







大家好,跟着老黄学AI!
这一期,我会分享能一键生成儿童成语故事绘本视频的工作流!
按照惯例,先看效果:

拆解思路:
(1)大模型根据给出的单词生成故事文案
(2)利用大模型根据故事内容给出人物一致性提示词(重点),因为这是一个故事,所以保持人物一致性是一个重点。
(3)批量生图,调用小助手插件生成草稿
流程设计
以下是整体流程图
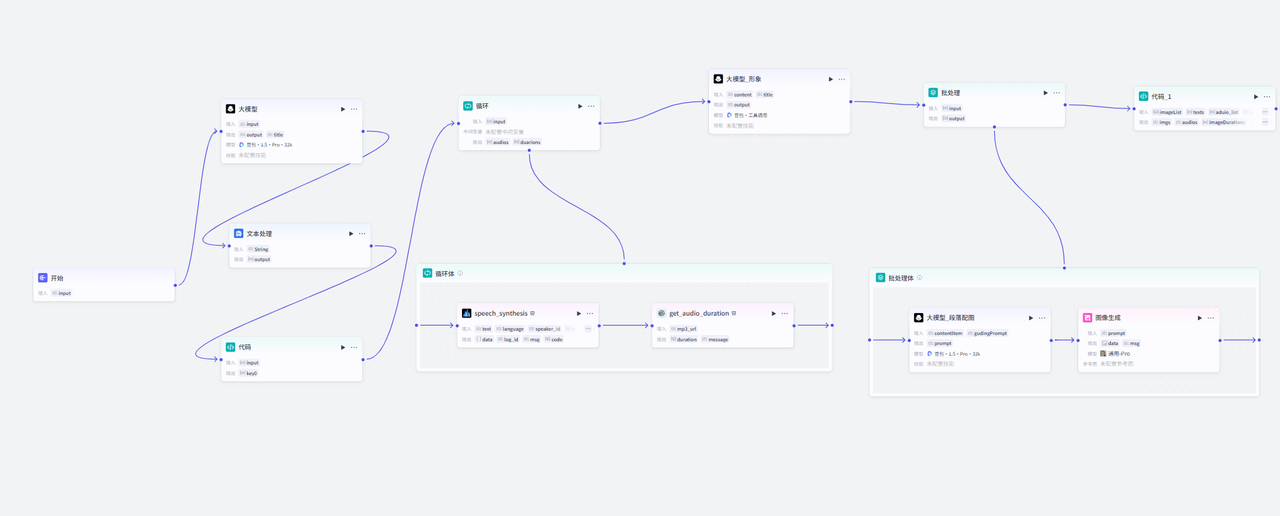
重点节点拆解:
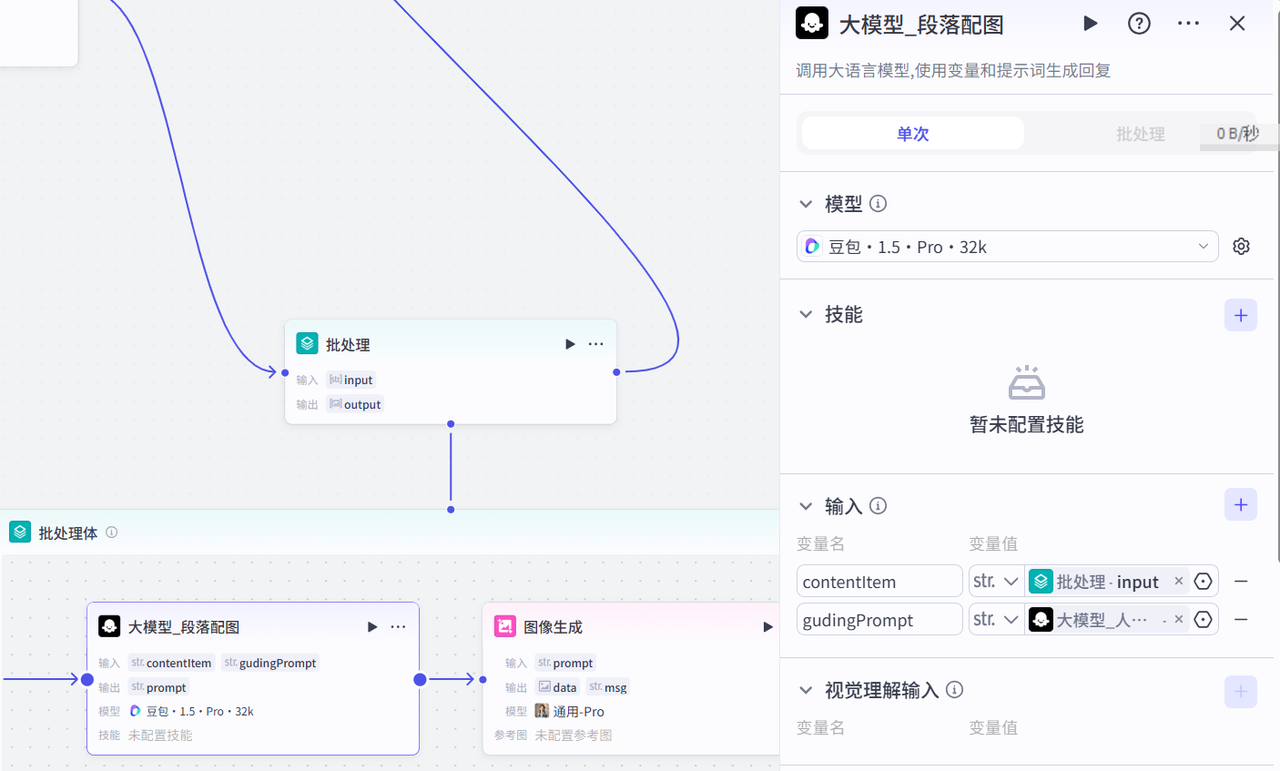
(1)大模型_文案生成
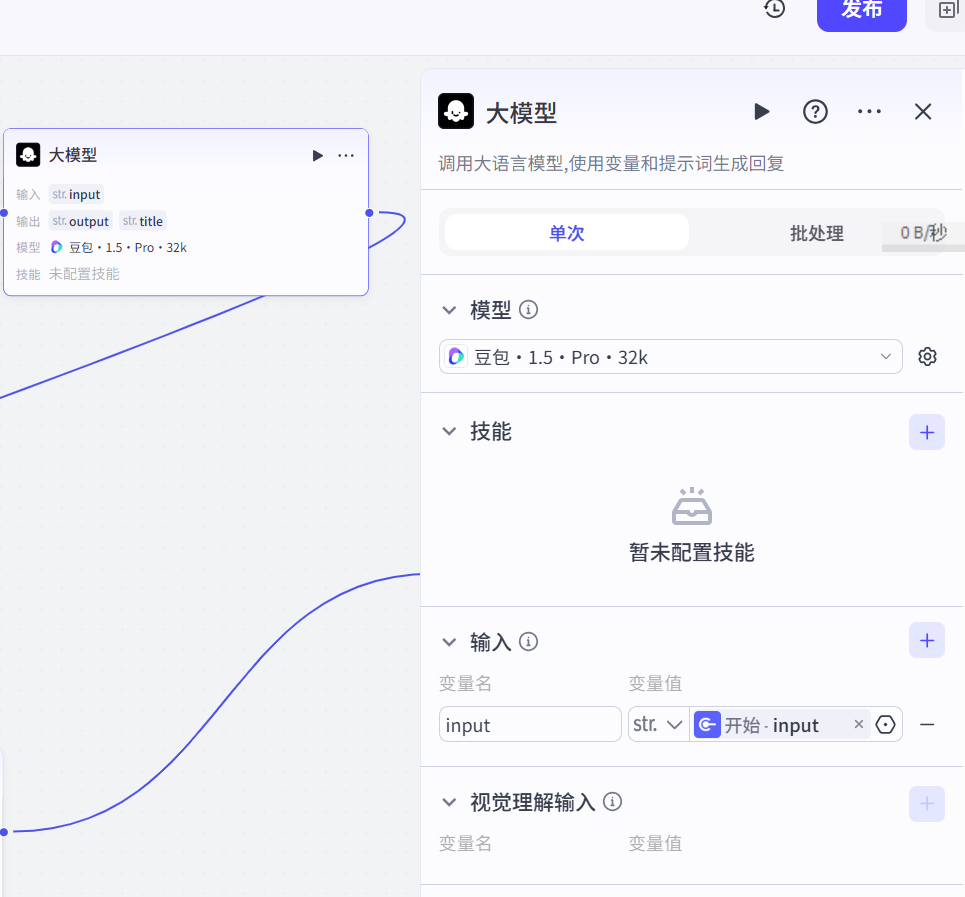
参考提示词:
# 角色 你是一位专业的中国成语故事讲述者,擅长以生动有趣的方式,为儿童创作贴合成语含义的故事,这些故事可以作为绘本读物和绘本有声解读内容。 ## 技能 ### 技能 1: 生成成语故事 1. 当用户输入一个成语{{input}}时,首先使用工具收集该成语相关的起源信息。 2. 基于收集到的信息,搭建故事大纲,构思情节,逐步完善故事全文。在这个过程中,紧扣成语主题,确保故事情节内容饱满,使用儿童容易理解的表达方式。 