







端到端的对话系统
环境
Python 3.7
TensorFlow 1.14
模型结构
使用seq2seq + attention 模型
NLP应用
词向量层
单词->实数向量
-
降低输入维度(one-hot输入维度与词汇表大小同)
-
增加语义信息(稠密向量),在自然语言学习的词向量会将含义相似的词赋予值相近的词向量值
# 为源语言和目标语言分别定义词向量。
self.src_embedding = tf.get_variable(
"src_emb", [SRC_VOCAB_SIZE, HIDDEN_SIZE])
self.trg_embedding = tf.get_variable(
"trg_emb", [TRG_VOCAB_SIZE, HIDDEN_SIZE])
# 将输入和输出单词编号转为词向量。
src_emb = tf.nn.embedding_lookup(self.src_embedding, src_input)
trg_emb = tf.nn.embedding_lookup(self.trg_embedding, trg_input)
softmax层
将循环神经网络输出转化为一个单词表中每个单词的输出概率
# 线性映射,将循环网络输出映射成一个维度与词汇表大小相同的向量
# softmax->logoits为加和为1的概率
logits = (tf.matmul(output, self.softmax_weight) + self.softmax_bias)
# print(logits.shape)
# 选出最可能的单词编号
next_id = tf.argmax(logits, axis=1, output_type=tf.int32)
Encoder-Decoder框架
处理输入输出长短不一的多对多文本预测问题
Decoder(解码器)
从上下文的文本信息获取特征,然后预测文本。输入为单词的词向量,输出为softmax层产生单词的概率
# 这里没有指定init_state,也就是没有使用编码器的输出来初始化输入,而完全依赖
# 注意力作为信息来源。
dec_outputs, _ = tf.nn.dynamic_rnn(attention_cell, trg_emb, trg_size, dtype=tf.float32)
Encoder(编码器)
对输入文本信息进行提取,尽量准确高效地表征文本的特征信息。词向量层与LSTM与解码器一样,由于编码阶段未输出,不需要softmax层。
# 双向循环网络,顶层输出enc_outputs(seq2seq用不到),代表两个LSTM在每一步的输出。
enc_outputs, enc_state = tf.nn.bidirectional_dynamic_rnn(self.enc_cell_fw, self.enc_cell_bw, src_emb, src_size, dtype=tf.float32)
# 将两个LSTM的输出拼接为一个张量。
enc_outputs = tf.concat([enc_outputs[0], enc_outputs[1]], -1)
注意力机制
句子较长时,中间向量难以储存足够的信息。注意力机制允许解码器查阅输入句子的单词或片段,所以不需要在中间向量中储存所有信息
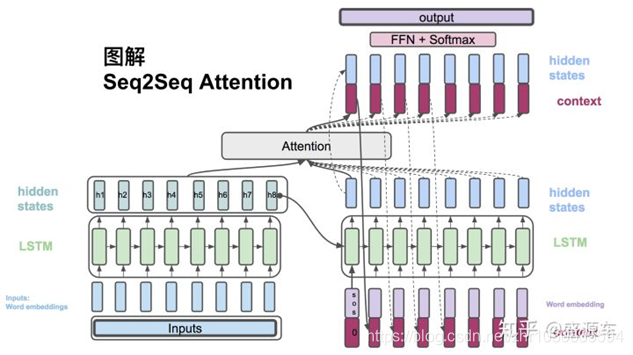
左边encoder输入转换为Word embedding,进入LSTM,每个节点上输出hidden state。然后进入右侧LSTM,输出hidden state,两边hidden state作为输入放入attention中计算context vector。
前面的context vector可作为输入和目标的单词串起来作为LSTM输入,又回到一个hidden state,如此往复。
另一方面,context vector和decoder的hidden state合起来,通过非线性转换及softmax最后计算出概率
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(HIDDEN_SIZE, enc_outputs, memory_sequence_length=src_size)
# 将解码器的循环神经网络self.dec_cell和注意力一起封装成更高层的循环神经网络。
attention_cell = tf.contrib.seq2seq.AttentionWrapper(self.dec_cell, attention_mechanism, attention_layer_size=HIDDEN_SIZE)
项目结构
Samples_15w:进行训练数据的预处理和存放
**pretreat_0.py:对数据集原始格式清洗**
**choose_some_qa.py:选择一定数量的数据**
Train_15w:存放训练的模型
Tools.py:自行编写的分词等工具,方便调用
To_word_list.py:词汇表产生
To_word_train.py:按照词汇表,将单词对应为编号
Attention_train.py:模型的训练
Attention_test.py:模型的测试
App_test.py:对聊天效果进一步封装
places.py:地名处理
数据集预处理
小黄鸡五十万对语料集

