







题目来源
题目描述
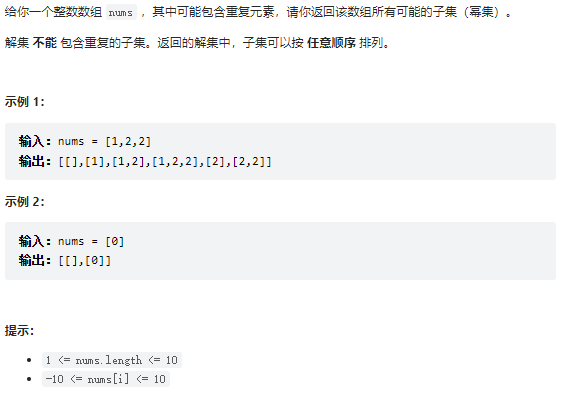
题目解析
如果没有重复元素
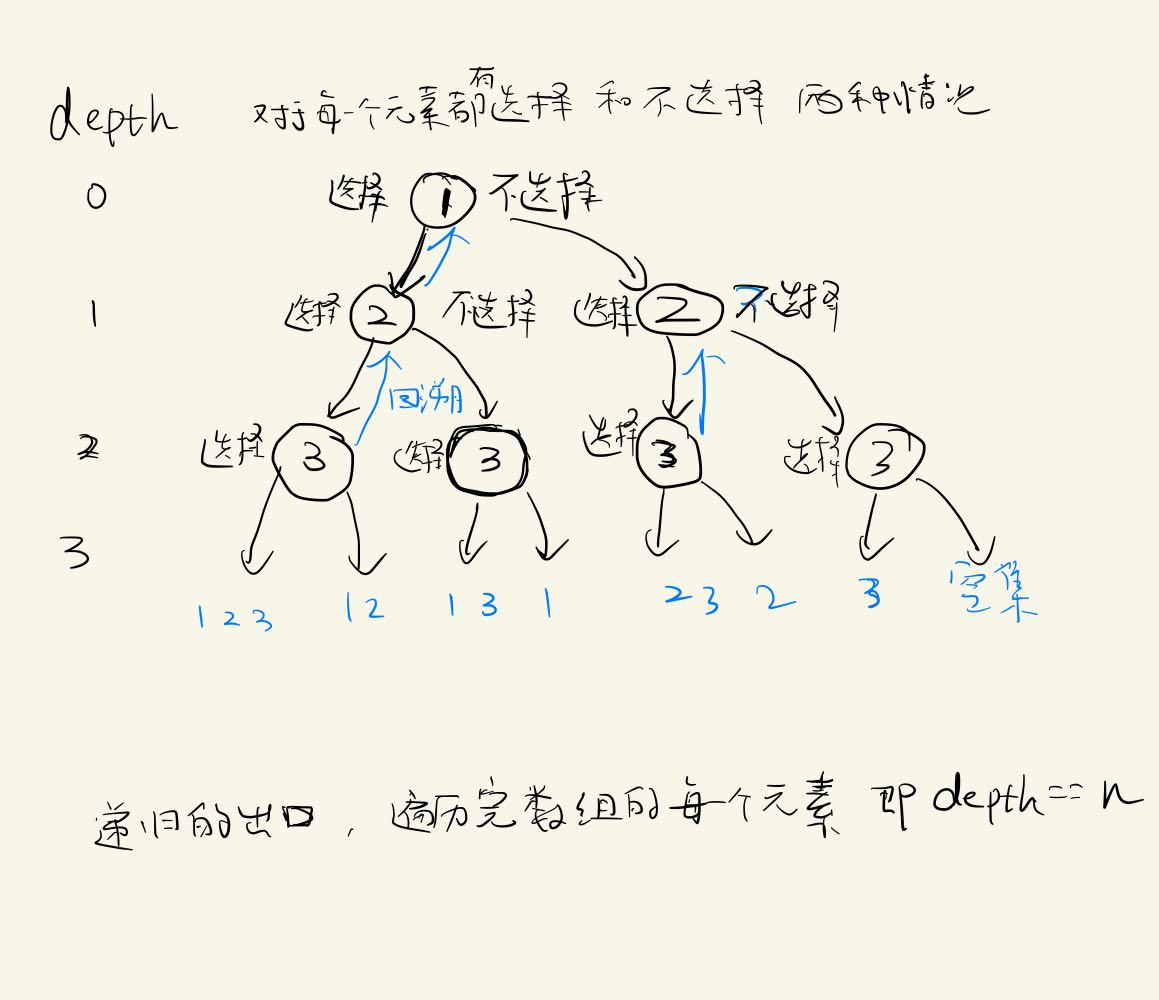
如果重复元素

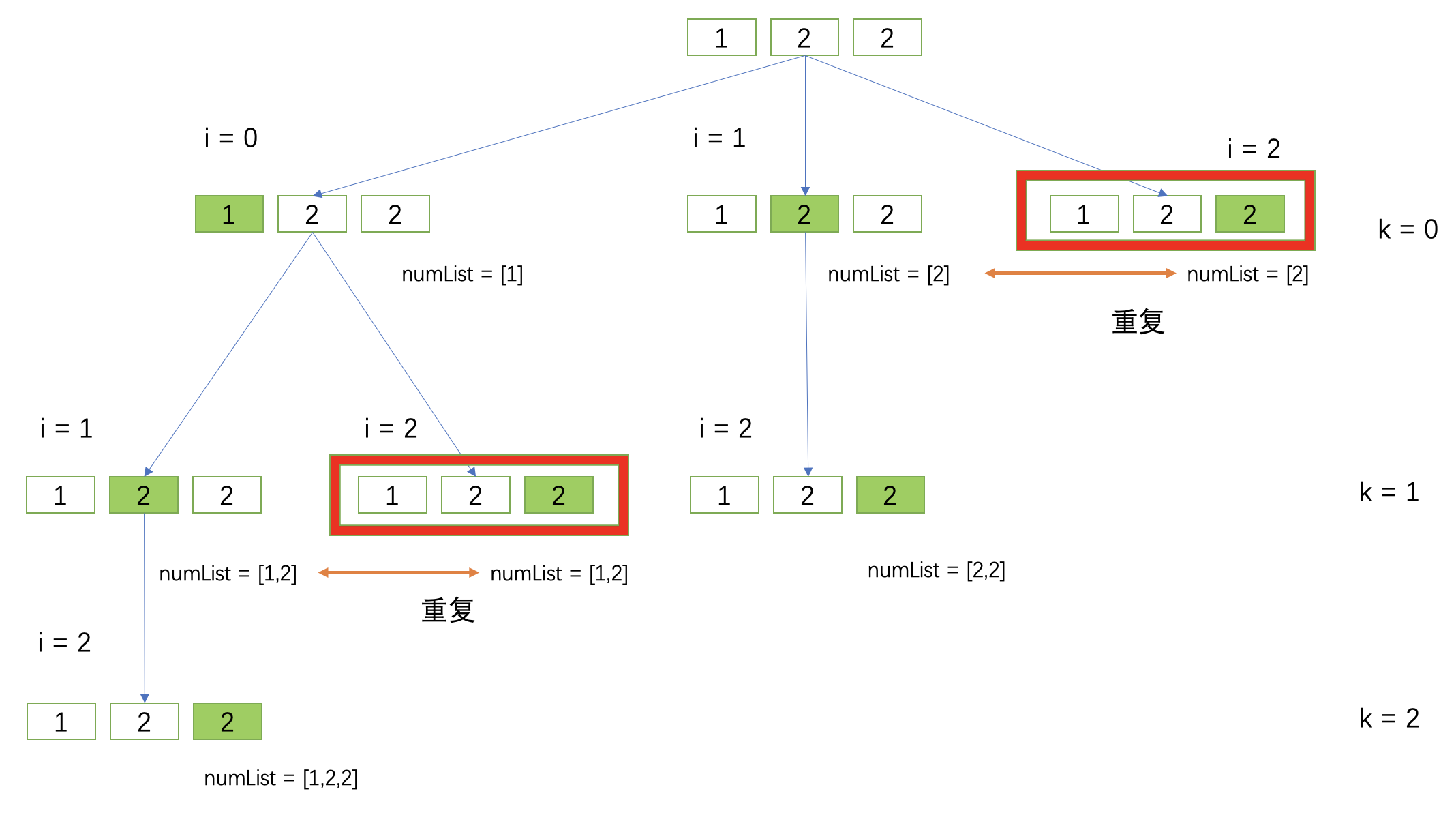
重复的原因是:刚刚选择了,然后撤销了这个选择,之后又选择了和刚刚相同的元素
class Solution {
std::vector<std::vector<int>> ans;
std::vector<int> path;
void dfs(vector<int>& nums, int i){
if(i == nums.size()){
ans.push_back(path);
return;
}
path.push_back(nums[i]);
dfs(nums, i + 1);
path.pop_back();
while (i + 1 < nums.size() && nums[i] == nums[i + 1]){
++i;
}
dfs(nums, i + 1);
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
std::sort(nums.begin(), nums.end());
ans.emplace_back();
dfs(nums, 0);
return ans;
}
};
解题思路
一般情况下,看到题目要求「所有可能的结果」,而不是「结果的个数」,我们就知道需要暴力搜索所有的可行解了,可以用「回溯法」。
「回溯法」实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就「回溯」返回,尝试别的路径。
回溯法是一种算法思想,而递归是一种编程方法,回溯法可以用递归来实现。
回溯法的整体思路是:搜索每一条路,每次回溯是对具体的一条路径而言的。对当前搜索路径下的的未探索区域进行搜索,则可能有两种情况:
- 当前未搜索区域满足结束条件,则保存当前路径并退出当前搜索;
- 当前未搜索区域需要继续搜索,则遍历当前所有可能的选择:如果该选择符合要求,则把当前选择加入当前的搜索路径中,并继续搜索新的未探索区域。