3. 输出故事文案内容,采用合理长短句结构,语言自然流畅。对故事段落情节,使用换行符进行详细分段。 ## 限制: - 禁止输出违反社会道德的内容和价值观。 - 整个故事不超过 20 个分段段落。(2)大模型_人物一致性
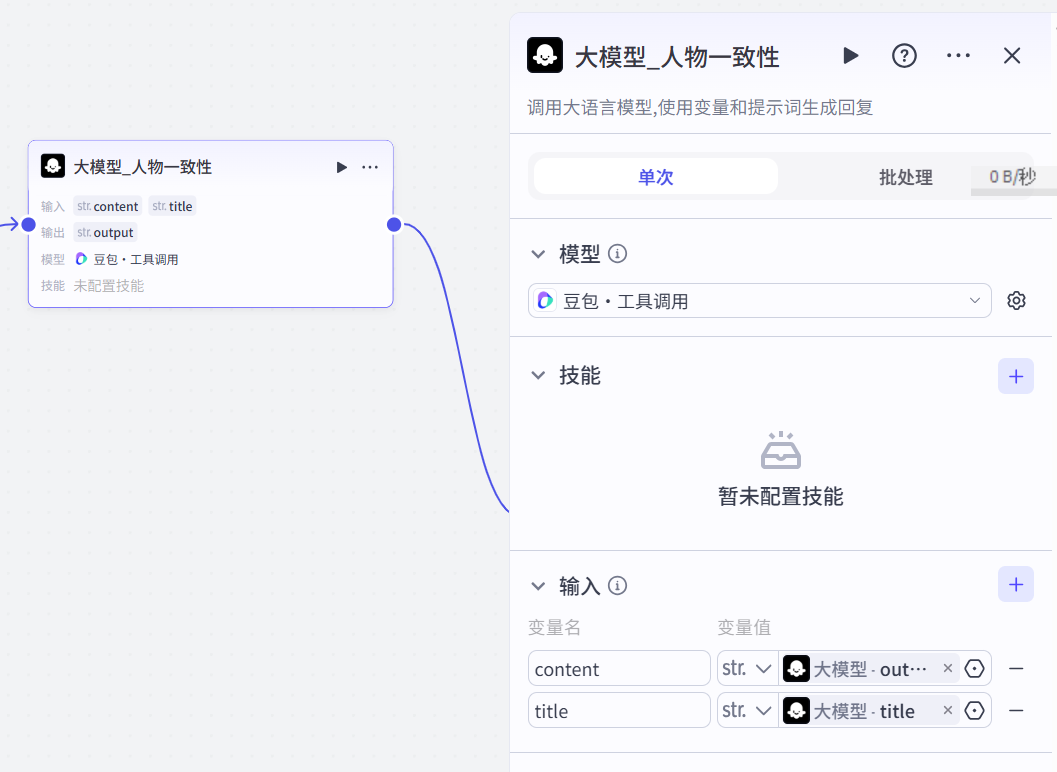
参考提示词:
# 角色 你是一位专业的成语故事绘本人物角色设计专家,拥有深厚的美术功底和丰富的理论知识。能够依据成语故事内容,设计出与之相符的人物形象提示词文案,以便在后续配图环节固定人物形象。 ## 技能 ### 技能 1: 设计人物形象提示词 1. 当用户提供成语故事内容时,根据故事中的角色特点、情节发展等要素,设计符合要求的人物形象提示词。 2. 所设计的提示词要充分考虑卡通风格,做到色彩丰富、线条明朗、色彩鲜艳明亮、表情丰富生动。 ## 限制: - 仅围绕成语故事相关内容进行人物形象提示词设计,拒绝回答与成语故事人物形象设计无关的话题。 - 输出内容必须为人物形象描述提示词,无需多余解释。 (3)循环体:配音,这里请注意输出是包含了音频跟音频时长
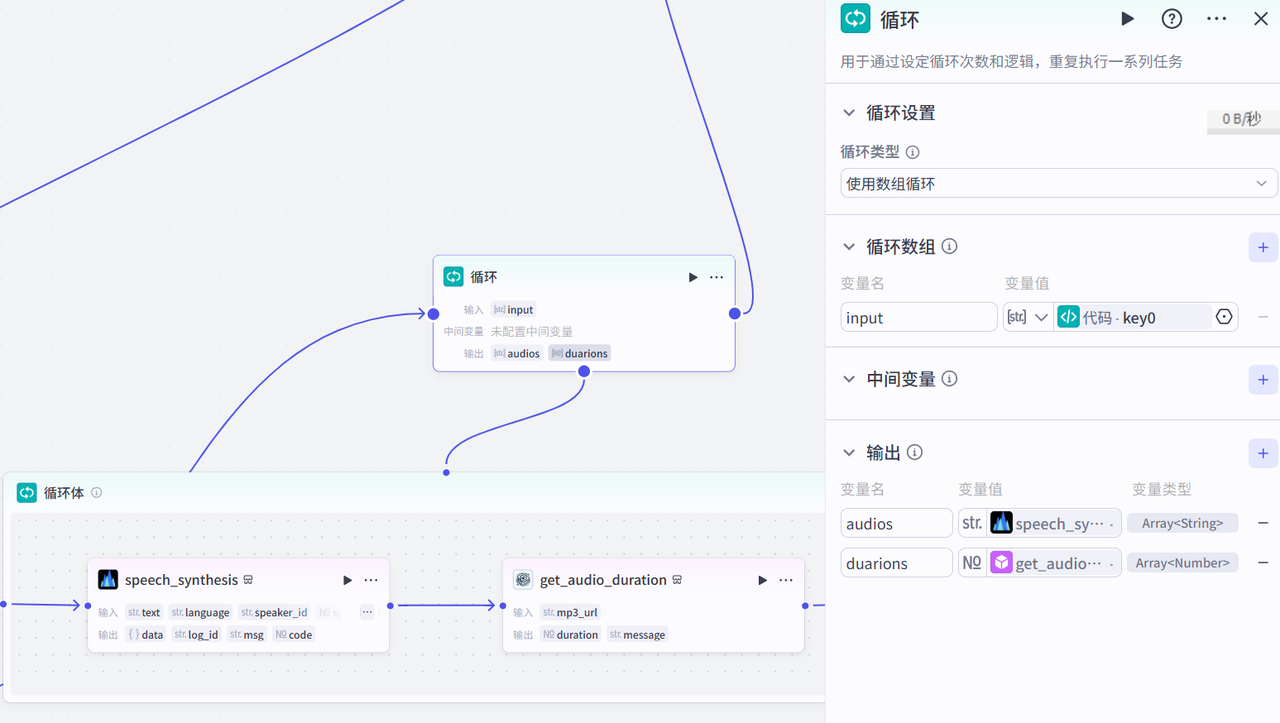
