








ViT引发的变革
Transformer最开始是作为自然语言处理(英语: Natural Language Processing ,缩写作 NLP)领域的模型框架,在该领域其可谓大放异彩,然而自始至终都有人在不断尝试将Transformer应用到视觉领域计算机视觉(Computer Vision 简称CV),从而实现NLP与CV的大一统。
ViT(Vision Transformer)是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
该篇文章的主要思想便是Transformer没有瓶颈,只要数据集够大,那么他的效果就会越好,并且在许多大型数据集上进行了实验,通过与当下主流的卷积神经网络模型进行消融实验,最终印证他的想法。
该论文一经问世,便引起来剧烈反响,之后,各种Transformer应用到计算机视觉领域的研究如雨后春笋版出现,由于Transformer的主要思想便是自注意力机制与encoder-decoder,其研究的主要思想便是将自注意力机制应用到卷积神经网络模型,实验证明,其具有很好的效果。
CV领域作为人工智能的一个重要分支,其主要包含以下方面:

ViT思想与实现
我们都知道,Transformer作为NLP算法的一员,擅长两者预测,分别是完形填空式与给出前句预测后句这两种类型,无论是那种,其处理的都是文本,抑或是一个序列,且由于序列长度的限制,其最佳为256,为了证明Transformer的通用性,那么将其转入计算机视觉时我们依旧是想将其转换为序列形式,这就产生了一个问题,如果是将图像按每个像素转换为扁平的一维序列,那么其长度是极大的,总所周知,Transformer的核心便是自注意力机制的引入,而自注意力机制便是将所有元素进行内积求权重,这是n2级别,对应图像像素而言这种计算量无疑是难以估量的。为了解决这个问题,Google团队提出可以引入patch的思想,即将图像分为16x16的图像块(这个尺寸是人为指定的),然后我们将图像块做出序列的形式送入Transformer模型。如下图:
ViT将输入图片分为多个patch(16x16),再将每个patch投影为固定长度的向量送入Transformer,后续encoder的操作和原始Transformer中完全相同。但是因为对图片分类,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测,这里之所以使用这个token是因为作者坚信在使用自注意力机制时其能够从其他的序列中获取到有用的信息,事实上也正如作者所预料。
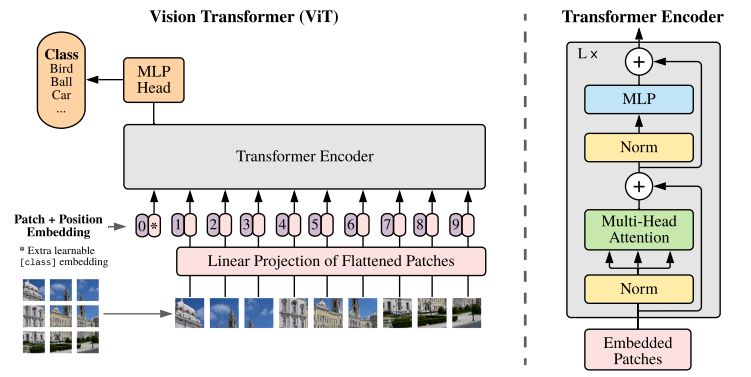
按照上面的流程图,一个ViT block可以分为以下几个步骤
(1) patch embedding:例如输入图片大小为224x224,将图片分为固定大小的patch,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197x768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题。
(2) positional encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768。
(3) LN/multi-head attention/LN:LN输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后在过一层LN,维度依然是197x768。
(4) MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768。
一个block之后维度依然和输入相同,都是197x768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出 Z0 作为encoder的最终输出 ,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式(4),后面接一个MLP进行图片分类
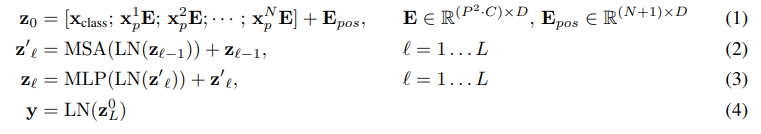

