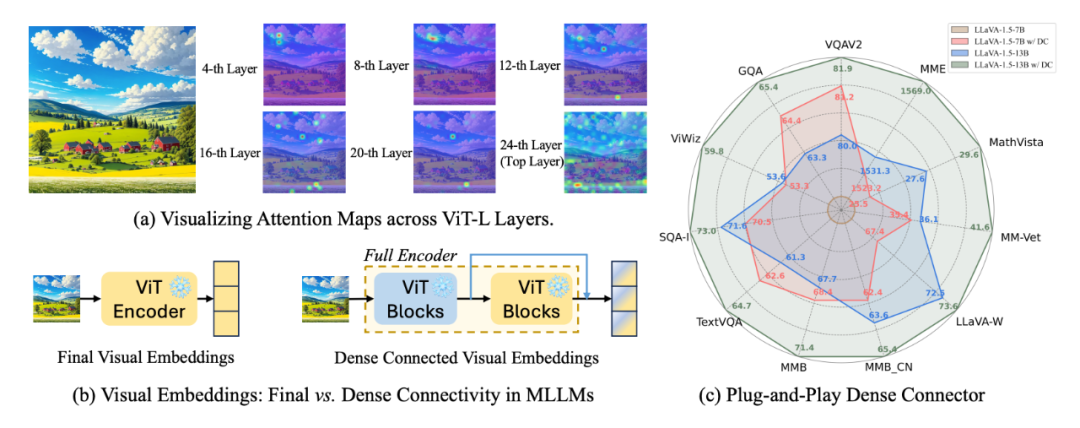
▲ 探索多层视觉特征,增强现有 MLLM 的能力

探索Dense Connector:三种实例
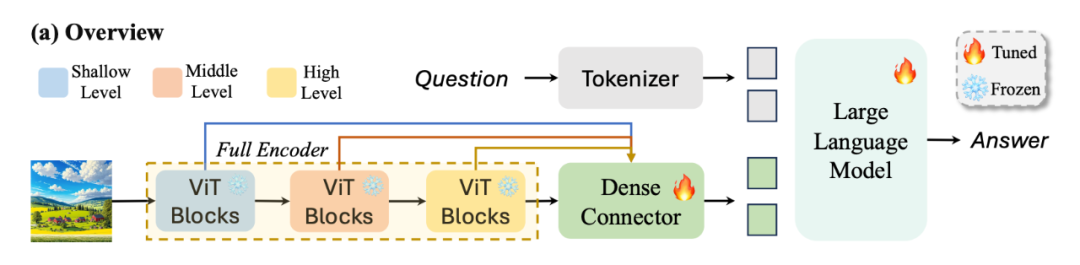
▲ 概览Dense Connector
现有的 MLLMs(如 LLaVA 和 InstructBLIP)通常将高层特征输入给 MLLM。然而,在计算机视觉的历史长河中,利用多层视觉特征以增强视觉表征是一种经典的策略(如 DenseNet, FPN 等)。
如上图,我们针对 MLLM 进行了相关的探索,以下是 Dense Connector 的三种实例探索,它融合多层视觉特征以获得更强的视觉表征。Dense Connector 分为两个部分:第一部分融合多层视觉特征,第二部分进行特征转换,将视觉特征转换到大语言模型的特征空间上。接下来,我们分别介绍实现这三种实例:
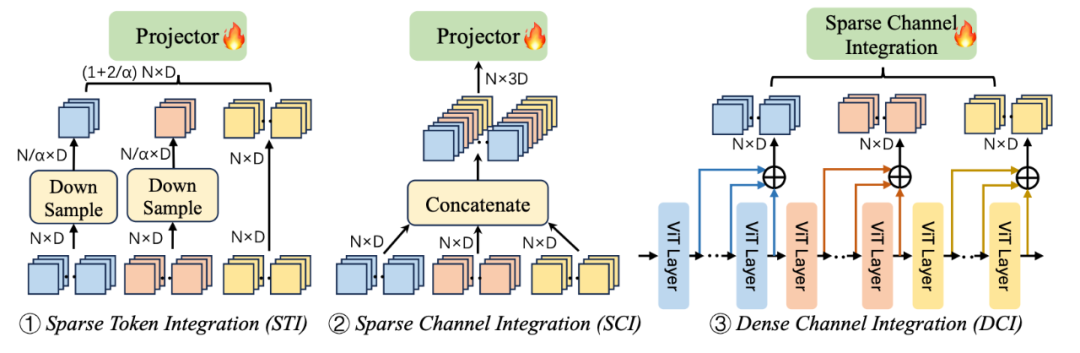
▲ Dense Connector的三种实例。N为token数,D为channel维度。
Sparse Token Integration (STI)
