







最新 YOLO 系列模型怎样在机器人端发光发热?本文从模型部署的原理出发,逐步介绍了模型在机器人端的推理环境和部署流程,并分享了 YOLOv8 模型的转换实例。欢迎阅读交流~
01
YOLOv8:一种精确&灵活的视觉 AI 方案
2023年1月,ultralytics公司推出了最新的 YOLO 系列模型——YOLOv8。对于这次发布的产品,ultralytics官方称其为"一种前沿的(cutting-edge)、最先进的(state-of-the-art )视觉模型”。除了性能提升,YOLOv8还能胜任多种视觉技术(分类、检测、分割、姿态估计和跟踪)。官方描述YOLOv8支持全方位的视觉AI任务(a full range of vision AI tasks),以此夸耀其在视觉AI领域无所不能。
a.精确&灵活
YOLOv8官方开源了五种不同参数规模的预训练模型:YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l和YOLOv8x。与参数量相当的YOLOv5 模型相比,YOLOv8在COCO数据集上的准确率实现了较大的提升。其中YOLOv8n和YOLOv8s的准确率提高了 5% 以上,这得益于YOLOv8在网络结构、训练方法、无锚技术和损失函数等方面的改进。相比之下参数量和推理时间的牺牲就微不足道了。

此外,YOLOv8的灵活性则体现在以下三个方面:
1. 由于YOLOv8在准确率方面的提升,在与YOLOv5相同精确程度的情况下其可以使用更轻量化的模型。
2. YOLOv8项目对python命令的支持使模型的训练、推理和导出更加便利。
3. YOLOv8对跟踪算法的支持及其在fastSAM中的应用,使其在工程中具备多样化的使用方法。
b.边端视觉方案的潜在选择
目标检测与跟踪算法的融合是边端不可或缺的视觉能力,这在机器人视觉导航、自动驾驶、军事制导等领域都有着广泛应用。而边端的复杂环境对视觉泛化能力也提出了很高的要求。YOLOv8在这两点上提供了支持:
1. YOLOv8项目已实现BoT-SORT和ByteTrack跟踪算法的融合。
2. FastSAM使用YOLOv8分割网络的主干进行图像数据的特征提取和掩码生成,这提供了一种使用 YOLOv8 实现视觉泛化能力的方案。
以上优势使得 YOLOv8 的边端部署具有更丰富的意义。

