







题目来源
题目描述
给定一个不为空的二叉搜索树和一个目标值 target,请在该二叉搜索树中找到最接近目标值 target 的 k 个值。
注意:
- 给定的目标值 target 是一个浮点数
- 你可以默认 k 值永远是有效的,即 k ≤ 总结点数
- 题目保证该二叉搜索树中只会存在一种 k 个值集合最接近目标值
示例:
- 输入: root = [4,2,5,1,3],目标值 = 3.714286,且 k = 2
- 输出: [4,3]
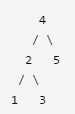
拓展:
- 假设该二叉搜索树是平衡的,请问您是否能在小于 O(n)(n 为总结点数)的时间复杂度内解决该问题呢?
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode() : val(0), left(nullptr), right(nullptr) {}
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
};
class Solution{
public:
std::vector<int> closestKValues(TreeNode *root, double target, int k){
}
};
题目解析
小根堆
思路
- 使用最小堆
- 将树中节点的值和给定的目标值计算出对应的差值,并和节点值一起组成pair类型,存储到最小堆中
- 再从最小堆中弹出前k个值对应的节点值,存储到结构中即可
class Solution{
std::priority_queue<std::pair<double , int>, std::vector<pair<double , int>>, std::greater<>> qMin;
void dfs(TreeNode *root, double &target){
if(root == nullptr){
return;
}
qMin.push({std::abs(root->val * 1.0 - target), root->val});
dfs(root->left, target);
dfs(root->right, target);
}
public:
std::vector<int> closestKValues(TreeNode *root, double target, int k){
dfs(root, target);
std::vector<int> res;
for (int i = 0; i < k; ++i) {
res.push_back(qMin.top().second);
qMin.pop();
}
return res;
}
};
最大堆
思路
- 使用最大堆存储 k 个值,超过 k 个值时,弹出多出的元素,最后将最大堆中的 k 个元素的值输出给数组即可;
class Solution{
std::priority_queue<std::pair<double , int>, std::vector<pair<double , int>>, std::less<>> qMin;
void dfs(TreeNode *root, double &target, int k){
if(root == nullptr){
return;
}
qMin.push({std::abs(root->val * 1.0 - target), root->val});
if(qMin.size() > k){
qMin.pop();
}
dfs(root->left, target, k);
dfs(root->right, target, k);
}
public:
std::vector<int> closestKValues(TreeNode *root, double target, int k){
dfs(root, target, k);
std::vector<int> res;
while (!qMin.empty()) {
res.push_back(qMin.top().second);
qMin.pop();
}
return res;
}
};
二分搜索
思路
- 先使用中序遍历将树中的元素存储到辅助数组中,在有序数组中需要和目标值最近的k个值
class Solution {
public:
vector<int> closestKValues(TreeNode* root, double target, int k) {
vector<int> res, v;
inorder(root, v);
int idx = 0;
double diff = numeric_limits<double>::max();
for (int i = 0; i < v.size(); ++i) {
if (diff >= abs(target - v[i])) {
diff = abs(target - v[i]);
idx = i;
}
}
int left = idx - 1, right = idx + 1;
for (int i = 0; i < k; ++i) {
res.push_back(v[idx]);
if (left >= 0 && right < v.size()) {
if (abs(v[left] - target) > abs(v[right] - target)) {
idx = right;
++right;
} else {
idx = left;
--left;
}
} else if (left >= 0) {
idx = left;
--left;
} else if (right < v.size()) {
idx = right;
++right;
}
}
return res;
}
void inorder(TreeNode *root, vector<int> &v) {
if (!root) return;
inorder(root->left, v);
v.push_back(root->val);
inorder(root->right, v);
}
};
思路:在中序遍历时直接比较
- 当遍历到一个节点时,如果此时结果数组不到k个,直接将此节点值加入结果 res 中
- 如果该节点值和目标值的差值的绝对值小于结果 res 的首元素和目标值差值的绝对值,说明当前值更靠近目标值,则将首元素删除,末尾加上当前节点值,反之的话说明当前值比结果 res 中所有的值都更偏离目标值,由于中序遍历的特性,之后的值会更加的偏离,所以此时直接返回最终结果即可
class Solution {
public:
vector<int> closestKValues(TreeNode* root, double target, int k) {
vector<int> res;
inorder(root, target, k, res);
return res;
}
void inorder(TreeNode *root, double target, int k, vector<int> &res) {
if (!root) return;
inorder(root->left, target, k, res);
if (res.size() < k) res.push_back(root->val);
else if (abs(root->val - target) < abs(res[0] - target)) {
res.erase(res.begin());
res.push_back(root->val);
} else return;
inorder(root->right, target, k, res);
}
};















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









