






一:算法目标
annoy 算法的目标是建立一个数据结构能够在较短的时间内找到任何查询点的最近点,在精度允许的条件下通过牺牲准确率来换取比暴力搜索要快的多的搜索速度。
二:算法流程
1:建立索引
Annoy的目标是建立一个数据结构,使得查询一个点的最近邻点的时间复杂度是次线性。Annoy 通过建立一个二叉树来使得每个点查找时间复杂度是O(log n)。 看下面这个图,随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点。这两个聚类中心点之间连一条线段(灰色短线),建立一条垂直于这条灰线,并且通过灰线中心点的线(黑色粗线)。这条黑色粗线把数据空间分成两部分。在多维空间的话,这条黑色粗线可以看成等距垂直超平面。
 |  |
接下里在超平面分割后的字空间内按照同样的方法继续确定超平面分割字空间,通过这样的方法我们可以将子空间的从属关系用二叉树来表示:
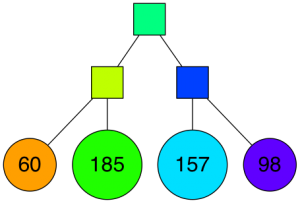 |
然后再继续分割,继续重复上述步骤,直到子节点包含的数据点数不超过 K 个,这里我们取 K = 10。
 |
通过多次递归迭代划分的话,最终原始数据会形成类似下面这样一个二叉树结构。二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息。Annoy建立这样的二叉树结构是希望满足这样的一个假设: 相似的数据节点应该在二叉树上位置更接近,一个分割超平面不应该把相似的数据节点分割二叉树的不同分支上。对应的二叉树结构如下所示:
 |
2 查询过程
通过上述步骤,我们建立了二叉树的结构用于表示上述点分布空间,每个节点都表示一个子空间,在点分布空间中接近的子空间在二叉树结构中表现为位置靠近的节点。这里有一个假设,如果两个点在空间中彼此靠近,任何超平面都不可能将他们分开。如果要搜索空间中的任意一个点,我们都可以从根结点遍历二叉树。假设我们要找下图中红色 X 表示的点的临近点:查找的过程就是不断看他在分割超平面的哪一边。从二叉树索引结构来看,就是从根节点不停的往叶子节点遍历的过程。通过对二叉树每个中间节点(分割超平面相关信息)和查询数据节点进行相关计算来确定二叉树遍历过程是往这个中间节点左孩子节点走还是右孩子节点走。通过以上方式完成查询过程。
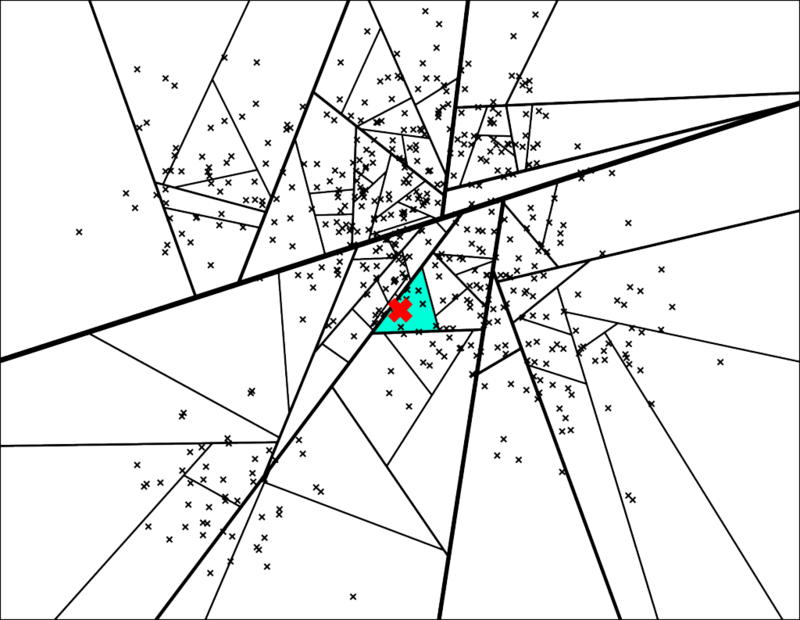 |  |
3 存在问题
但是上述描述存在两个问题:
(1)查询过程最终落到叶子节点的数据节点数小于 我们需要的Top N相似邻居节点数目怎么办?
(2)两个相近的数据节点划分到二叉树不同分支上怎么办?
4 解决方法
(1)如果分割超平面的两边都很相似,那可以两边都遍历;下面是是个示意图:
 |
(2) 建立多棵二叉树树,构成一个森林,每个树建立机制都如上面所述那样。多棵树示意图如下所示:
 |
(3) 采用优先队列机制:采用一个优先队列来遍历二叉树,从根节点往下的路径,根据查询节点与当前分割超平面距离(margin)进行排序。
5:合并节点
每棵树都返回一堆近邻点后,如何得到最终的Top N相似集合呢?首先所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离, 最终根据距离值从近距离到远距离排序, 返回Top N近邻节点集合。
 |
 |
 |
三:代码实战
from annoy import AnnoyIndex
#坑坑坑:annoy必须为整数索引,所以要建立item与整数的映射
nItem = {} #建立 N->item 字典映射,这样能够最后从查询到的近似向量id值查询到映射的词
itemN = {} #建立 item->N 映射,便于低频item映射
#将所有item_vector通过Annoy算法建立索引树
vf = 32 #所建立索引的向量长度
vt = AnnoyIndex(vf, metric='angular') #采用余弦距离计算
count = 0
item_vector = {}
#加载模型向量 page_event_model为训练完的word2vec模型文件
with open(localpath + 'page_event_model') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=' ')
for line in csv_reader:
#if len(line) != 33: continue
try:
count += 1
item_uuid = line[0]
line = line[1:]
item_vec = [float(vec) for vec in line] # annoy元素只能是float类型数据
vt.add_item(count, item_vec) # 将高频item加载到annoy索引树中
calculate_N.add(count)
nItem.setdefault(count, item_uuid) # 建立count->item的索引,便于后期查找恢复
itemN.setdefault(item_uuid, count) # 建立item->count的索引,便于映射低频item
item_vector.setdefault(item_uuid, item_vec) #存储每个item 和 向量
except Exception as e:
#print (traceback.print_exc())
continue
vt.build(100) #树的个数
vt.save(localpath + 'annoy_item_vector_index') #保存向量索引树
#读取模型文件,进行计算最近距离数据
u = AnnoyIndex(vf, metric='angular')
u.load(localpath + 'annoy_item_vector_index')
ruku = []
#生成入库trigger
for number in calculate_N:
try:
v = []
item = nItem[number]
ctype_base = item.split('_')[0]
result = u.get_nns_by_item(number, 50, include_distances=True) #基于annoy获得最近的50个向量item,result为一个list,list内元素为item的索引整数
for index, score in zip(result[0], result[1]):
item_sim = nItem[index] #基于索引得到item
score = 0.5 * (abs(1 - score)) + 0.5
参考文献:

















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