了解了Vision Transformer的基本思想,我们了解到实现物体分类可以通过上面的方法来实现,那么对于计算机视觉领域的其他问题呢,比如目标检测,语义分割呢?
此外,论文中还指出,相较于其他的卷积神经网络算法,ViT的速度更快,看到这里是不是很激动,ViT不但效果拔群,速度也是一骑绝尘,不正是鱼与熊掌兼得吗,然而属实高兴太早了,作者所言的速度快只是相对的,而且大家不要忘了一个前提,ViT之所以能够大放异彩很重要的原因便是数据集足够大,在作者眼中,像ImageNet这样的数据集只是中小数据集,而实验中使用的谷歌的数据集,其高达三亿数据量。而所谓的速度也是使用TPU后依旧需要运行很长时间(2500天)简直无法想象。所以还是建议诸位,虽然这是一个可行的方案,但是否要执行却有待商榷。当然这里指的是从头开始,作者的实验支持,通过大量的数据集进行预训练,之后我们可以使用这些预训练模型在小型数据集上进行微调,进而得到较为满意的结果。
基础知识
今天我们就来学习一下使用Transformer来完成目标检测的算法:DETR,该模型的调试过程大家可以参考博主的这篇博客:
总体而言,该模型的调试还是十分简单的。
注意:DETR算是Transformer应用于计算机视觉领域的开山之作,其更重要的是一种思想,其摆脱了Faster-RNN系列的区域选择,摆脱了YOLO系列的Anchor限制,进而摆脱了NMS带来的计算消耗,尽管与当前的主流目标检测方法相较有些力不从心,这些大胆的创新之举已经足以让其大放异彩。博主其实想说的对于DETR模型而言,我们不需要对其要求太过苛刻,因为我们有理由相信,其只是一个开端,其前路十分光明。
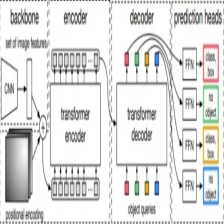
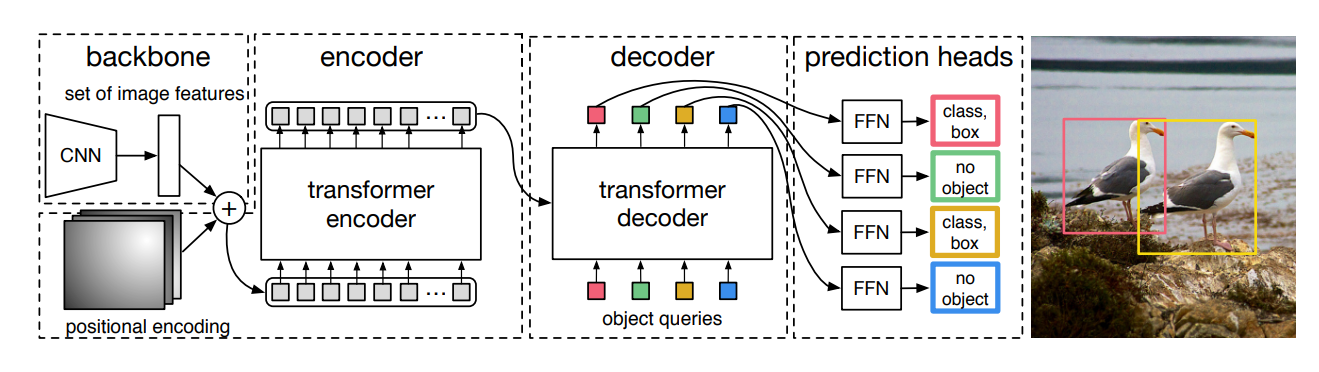
DETR模型实现流程
DETR模型如下:首先是通过将图像信息送入一个卷积网络模型中去提取特征,通过CNN来得到patch作为输入,进而将这些特征送入Encoder进行编码,处理成为我们想要的属性特征,随后通过Decoder的Q(在DETR中是随机初始化的,为0+位置编码,0代表从头开始,位置编码则可以让我们的注意力有个具体的方向,不要想无头苍蝇般乱撞)给出条件,进而能够获取到最好的特征,将特征信息再经过全连接层进行回归与分类,进而获得物体的类别与位置信息。
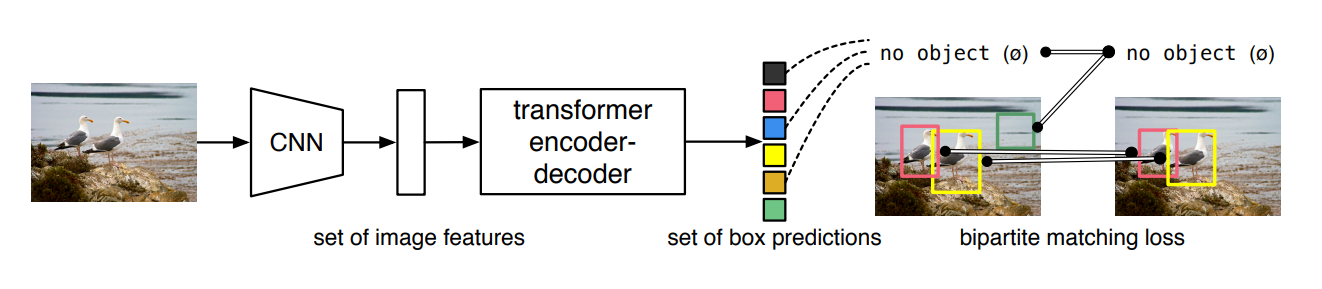
值得注意的是,再DETR中设定输出100个预测框,这个是人为设定的,考虑到一张图片即使复杂也不过十几个,几十个目标而已,进而过滤区分目标与背景,如下图最终识别出两个物体。
训练时如何筛选预测框
在训练过程中,我们的GT只有两个,那么该如何将其余的98个预测框去除呢?这里的过滤方法使用的是匈牙利算法,按照LOSS最小的组合,选出2个目标物体后,其余的为背景。
因此Decoder中提供了100个向量来进行学习,其要借助Encoder中生成的特征来决定自己如何重构,即Decoder实际上是要让自己更好更精确的去描述这些特征,即可认为是通过学习来描述特征。那么,objects queries便是核心,让它学习如何从原始特征中找的物体。此外,与原始的Transformer不同,如今的Q是并行的。
可以看到,Encoder的作用是进行特征的提取,那么我么是否可以不要这个Encoder而直接使用一个CNN网络来直接连接Decoder呢?其实理论上也是可行的,但为何仍采用这种方式呢,论文中作者给出解释:
作者认为这种注意力的效果很好,通过self-attention获取到这些特征并加以突出,随后来供Decoder进行挑选。

