







.01
概述
在人工智能领域,尤其是自然语言处理(NLP)中,Transformer、BERT和SBERT已经成为技术发展的基石。然而,很多人对它们的工作原理、优缺点以及实际应用还不够了解。本篇文章将深入解析这些技术,从基础概念到最新进展,帮助你掌握背后的关键逻辑。
.02
Transformers:NLP领域的“革命性武器”
1) 什么是Transformer?
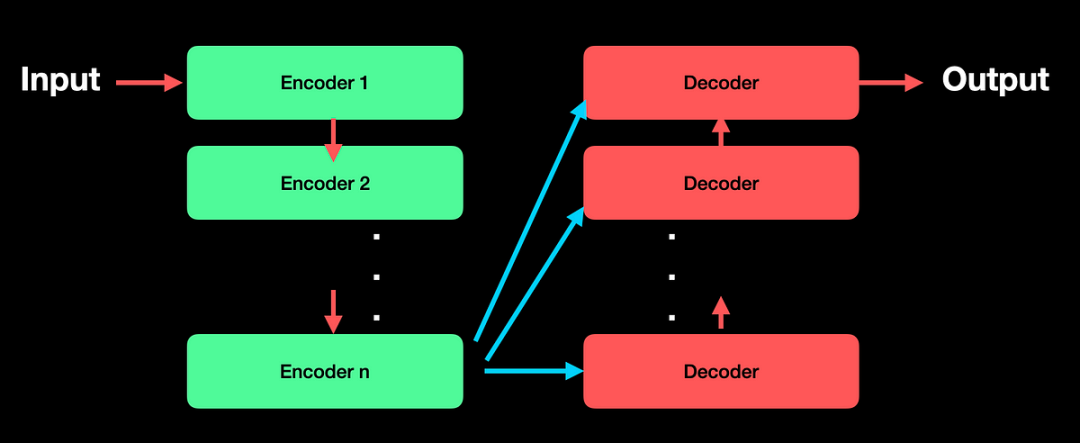
Transformer模型诞生于2017年,最初是为了解决机器翻译问题。如今,它已经成为几乎所有大规模语言模型(LLM)的核心。
Transformer模型的架构由两个主要模块组成:编码器(Encoder)和解码器(Decoder)。
- 编码器:将输入转换为矩阵表示,用于捕捉上下文信息。
- 解码器:基于编码器输出生成最终的结果,如翻译句子或预测下一步文本。
经典的Transformer模型每个模块由6层堆叠而成,而这些层都依赖一个核心机制:多头自注意力机制(Multi-Headed Self-Attention)。
2) Transformer的优势:捕捉全局上下文
与早期的RNN或LSTM不同,Transformer模型可以捕捉整个输入序列的全局上下文,而不仅仅是单个词的局部信息。这种特性让它在处理长文本时表现出色。
3) Transformer的局限性
尽管Transformer在许多任务中表现出色,但在某些场景下仍存在不足。例如:
- 仅考虑历史信息:Transformer的注意力层通常只关注“过去的上下文”,对于某些需要前后双向理解的任务(如问答)表现会受限。
举个例子:
“John带着Milo参加了聚会。Milo在聚会上玩得很开心。他是一只白色的猫。”
如果我们问:“Milo是否和John在聚会上喝酒了?”
仅依赖前两句,模型可能回答“玩得开心可能意味着喝酒了”;但如果能结合第三句——“Milo是一只猫”,答案显然是“不可能”。
这时,我们需要一个能够同时理解前后文的模型,这便是BERT。
.03
BERT:双向编码的“语义大师”
1) 什么是BERT?
