









交通标志
数据预处理
这里下载数据集。
值得注意的是,原始数据集的图像格式为PPM格式,这是一种比较老的图片保存格式,为了解决这个问题,我用opencv重新将这些图片转换为PNG格式,这样子我们就可以很直观的看到数据图片了。
转换脚本
## translate ppm image to png image
import cv2
import os
ORIGINAL_TRAIN_PATH = '../BelgiumTSC_Training/Training'
ORIGINAL_TEST_PATH = '../BelgiumTSC_Testing/Testing'
for train_class in os.listdir(ORIGINAL_TRAIN_PATH):
if not os.path.isdir('../traffic-sign/train/'+train_class):
os.mkdir('../traffic-sign/train/'+train_class)
for pic in os.listdir(ORIGINAL_TRAIN_PATH + '/'+ train_class):
if not (pic.split('.')[1] == 'ppm'):
continue
im = cv2.imread(ORIGINAL_TRAIN_PATH + '/' +train_class+'/'+ pic)
name = pic.split('.')[0]
new_name = name+'.png'
print (new_name)
cv2.imwrite('../traffic-sign/train/' + train_class + '/'+ new_name,im)
for test_class in os.listdir(ORIGINAL_TEST_PATH):
if not os.path.isdir('../traffic-sign/test/'+test_class):
os.mkdir('../traffic-sign/test/'+test_class)
for pic in os.listdir(ORIGINAL_TEST_PATH + '/'+ test_class):
if not (pic.split('.')[1] == 'ppm'):
continue
im = cv2.imread(ORIGINAL_TEST_PATH + '/' +test_class+'/'+ pic)
name = pic.split('.')[0]
new_name = name+'.png'
print (new_name)
cv2.imwrite('../traffic-sign/test/' + test_class + '/'+ new_name,im)
搭建CNN模型
用深度学习做图片分类选的网络肯定是卷积神经网络,但是现在CNN的种类很多,哪一个会在我们这个分类任务表现很好呢?在试验之前,没有人会知道,一般而言,先选一个最简单又最经典的网络跑一下看看分类效果是最明智的选择,那么Lenet肯定是最符合以上要求的,实现简单,又很经典
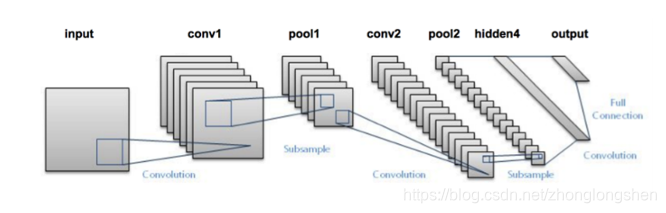
# import the necessary packages
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras import backend as K
class LeNet:
@staticmethod
def build(width, height, depth, classes):
# initialize the model
model = Sequential()
inputShape = (height, width, depth)
# if we are using "channels last", update the input shape
if K.image_data_format() == "channels_first": #for tensorflow
inputShape = (depth, height, width)
# first set of CONV => RELU => POOL layers
model.add(Conv2D(20, (5, 5),padding="same",input_shape=inputShape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
#second set of CONV => RELU => POOL layers
model.add(Conv2D(50, (5, 5), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(500))
model.add(Activation("relu"))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
# return the constructed network architecture
return model
其中conv2d表示执行卷积,maxpooling2d表示执行最大池化,Activation表示特定的激活函数类型,Flatten层用来将输入“压平”,用于卷积层到全连接层的过渡,Dense表示全连接层(500个神经元)。
参数解析器和一些参数的初始化
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import img_to_array
from keras.utils import to_categorical
from imutils import paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import cv2
import os
import sys
sys.path.append('..')
from net.lenet import LeNet
def args_parse():
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-dtest", "--dataset_test", required=True,
help="path to input dataset_test")
ap.add_argument("-dtrain", "--dataset_train", required=True,
help="path to input dataset_train")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
return args
我们还需要为训练设置一些参数,比如训练的epoches,batch_szie等。这些参数不是随便设的,比如batch_size的数值取决于你电脑内存的大小,内存越大,batch_size就可以设为大一点。又比如norm_size(图片归一化尺寸)是根据你得到的数据集,经过分析后得出的,因为我们这个数据集大多数图片的尺度都在这个范围内,所以我觉得32这个尺寸应该比较合适,但是不是最合适呢?那还是要通过实验才知道的,也许64的效果更好呢?