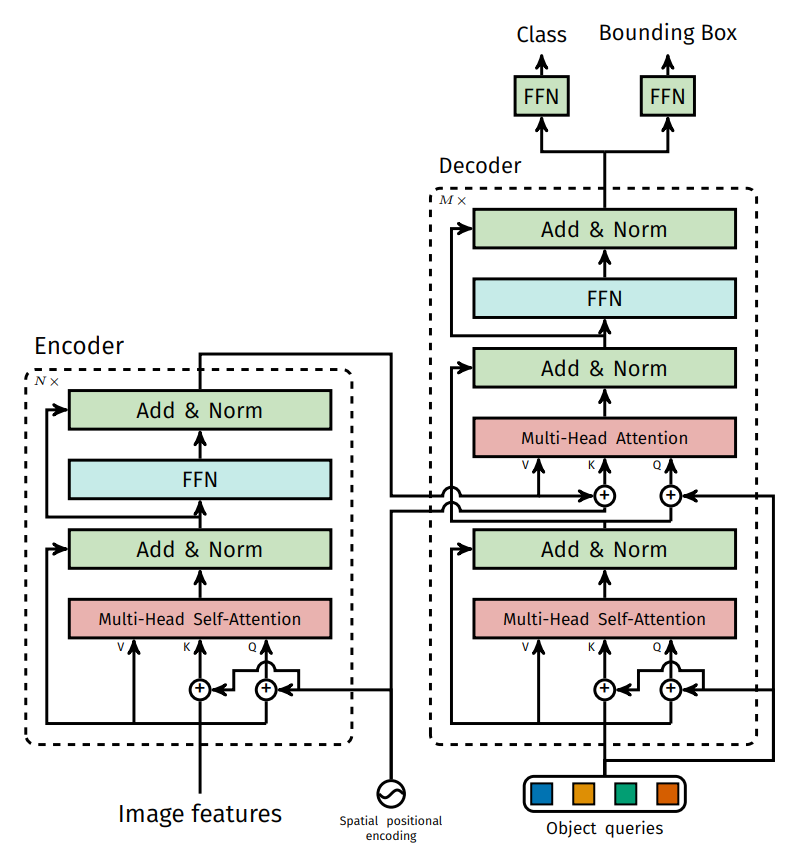
网络架构
Encoder继续沿用Transforemer的架构,并未进行什么改动,重点在于Decoder的设计。在Decoder中,首先做自注意力机制,我们在初始化时也产生了K,V,Q,这时是自己玩,得到的K,V特征并不重要,重要的是将Q处理好,随后便用到了Encoder中的K,V以及我们在Decoder中的Q进行注意力计算。最终我们要的就是Q,将Q通过全连接层得到我们所需要的class和位置即可。
启示
在论文中,作者提到,注意力机制的引入能够很好的解决物体被遮挡问题。如下图:即使面对很严重的遮挡问题,注意力机制都可以很好的解决。


















 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











