






Hadoop集群搭建-详细安装配置
Hadoop是一个分布式系统,可以通过在多台计算机上搭建Hadoop集群来实现更高效的数据处理和存储。
- 准备机器
在每台计算机上安装Java,并设置JAVA_HOME环境变量。确保每台计算机都有相同的版本和配置。
| 机器名称 | 地址 | 描述 |
| hadoop130 | 192.168.64.130 | |
| hadoop131 | 192.168.64.131 | |
| hadoop132 | 192.168.64.132 |
关闭防火前执行如下命令
systemctl stop firewalld
systemctl disable firewalld.service
集群部署规划
| hadoop130 | hadoop131 | hadoop132 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
- 准备jar包
hadoop-3.3.6.tar.gz 上传
- 解压配置
1》解压
tar -zxvf hadoop-3.3.6.tar.gz
2》移动
mv hadoop-3.3.6 /opt/module
3》修改配置文件
配置文件在 etc/hadoop下

core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件
• workers : 配置从节点( DataNode )有哪些
• hadoop-env.sh : 配置 Hadoop 的相关环境变量
• core-site.xml : Hadoop 核心配置文件
• hdfs-site.xml : HDFS 核心配置文件
1》配置Hadoop环境
vi /etc/profile.d/my_env.sh
添加以下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
更新一下profile文件,让环境生效
source /etc/profile
2》修改四个配置文件
- core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--ameNode address -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop130:8020</value>
</property>
<!--adoop data path -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.3.6/data</value>
</property>
<!--HDFS net page user -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
- hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web visit address-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop130:9870</value>
</property>
<!-- 2nn web visit address -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop132:9868</value>
</property>
</configuration>
- yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--MR:shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--resourceManager address-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop131</value>
</property>
<!--nvironment -->
<property>
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--MapReduce run on Yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4》hadoop-env.sh
添加以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_381
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
5》配置workers
vi /opt/module/hadoop-3.3.6/etc/hadoop/workers
#添加以下内容,该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
hadoop130
hadoop131
hadoop132
- 运行测试
1》SSH无密登录配置
vi /etc/hosts 文件,添加域名与IP的映射
192.168.64.130 hadoop130
192.168.64.131 hadoop131
192.168.64.132 hadoop132
密码配置
位置: /root/.ssh
生成:ssh-keygen -t rsa
拷贝:ssh-copy-id hadoop130
ssh-copy-id hadoop131
ssh-copy-id hadoop132
测试:ssh hadoop131
exit
ssh hadoop132
exit
2》把/opt/module/hadoop-3.3.6 拷贝到另外两台机器上
cd /opt/module
scp -r hadoop-3.3.6 hadoop131:/opt/module
scp -r hadoop-3.3.6 hadoop132:/opt/module
3》启动集群
3.1如果集群是第一次启动,需要在hadoop130节点格式化NameNode
hdfs namenode –format
出现:
2023-07-26 14:39:35,389 INFO common.Storage: Storage directory /opt/module/hadoop-3.3.6/data/dfs/name has been successfully formatted.
2023-07-26 14:39:35,421 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/module/hadoop-3.3.6/data/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2023-07-26 14:39:35,516 INFO namenode.FSImageFormatProtobuf: Image file /opt/module/hadoop-3.3.6/data/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 399 bytes saved in 0 seconds .
