







题目来源
题目描述
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
}
};
题目解析
数学归纳法
举个例子,比如nums = [1,2,3]的子集是[ [],[1],[2],[3],[1,3],[2,3],[1,2],[1,2,3] ]。
我们先来看看[1,2]的子集,它为:[ [],[1],[2],[1,2] ]
可以发现:subset( [1,2,3] ) - subset( [1,2] ) = [3],[1,3],[2,3],[1,2,3]
⽽这个结果,就是把 sebset( [1,2] ) 的结果中每个集合再添加上 3。
换句话说,如果 A = subset([1,2]) ,那么:subset( [1,2,3] ) = A + [A[i].add(3) for i = 1…len(A)]
这就是⼀个典型的递归结构嘛, [1,2,3] 的⼦集可以由 [1,2] 追加得出, [1,2] 的⼦集可以由 [1] 追加得出,base case 显然就是当输⼊集合为空集时,输出⼦集也就是⼀个空集。
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
// base case,返回⼀个空集
if (nums.empty()) return {{}};
// 把最后⼀个元素拿出来
int n = nums.back();
nums.pop_back();
// 先递归算出前⾯元素的所有⼦集
vector<vector<int>> res = subsets(nums);
int size = res.size();
for (int i = 0; i < size; i++) {
// 然后在之前的结果之上追加
res.push_back(res[i]);
res.back().push_back(n);
}
return res;
}
};
思路一
- 单看每个元素,都有两种选择:选入子集、不选入子集
- 比如
[1, 2, 3],先看1,选1或者不选1;然后再看2,选2或者不选2,依此类推 - 考察当前枚举的数,基于选它而继续,是一个递归分支;基于不选它而继续,又是一个分支
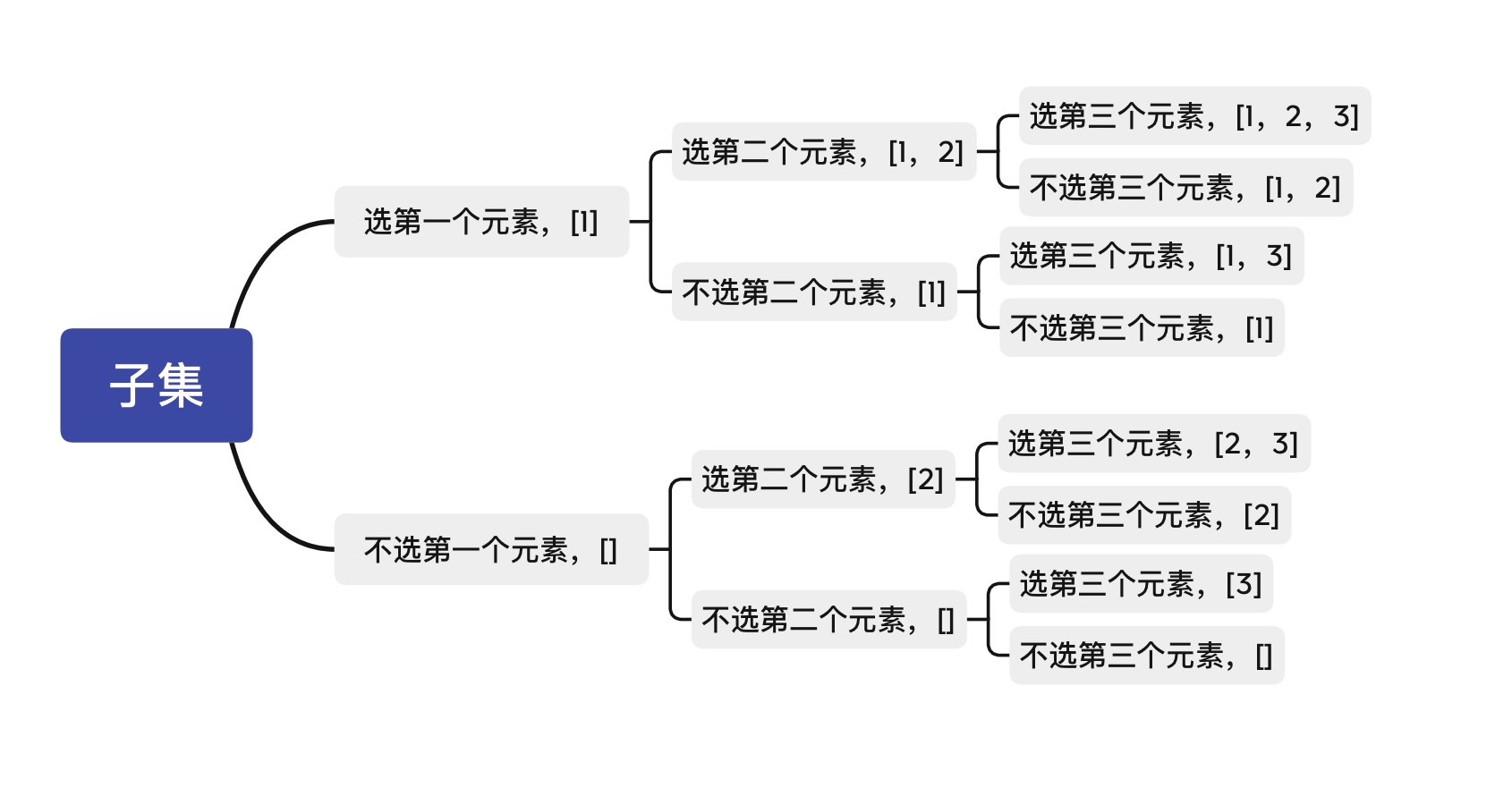
