







目录
一、贝叶斯(Bayesian)
1.1故事背景
贝叶斯全名为托马斯·贝叶斯(Thomas Bayes,1701-1761),是一位与牛顿同时代的牧师,是一位业余数学家,平时就思考些有关上帝的事情,当然,统计学家都认为概率这个东西就是上帝在掷骰子。当时贝叶斯发现了古典统计学当中的一些缺点,从而提出了自己的“贝叶斯统计学”,但贝叶斯统计当中由于引入了一个主观困素(先验概率,下文会介绍),一点都不被当时的人认可。直到20世纪中期,也就是快200年后了,统计学家在古典统计学中遇到了瓶颈,伴随着计算机技术的发展,当统计学家使用贝叶斯统计理论时发现能解决很多之前不能解决的问题,从而贝叶斯统计学一下子火了起来,两个统计学派从此争论不休。
1.2一句话解释
经典的概率论对小样本事件并不能进行准确的评估,若想的到相对准确的结论往往需要大量的现场实验;而贝叶斯理论能较好的解决这一问题,利用已有的先验信息,可以得到分析对象准确的后验分布,贝叶斯模型是用参数来描述的,并且用概率分布描述这些参数的不确定性。
贝叶斯分析的思路由证据的积累来推测一个事物发生的概率,它告诉我们当我们要预测一个事物需要的是首先根据已有的经验和知识推断一个先验概率,然后在新证据不断积累的情况下调整这个概率。整个通过积累证据来得到一个事件发生概率的过程我们称为贝叶斯分析。
1.3基本概念
(1)分布函数
分布函数是概率论中一个重要的概念,用于描述随机变量取某个值的概率大小。
(2)概率密度函数
仅针对连续型变量定义,可以理解成连续型随机变量的似然函数。它是连续型随机变量的分布函数的一阶导数,即变化率。
(3)概率质量函数
仅针对离散型随机变量定义,它是离散型随机变量在各个特定值上取值的概率。注意,连续型随机变量的概率密度函数虽然与离散型随机变量的概率质量函数对应,但是前者并不是概率,前者需要在某个区间进行积分后表示概率,而后者是特定值概率。连续型随机变量没有在某一点的概率的说法(因为每一点的概率密度函数都是D)
假设X是抛均匀硬币的结果,
反面取值为0,正面取值为1。那么其概率质量函数为: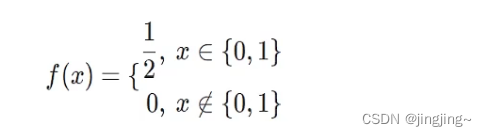
(4)似然函数
简称似然,是指在某个参数下,关于数据的函数。它在统计推断问题中极其重要。一般表示为:![]()
(5)边缘分布
在统计理论中,边缘分布指一组随机变量中,只包含其中部分变量的概率分布。
1.4概率:

什么是概率。咱们来抛硬币吧,大家的第一反应就是五五开。为什么会这样觉得呢?因为我做了很多少次试验,其中基本是一半一半,这就说明了古典统计学的思想,概率是基于大量实验的,也就是大数定理。对于硬币来说我们可以来试一试,那有些事没办法进行试验该怎么办呢?今天下雨的概率50%,日本某城市下个月发生地震的概率30%,这些概率怎么解释呢?日本在100次试验中,地震了30次?这很难玩啊!所以古典统计学就无法解释了。这只是其一,再比如说,你去赌场了,你问了10个人赢没赢钱,他们都说赢了,按照古典统计学思想,咱们是不是稳赢啊!
1.5世界观的区别:
统计学派:
观察到的数据被认为是随机的,因为它们是随机过程的实现,因此每次观察系统时都会发生变化。模型参数被认为是固定的。参数的值是未知的,但它们是固定的,因此我们对它们进行条件设置。
p(aly)
概率推理通常涉及推导未知参数的估计,基于一些选择的最优性准则选择,如无偏性、方差最小化。
比如说,在今天绝地求生里面吃鸡了的真假。定义参数a:
a = 1,吃鸡;
a =0,没有。
那么频率派认为,a是取值0或者1的固定数,不能说a=1的概率是多少。
贝叶斯学派:
数据被认为是固定的,他们使用的是随机的,但是一旦他们被拿到手了,就不会改变。贝叶斯用概率分布来描述模型参数的不确定性,这样一来,他们就是随机的了
p(aly)
我们要得到的就是对应该数据所有参数的可能性(分布)的情况。
还是上面的例子,这回我们可以说a=1概率是30%。而且随着所得样本的增多,我们可以把这个概率加以变化。
1.6贝叶斯公式

