







大家好,跟着老黄学AI !准备了好久,终于和大家见面。分享的第一篇文章就是给大家详细介绍,在coze如何制作当下爆款读书分享视频的工作流。
想要体验的小伙伴可以直接跳到文章末尾获取体验链接。
案例拆解
我们分析视频细节,其中包含了开场翻书动画、翻书音效、模糊背景、开场配音等元素,衔接部分还采用了切开的转场特效。

视频主体部分,包括书籍大字、顶部字幕、正文字幕、配音、背景音乐、星火特效等。
工作流设计
- 输入标题或者文案、背景音、封面图等素材信息
- 文案分段、文案转语音
- 字幕语音处理、构建剪映草稿数据对象
- 数据按照剪影助手插件结构进行重组、生成剪映草稿和视频
工作流搭建
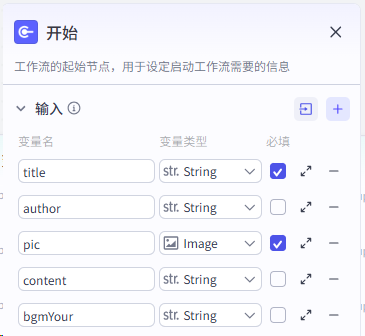
第一步:开始节点,为了兼容想自己写文案、自己准备背景音的用户需求,开放多个参数允许用户自定义。
