






1 Batch Norm, BN
1)介绍Batch normalization
在logistic回归中,我们已经知道将输入归一化有助于加速训练, 那么在神经网络中,我们不只需要将输入归一化,对隐藏层中activations同样需要归一化处理。一般,我们是对
Z
[
l
]
Z^{[l]}
Z[l]进行归一化。
Batch Norm的步骤:
对每一层的激活单元
z
[
l
]
(
i
)
z^{[l](i)}
z[l](i),在后面的书写中省略上标[l],先减去均值再除以标准偏差,为了使数值稳定,通常在分母加上
ϵ
\epsilon
ϵ以防止分母为0.因此有
现在,为了赋予各隐藏单元不同的分布,我们将计算
这里
γ
\gamma
γ和
β
\beta
β是你模型的学习参数,可以使用梯度下降或者梯度下降的优化算法求出来。我们计算可以得到当
γ
=
δ
2
+
ϵ
,
β
=
μ
\gamma=\sqrt{\delta^2+\epsilon},\beta=\mu
γ=δ2+ϵ,β=μ时其实是还原了z的分布。
那么赋予影藏单元不同的分布的意义在于什么呢?
在3部分给出答案


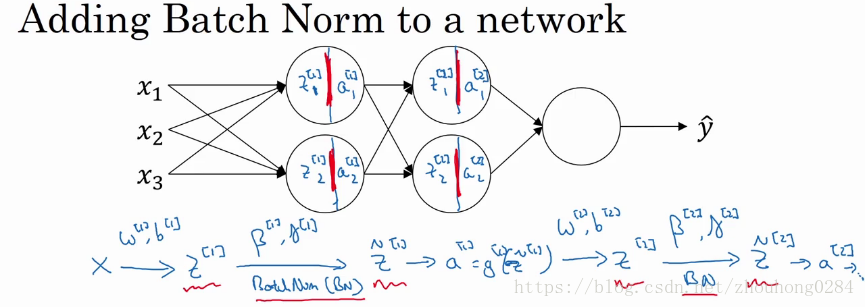
2)在神经网络中使用Batch Norm
先将Batch Norm加入到神经网络架构中,对每一层神经网络中
γ
[
l
]
\gamma^{[l]}
γ[l]和
β
[
l
]
\beta^{[l]}
β[l]的训练使用梯度下降法或者是其优化算法。
γ
[
l
]
\gamma^{[l]}
γ[l]和
β
[
l
]
\beta^{[l]}
β[l]都是(
n
[
l
]
n^{[l]}
n[l],1)维的向量,也就是对不同维度的z均有一个均值和方差。
注意:要区分优化算法中的参数
β
\beta
β和均值
β
[
l
]
\beta^{[l]}
β[l],这是两个完全不一样的参数。
实际上,在mini-batch中不使用Batch Norm的时候,计算z的公式是
z
[
l
]
=
w
[
l
]
a
[
l
−
1
]
+
b
[
l
]
z^{[l]}=w^{[l]}a^{[l-1]}+b^{[l]}
z[l]=w[l]a[l−1]+b[l],在做Batch Norm之后,因为要先将
z
[
l
]
z^{[l]}
z[l]归一化,因此无论
b
[
l
]
b^{[l]}
b[l]的值是多少,都是要被减去的,所以在训练中,我们可以不考虑
b
[
l
]
b^{[l]}
b[l]的值。
具体的。对每个mini-batch实施batch Norm的步骤是:

3)为什么Batch Norm是有效?
- 归一化输入,使得它们在同样的范围中可以加快训练速度;
- 使得后层中的权重可以适应前面权重的变化。
当前层的参数发生变化的时候,对后层来说,输入无时无刻不在变化,因此就会出现covariate shift的问题。这时Batch正则化的作用限制了在前层的参数更新对数值分布的影响,就是无论前层输入z如何变化,z的均值和方差不会变化。(全局理解) - regularization
每个nimi-batch集的归一化是对这一个mini-batch所做的,因此归一化之后的值 z [ l ] z^{[l]} z[l]在每一层上存在一些噪声,这些噪声和dropout带来的影响一样可以实现正则化。
另外的理解:
解决了反向传播过程中的梯度问题,如果不进行Batch norm,梯度可能会出梯度消失或者梯度爆炸。
4) 测试时的Batch Norm
归一化时使用的均值和方差怎么做?
使用指数加权平均来计算每个mini-batch的均值和方差,然后使用最后的均值来对测试样本做归一化。