现有方法通过 projector 将高层的 ViT patch token 转换为大语言模型的输入 token。沿着这种思路,我们将浅层视觉特征作为额外的 token 输入给 LLM。然而,随着 token 数量的增加,大语言模型的前向计算时间也会增加,并且相同编码器的不同层特征存在一定的冗余信息。
为了解决这些问题,我们使用 average pooling 对低层视觉 token 进行下采样,同时保持高层特征不变。然后,我们将这些特征沿着 token 维度进行拼接,并输入到一个共享权重的 projector 中进行特征空间转换。
Sparse Channel Integration (SCI)
STI 方法简单有效,但是由于 token 数的增多,影响了其推理效率。受到 DenseNet 的启发,我们提出了本文的一个核心方法:将 multi-level 的视觉特征沿着特征维度拼接,然后将拼接后的视觉特征通过 projector。projector 在这里不仅作为视觉特征的融合器,也作为视觉特征到文本特征的映射器,巧妙的实现了两种功能。
这部分核心代码仅三行!
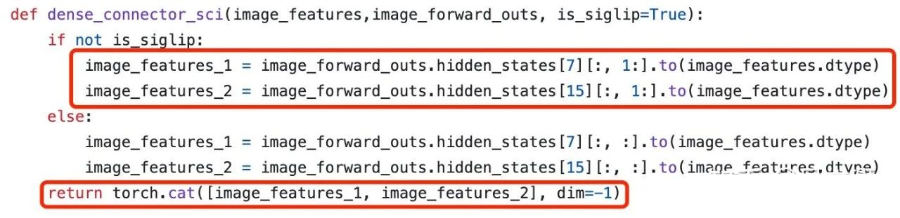
Dense Channel Integration (DCI)
上述的 STI 和 SCI 方法都取得了不错的效果。然而,由于上述方法需要沿着 token 或者 channel 维度进行拼接,我们仅选择了少数几层特征进行拼接。选择过多的特征会导致维度过高,导致效果不好。