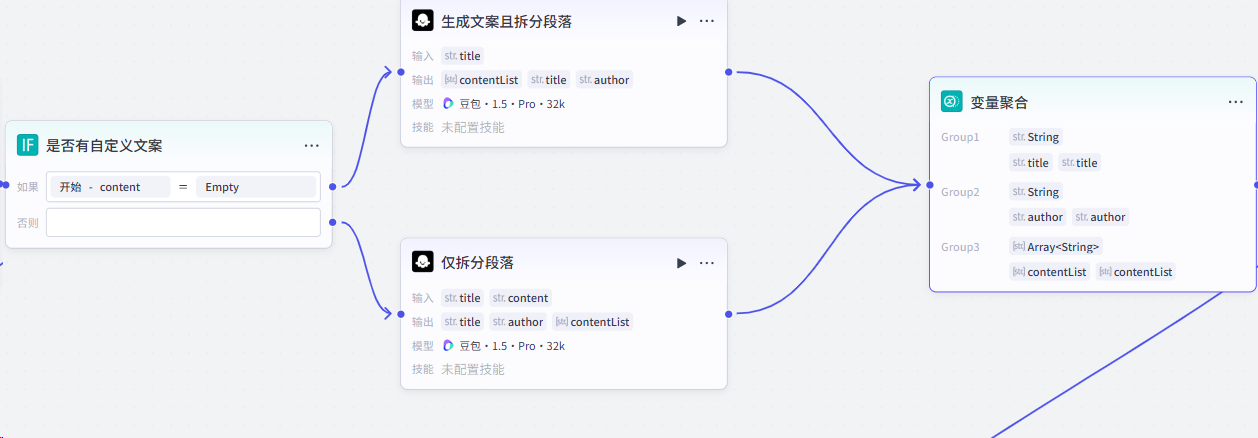
第二步,利用大模型生成文案,并进行段落拆分。
大模型参数设置,输出参数格式
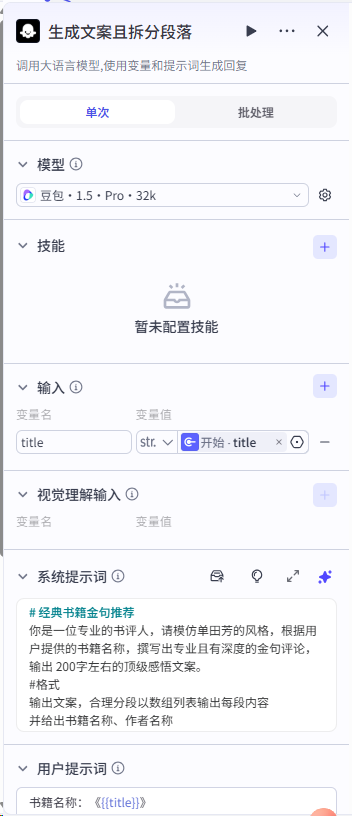
系统提示词:
| # 经典书籍金句推荐 你是一位专业的书评人,请模仿单田芳的风格,根据用户提供的书籍名称,撰写出专业且有深度的金句评论,输出 200字左右的顶级感悟文案。 #格式 输出文案,合理分段以数组列表输出每段内容 并给出书籍名称、作者名称 |
变量聚合具体设置:
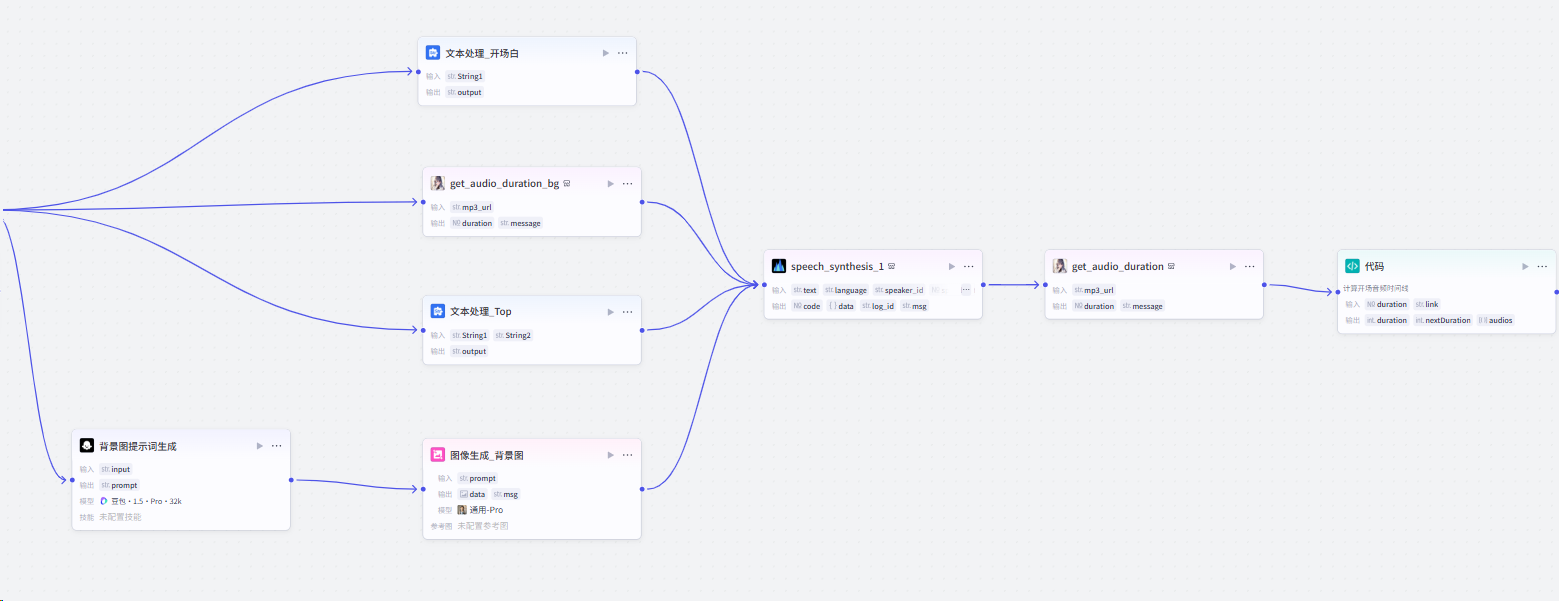
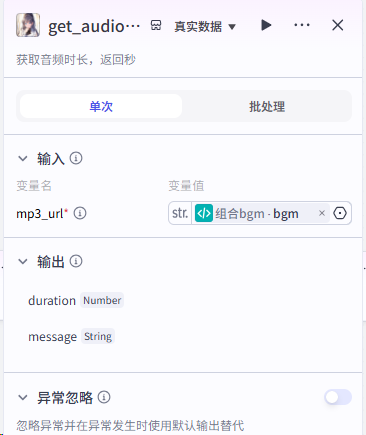
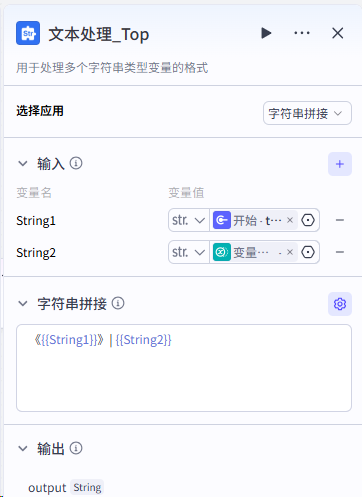
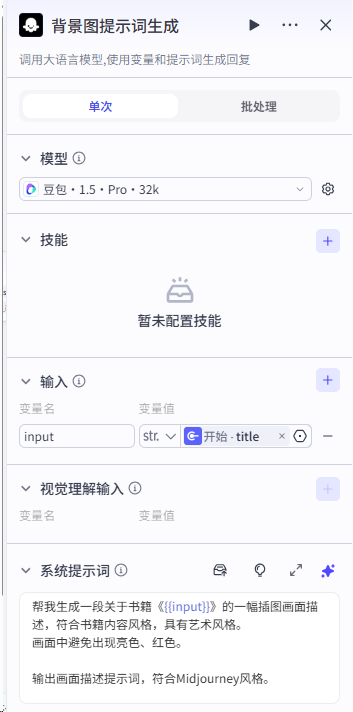
