






1:ROC—AUC曲线
AUC:一个正例,一个负例,预测为正的概率值比预测为负的概率值还要大的可能性。
所以根据定义:我们最直观的有两种计算AUC的方法
1:绘制ROC曲线,ROC曲线下面的面积就是AUC的值(积分)
2:假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有m*n个样本对,计数,正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,累加计数,然后除以(m*n)就是AUC的值
1.1:AUC原理
1、roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(负样本判断错的)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)2
2、针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
列联表如下,1代表正类,0代表负类
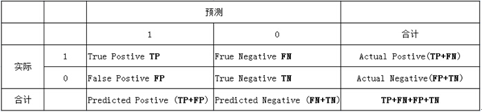 |
由上表可得出横,纵轴的计算公式:
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。Sensitivity
(2)负正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。1-Specificity
(3)真负类率(True Negative Rate)TNR: TN/(FP+TN),代表分类器预测的负类中实际负实例占所有负实例的比例,TNR=1-FPR。Specificity
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
形状:阶梯形
1.2:代码实现AUC
#author: wepon
def naive_auc(labels,preds):
"""
最简单粗暴的方法
先排序,然后统计有多少正负样本对满足:正样本预测值>负样本预测值, 再除以总的正负样本对个数
复杂度 O(NlogN), N为样本数
"""
n_pos = sum(labels)
n_neg = len(labels) - n_pos
total_pair = n_pos * n_neg
labels_preds = zip(labels,preds)
labels_preds = sorted(labels_preds,key=lambda x:x[1])
accumulated_neg = 0
satisfied_pair = 0
for i in range(len(labels_preds)):
if labels_preds[i][0] == 1:
satisfied_pair += accumulated_neg
else:
accumulated_neg += 1
return satisfied_pair / float(total_pair)
2:GAUC
2.1:背景
很多情况我们都是把auc当成最常用的一个评价指标,而auc反映整体样本间的排序能力,但是有时候auc这个指标可能并不能完全说明问题,有可能auc并不能真正反映模型的好坏,以CTR预估算法(推荐算法一般把这个作为一个很重要的指标)为例,把用户点击的样本当作正样本,没有点击的样本当作负样本,把这个任务当成一个二分类进行处理,最后模型输出的是样本是否被点击的概率。
举个很简单的例子,假如有两个用户,分别是甲和乙,一共有5个样本,其中+表示正样本,-表示负样本,我们把5个样本按照模型A预测的score从小到大排序,得到 甲-,甲+,乙-,甲+,乙+. 那么实际的auc应该是 (1+2+2)/(32)=0.833, 那假如有另一个模型B,把这5个样本根据score从小到大排序后,得到 甲-,甲+,甲+,乙-,乙+, 那么该模型预测的auc是(1+1+2)/(32)=0.667.
那么根据auc的表现来看,模型A的表现优于模型B,但是从实际情况来看,对于用户甲,模型B把其所有的负样本的打分都比正样本低,故,对于用户甲,模型B的auc是1, 同理对于用户乙,模型B的auc也应该是1,同样,对于用户甲和乙,模型A的auc也是1,所以从实际情况来看,模型B的效果和模型A应该是一样好的,这和实际的auc的结果矛盾。
可能auc这个指标失真了,因为推荐系统的排序是个性化的,不同用户的排序结果不太好比较,这可能导致全局auc并不能反映真实情况。
2.2:公式
因为auc反映的是整体样本间的一个排序能力,而在计算广告领域,我们实际要衡量的是不同用户对不同广告之间的排序能力, 实际更关注的是同一个用户对不同广告间的排序能力,为此,参考了阿里妈妈团队之前有使用的group auc的评价指标 group auc实际是计算每个用户的auc,然后加权平均,最后得到group auc,这样就能减少不同用户间的排序结果不太好比较这一影响。group auc具体公式如下:
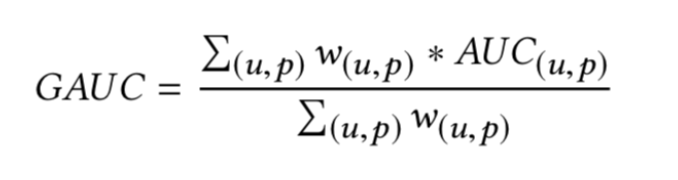 |
2.3:代码实现
import numpy as np
from sklearn.metrics import roc_auc_score
from collections import defaultdict
from tkinter import _flatten
import pandas as pd
def cal_group_auc(labels, preds, user_id_list):
"""Calculate group auc"""
print('*' * 50)
if len(user_id_list) != len(labels):
raise ValueError(
"impression id num should equal to the sample num," \
"impression id num is {0}".format(len(user_id_list)))
group_score = defaultdict(lambda: [])
group_truth = defaultdict(lambda: [])
for idx, truth in enumerate(labels):
user_id = user_id_list[idx]
score = preds[idx]
truth = labels[idx]
group_score[user_id].append(score)
group_truth[user_id].append(truth)
group_flag = defaultdict(lambda: False)
for user_id in set(user_id_list):
truths = group_truth[user_id]
flag = False
for i in range(len(truths) - 1):
if truths[i] != truths[i + 1]:
flag = True
break
group_flag[user_id] = flag
impression_total = 0
total_auc = 0
#
for user_id in group_flag:
if group_flag[user_id]:
auc = roc_auc_score(np.asarray(group_truth[user_id]), np.asarray(group_score[user_id]))
total_auc += auc * len(group_truth[user_id])
impression_total += len(group_truth[user_id])
group_auc = float(total_auc) / impression_total
group_auc = round(group_auc, 4)
return group_auc
if __name__=='__main__':
a=[1,2,1,2]
b=[0.6,0.7,0,0]
c=[1,1,0,0]
d=np.array([[1],[1],[0],[0]])
print(d)
print(list(_flatten(d.tolist())))
print(cal_group_auc(list(_flatten(d.tolist())),b,a))















 2602
2602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









