







0、需求说明
数据格式

期望输出的结果
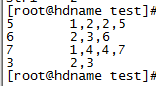
做简单分析:
a. 由于只有两列,所以可以将map的InputFormat设置为KeyValueTextInputFormat
b. 事实上这里实现了两个排序,即对输出的key和value都做了排序,对于value相当于是分组排序,这种时候需要将key和value放在同一个对象中,所以自定义一个类型
1.自定义(key)类型
结果类型为 StrWritable(String strName,String strValue),并未实现构造方法,只是为了方便查看
完整的代码将放在最后面
将两列做为一个对象,自定义这个对象,继承WritableComparable,实现以下方法
方法的实现:
set、get方法 –>set方法在map中用来设置输入的key,故可以选择合并起来,get方法将在后续的reduce和排序中用来获取值
自定义类型实现序列化和反序列化
compareTo方法 –> 这个方法在排序中会用到,因为MR框架中的默认排序是使用key对象中的该方法进行的,所以如果不实现自己的排序方法的话,重写这个类是必要的
这里还有一些诸如toString、hashcode、equal等方法可以实现,根据需要选择,如在默认的分区中MR框架会调用hashcode方法
2、hadoop中的辅助排序
辅助排序分三种,分别为分区partitioner、key比较函数Comparator 、分组函数Grouping Comparator
在本文中只实现了后两者,类名分别为:StrNameComparator 和SortComparator
StrNameComparator 是对 StrWritable(String strName,String strValue)中的strName比较
SortComparator的处理是当传入的两个对象的strName不一致时,对strValue进行比较,结果都是返回int
完整的代码将放在最后面
a. partitioner
将满足相同条件的map结果分到同一个reduce中,默认是根据key的hashCode来分配的,重写只要实现getPartition方法即可
该类的作用是在map之后运行的
在job调用中提供的方法是 job.setPartitionerClass(Partitioner p)
b. key Comparator
默认使用compareTo方法,在自定义这里重定义了排序方法,即以key中的第一列进行排序
在partitioner之后进行,会将相同key的value放到一起进行迭代
下图是一种在StrWritable(String strName,String strValue)中针对 strName实现的key排序
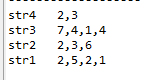
注意这里并没有对 str2实现排序
在job中提供的方法是
job.setSortComparatorClass(StrNameComparator.class)
c. Grouping Comparator
在reduce阶段,会构造一个key对应的value迭代器,同一个reduce里面具有相同key的数据会被分到同一个组
分组函数,注意这个分组函数的排序排的是对应的组,而不是结果。
即如果要实现对分组的结果(如b中的strValue)进行排序的话,那么需要先对组(b中的strName)进行排序,分组函数设置的排序类既是这个
然后再设置job的setSortComparatorClass进行strValue的比较,完整的设置如下
job.setSortComparatorClass(SortComparator.class);
//在b中,没有下面一行,并且这里设置的值是StrNameComparator.class
job.setGroupingComparatorClass(StrNameComparator.class);d. key比较函数与分组函数的补充说明
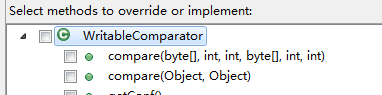
在b和c中出现的两个类 StrNameComparator 、SortComparator继承的类都是hadoop.io中的WritableComparator,每一个实现都需要对比较的对象进行注册,然后根据需要重写其中的compare方法,如下图