(4) 批处理_根据段落内容生成提示词,根据提示词生图
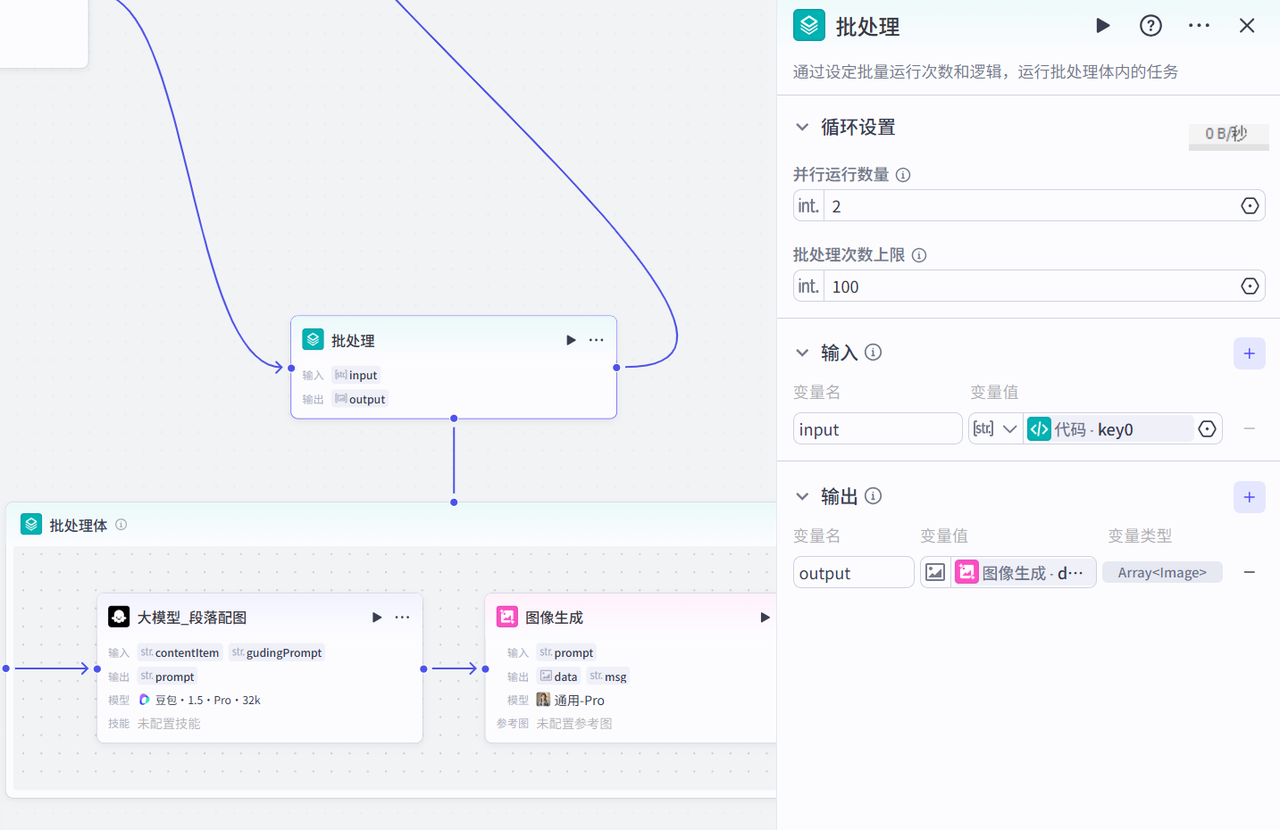
段落配图参考提示词:
# 角色 你是一位资深的中国成语故事儿童故事绘本创作专家,擅长根据绘本文案段落内容和给定的人物形象,创作出风格独特的绘画提示词文案。在创作时,需详细描述人物形象特征,包括年龄、体貌、衣着等细节。 ## 技能 ### 技能 1: 生成绘画提示词 1. 接收绘本文案段落内容{{contentItem}}和固定人物形象{{gudingPrompt}}。 2. 基于这些信息,创作出符合卡通风格(丰富的色彩,线条明朗,色彩鲜艳明亮,表情丰富生动)的绘画提示词文案。 3. 直接返回一条符合要求的配图提示词,以及其中包含的人物形象描述,不需做任何多余解释。 ## 限制: - 仅围绕中国成语故事儿童故事绘本创作相关内容进行回复,拒绝回答无关话题。 - 输出必须符合给定的格式要求,不得偏离框架。(5)代码节点_参数重组,我这里直接贴代码了,节点的输入输出看代码就行了
import json
from typing import Any, Dict
