







在连续百度和google之后都发现找不到任何一个解决的方法,几乎所有人都是说是hadoop(插件)自身的问题,建议打包成jar放到集群上去执行
我之所以没这么做是因为之前我是可以的,并且我找到了我的另一个测试程序也是可以成功的,另一个重要的原因是太懒了
针对这种类型的错误原因这里给出一种可靠的解决方案,但并不保证所有这种NullPointerException都可以这样解决。
先说结果:错误原因就是我们自己定义的MapReduce类型有误,如果有其他原因欢迎大家留言
这里分享一下我自己的解决方法。
补充一下我的环境
集群都是cdh5.3.0 对应的hadoop集群是2.5.0
win7 64、Myeclipse10.7、Maven-3.05
在远程进行测试的时候发现一个MapReduce程序无法通过,出现了NullPointerException错误,少量错误信息如下
java.lang.Exception: java.lang.NullPointerException
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:522) 这里提供两张截图,是我在测试过程中发现的
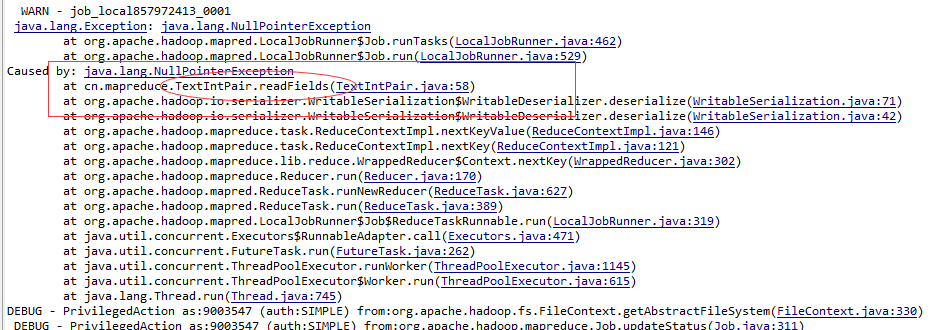
对应类的该方法代码如下
public void readFields(DataInput in) throws IOException {
this.joinKey.readFields(in);
this.flag.readFields(in);
this.values.readFields(in);
//看方法内的赋值和下面注释的赋值,有没有感觉怪怪的
/*
* joinKey=new Text(in.readUTF());
* flag=new Text(in.readUTF());
* values=new Text(in.readUTF());
*/
} 再来看另一张图
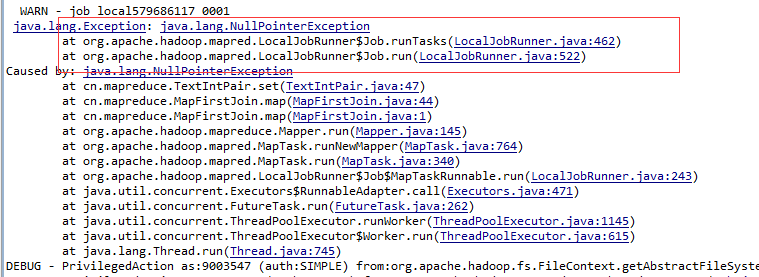
对应的代码如下
public void set(String joinKey, String flag, String values) {
this.joinKey.set(joinKey);
this.flag.set(flag);
this.values.set(values);
}
/* this.joinKey = new Text(joinKey);
this.flag = new Text(flag);
this.values = new Text(values);*/ 这是我在解决问题之后尝试的错误还原,对这些参数的赋值是不能使用set方法的,当然了有人细心的小伙伴会发现在hadoop的1.x大家都是(至少是可以)这样干的,所以我也不知道为什么版本2.x就不行了,毕竟看源码还是好吃力的。
解释一下我在类的变量定义为Text是因为Text类型有个set方法,我可以直接set而不用使用等于号并且在map端我也可以直接将String类型set进去,我以为会省下一些步骤。
至于解决方法,那就是在自定义的writable类型里不要用类似的已有的Writable类型的set方法进行赋值,我这里的解决方式就是将上面代码中注释的部分覆盖掉方法内的未注释的就可以了
我感觉这种错误可能只有刚入门的人才会犯,面对大众的东西你在网上找不到答案的时候,唯一的解释就是i的错误太低级了,低级到没人犯…让我哭一会儿…
所以在MR编程的时候还是很有必要区分版本的,不能完全跟着网上的1.x版本例子进行,另外我建议在没有很特殊的要求情况下,自定义类型的时候还是老老实实的定义为基本类型。
2015年5月21日16:31:56 补充
这种情况应该就是网上大家说的没办法远程进行开发需要打包成jar到集群上了
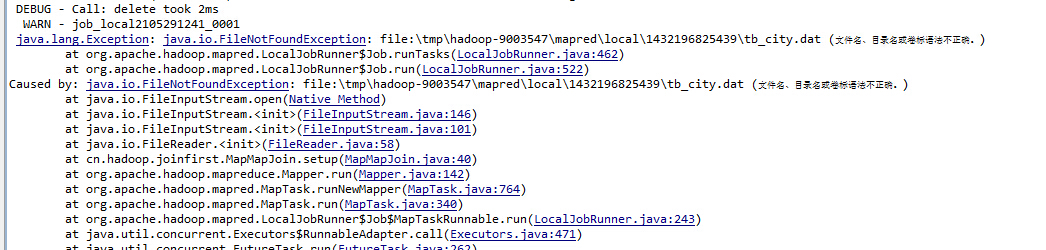
这个看路径就是有问题的,大概如果提供一个绝对路径可能会得到解决















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