2023-07-26 14:39:35,535 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2023-07-26 14:39:35,551 INFO namenode.FSNamesystem: Stopping services started for active state
2023-07-26 14:39:35,551 INFO namenode.FSNamesystem: Stopping services started for standby state
2023-07-26 14:39:35,557 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2023-07-26 14:39:35,558 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop130/192.168.64.130
************************************************************/
3.2启动HDFS
start-dfs.sh
出现
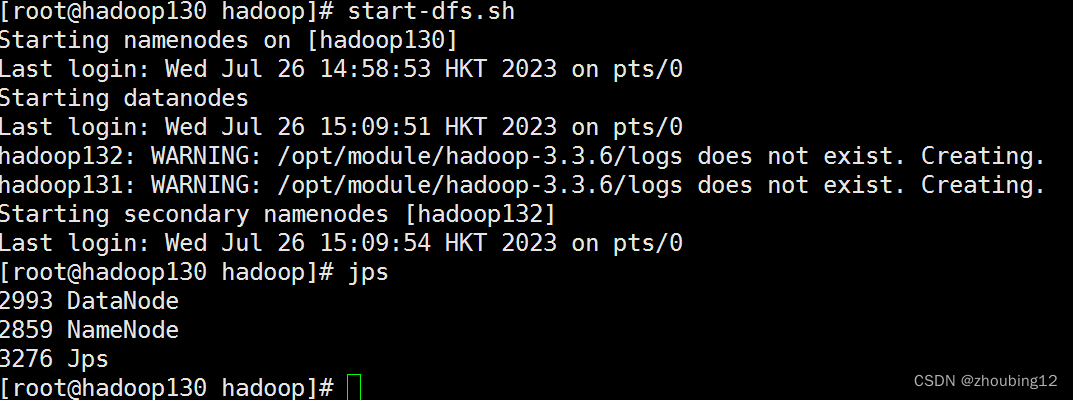
Jps检查