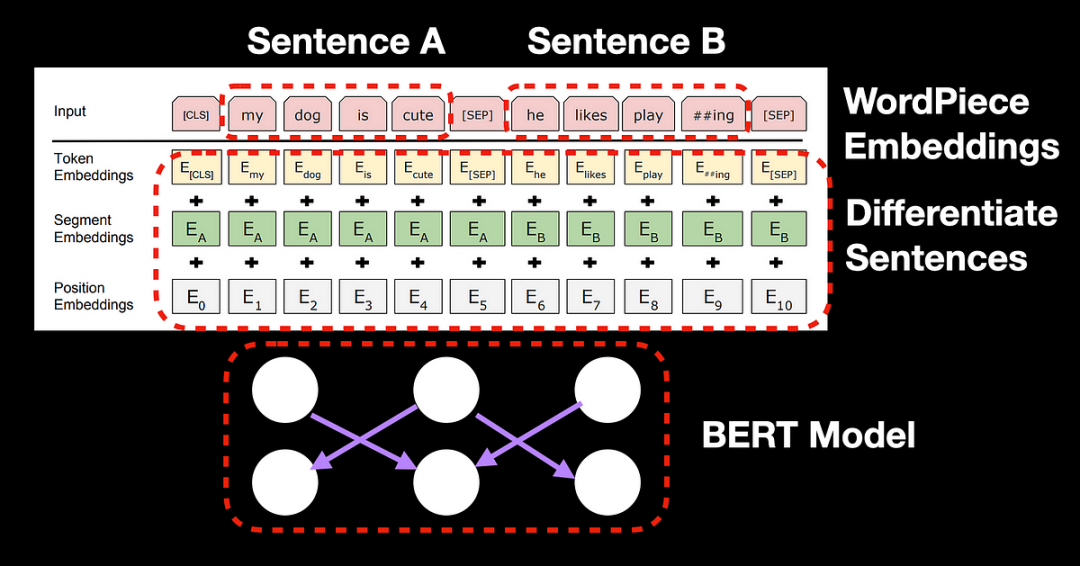
BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer编码器开发的模型,但与Transformer不同的是,BERT采用双向自注意力机制,能够同时理解句子前后文的信息。
BERT的设计使其特别适合处理像问答、文本摘要等任务。它通过引入特殊的标记(如[CLS]和[SEP]),让模型能够更好地区分问题和答案,进而进行上下文推理。
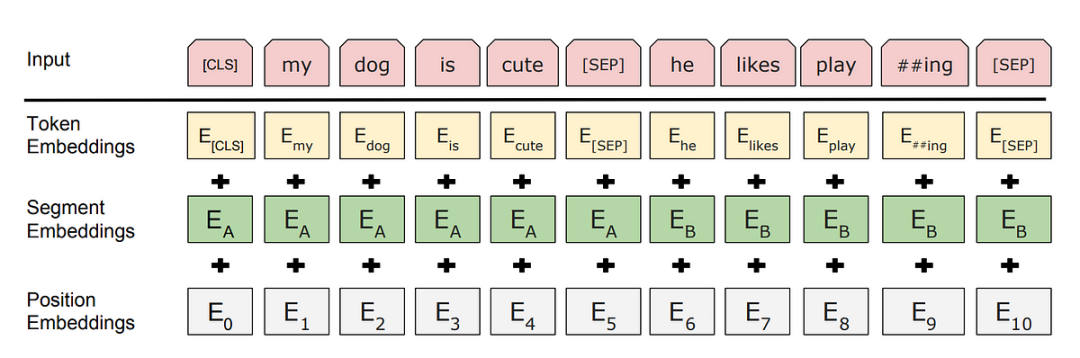
2) BERT的训练方法
BERT的强大来源于两种预训练任务:
- 掩码语言模型(Masked Language Model, MLM):随机遮盖输入文本的15%的词汇,模型需要预测被遮盖的词是什么。
- 下一句预测(Next Sentence Prediction, NSP):判断两句输入文本是否是相邻句。

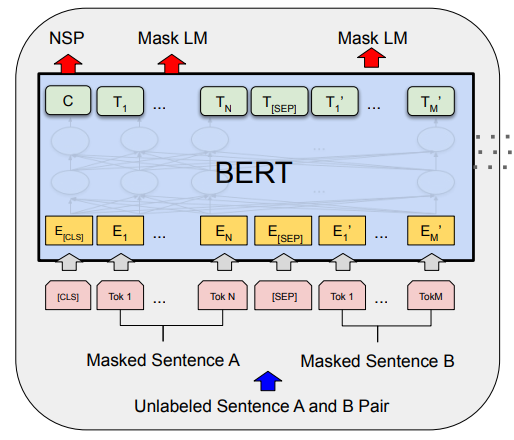
3) BERT的局限性
尽管BERT在语义理解上表现强大,但它在处理大规模相似性搜索任务时表现欠佳。例如,当需要在10,000条句子中找到与某个句子最相似的一条时,BERT需要对每个句子对进行两两比较,计算量巨大。这种二次复杂度使其难以在大规模语义搜索中应用。
于是,SBERT应运而生。
.04
SBERT:专注于语义相似度的革新模型
1) 什么是SBERT?