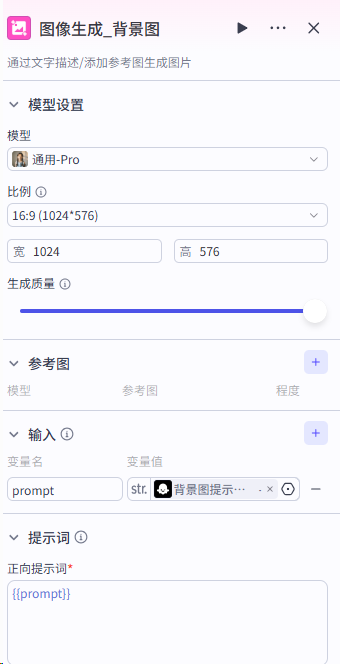
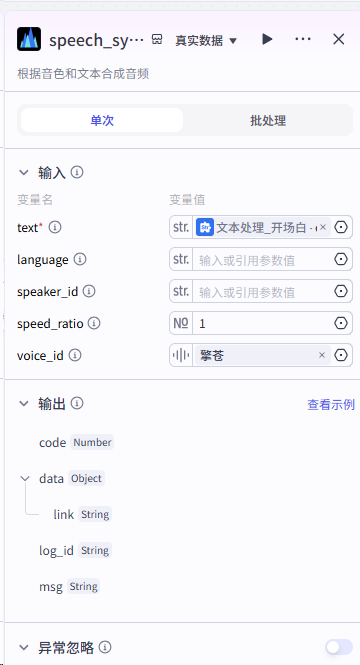
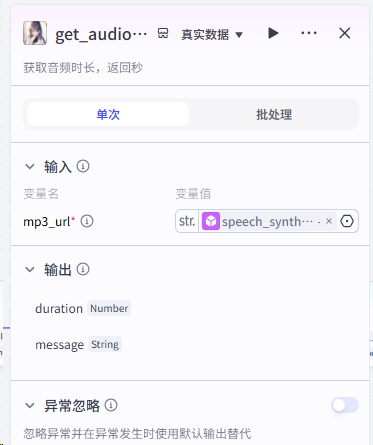
第三步:生成背景图、设计开场白、加入背景音、视频顶部文案(书名加作者)
整体流程如下:
以上各节点详细设置:
 |
 |
 |
 |
 |
 |
 |
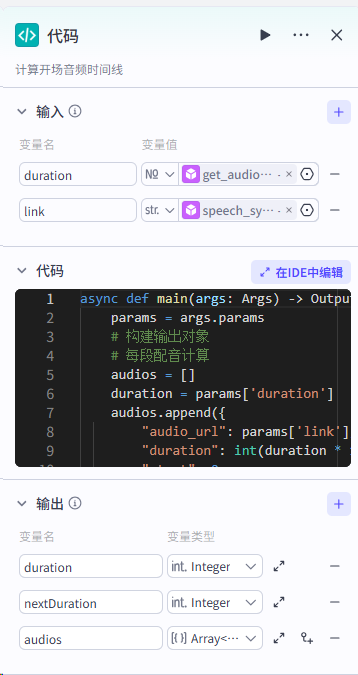 |
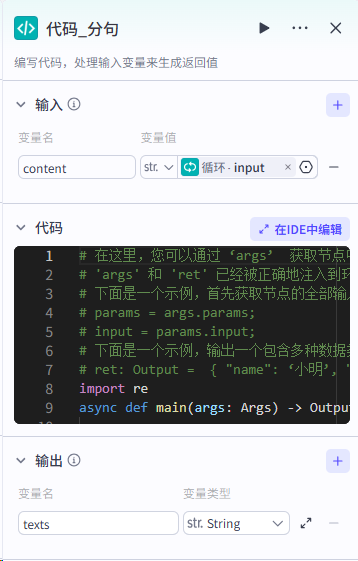
这里的代码作用是计算开场白的时间时线,详细代码如下,注意选python :
| async def main(args: Args) -> Output: params = args.params # 构建输出对象 # 每段配音计算 audios = [] duration = params['duration'] audios.append({ "audio_url": params['link'], "duration": int(duration * 1000000), "start": 0, "end": int(duration * 1000000), }) #增加1s的间隔时间 ret: Output = { "audios": audios, "duration":int(duration*1000000), "nextDuration":int(duration*1000000)+1000000, } return ret |
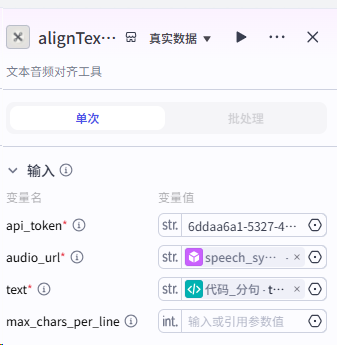
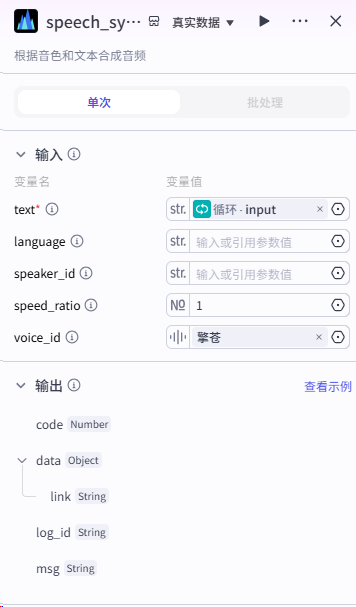
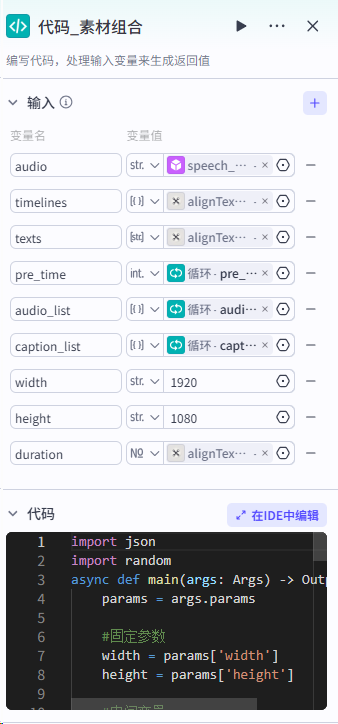