# initialize the number of epochs to train for, initial learning rate,
# and batch size
EPOCHS = 35
INIT_LR = 1e-3
BS = 32
CLASS_NUM = 62
norm_size = 32
载入数据
def load_data(path):
print("[INFO] loading images...")
data = []
labels = []
# grab the image paths and randomly shuffle them
imagePaths = sorted(list(paths.list_images(path)))
random.seed(42)
random.shuffle(imagePaths)
# loop over the input images
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (norm_size, norm_size))
image = img_to_array(image)
data.append(image)
# extract the class label from the image path and update the
# labels list
label = int(imagePath.split(os.path.sep)[-2])
labels.append(label)
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
# convert the labels from integers to vectors
labels = to_categorical(labels, num_classes=CLASS_NUM)
return data,labels
训练
def train(aug,trainX,trainY,testX,testY,args):
# initialize the model
print("[INFO] compiling model...")
model = LeNet.build(width=norm_size, height=norm_size, depth=3, classes=CLASS_NUM)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit_generator(aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS, verbose=1)
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"])
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
N = EPOCHS
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on traffic-sign classifier")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(args["plot"])
在这里我们使用了Adam优化器,由于这个任务是一个多分类问题,可以使用类别交叉熵(categorical_crossentropy)。但如果执行的分类任务仅有两类,那损失函数应更换为二进制交叉熵损失函数(binary cross-entropy)
主函数
#python train.py --dataset_train ../../traffic-sign/train --dataset_test ../../traffic-sign/test --model traffic_sign.model
if __name__=='__main__':
args = args_parse()
train_file_path = args["dataset_train"]
test_file_path = args["dataset_test"]
trainX,trainY = load_data(train_file_path)
testX,testY = load_data(test_file_path)
# construct the image generator for data augmentation
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,
height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
horizontal_flip=True, fill_mode="nearest")
train(aug,trainX,trainY,testX,testY,args)
在正式训练之前我们还使用了数据增广技术来对我们的小数据集进行数据增强(对数据图像进行随机旋转,移动,翻转,剪切等),以增强模型的泛化能力。
训练代码已经写好了,接下来开始训练(图片归一化尺寸为32,batch_size为32,epoches为35)。
python train.py --dataset_train ../../traffic-sign/train --dataset_test ../../traffic-sign/test --model traffic_sign.model
预测
# import the necessary packages
from keras.preprocessing.image import img_to_array
from keras.models import load_model
import numpy as np
import argparse
import imutils
import cv2
norm_size = 32
def args_parse():
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
ap.add_argument("-s", "--show", action="store_true",
help="show predict image",default=False)
args = vars(ap.parse_args())
return args
def predict(args):
# load the trained convolutional neural network
print("[INFO] loading network...")
model = load_model(args["model"])
#load the image
image = cv2.imread(args["image"])
orig = image.copy()
# pre-process the image for classification
image = cv2.resize(image, (norm_size, norm_size))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
# classify the input image
result = model.predict(image)[0]
#print (result.shape)
proba = np.max(result)
label = str(np.where(result==proba)[0])
label = "{}: {:.2f}%".format(label, proba * 100)
print(label)
if args['show']:
# draw the label on the image
output = imutils.resize(orig, width=400)
cv2.putText(output, label, (10, 25),cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 255, 0), 2)
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
#python predict.py --model traffic_sign.model -i ../2.png -s
if __name__ == '__main__':
args = args_parse()
predict(args)
单张图片的预测:
python predict.py --model traffic_sign.model -i ../2.png -s














 3109
3109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