02
将模型留在边端
要实现 YOLOv8 模型在机器人等边端产品上运行的目的,我们需要了解模型部署的相关知识。
a.模型部署
Deploying a model refers to placing a machine-learning model into an environment where it can do the job it was created to do.
将机器学习模型安置在恰当“工作岗位”上的过程叫作模型部署。除了将模型的能力植入到需要它的地方外,还伴随着对模型的优化,比如算子融合与重排,权重量化、知识蒸馏等。
模型的设计和训练通常比较复杂,这一过程依赖于灵活的模型开发框架PyTorch,TensorFlow等。模型的使用追求在特定场合下实现模型的“瘦身”及其加速推理,这需要用推理框架 TensorRT、ONNX Runtime 等进行支持。从这个角度理解,模型部署过程也可以看做模型从开发框架到特定推理框架的移植过程。
b.从开发框架到推理框架
模型开发框架和推理框架的多样性便利了模型的设计和使用,也给模型转换带来了挑战。为简化模型部署流程,Facebook和微软在2017年共同发布了一种深度学习模型的中间表示形式:ONNX。这样一来,众多的模型训练框架和推理框架只需与 ONNX 建立联系,即可实现模型格式的相互转换。ONNX 表示形式的出现使模型部署逐渐形成了 “模型开发框架 -> 模型中间表示 -> 模型推理框架” 的范式。
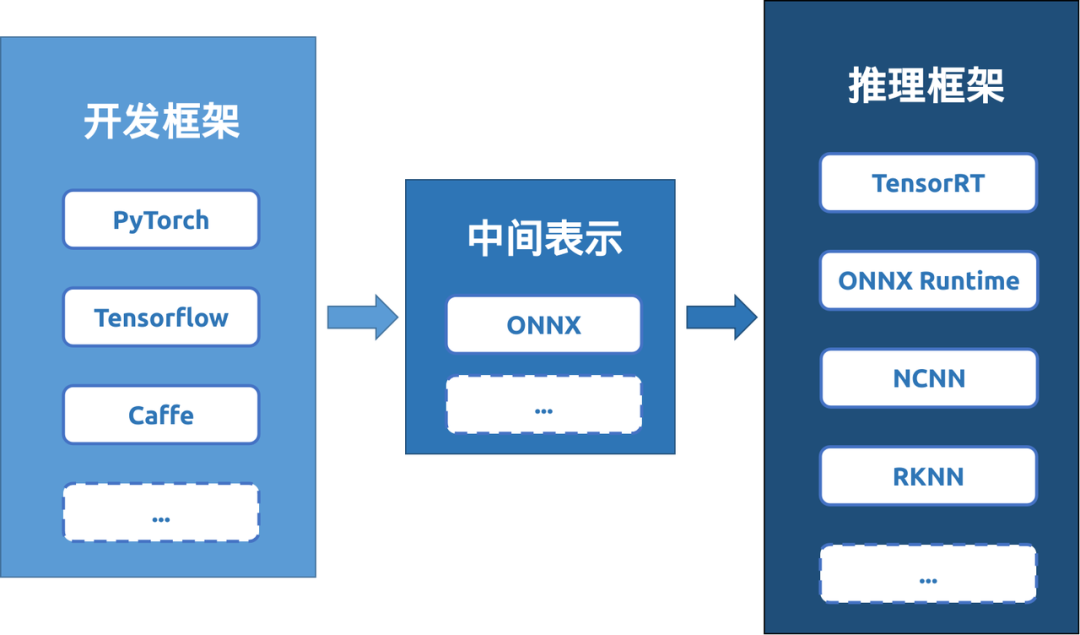
那怎样将开发框架下的模型移植到推理框架下呢?一个容易的想法就是对一个模型进行逐层解析,并使用推理框架支持的工具重新实现该模型的推理过程。不过考虑到模型转换的通用性,目前主流的模型转换过程都是通过“追踪法”实现的:给定一组输入,运行模型并记录这组数据在模型当中经历的计算过程,将此计算过程保存下来作为转换之后的模型[1]。
在模型转换过程中输入的数据除了被用来追踪模型的运算过程外,有时还会被用来优化模型转换中的量化参数。在ONNX到RKNN的转换过程中,模型根据输入数据的最大值、最小值,寻找合适的量化参数。
03
RKNN:高效的边端推理框架
a.专注于神经网络计算的硬件设备——NPU
众所周知,神经网络模型可以在 GPU 上加速推理,但作为一种通用芯片,其设计精细,造价昂贵,体积和功耗较大,部署在边端过于奢侈。随着人工智能的发展,工程人员迫切需要一种专门用于神经网络推理的高效计算设备,NPU正是诞生在这样的需求下。