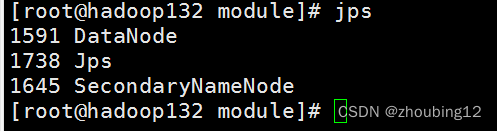
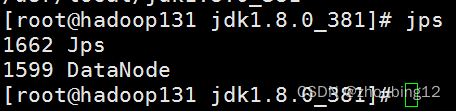
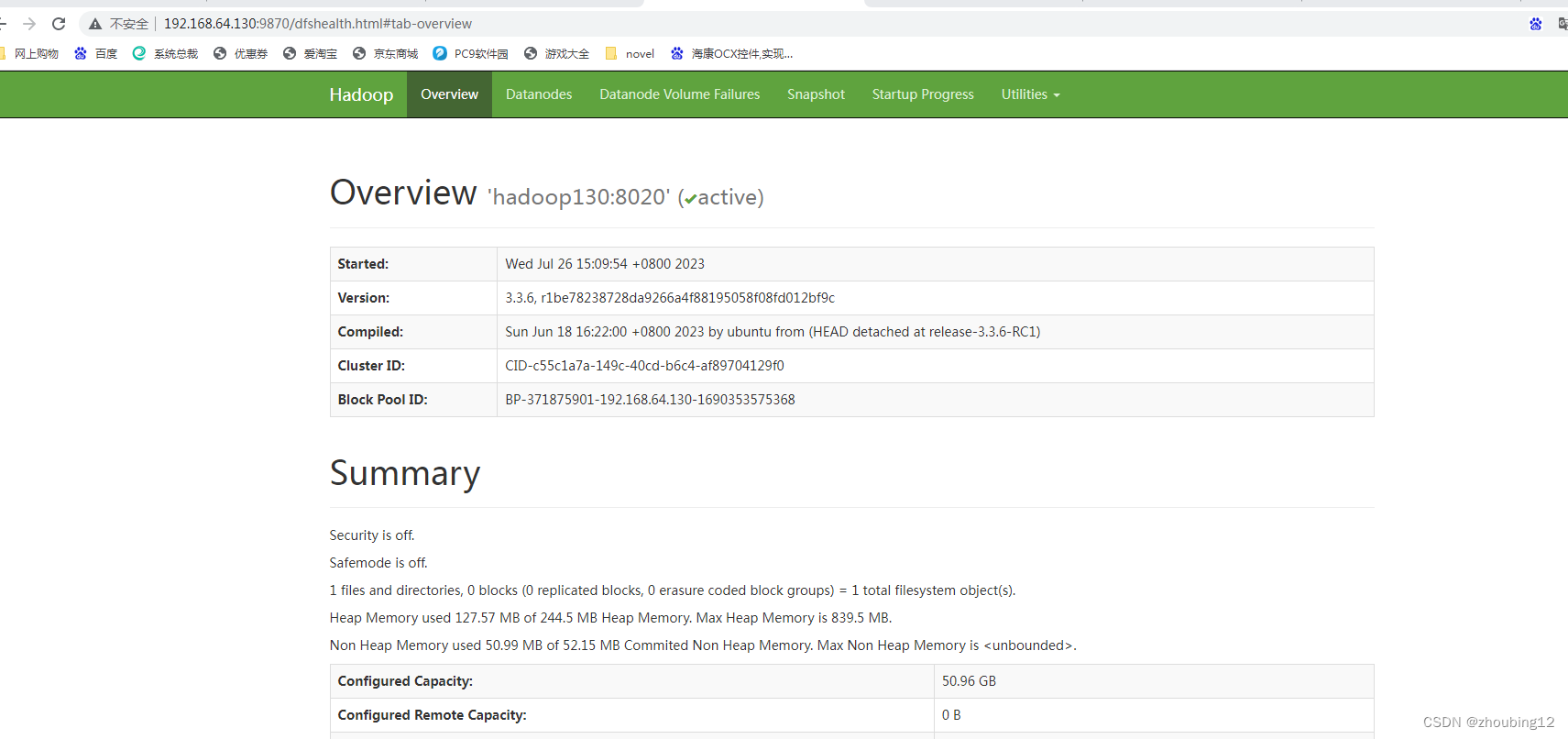
浏览器检查
hadoop130:9870或192.168.64.130:9870
3.3 在Hadoop131上启动yarn
start-yarn.sh
jps检查
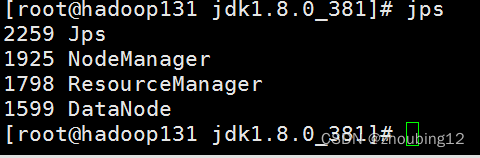
浏览器中输入:http://hadoop131:8088
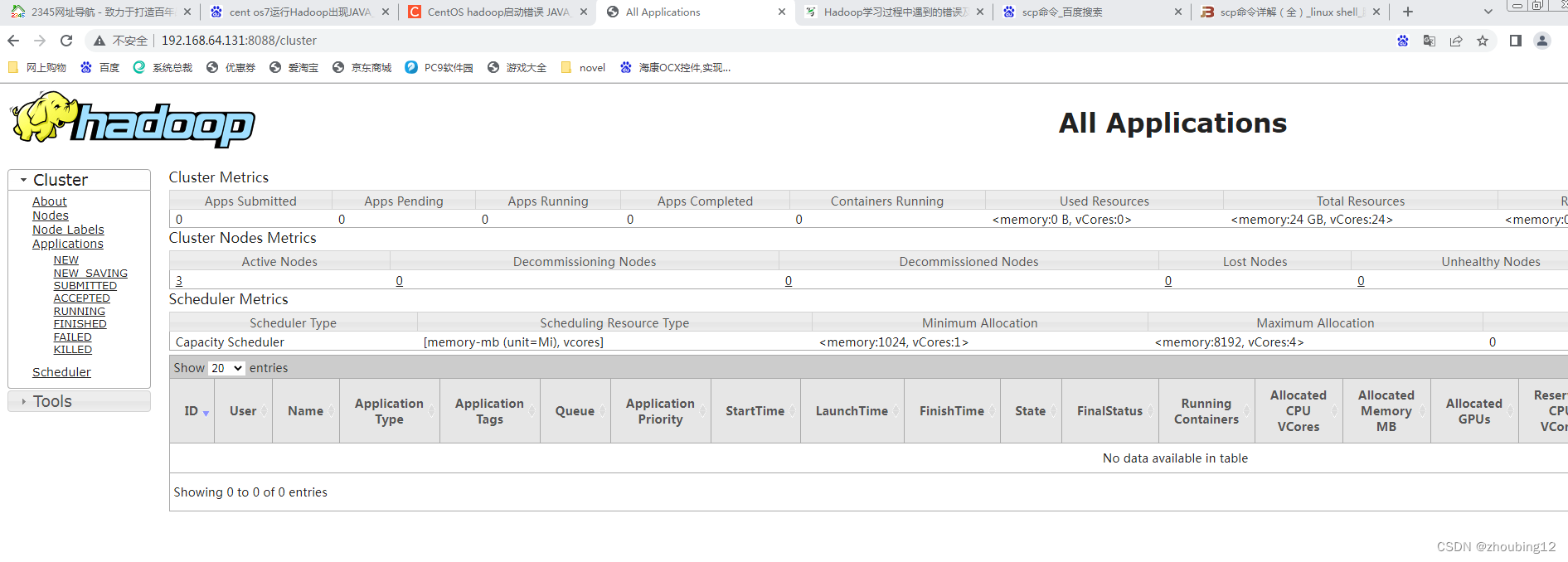
3.4 测试
3.4.1 创建文件目录
创建目录
hadoop fs -mkdir /wcinput
上传文件
hadoop fs -put word.txt /wcinput
在浏览器上输入hadoop130:9870
检查文件OK
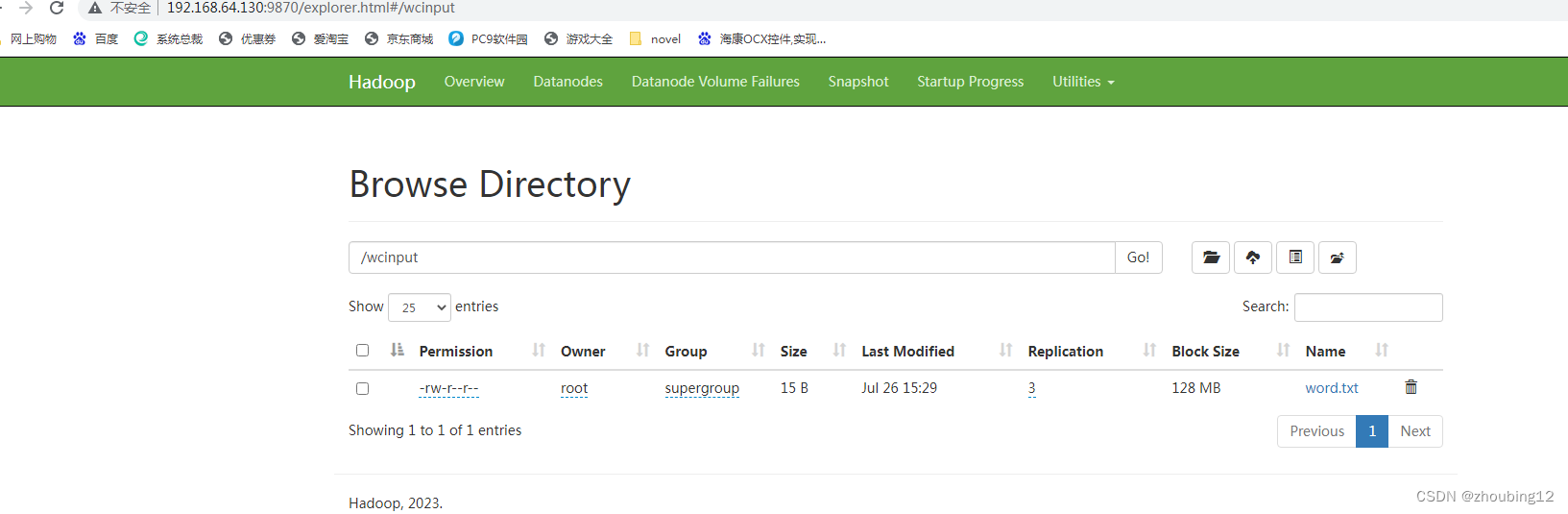
3.4.2 WordCount测试
hadoop jar \
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar \
wordcount \
/wcinput/word2.txt \