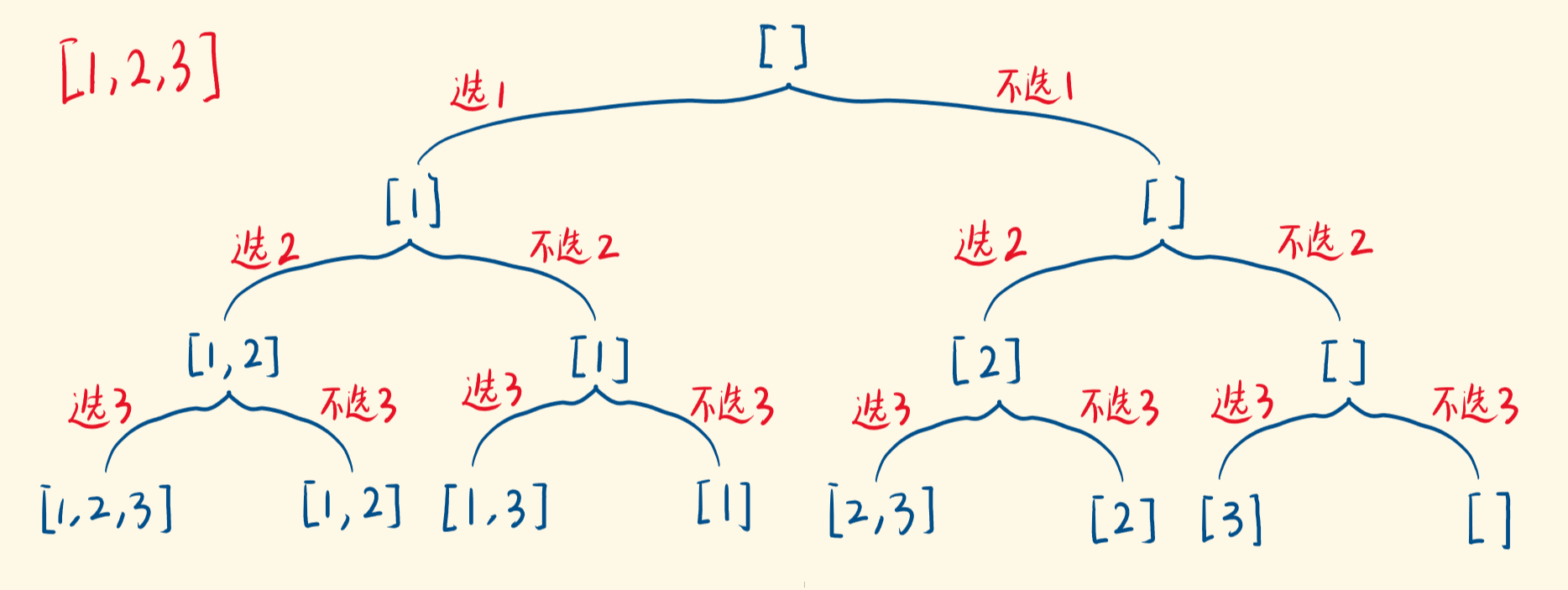
- 用索引
index代表当前递归考察的数nums[index] - 当
index越界时,说明所有数字考察完了,得到一个解,把它加入解集,结束当前递归分支
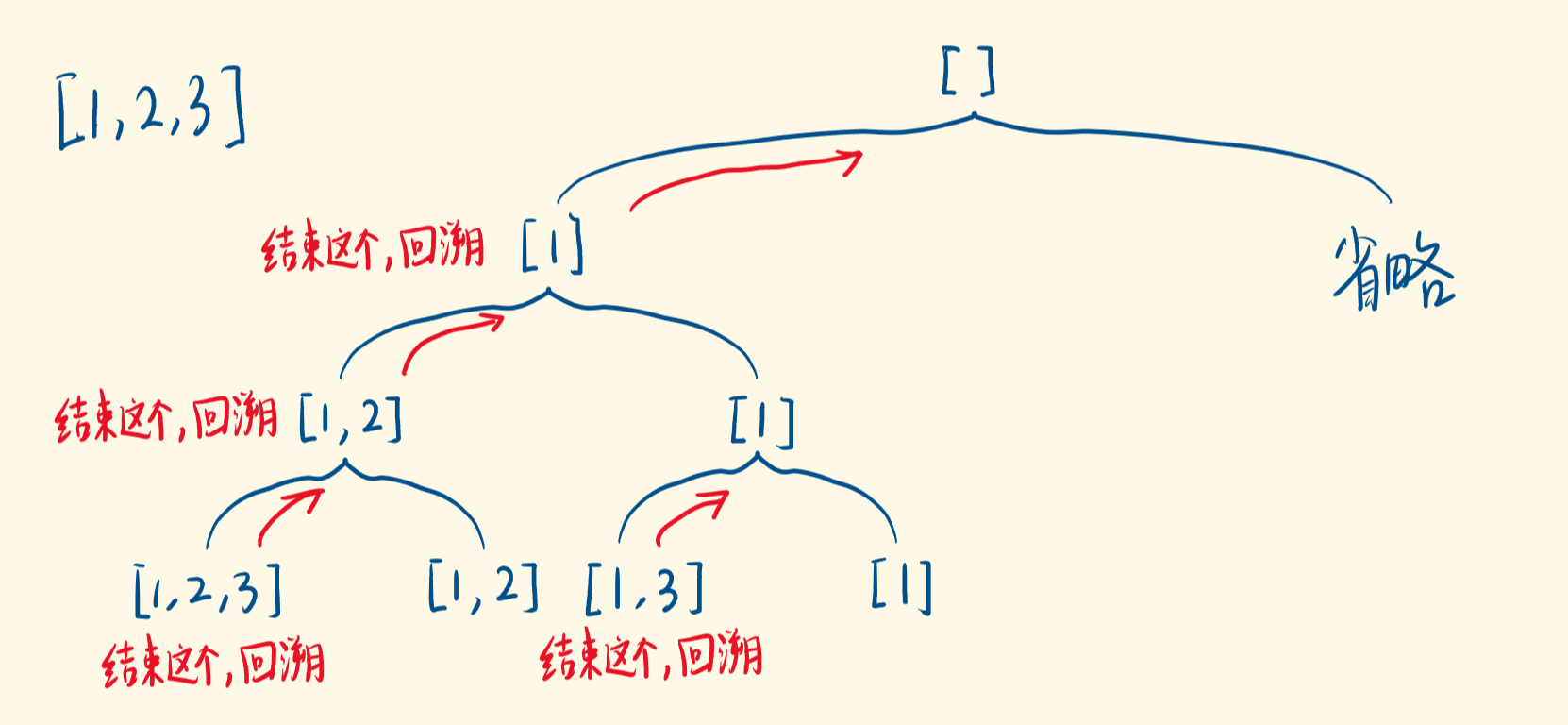
为什么要回溯
- 因为不是找到一个自己就完事
- 找到一个子集,结束递归,要撤销当前选择,回到选择前的状态,做另一个选择----不选当前的数,基于不选,往下递归,继续生成子集
- 回退到上一步,才能再包含解的空间树中把路走全,回溯出所有的解
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> ans;
std::function<void(int , std::vector<int>&)> dfs = [&](int i, std::vector<int> &path){
if(i == nums.size()){ // 调用子递归前,加入解集
ans.emplace_back(path); // 加入解集
return; // 结束当前的递归
}
path.emplace_back(nums[i]); // 选择这个数
dfs(i + 1, path); // 基于该选择,继续往下递归,考察下一个数
path.pop_back(); // 上面的递归结束,撤销该选择
dfs(i + 1, path); // 不选这个数,继续往下递归,考察下一个数
};
std::vector<int> path;
dfs(0, path);
return ans;
}
};
class Solution {
public:
vector<vector<int>> ans;
int len;
vector<vector<int>> subsets(vector<int>& nums) {
//对于每个元素,两个选择,包含,不包含
vector<int> track;
len = nums.size();
ans.push_back({});//直接把空集先放入,不然后面会多次放入空集
dfs(0,track,nums);
return ans;
}