区别于传统处理器的冯诺依曼结构——存储单元与计算单元分离,NPU 的设计灵感来源于生物体中的神经网络:信息的存储和处理都集中在神经元的突触上。基于该设计理念,NPU 在推理神经网络过程中,数据的计算和存储是一体化的,省去了从存储单元上读取数据的过程。这样做的直接收益是:数据吞吐量有了上百倍的提升。NPU 拥有精简的指令集,一条指令可以完成一组神经元的处理,相似的功能依靠 CPU 和 GPU 配合工作可能需要上千条指令才能完成,这也让 NPU 在功耗、计算性能上展现出独特优势。
b.RKNN 框架支持模型在NPU上的推理
RKNN是 Rockchip NPU 平台使用的一种推理框架,它为深度学习模型在 NPU上的推理提供了便利。为了支持不同框架下训练的模型使用RKNN框架推理,RKNN官方发布了rknn-toolkit开发套件。该工具提供了一系列 Python API 用于支持模型转换、模型量化、模型推理以及模型的状态检测等功能。rknn-toolkit 的安装和使用可以参考官方给出的文档 [2]。
典型的 RKNN 模型部署过程一般需要经历以下四步:
RKNN 模型配置 --> 模型加载 --> RKNN 模型构建 --> RKNN 模型导出
-
RKNN模型配置用于设置模型转换参数,包括输入数据均值、量化类型、量化算法以及模型部署平台等。
-
模型加载是指将转换前的模型加载到程序中,目前 RKNN 支持 ONNX、PyTorch、TensorFlow、Caffe 等模型的加载转换。值得一提的是,模型加载是整个转换过程中的关键步骤,这一步允许工程人员自行指定模型加载的输出层和输出层名称,这决定了原始模型哪些部分参与了模型转换过程。
-
RKNN模型构建用于指定模型是否进行量化、并指定用于量化校正的数据集。
-
RKNN模型导出用于保存转换后的模型。
# 代码示例 rknn = RKNN(verbose=True) rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform='rk3566') rknn.load_onnx(model='./model.onnx', inputs=['images'], outputs=['output0']) rknn.build(do_quantization=QUANTIZE_ON, dataset='./dataset.txt') rknn.export_rknn(export_path='./model.rknn')
c.NPU 加速
“我想把一个 “ 张量逐元素相乘 ” 的计算放在 NPU 上加速,我该怎么做?”
这个问题在现实中或许是没有意义的,因为该功能实现过程的开销可能已经超过了使用 CPU 直接进行计算。但为了进一步理解 RKNN 的框架使用,我们提供一个大致的实现步骤:
-
在ONNX框架下定义一个Mul算子,定义两个输入节点和一个输出节点(这三个节点张量维度相同),并生成一个ONNX模型文件。
-
创建RKNN对象并设置RKNN运行平台。
-
加载模型。指定
inputs = ['输入节点1的名称', '输入节点2的名称'],outputs = ['输出节点的名称']。 -
构建模型。创建一个目标维度的张量存储为图片,作为 dataset 参数。
-
导出模型。
将得到的模型在 RKNN 开发板上加载,设置输入为两个待计算的张量并推理模型,即可实现“张量逐元素相乘”在 NPU 上的加速。
04
YOLOv8 模型转换实例
本文提供了YOLOv8检测模型和分割模型的转换示例。模型转换的关键在于输出层的选择以及对模型输出数据的后处理。
a.检测模型转换(ONNX -> RKNN )
本例选择模型倒数第二层Concat的两侧输入作为模型转换后的输出节点。下方列出了选取输出层位置的代码和网络结构示意图。读者也可自行选择其他节点作为模型的输出。
# Load ONNX model
ret = rknn.load_onnx(model=ONNX_MODEL, outputs=['/model.28/Mul_2_output_0', '/model.28 /Sigmoid_output_0'])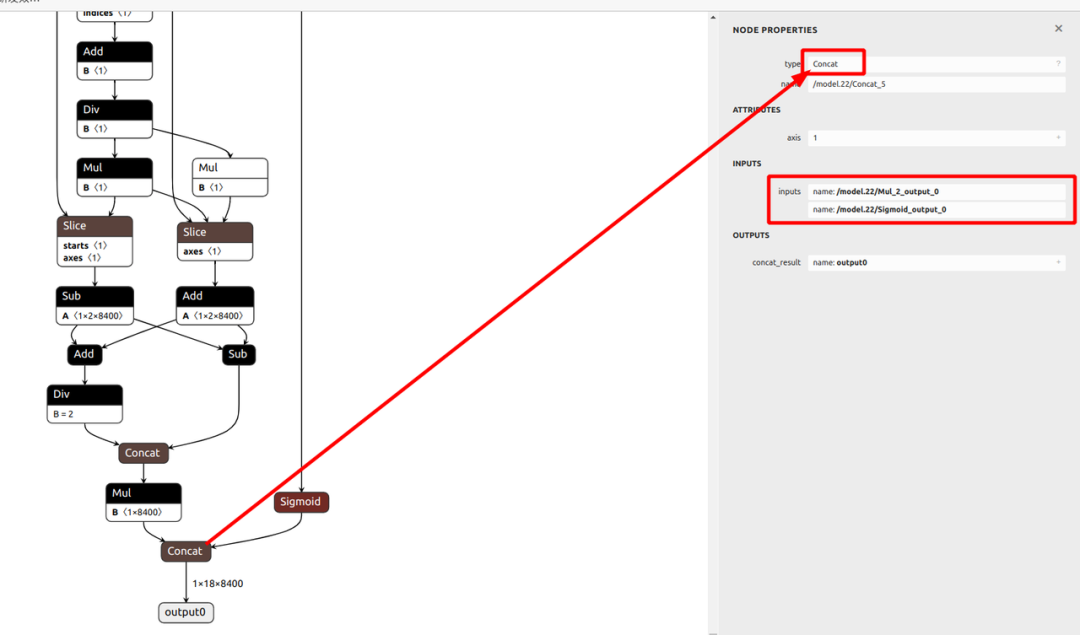
需要注意的是,这里得到的输出只是模型输出(两个四维张量),并非检测结果!为了得到有用的检测框和类别信息,还需手动进行后处理操作。这里我们将 outputs 的维度输出,可以看到输出张量的维度分别是 (1, 4, 34000) 和 (1, 8, 34000) 。这里第一个维度 “1” 表示模型推理的批量大小;第二个维度 “4” 和 “8” 分别表示检测框信息和类别信息(本例中使用的网络有 8 个检测类别);第三个维度表示原始候选框个数。
# Inference
outputs = rknn.inference(inputs=[img])
# 输出维度
print(f'outputs[0].shape : {outputs[0].shape}')
# outputs[0].shape : (1, 4, 34000)
print(f'outputs[1].shape : {outputs[1].shape}')
# outputs[1].shape : (1, 8, 34000)为了测试转换后模型输出的张量是否包含了正确的检测信息,还需要将后处理结果在图片上可视化。模型转换后的结果如下图(右一)所示。与 ONNX 的推理结果相比,模型基本维持了转换前的检测效果。

