






 本项目对绝地求生玩家比赛记录数据集进行探索性分析(EDA),基本无建模过程。介绍了环境配置、数据获取方式,对数据集中的文件属性进行了说明,处理了空值,构造了吃鸡列,还分析了不同模式吃鸡率、载具移动距离与吃鸡率等内容。
本项目对绝地求生玩家比赛记录数据集进行探索性分析(EDA),基本无建模过程。介绍了环境配置、数据获取方式,对数据集中的文件属性进行了说明,处理了空值,构造了吃鸡列,还分析了不同模式吃鸡率、载具移动距离与吃鸡率等内容。
PUBG Dataset EDA
简介
本项目对绝地求生玩家比赛记录数据集进行分析,主要为数据探索(EDA),基本无建模过程。使用的数据集来自Kaggle,下载地址给出。
环境配置
基于Python3,需要的第三方包在requirements.txt给出。
数据获取
根据上面的链接即可下载数据集,数据量较大,习惯NoteBook的可以直接在Kaggle Kernel上运行,具体操作见之前博客。
数据集下载解压后得到如下四个文件。

- erangel.png
- 绝地海岛艾伦格地图(便于Kaggle玩家热点图绘制)
- mirangel.jpg
- 热情沙漠米拉玛地图(便于Kaggle玩家热点图绘制)
- 雨林地图没有数据(em,,,我也是玩过的人)
- aggregate.zip
- 玩家比赛统计数据
- deaths.zip
- 玩家被击杀数据
- 本次分析会设计到上述的两类数据。(由于数据量大,原数据集数据量切分为多个部分,对两类数据只分析第一部分即agg_match_stats_0.csv和kill_match_stats_final_0.csv)
对数据集中的数据文件进行初步探索,显示大致文件分布内容如下。
数据探索分析(EDA)
csv文件属性列出如下。
- agg_match_stats_i.csv文件属性(按照csv文件表头顺序)
- date:对局时间
- game_size:游戏规模(队伍数量)
- match_id:对局id
- match_mode:对局模式(第一人称还是第三人称)
- party_size:组队模式(单人赛、双人赛、四人赛)
- player_assists:助攻次数
- player_dbno:击倒人数
- player_dist_ride:载具移动距离
- player_dist_walk:行走距离
- player_dmg:伤害数值
- player_kills:击杀人数
- player_name:玩家名称
- player_survive_time:玩家生存时间
- team_id:队伍id
- team_placement:队伍排名
- kill_match_stats_final_i.csv文件属性
- killed_by:死亡方式
- killer_name:击杀者名字
- killer_placement:击杀者排名
- killer_position_x:击杀者位置x坐标
- killer_position_y:击杀者位置y坐标
- map:地图
- match_id:比赛id
- time:存活时间
- victim_name:被击杀者名字
- victim_placement:被击杀者排名
- victim_position_x:被击杀者位置x坐标
- victim_position_y:被击杀者位置y坐标
简单进行数据展示如下。
- 共有13849287条记录。