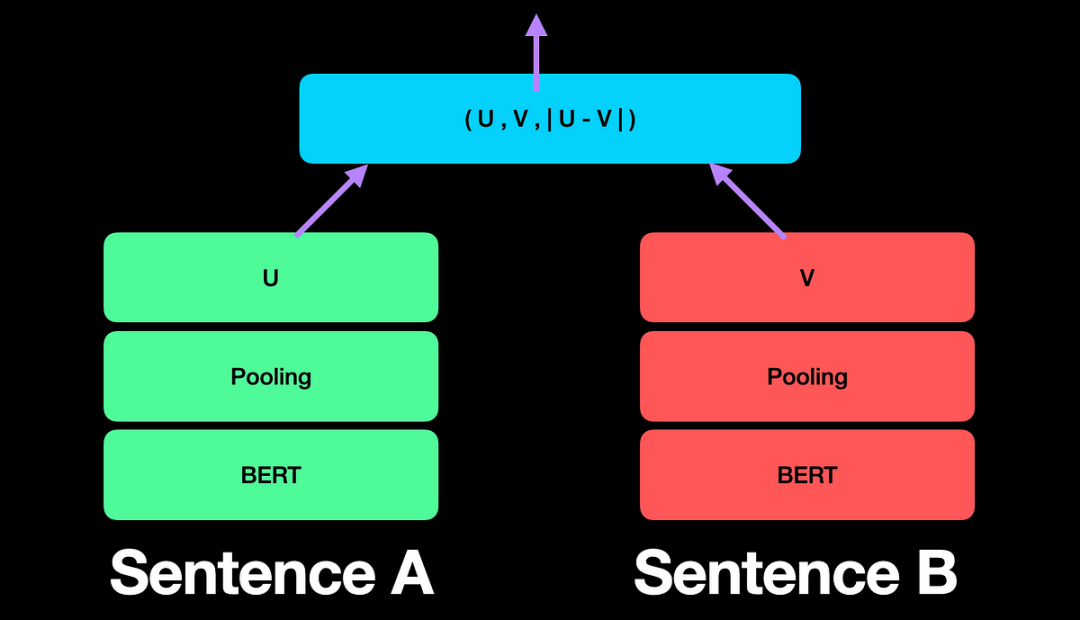
SBERT(Sentence-BERT)通过在BERT的基础上引入Siamese网络(孪生网络),解决了大规模相似性搜索的计算瓶颈。
与BERT不同,SBERT不需要每次都对句子对进行比较,而是先对每个句子生成独立的固定长度向量(如1×768维度),然后再通过简单的数学运算(如余弦相似度)来比较句子间的相似性。
2) SBERT的架构与特点
SBERT的架构引入了池化层(Pooling Layer),将BERT的输出从高维度(如512×768)简化为低维度(如1×768),大幅降低了计算复杂度。此外,它还支持三种训练方式:
- 自然语言推理(NLI):基于分类任务(如“推断”“中性”“矛盾”)进行训练。
- 句子相似度(Sentence Similarity):直接优化余弦相似度,适合语义相似任务。
- 三元组损失(Triplet Loss):通过比较锚点句、正样本句和负样本句的距离,优化语义表示。
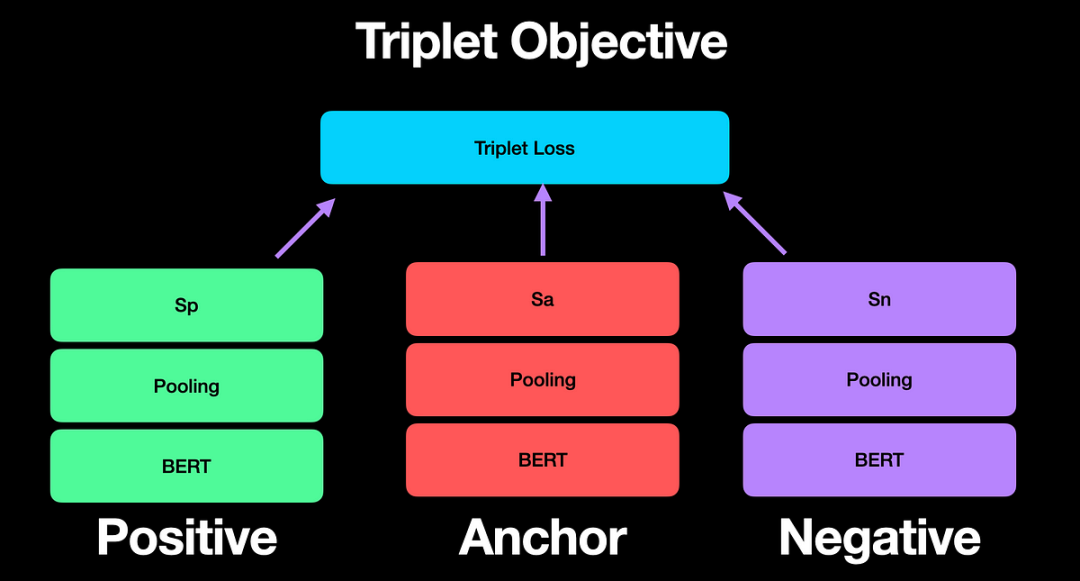
3) SBERT的实际应用
SBERT已经成为构建检索增强生成(RAG)流水线的核心工具。通过开源库sentence-transformers,你可以轻松生成句子嵌入,并进行语义搜索。以下是简单的代码示例:
# 安装库
!pip install sentence-transformers
# 加载模型
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('bert-base-nli-mean-tokens')
# 生成句子嵌入
sentences = [
"今天的天气真好。",
"外面阳光明媚!",
"他开车去了体育场。",
]
embeddings = model.encode(sentences)
# 计算相似度
similarities = model.similarity(embeddings, embeddings)
print(similarities)
.05
总结:从Transformer到SBERT,探索NLP的未来
从Transformer的全局上下文捕捉,到BERT的双向语义理解,再到SBERT的大规模相似性搜索优化,这些模型展现了NLP领域的不断突破。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1516
1516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









