







概述
RCU是Read-Copy-Update的缩写。于linux2.5版本开发期间加入并顺利被社区接纳。现在广泛应用于指针及内核链表的保护。RCU相对其它并发访问保护的锁,具体更好的性能,因为严格意义上来说,RCU并不是一个锁。但RCU对内存是有一定的开销的。
为何需要RCU
- 性能问题,无需获得锁,性能更好。
- 读写线程可并发执行。
RCU使用接口
rcu_read_lock() //RCU读临界区开始
rcu_read_unlock() //RCU读临界区结束
synchronize_rcu() //同步等待所有现存读访问完成
call_rcu() //注册一个回调函数,等所有读访问完成后,调用回调函数摧毁旧数据
rcu_assign_pointer() //发布更新后的数据
rcu_dereference() //获取RCU保护和指针RCU使用条件
- 对共享数据访问大多是只读,写访问相对很少(如文件系统中查找目录,但修改目录相对较少)
- RCU保护的代码范围内不能睡眠
- 受保护的资源必须通过指针访问
-读者对新旧数据不是非常敏感
RCU使用范例
我们从一个例子入手,这个例子来源于linux kernel文档中的whatisRCU.txt。这个例子使用RCU的核心API来保护一个指向动态分配内存的全局指针。
struct foo {
int a;
char b;
long c;
};
DEFINE_SPINLOCK(foo_mutex);
struct foo *gbl_foo;
//写线程
void foo_update_a(int new_a)
{
struct foo *new_fp;
struct foo *old_fp;
new_fp = kmalloc(sizeof(*new_fp), GFP_KERNEL);
spin_lock(&foo_mutex);//RCU本身不能保护写的并发,用spinlock保护
old_fp = gbl_foo;
*new_fp = *old_fp;
new_fp->a = new_a;
rcu_assign_pointer(gbl_foo, new_fp); //发布新数据
spin_unlock(&foo_mutex);
synchronize_rcu(); //同步等待读完成后摧毁旧数据
kfree(old_fp);
}
//读线程
int foo_get_a(void)
{
int retval;
rcu_read_lock(); //RCU读开始
retval = rcu_dereference(gbl_foo)->a; //获取保护的指针
rcu_read_unlock(); //RCU读结束
return retval;
}RCU实现原理
RCU机制记录了指向共享数据结构的指针的所有使用者,在该结构将要改变时,首先创建一个副本,在副本中修改。在所有读访问使用者结束对旧副本的读取后,指针可以替换为指向新的修改过的副本,然后将旧数据摧毁。
RCU实现分析
宽限期(Grace Period)
通常把写者开始更新,到所有读者完成访问这段时间叫做宽限期(Grace Period)。内核中实现宽限期等待的函数是synchronize_rcu。
如何判断渡过了宽限期?
我们先看一下读的锁标志:
static inline void __rcu_read_lock(void)
{
preempt_disable();
}
static inline void __rcu_read_unlock(void)
{
preempt_enable();
}这时是否度过宽限期的判断就比较简单:每个CPU都经过一次抢占。因为发生抢占,就说明不在rcu_read_lock和rcu_read_unlock之间,必然已经完成访问或者还未开始访问。
静态期(synchronize_rcu)
kernel把这个完成抢占的状态称为quiescent state。每个CPU在时钟中断的处理函数中,都会判断当前CPU是否度过quiescent state。
void update_process_times(int user_tick)
{
......
rcu_check_callbacks(cpu, user_tick);
......
}
void rcu_check_callbacks(int cpu, int user)
{
......
if (user || rcu_is_cpu_rrupt_from_idle()) {
/*在用户态上下文,或者idle上下文,说明已经发生过抢占*/
rcu_sched_qs(cpu);
rcu_bh_qs(cpu);
} else if (!in_softirq()) {
/*仅仅针对使用rcu_read_lock_bh类型的rcu,不在softirq,
*说明已经不在read_lock关键区域*/
rcu_bh_qs(cpu);
}
rcu_preempt_check_callbacks(cpu);
if (rcu_pending(cpu))
invoke_rcu_core();
......
}经典RCU与Tree RCU
linux2.6.29之前的RCU通常被称为经典RCU(classic RCU).经典RCU在大型系统中遇到了性能问题,后来由Tree RCU解决对应的性能问题。目前的内核大多使用Tree RCU.
Tree RCU采用树状结构:
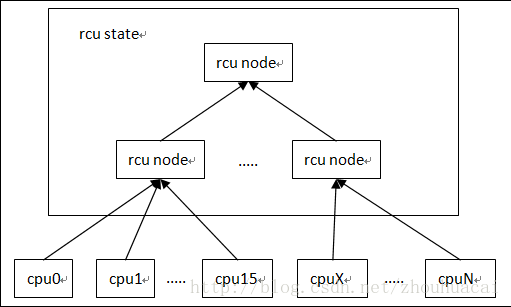
内核中RCU相关链表操作
为了操作链表,在include/linux/rculist.h有一套专门的RCU API。如:list_entry_rcu、list_add_rcu、list_del_rcu、list_for_each_entry_rcu等。即对所有kernel 的list的操作都有一个对应的RCU操作。其将指针的获取替换为使用rcu_dereference。
rculist.h (include\linux)
list_entry_rcu()
list_add_rcu()
list_add_tail_rcu()















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