/wcinput/outtxt2/
执行需要一定时间。。。
结果显示
查看结果
显示结果文件
hadoop fs -ls /wcinput/outtxt2

显示结果内容
hadoop fs -cat /wcinput/outtxt2/part-r-00000

运行自己打包程序(读取hdfs下/wcinput/word2.txt文件内容)
hadoop jar ./hadoopbase.jar com.bigdata.hadoopbase.test.ReadTxt
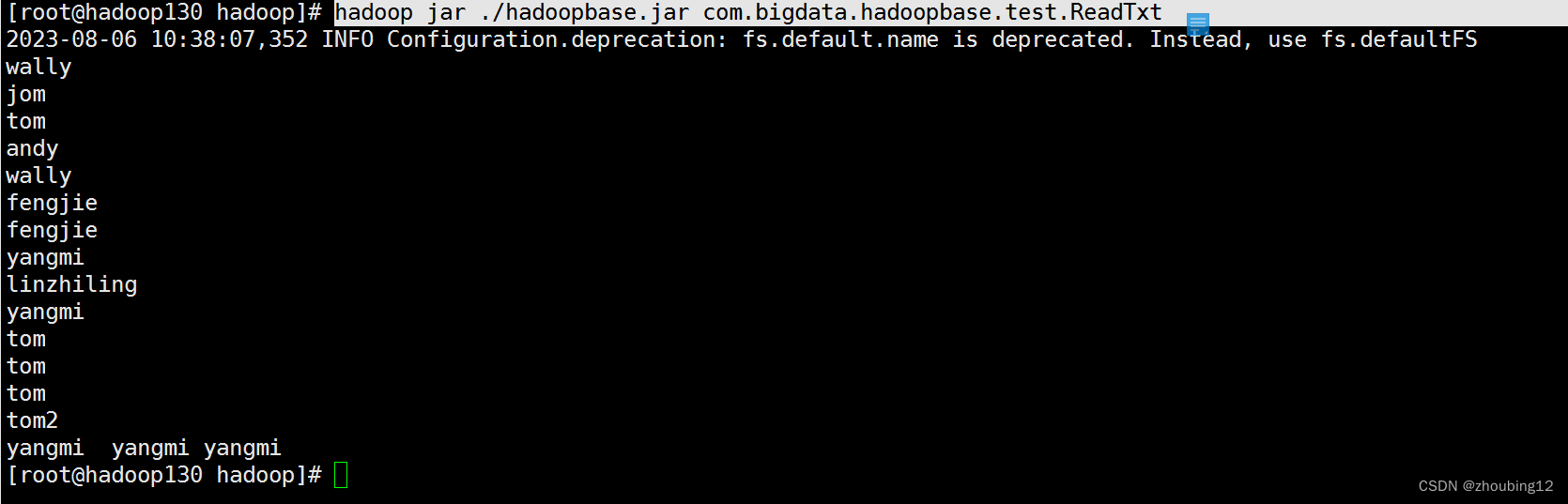
3.5 启动停止命名
1》整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
2》整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
3》分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
4》启动/停止YARN(在Hadoop131上运行)
yarn --daemon start/stop resourcemanager/nodemanager
4》历史服务
4.1》修改 mapred-site.xml