事实上在hadoop 中还提供了一种更原生的比较器 RawComparator,WritableComparator就是其子类,RawComparator的一个优势在与其可以直接对序列化的对象进行比较
还有就是在writablecomparable中对compare实现了多态,其中之一就是对字节的比较,本文中有偷懒,直接对字符串用compareTo进行比较
3、代码
a.StrWritable 自定义类
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class StrWritable implements WritableComparable<StrWritable>{
private String strName;
private String strValue;
public void setstrName(String strName) {
this.strName = strName;
}
public void setstrValue(String strValue) {
this.strValue = strValue;
}
public String getstrName() {
return strName;
}
public String getstrValue() {
return strValue;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(strName);
out.writeUTF(strValue);
}
@Override
public void readFields(DataInput in) throws IOException {
strName =in.readUTF();
strValue =in.readUTF();
}
@Override
public int compareTo(StrWritable o) {
//这里只对StrName进行比较,在Job中在没有分组函数情况下,默认是这个排序,也可以重新定义
int i= o.getstrName().compareTo(this.strName);
//if(i!=0)
return i;
//return o.getstrName().compareTo(this.strName);
}
}b. Map函数
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MapStr extends Mapper<Object, Text, StrWritable, IntWritable>{
private StrWritable sw=new StrWritable();
private IntWritable intWritable =new IntWritable(0);
@Override
protected void map(Object key, Text value,
Context context)
throws IOException, InterruptedException {
// 这里用的inputformat输入格式为KeyValueTextInputFormat 所以会自动将key设置为第一列,第二列为value
sw.setstrName(key.toString());
sw.setstrValue(value.toString());
int valueint=Integer.parseInt(value.toString());
System.out.println("Map key " +sw.getstrName() +" "+sw.getstrValue()+" value "+valueint);
intWritable.set(valueint);
context.write(sw, intWritable);
}
}c. Reducer函数
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReduceStr extends Reducer<StrWritable, IntWritable, Text, Text>{
//static{System.out.println("-----------------------------------");}
@Override
protected void reduce(StrWritable sw, Iterable<IntWritable> iterable,
Context context)
throws IOException, InterruptedException {
Iterator<IntWritable> it =iterable.iterator();
StringBuffer sb = new StringBuffer();
while(it.hasNext()){
sb.append(it.next().get()).append(',');
}
if(sb.length()>0)
sb.deleteCharAt(sb.length()-1);
//System.out.println(sw.getstrName() +" "+sb.toString());
context.write(new Text(sw.getstrValue()), new Text(sb.toString()));
}
}d. StrNameComparator 分组函数
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/*关于实现的是降序还是升序问题,进行比较看返回值,返回1为升序 -1位降序
* */
public class StrNameComparator extends WritableComparator{
public StrNameComparator(){
super(StrWritable.class,true);
}
@Override
@SuppressWarnings("rawtypes")
public int compare(WritableComparable a, WritableComparable b) {
StrWritable s1 = (StrWritable)a;
StrWritable s2 =(StrWritable)b;
return s1.getstrName().compareTo(s2.getstrName());
}
}e. SortComparator 二次排序函数
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class SortComparator extends WritableComparator{
public SortComparator(){
super(StrWritable.class,true);
}
@Override
@SuppressWarnings("rawtypes")
public int compare(WritableComparable a, WritableComparable b) {
StrWritable s1 = (StrWritable)a;
StrWritable s2 =(StrWritable)b;
int i = s1.getstrName().compareTo(s2.getstrName());
if(i!=0)
return i;
return s1.getstrValue().compareTo(s2.getstrValue());
}
f. Job主方法
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobStr {
/**
* @param args
* @throws IOException
* @throws InterruptedException
* @throws ClassNotFoundException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if(args.length!=2){
System.err.println("输入正确的参数");
System.exit(2);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"JobStr Dino");
job.setJarByClass(JobStr.class);
job.setMapperClass(MapStr.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setReducerClass(ReduceStr.class);
job.setMapOutputKeyClass(StrWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setSortComparatorClass(SortComparator.class);
job.setGroupingComparatorClass(StrNameComparator.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//判断输入路径是否存在,存在即删除
FileSystem fs= FileSystem.get(URI.create(args[1]), conf);
Path path = new Path(args[1]);
if(fs.exists(path))
{ try
{
fs.delete(path, true);
System.out.println(path.getName() + "删除成功 ");
}catch(Exception e){
System.err.println(e.getMessage());
}
}
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}4、总结
在这里尽量把我自己总结的东西分享出来,未必能让大家懂甚至也可能存在一些不妥的地方,但都希望能被大家借鉴到一些;在这总结中也存在知识深度的不够,比如partitioner、排序带来的是升序还是降序该怎么控制等等,由于是刚开始写博客,对markdown不太会用,以后都慢慢改进,请大家将就。
欢迎大家一起交流。















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