为了融合更多层的视觉特征,我们在 SCI 的基础上提出了一种更有效的方法融合更多的视觉特征层。我们的做法如下:首先将 ViT 层(例如,24 层的 ViT-L/14)分为 3 组,分别是第 1~8 层,第 9~16 层,第 17~24 层三组视觉特征。我们对这三组特征分别进行特征相加后,将 24 层视觉特征缩减为 3 个视觉特征表征。然后我们将这三个融合后的视觉特征和 ViT 原本的高层特征沿着 channel 维度进行拼接,并通过 projector 进行特征融合和特征映射。

实验结果
下图是 Dense Connector 的三种实例化结果,以 Baseline LLaVA-1.5 为参考,三种实例都有明显提升,也能看到其中 Dense Channel Integration (DCI) 实现了最好的结果。
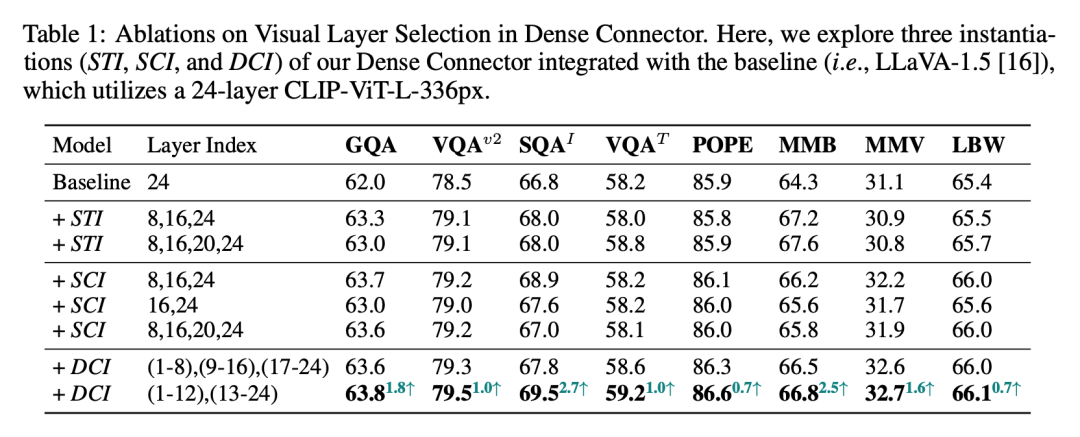
▲ Dense Connector的三种实例化结果
此外,我们测试了利用不同视觉编码器的多层视觉特征的效果,我们将 CLIP-L 替换成更先进的 SigLIP-SO,验证了 Dense Connector 能适用于其他的视觉 backbone。为了验证 Dense Connector 能轻松集成到现有的 MLLM 框架中,除了 LLaVA-1.5,我们也将 Dense Connector 应用于最近的高分辨率双流架构的 Mini-Gemini,并实现了进一步的性能提升。同样,基于更大的预训练数据,效果提升也明显。