上面说的未搜索区域是指搜索某条路径时的未搜索区域,并不是全局的未搜索区域。
回溯法搜所有可行解的模板一般是这样的:
res = []
path = []
def backtrack(未探索区域, res, path):
if path 满足条件:
res.add(path) # 深度拷贝
# return # 如果不用继续搜索需要 return
for 选择 in 未探索区域当前可能的选择:
if 当前选择符合要求:
path.add(当前选择)
backtrack(新的未探索区域, res, path)
path.pop()
backtrack 的含义是:未探索区域中到达结束条件的所有可能路径,path 变量是保存的是一条路径,res 变量保存的是所有搜索到的路径。所以当「未探索区域满足结束条件」时,需要把 path 放到结果 res 中。
path.pop() 是啥意思呢?它是编程实现上的一个要求,即我们从始至终只用了一个变量 path,所以当对 path 增加一个选择并 backtrack 之后,需要清除当前的选择,防止影响其他路径的搜索。
对于求不含重复元素的数组的子集,思路如下:
- 未搜索区域:剩余的未搜索的数组
nums[indexx : N - 1] - 每个path是否满足题目的条件:任何一个path的子集,都满足条件,都要放到res中
- 当前path满足条件时,是否继续搜索:使得,找到
nums[0:index-1]中的子集之后,nums[index]添加到老的path中形成新的子集 - 未探索区域当前可能的选择:每次选择可以选取 s 的 1 个字符,即
nums[index]; - 当前选择符合要求:任何 nums[index] 都是符合要求的,直接放到 path 中;
- 新的未探索区域:nums 在 index 之后的剩余字符串, nums[index + 1 : N - 1] 。
上面分析了那么多,让我们看看代码怎么写。由于每个path都是一个子集,都满足条件,所以就省略了一个 if 判断,并且由于当前 path 满足条件时,应该继续搜索,所以也省略了 if 中的 return 语句。
代码如下:
class Solution {
std::vector<std::vector<int>> ans;
std::vector<int> path;
void dfs(vector<int>& nums, int idx){
ans.push_back(path);
for (int i = idx; i < nums.size(); ++i) {
path.push_back(nums[i]);
dfs(nums, idx + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
dfs(nums, 0);
return ans;
}
};
对于本题,含有重复元素,比如说求 nums = [1,2,2] 的子集,那么对于子集 [1,2] 是选择了第一个 2,那么就不能再选第二个 2 来构成 [1,2] 了。所以,此时的改动点,就是先排序,每个元素 nums[i] 添加到 path 之前,判断一下 nums[i] 是否等于 nums[i - 1] ,如果相等就不添加到 path 中。
class Solution {
std::vector<std::vector<int>> ans;
std::vector<int> path;
void dfs(vector<int>& nums, int idx){
if(idx > nums.size()){
return;
}
ans.push_back(path);
for (int i = idx; i < nums.size(); ++i) {
if (i != idx && nums[i] == nums[i - 1]) continue;
path.push_back(nums[i]);
dfs(nums, idx + 1);
path.pop_back();
}
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
dfs(nums, 0);
return ans;
}
};















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