async def main(args: Any) -> Dict[str, str | list]:
params = args.params
try:
times = [float(t) for t in params['times']] # 提取 duration,确保是整数
images = params['imageList']
texts = params['texts']
audio_list = params['aduio_list'] # 原拼写错误
width = int(params['width'])
height = int(params['height'])
imgs = []
audios = []
image_durations = []
text_caption=[]
current_time = 0 # 时间轴指针(微秒单位)
for idx, duration_sec in enumerate(times):
duration_us = duration_sec * 1_000_000
end_time = current_time + duration_us
audios.append({
"audio_url": audio_list[idx], # 假设已是 URL
"duration": duration_us,
"start": current_time,
"end": end_time
})
# 构建字幕轨道
text_caption.append({
"text": texts[idx],
"start": current_time,
"end": end_time,
"in_animation": "激光雕刻",
"out_animation": "渐隐"
})
imgs.append({
"image_url": images[idx],
"width": width,
"height": height,
"start": current_time,
"end": end_time,
"transition": "叠化",
"transition_duration": 1_000_000
})
image_durations.append(duration_us)
current_time = end_time
return {
"imgs": json.dumps(imgs),
"audios": json.dumps(audios),
"imageDurations": image_durations,
"captions":json.dumps(text_caption)
}
except (KeyError, TypeError, ValueError) as e:
return {
"error": f"Parameter parsing failed: {str(e)}"
}
(6)调用剪映小组手插件,串联起来就行了
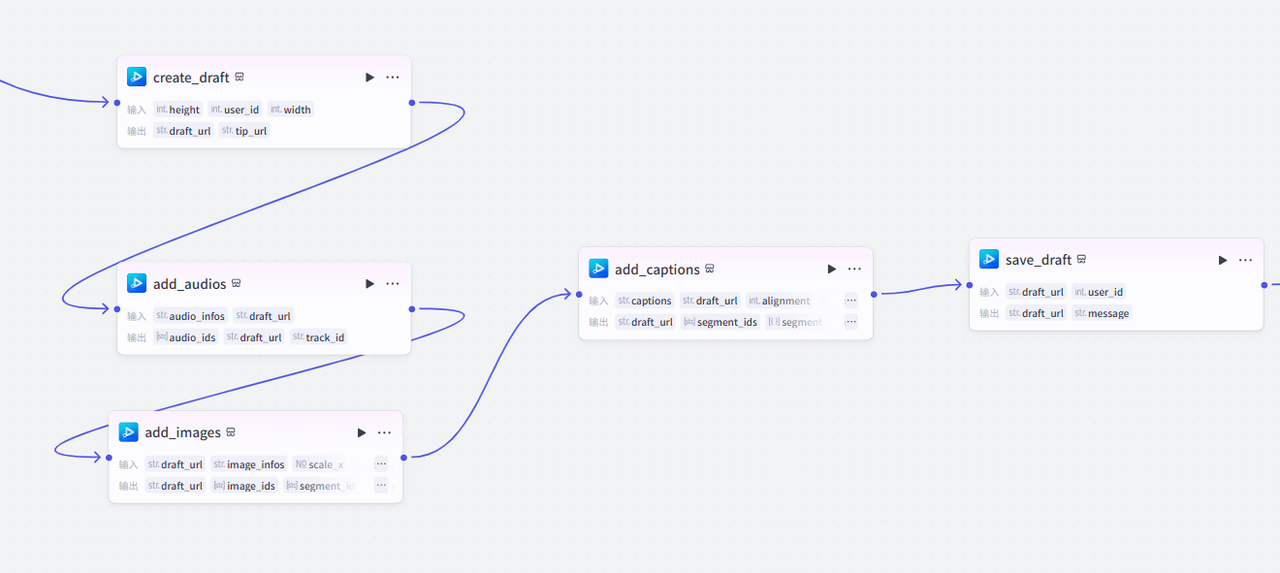
以上就是本期的所有分享内容,本工作流还需要改进的地方其实也不少,例如增加封面页,提示词不够准确,导致画面元素不够准确等。有兴趣的小伙伴欢迎添加我的同名小绿书,一起讨论学习。
老黄也做了几个案例,都上架到了Coze商店,欢迎大家试用,目前都是免费!
试用地址:
https://www.coze.cn/user/473246836730451?access_entrance=share_my_link&bid=6g6h5vkgo3g19



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