void dfs(int index, vector<int> &track,vector<int>& nums){
if(index==len) return;
track.push_back(nums[index]);
ans.push_back(track);
dfs(index+1,track,nums);//包含当前元素
track.pop_back();
dfs(index+1,track,nums);//不包含
return;
}
};
class Solution {
vector<vector<int>> ans;
vector<int>path;
// 当前来到idx位置做决定
// [0....idx-1]已经决定好了
// 每个位置两种选择:要& 不要
void process(vector<int>& nums, int idx){
if(idx == nums.size()){
ans.push_back(path);
return;
}
process(nums, idx + 1);
path.push_back(nums[idx]);
process(nums, idx + 1);
path.pop_back();
}
public:
vector<vector<int>> subsets(vector<int>& nums) {
process(nums, 0);
return ans;
}
};
思路二
- 刚才的思路是:逐个考察数字,每个数都选或不选。等到递归结束的时候,把集合加入解集
- 换一种思路:在执行子递归之前,加入解集,即,在递归压栈前 “做事情”。
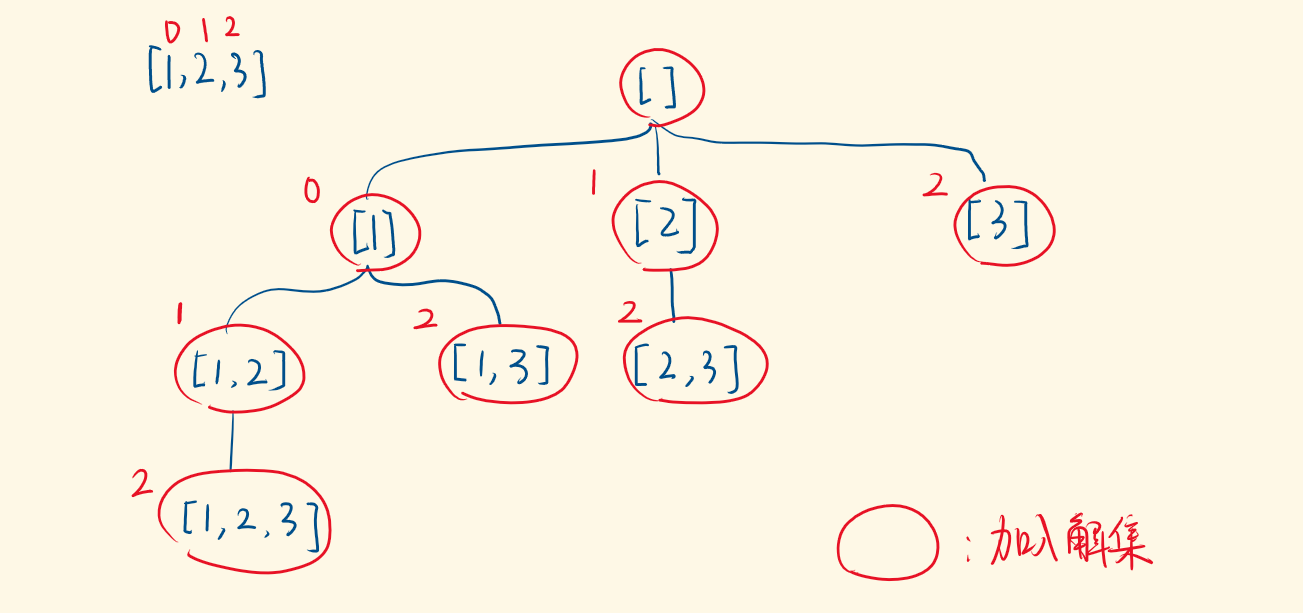
- 用for枚举出当前可选的数,比如选第一个数时:1、2、3可选
- 如果第一个数选 1,选第二个数,2、3 可选;
- 如果第一个数选 2,选第二个数,只有 3 可选(不能选1,产生重复组合)
- 如果第一个数选 3,没有第二个数可选
- 即,每次传入子递归的index是:当前你选的数的索引 + 1
- 每次递归的选项变少,一直递归到没有可选的数字,那就进不了for循环,落入不了递归,整个DFS结束
- 可见我们没有显示的设置递归的出口,而是通过控制循环的起点,使得最后递归自然结束
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> ans;