b.分割模型转换(ONNX -> RKNN )
YOLOv8分割模型的转换与检测模型有许多相似之处。在建立和导出模型的步骤中,本例选择了output1和output0前concat的三个输入,其余部分与检测模型的转换过程一致。读者也可自行选择输出节点。输出节点位置和模型转换代码如下所示:
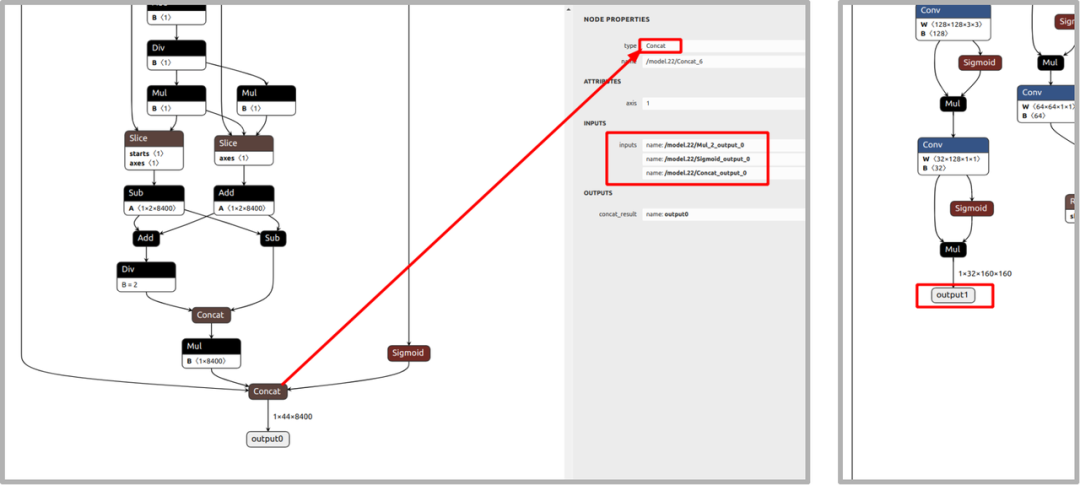
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL, outputs=['/model.22/Mul_2_output_0',
'/model.22/Sigmoid_output_0',
'/model.22/Concat_output_0',
'output1'])将 outputs 的维度输出,得到 4 个张量,其维度分别是 (1, 4, 8400),(1, 8, 8400),(1, 32, 8400) 和 (1, 32, 160, 160)。其中前两个张量包含了检测框信息和目标类别信息,后两个张量包含了掩码信息。由此可见,YOLOv8 分割模型的推理结果中包含了目标检测的结果。
# Inference
outputs = rknn.inference(inputs=[img])
# 输出维度
print(f'outputs[0].shape : {outputs[0].shape}')
# outputs[0].shape : (1, 4, 8400)
print(f'outputs[1].shape : {outputs[1].shape}')
# outputs[1].shape : (1, 8, 8400)
print(f'outputs[2].shape : {outputs[2].shape}')
# outputs[2].shape : (1, 32, 8400)
print(f'outputs[3].shape : {outputs[3].shape}')
# outputs[3].shape : (1, 32, 160, 160)将后处理结果在图片上可视化,模型转换后的结果如下图(右一)所示。与 ONNX的推理结果相比,模型基本维持了转换前的分割效果。

参考:
[1] open-mmlab mmdeploy项目 https://github.com/open-mmlab/mmdeploy/tree/main/docs/zh_cn/tutorial
[2] rknn-toolkit2 官方文档 https://github.com/rockchip-linux/rknn-toolkit2/blob/master/doc/Rockchip_Quick_Start_RKNN_Toolkit2_CN-1.5.0.pdf
另外,我们正在组建机器人行业交流群,如果你对机器人技术、热点、产品及应用感兴趣,欢迎私聊小智~














 1726
1726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