<property>
<name>mapreduce.framework.name></name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop130:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop130:19888</value>
</property>
分发到hadoop131和hadoop132 上
4.2》启动历史服务
在hadoop130上启动
mapred --daemon start historyserver
4.3》查看历史服务
jps
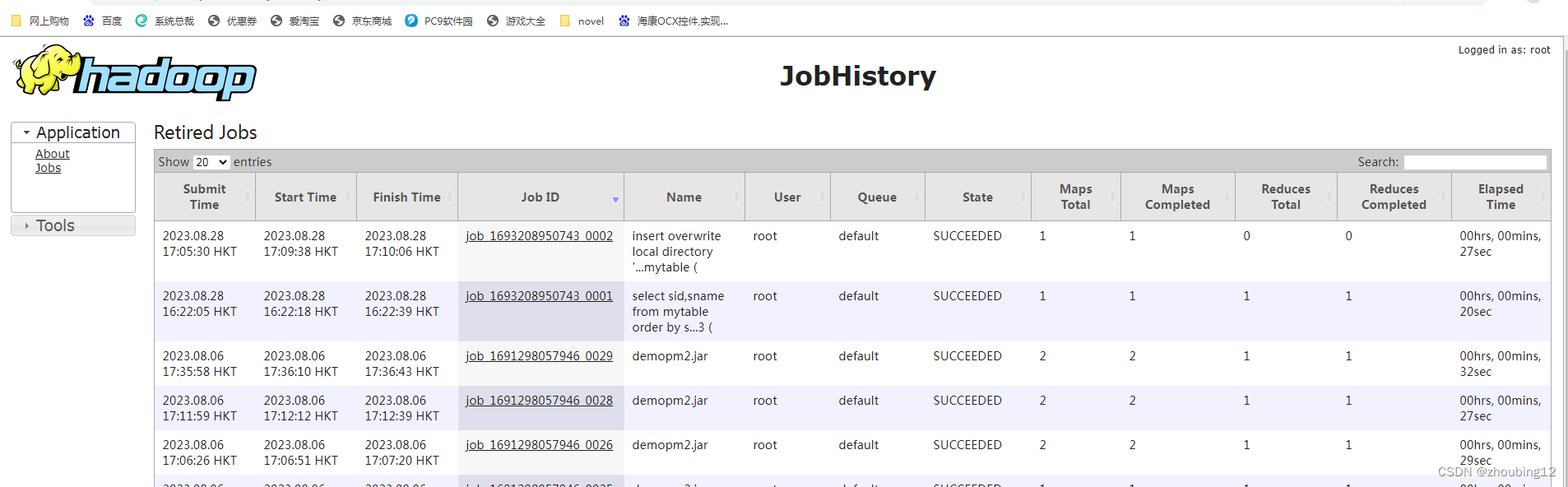
查看JobHistory
http://hadoop130:19888/jobhistory
- 说明
端口说明
默认端口更改
最近配置Hadoop3.x集群的时候发现了一些端口变动,导致web访问UI界面失败,查阅资料共享一下。
Namenode 端口:
2.x端口 3.x端口 name desc
50470 9871 dfs.namenode.https-address The namenode secure http server address and port.
50070 9870 dfs.namenode.http-address The address and the base port where the dfs namenode web ui will listen on.
8020 9820 fs.defaultFS 指定HDFS运行时nameNode地址
Secondary NN 端口:
2.x端口 3.x端口 name desc
50091 9869 dfs.namenode.secondary.https-address The secondary namenode HTTPS server address and port
50090 9868 dfs.namenode.secondary.http-address The secondary namenode HTTPS server address and port
Datanode 端口:
2.x端口 3.x端口 name desc
50020 9867 dfs.datanode.ipc.address The datanode ipc server address and port.
50010 9866 dfs.datanode.address The datanode server address and port for data transfer.