std::function<void(int , std::vector<int>&)> dfs = [&](int i, std::vector<int> &path){
ans.push_back(path); // 调用子递归前,加入解集
for (int j = i; j < nums.size(); ++j) { // 枚举出所有可选的数
path.push_back(nums[j]); // 选这个数
dfs(j + 1, path); // 基于选这个数,继续递归,传入的是j+1,不是i+1
path.pop_back(); // 撤销选这个数
}
};
std::vector<int> path;
dfs(0, path);
return ans;
}
};
可以看见,对res更新的位置处在前序遍历,也就是说,res就是树上的所有节点
动态规划
划分子集问题符合动态规划使用条件:
- 大问题可拆分:当前以第i个元素结尾的子集 = 前面i-1个元素的子集 + 前面所有i-1个元素子集里加入第i个元素
- 最优子结构性:当前解的最优解可根据前一个状态的最优解求出
- 无后效性:怎么求出前i-1个元素子集的最优解对后面的结构没有影响
可以这么表示,dp[i]表示前i个数的解集,可表达为dp[i] = dp[i - 1] + collections(i)。其中,collections(i)表示把dp[i-1]的所有子集都加上第i个数形成的子集。
【具体操作】
因为nums大小不为0,故解集中一定有空集。令解集一开始只有空集,然后遍历nums,每遍历一个数字,拷贝解集中的所有子集,将该数字与这些拷贝组成新的子集再放入解集中即可。时间复杂度为O(n^2)。
- 例如[1,2,3],一开始解集为[[]],表示只有一个空集。
- 遍历到1时,依次拷贝解集中所有子集,只有[],把1加入拷贝的子集中得到[1],然后加回解集中。此时解集为[[], [1]]。
- 遍历到2时,依次拷贝解集中所有子集,有[], [1],把2加入拷贝的子集得到[2], [1, 2],然后加回解集中。此时解集为[[], [1], [2], [1, 2]]。