2 多类分类Softmax
C表示多分类的种类
使用softmax layer可以训练出多分类模型。
Activation function:
t
=
e
[
z
l
]
t=e^{[z^l]}
t=e[zl] 先求出最后一层的z向量,通过z向量得到临时变量t
a
l
=
t
i
∑
i
=
1
c
t
i
a^l=\frac{t_i}{\sum_{i=1}^{c}t_i}
al=∑i=1ctiti 通过将t归一化得到输出
y
^
\hat y
y^,输出就是属于各类的概率。
我们可以将最后一层理解为一个softmax激活函数的输出:
y
^
=
g
l
(
z
l
)
\hat y=g^l(z^l)
y^=gl(zl),与之前的激活函数不同的是,它的输入
z
l
z^l
zl是一个向量,输出也是一个向量,而之前的激活函数,比如说Relu,输入是一个值z输出一个值a。
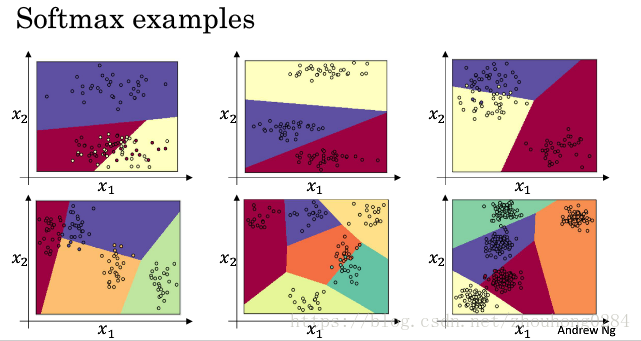
对于一个没有隐藏层的神经网络,使用softmax分类可以将输入线性映射到不同的类别中:
注意到它们的分类边界都是线性的。当输出只有两个类时,其实就是logistic回归。因此softmax是将logistics回归扩展到多分类。
什么是hardmax,就是不输出概率,而是直接输出所属类别向量,比如对于
z
l
=
[
5
,
2
,
−
1
,
3
]
z^l=[5,2,-1,3]
zl=[5,2,−1,3],直接输出
[
1
,
0
,
0
,
0
]
[1,0,0,0]
[1,0,0,0].
损失函数如何定义?对于单个输出
L
(
y
,
y
^
)
=
−
∑
i
=
1
C
y
i
log
y
^
i
L(y,\hat y)=-\sum_{i=1}^C y_i\log \hat y_i
L(y,y^)=−∑i=1Cyilogy^i,对于整体的样本集就是
J
=
1
m
∑
i
=
1
m
L
(
y
i
,
y
^
i
)
J=\frac{1}{m}\sum_{i=1}^mL(y^i, \hat y^i)
J=m1∑i=1mL(yi,y^i).
含有softmax layer的梯度下降:
注意
d
z
l
=
y
^
−
y
\rm d z^l=\hat y-y
dzl=y^−y
使用编程框架,给定正向传播公式,它就可以自动计算出反向传播公式。
3 深度学习框架
Tensorflow的典型范例:
先给定损失函数的系数,定义变量w和系数x,定义损失函数
然后给出模型的训练方法(梯度下降或者优化的梯度下降),目标(最小化损失函数)
后面几步是TensorFlow中常用的规则性语句
最后输入迭代次数进行多次梯度下降求变量w的拟合成果。

总结
这周学习完成之后,你应该可以回答以下几个问题:
1.Batch Norm是在干什么,它的原理及好处?
2.多类分类时的softmax是如何进行的?
3.学会基本的tensorflow使用。














 1648
1648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