50475 9865 dfs.datanode.https.address The datanode secure http server address and port
50075 9864 dfs.datanode.http.address The datanode http server address and por
Yarn 端口
2.x端口 3.x端口 name desc
8088 yarn.resourcemanager.webapp.address http服务端口
hadoop jar命令解读
hadoop jar ./test/wordcount/wordcount.jar org.codetree.hadoop.v1.WordCount /test/chqz/input /test/chqz/output
各段的含义:
(1) hadoop:${HADOOP_HOME}/bin下的 shell脚本名。
(2) jar:hadoop脚本需要的 command参数。
(3) ./test/wordcount/wordcount.jar:要执行的jar包在 本地文件系统中的完整路径, 参递给RunJar类。
(4) org.codetree.hadoop.v1.WordCount:main方法所在的类, 参递给RunJar类。
(5) /test/chqz/input**:** 传递给WordCount类,作为 DFS文件系统的路径,指示输入数据来源。
(6) /test/chqz/output: 传递给WordCount类,作为 DFS文件系统的路径,指示输出数据路径。
Hadoop启停服务命令及说明
| 类属 | 命令脚本 | 说明 |
| All | sbin/start-all.sh | 启动所有的Hadoop守护进程,包括NameNode、DataNode、ResourceManager、NodeManager、Secondary NameNode |
| sbin/stop-all.sh | 停止所有的Hadoop守护进程,包括NameNode、DataNode、ResourceManager、NodeManager、Secondary NameNode | |
| HDFS | sbin/start-dfs.sh | 启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode |
| sbin/stop-dfs.sh | 停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode | |
| sbin/hadoop-daemons.sh start namenode | 单独启动NameNode守护进程 | |
| sbin/hadoop-daemons.sh stop namenode | 单独停止NameNode守护进程 | |
| sbin/hadoop-daemons.sh start datanode | 单独启动DataNode守护进程 | |
| sbin/hadoop-daemons.sh stop datanode | 单独停止DataNode守护进程 | |
| sbin/hadoop-daemons.sh start secondarynamenode | 单独启动SecondaryNameNode守护进程 | |
| sbin/hadoop-daemons.sh stop secondarynamenode | 单独停止SecondaryNameNode守护进程 | |
| yarn | sbin/start-yarn.sh | 启动ResourceManager、NodeManager |
| sbin/stop-yarn.sh | 停止ResourceManager、NodeManager | |
| sbin/yarn-daemon.sh start resourcemanager | 单独启动ResourceManager | |