- 遍历到3时,依次拷贝解集中所有子集,有[], [1], [2], [1, 2],把3加入拷贝的子集得到[3], [1, 3], [2, 3], [1, 2, 3],然后加回解集中。此时解集为[[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3]]。

class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums){
if(nums.size()==0)return {{}};
vector<vector<int>> ans;
ans.emplace_back(); // 首先将空集加入解集中
for (int i = 0; i < nums.size(); ++i) { //当前新加入的值nums[i]
int last_size = ans.size(); //前面i-1子集中元素个数
for(int j = 0;j<last_size;j++){ //将nums[i]分别放进ans[j]的各个vector中,再放进ans中
//nums[i]放进空集
if(ans[j].empty())
ans.push_back({nums[i]});
else{
//可以写成一句,拆开方便阅读
vector<int> temp;
temp = ans[j];
temp.push_back(nums[i]);
ans.push_back(temp);
}
}
}
return ans;
}
};
分治法
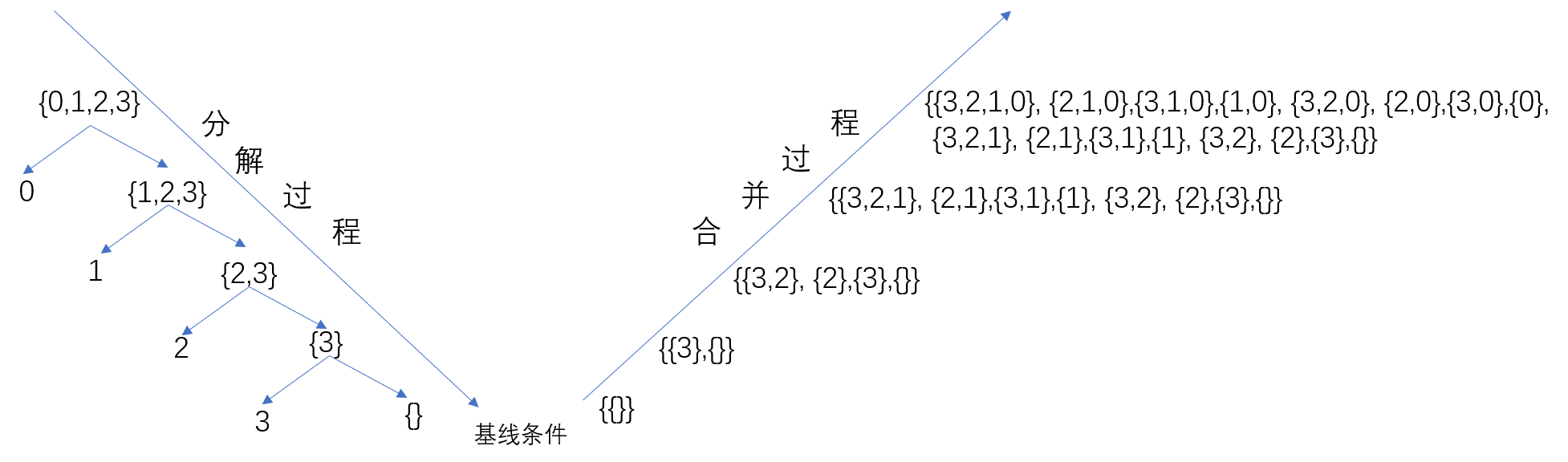
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
if(nums.size()==0){
return {{}};
}
int temp_int=nums.back();
nums.pop_back();
vector<vector<int>>temp_vec_vec=subsets(nums);
int k=temp_vec_vec.size();
for(int i=0;i<k;i++){
temp_vec_vec.push_back(temp_vec_vec[i]);
temp_vec_vec[i].push_back(temp_int);
}
return temp_vec_vec;
}
};
类似题目