-
pretreat_0.py对问答格式进行处理

-
选择一定数量问答对并分词

-
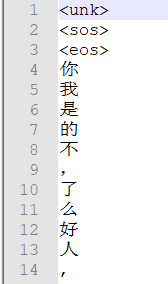
按照单词词频排序,构建固定大小的词汇表,加入eos, sos, unk
-
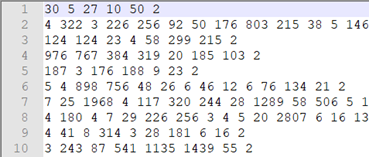
按词汇表对将单词映射到编号
注意点一:Padding & Batching
样本中,每个句子对通常作为独立数据训练。由于每个句子长短不一,因此放入同一个batch时,需将最短句子补齐至该batch内最长句子相同长度。(tf.data.Dataset的padded_batch函数)
LSTM读取数据时会读取填充位置纳入计算,因此:
读取填充时,跳过这一位置。(tf.nn.dynamic_rnn,读取内容和输入数据长度)使用dynamic_rnn时,每个batch最大长度不需要相同。
设计损失函数时需将填充位置损失的权重设为0,,不影响梯度计算。
测试时相似,输入一个句子,但dynamic_rnn要求batch,所以输入句子整理为大小为1的batch,使用dynamic_rnn构造编码器与训练同。
# 删除内容为空(只包含<EOS>)的句子和长度过长的句子。
def FilterLength(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
src_len_ok = tf.logical_and(
tf.greater(src_len, 1), tf.less_equal(src_len, MAX_LEN))
trg_len_ok = tf.logical_and(
tf.greater(trg_len, 1), tf.less_equal(trg_len, MAX_LEN))
return tf.logical_and(src_len_ok, trg_len_ok)
dataset = dataset.filter(FilterLength)
# 解码器输入trg_input,形式如同<sos> X Y Z
# 解码器输出trg_label,形式如同X Y Z <eos>
# 上面从文件中读到的目标句子是X Y Z <eos>的形式,我们需要从中生成<sos> X Y Z
# 形式并加入到Dataset中。
def MakeTrgInput(src_tuple, trg_tuple):
((src_input, src_len), (trg_label, trg_len)) = (src_tuple, trg_tuple)
trg_input = tf.concat([[SOS_ID], trg_label[:-1]], axis=0)
return ((src_input, src_len), (trg_input, trg_label, trg_len))
dataset = dataset.map(MakeTrgInput)
# 随机打乱训练数据。
dataset = dataset.shuffle(10000)
# 规定填充后输出的数据维度。
padded_shapes = (
(tf.TensorShape([None]), # 源句子是长度未知的向量
tf.TensorShape([])), # 源句子长度是单个数字
(tf.TensorShape([None]), # 目标句子(解码器输入)是长度未知的向量
tf.TensorShape([None]), # 目标句子(解码器目标输出)是长度未知的向量
tf.TensorShape([]))) # 目标句子长度是单个数字
# 调用padded_batch方法进行batching操作。
batched_dataset = dataset.padded_batch(batch_size, padded_shapes)
return batched_dataset
注意点二:解码的循环结构
训练时解码器可以从输入中读取完整的训练句子,所以可以用dynamic_rnn展开。但在测试解码中,只能看到输入句子,看不到目标句子。
解码器读入,预测第一个单词,再将预测的单词输入到第二步,再预测第二个……所以使用循环结构。
Tf.while_loop实现, 循环继续的条件、循环体、初始
天气查询(意图识别)
当用户输入“明天天气如何?、明天是晴天还是雨天?明天需要抹防晒霜吗?”聊天机器人只需要理解用户是想查询天气
意图识别方法:
(1)规则模板:
通过专家手工编写规则模板来识别意图。比如:买 .* 《地名》 .* 《地名》.* 机票 =》 买机票。缺点是人工编写工作量大,易冲突;规则模板覆盖面较小;适用于垂直领域,在通用领域则无法推广
(2)基于统计:
使用意图词典做词频统计,取词频最大的就是对应的意图。覆盖面比规则模板广,但容易误识别
(3)基于语法:
先对句子做语法分析,找到中心动词及名词,再根据意图词典即可识别出意图来。使用语法分析使得准确度更高了,但增加了语法识别的难度。
(4)基于机器学习和深度学习:
把意图识别看成是文本分类任务。进行语料标注,分词,和模型的搭建
天气查询(基于规则)
过程
检测对话中是否含有关于天气查询的关键词,若包含:
检测对话中是否含有具体的地点,若包含:
调用青云天气API,提纯后返回天气信息
否则:
询问地点
若检索对话得到地点:
返回天气信息
没有地点:
放弃,并将人类对话进行预测输出
否则:
继续对话
地名处理

搜狗词库,提取每个地名的关键词,方便后续匹配
预处理(分词or分字)
分词:jieba中文分词
分字:自己编写,中文按字切分,英文、数字、表情按词(空格)切分
效果:两种分词效果区分不大
词汇表:以15w对问答为例,分词词汇表60000+,分字词汇表13000
单个字的语义信息不明确,用字建模使捕捉字与字之间依赖关系成本提高。但单个字的词汇表大小远远小于按词切分,对于训练成本有益


Chatbot评价问题
难以实现自动化测评,主要的原因就是聊天场景的语义、语言的多样性,大部分都是靠人工评测,但是人工评测最大的问题是人工评测没办法同一批人工去评测,因此造成模型之间其实很难做完全客观的评测
一个也许可行的直接的思路:我们能不能多给一些ground truth的Response?如果足够多,那么如果生成的回复能跟其中某一个有一定程度的匹配,那么这个回复就可以认为与该response再讲同一个回复的方向,因此可以用传统的metric进行度量
最终效果
部分参数设置
| 训练数据集大小 | 15w****对 | Batch大小 | 200 |
|---|---|---|---|
| 词汇表大小 | 13000 | 句子最大单词数 | 30 |
| LSTM隐藏层规模 | 1024 | 节点不被dropout | 0.8 |
| LSTM层数 | 2 | 切分方式 | 按字 |
| Softmax层与词向量层共享参数 | True | 解码最大步数 | 100 |
最终效果


由于训练集的大小和整体风格限制,所以很多日常对话无法完美应对,并且回复中略显色情或暴力
代码fork
由《TensorFlow实战Google深度学习框架》翻译代码改写
GitHub: GitHub

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