| sbin/yarn-daemons.sh start nodemanager | 单独启动NodeManager | |
| sbin/yarn-daemon.sh stop resourcemanager | 单独停止ResourceManager | |
| sbin/yarn-daemons.sh stopnodemanager | 单独停止NodeManager | |
| 历史服务器 | sbin/mr-jobhistory-daemon.sh start historyserver | 手动启动jobhistory |
| sbin/mr-jobhistory-daemon.sh stop historyserver | 手动停止jobhistory |
关于hadoop jar命令
hadoop jar MinTemperature.jar MinTemperature /dir3in/temperature.txt /dir4/out
命令的含义:
hadoop:$HADOOP_HOME/bin 下的shell脚本名。
1. jar:hadoop脚本需要的command参数。
2. MinTemperature.jar:要执行的jar包在本地文件系统中的完整路径。
3. MinTemperature:main方法所在的类,全类名。
4. /dir3/in/temperature.txt:HDFS文件系统的路径,指示输入数据来源。
5. /dir4/out:HDFS文件系统的路径,指示输出数据路径。
特注: 1,2,3必须有
运行jar式例
一个输入文件
hadoop jar ./demopara.jar com.example.hadoop3Demo.test.WordCountDriverPara "hdfs:/wcinput/words.txt" "hdfs:/out90"
固定一个输入文件 外加一个输入文件
hadoop jar ./demopm.jar com.example.hadoop3Demo.test.WordCountDriverPara hdfs:/wcinput/words.txt hdfs:/out920
hdfs dfs -cat /out920/part-r-00000
多个输入文件(1个输入文件)
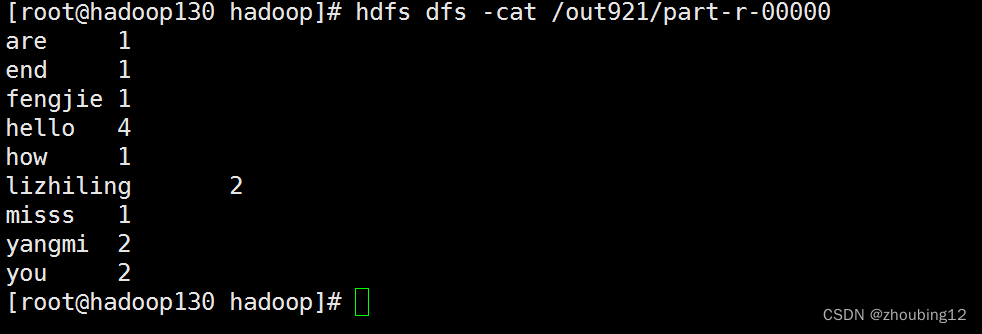
hadoop jar ./demopm2.jar com.example.hadoop3Demo.test.WordCountDriverPara hdfs:/wcinput/words.txt hdfs:/out921
hdfs dfs -cat /out921/part-r-00000
多个输入文件(2个输入文件 程序内固定一个,外部参数一个)
hadoop jar ./demopm2.jar com.example.hadoop3Demo.test.WordCountDriverPara hdfs:/wcinput/words.txt hdfs:/wcinput/words.txt hdfs:/out922
hdfs dfs -cat /out922/part-r-00000
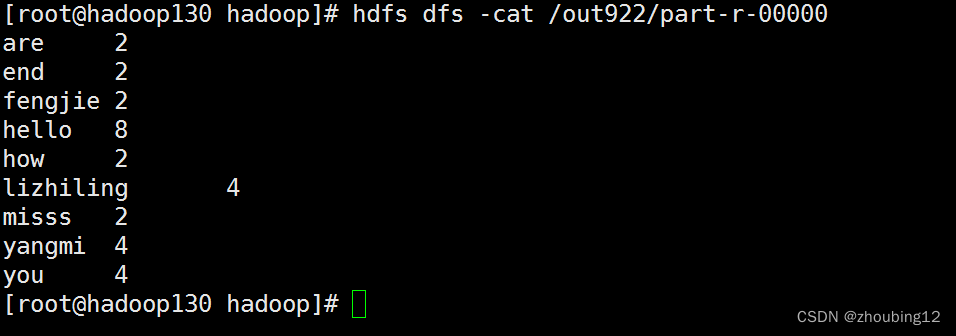
多个输入文件(2个输入文件 外部参数2个)
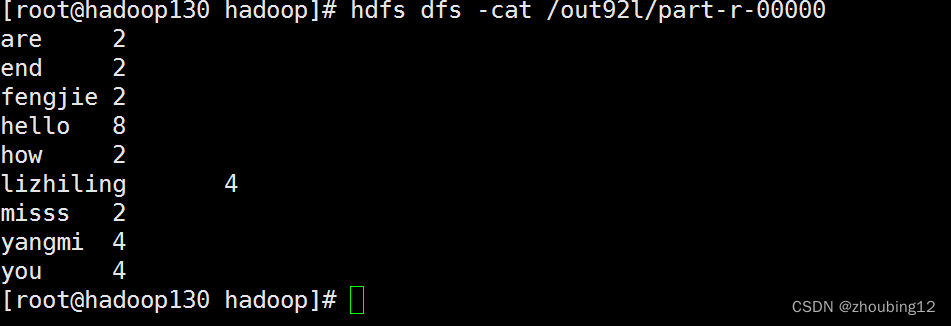
hadoop jar ./demopm2.jar com.example.hadoop3Demo.test.WordCountDriverPara hdfs:/wcinput/words.txt /wcinput/words.txt hdfs:/out92l
hdfs dfs -cat /out92l/part-r-00000















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