| 题目 | 思路 |
|---|---|
| leetcode:77. 给定集合[1…n],从中挑选k(指定)个数,返回所有组合(每个数可以用一次) combination | 组合是顺序无关的,如 [1,2] 和 [2,1] 是同一个组合不同排列。组合时需要一个idx来排除已经选过的数:对于每个数,有两种选择,要,不要;当path.size()==k时时表示找到了一种组合 |
| leetcode:46. 无序(不重复)数组所有的全排列 Permutations | 数要全部用光(每个答案长度是固定的),所以对于第一位可以选择num[0…x],对于第二位可以选择除了第一位的所有选择…直到所有数全部用完 |
| leetcode:78. 无序(不重复)数组所有的不重复子集subsets | 对于每一个元素,都有选择和不选择两种选择,一直到没有元素可选了,才收集可能的答案 |
| leetcode:90. 无序(可重复)数组所有的不重复子集 Subsets II | 怎么去重呢?重复的原因是:刚刚选择了,然后撤销了这个选择,之后又选择了和刚刚相同的元素;所以先排序,然后去重(为什么要排序,将重复的元素放在一起,便于剪枝) |
| leetcode:320.列举单词的全部缩写 Generalized Abbreviation | 对于每一个字符,可以用1代替或者取原来的。如果发现有多个1就变为加起来的数 |
| leetcode:784. 给定一个字符串,可以将字母变大写或者小写,能够得到的全排列 letter-case-permutation | 对于每一个字母,有变大写、边小写两种选择 。到了idx == str.size(),说明已经得到了一个答案 |
| - leetcode:1755. 最接近目标值的子序列和 | 将数组一分为二,分别枚举出左半边和右半边的子集和。那么原数组的一个子序列和,一定是下面三者之一:lsum中的某个元素、rsum中的某个元素,lsum和rsum中的某个元素之和。对于第三种情况,相当于:给定两个数组,如何在两个数组中各选出一个整数,令它们的和尽可能的接近目标值。可以用双指针来做 |















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