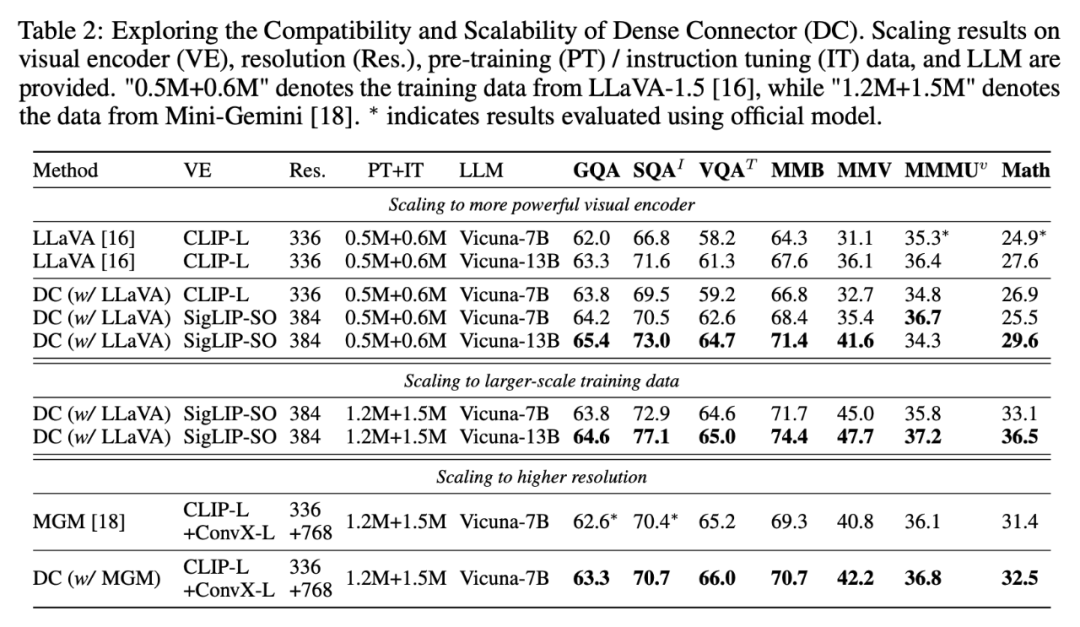
▲ 兼容性分析
我们基于 LLaVA-1.5 的训练数据,提供了基于不同参数量(2B-70B)大语言模型的结果,能看到其 scale up 能力。不过由于计算资源的限制(大部分模型都使用 8 卡 A100 训练),为了训练 34B 模型和 70B 模型,我们只能冻结 LLM 仅训练 LoRA 微调。后面如果有更丰富的 80G A100 多机资源,很显然 full tuning LLM 以及使用比 LLaVA-1.5 更多的训练数据(比如 Mini-Gemini)会有更好的结果。
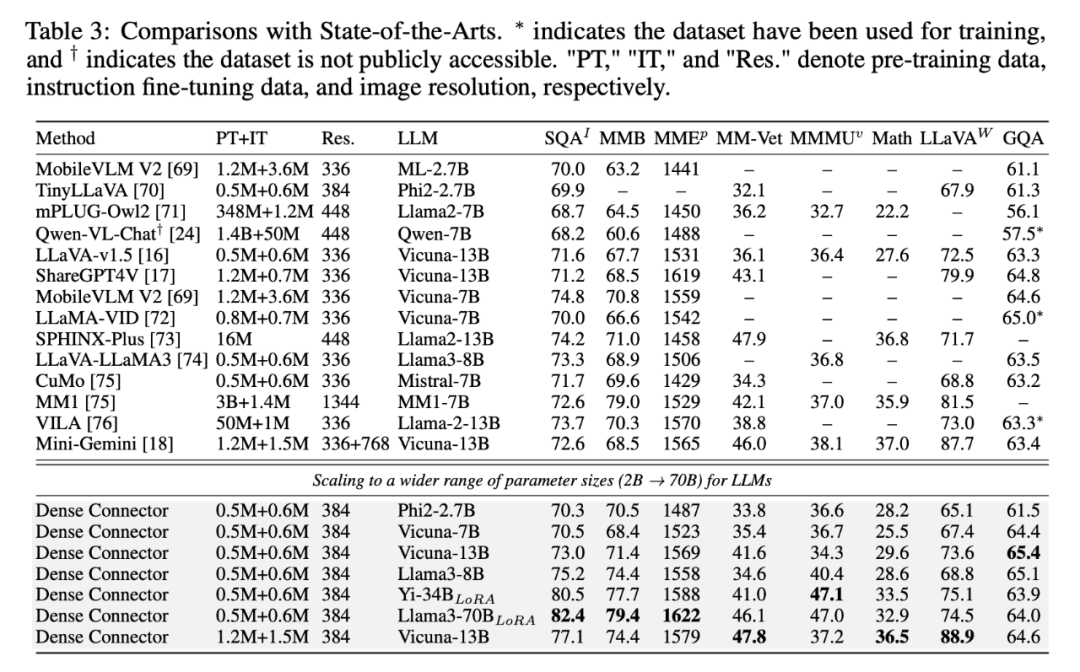
▲ 使用不同LLM的结果
除了图像模态,我们也直接利用 FreeVA [1] 将我们的模型用于视频对话(没有经过任何的视频数据训练),也取得了不错的结果。
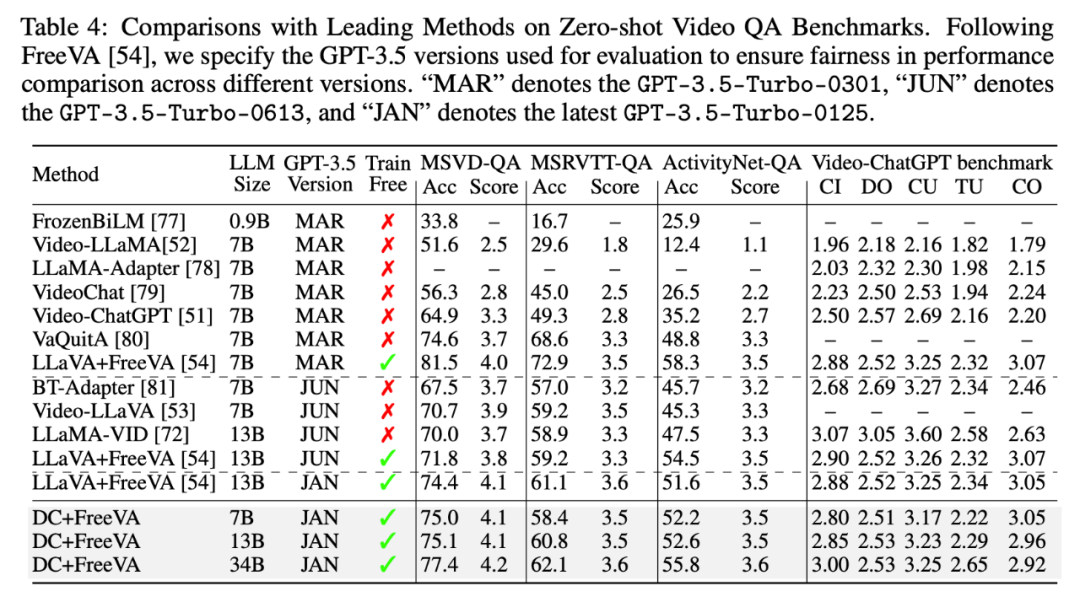
▲ 视频场景结果
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