- 共有13426348条记录。

空值
对空值记录查看,其中20249存在空值,均为玩家名称,不影响建模。
df_data_aggregate[df_data_aggregate.isnull().values == True].drop_duplicates()
df_data_deaths[df_data_deaths.isnull().values == True].drop_duplicates()
使用下述代码对空值记录删除。
df_data_aggregate.drop_duplicates(inplace=True)
df_data_deaths.drop_duplicates(inplace=True)
属性构造
补充吃鸡列,并显示击杀数与吃鸡概率的关系。
plt.figure(figsize=(20, 8))
plt.subplot(1, 2, 1)
# 剔除击杀数不合理的玩家
df_data_aggregate.loc[df_data_aggregate['player_kills'] < 50, ['player_kills', 'won']].groupby('player_kills')['won'].mean().plot()
plt.xlabel('kill number')
plt.ylabel("probability of No1")
plt.subplot(1, 2, 2)
df_data_aggregate.loc[df_data_aggregate['player_kills'] < 50, ['player_kills', 'won']].groupby('player_kills')['won'].mean().plot.bar()
plt.xlabel('kill number')
plt.ylabel("probability of No1")
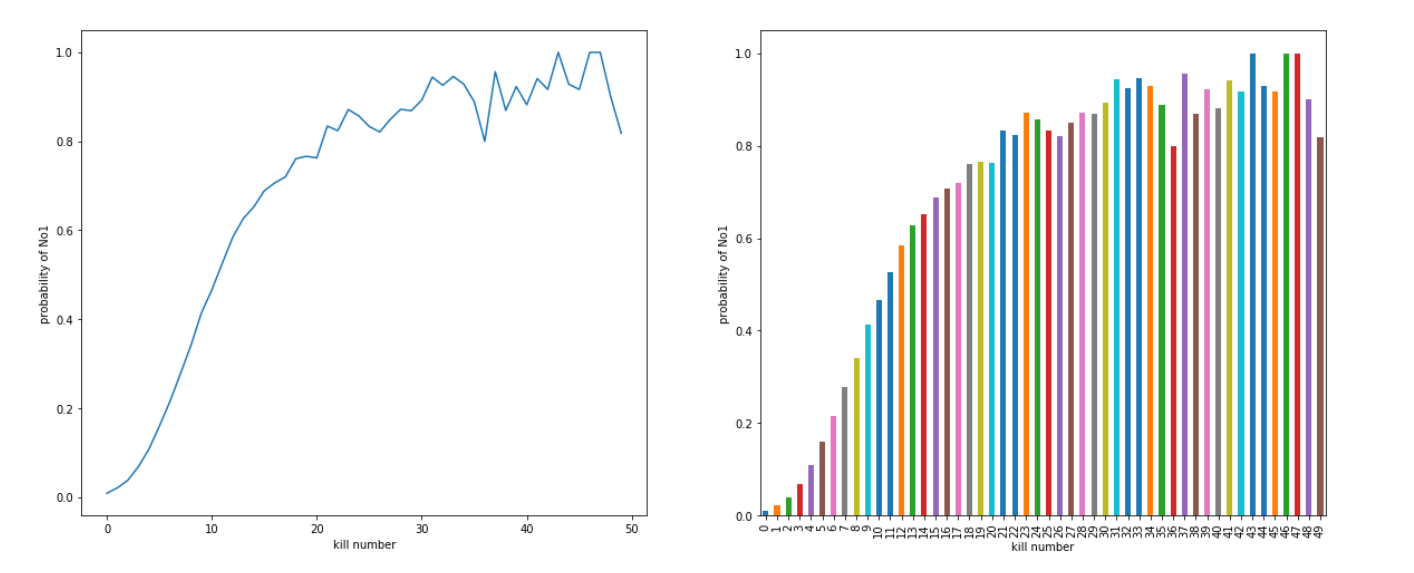
探索分析
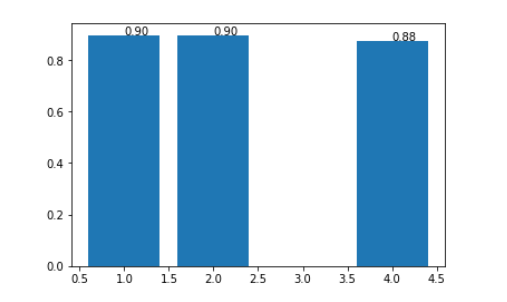
查看不同模式吃鸡率。各模式吃鸡率还是比较接近的,这说明这个游戏几种模式设计都是比较合理的。
v = df_data_aggregate.groupby('party_size')['player_kills'].mean()
plt.bar(v.index, v.values)
for x, y in zip(v.index, v.values):
plt.text(x, y, "{:.2f}".format(y))
plt.show()
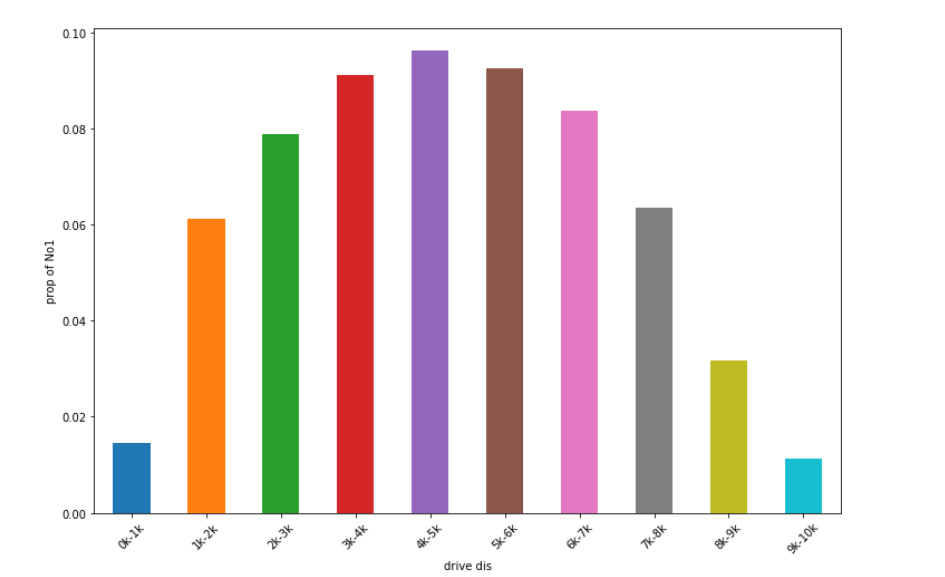
查看载具移动距离与吃鸡率。(嗯,不是在吃鸡,就是在吃鸡的路上。)
df_ride = df_data_aggregate.loc[df_data_aggregate['player_dist_ride']<20000, ['player_dist_ride', 'won']]
labels=["0k-1k", "1k-2k", "2k-3k", "3k-4k","4k-5k", "5k-6k", "6k-7k", "7k-8k", "8k-9k", "9k-10k"]
df_ride['drive'] = pd.cut(df_ride['player_dist_ride'], 10, labels=labels)
df_ride.groupby('drive').won.mean().plot.bar(rot=45, figsize=(12, 8))
plt.xlabel("drive dis")
plt.ylabel("prop of No1")
对玩家死亡数据集的初探。

落地成盒在哪里,统计存活时间段的玩家的死亡地点。


其他如最后毒圈缩在哪里,思路类似。
补充说明
EDA思路参考“Alfred数据室”,代码实现不同。具体数据集地址给出(20G),不可能上传,故Github只有背景图与NoteBook文件。具体代码见我的Github,欢迎star或者fork。


















 2886
2886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