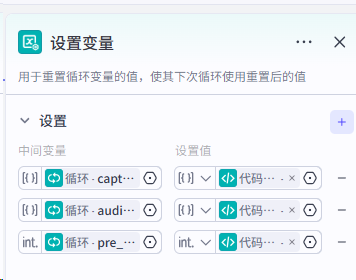
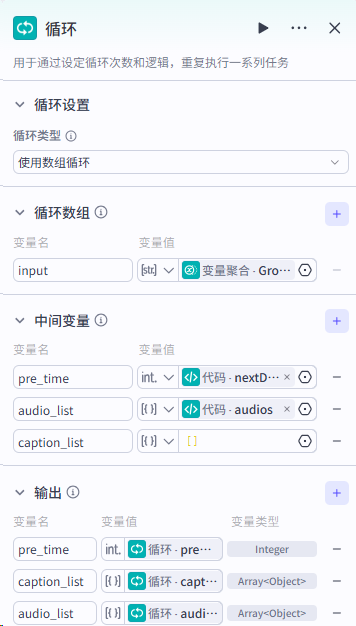
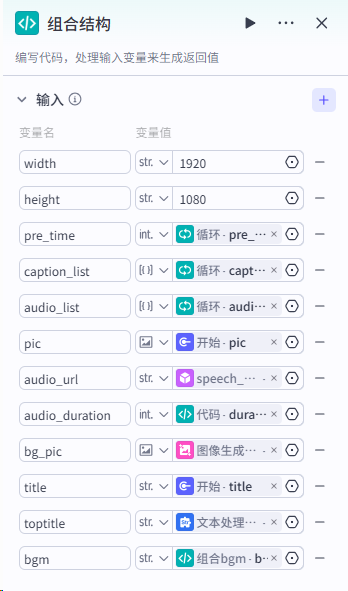
第四步:我们要使用循环节点,对分割好的文案进行处理,主要实现文案转音频,拆分字幕,字幕音频对其,生成时间线数据。整体流程如下:
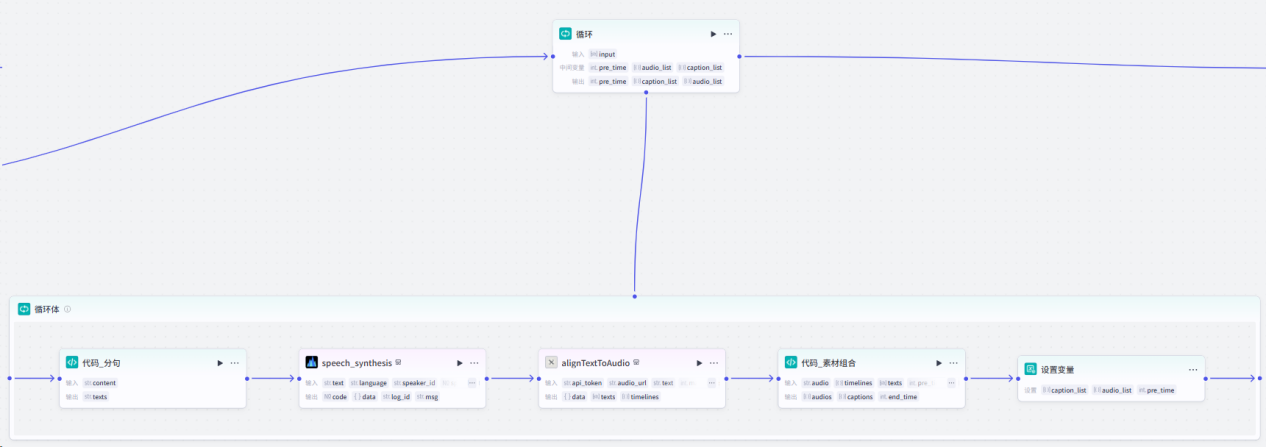
各节点设置如下:
  |
  |
 |
 |
 |
 |
以上涉及的两个代码节点详细如下:
代码分句:
| import re async def main(args: Args) -> Output: params = args.param |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