1.7先验概率
先验概率是贝叶斯推断中的一个重要概念,表示在考虑任何数据之前,我们对一个事件或参数的概率分布的初始估计。这个估计通常是基于以往的经验或领域知识得出的。在贝叶斯推断中,先验概率与后验概率一起用于更新参数的估计值.
先验概率在机器学习、统计学和人工智能等领域都有广泛应用。例如,在贝叶斯优化中,通过使用先验分布来描述优化问题的不确定性,可以更快速地找到最优解。在深度学习中,贝叶斯神经网络使用先验分布来控制模型的复杂性,并提高模型的泛化能力。
1.8符号
![]() 正比于的符号
正比于的符号
1.9 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯理论的分类算法,适用于文本分类、垃圾邮件过滤等多种场景。它的主要思想是根据已知类别的训练数据,学习每个类别的先验概率和每个特征在各个类别中的条件概率,然后基于这些概率进行分类预测。
在朴素贝叶斯中,假设所有特征都是相互独立的(这也是“朴素”这个词的来源),因此可以将分类问题简化为每个特征独立决定结果的问题。
二、 BPR算法使用背景
在很多推荐场景中,我们都是基于现有的用户和商品之间的一些数据,得到用户对所有商品的评分,选择高分的商品推荐给用户,这是funkSVD之类算法的做法,使用起来也很有效。但是在有些推荐场景中,我们是为了在千万级别的商品中推荐个位数的商品给用户,此时,我们更关心的是用户来说,哪些极少数商品在用户心中有更高的优先级,也就是排序更靠前。也就是说,我们需要一个排序算法,这个算法可以把每个用户对应的所有商品按喜好排序。BPR就是这样的一个我们需要的排序算法。
三、显示反馈与隐式反馈
2.1 显式反馈与隐式反馈基本概念
显式反馈是指:用户明确喜欢和不喜欢的物品。例如:用户对物品的评分,如电影评分。
隐式反馈是指:用户对于浏览过的物品没有明确表示喜欢或厌恶。这种类型数据只能认为全部是正反馈也即喜欢的物品。例如:用户对物品的交互行为,如浏览,购买等,现实中绝大部分数据属于隐式反馈,可以从日志中获取。
2.2 显式反馈与隐式反馈的比较

四、定义

传统的解决方法:在使用隐式反馈的情况下,我们会发现观察到的数据均为正例(因为用户对物品交互过才会被观察到),而那些没有被观察到的数据(即用户还没有产生行为的物品),分为两种情况,一种是用户确实对该物品没有兴趣(负类),另一种则是缺失值(即用户以后可能会产生行为的物品)。
传统的个性化推荐通常是计算出用户u对物品i的个性化分数,然后根据个性化分数进行排序。为了得到训练数据,通常是将所有观察到的隐式反馈(u,i)∈ S作为正类,其余所有数据作为负类,如下图所示,左图为观察到的数据,右图为填充后的训练数据:

在填零的情况下,我们的优化目标变成了希望在预测时观测到的数据预测为1,其余的均为0.于是产生的问题是,我们希望模型在以后预测的缺失值,在训练时却都被认为是负类数据。因此,如果这个模型训练的足够好,那么最终得到的结果就是这些未观察的样本最后的预测值都是0。
BPR的解决方式:BPR采用了成对优化pairwise的方式。
如下图,基于观察到的数据S构建数据集Ds:对用户u来说,如果对物品i产生过行为(即(u,i) ∈ S),而没有对物品j产生过行为,则得到了一个偏好对(u,i,j)。如对用户u1来说,对物品i2产生过行为,而没有对物品i1产生过行为,则得到了用户u1的一个偏好对(u1,i2, i1),或者表示为i2 >u1 i1.如果一个用户对两个物品同时产生过行为,或者同时没有产生过行为,则无法构建偏好对。接着,对每个用户,就可以构建Ⅰ×Ⅰ的偏好矩阵。所有用户的偏好对构成了训练集Ds :U xⅠ×Ⅰ![]()
注意,对每个三元组样本(u,i,j), i必然是产生过行为的物品,j必然是未被产生过行为的物品,因此Ds只包括下图右边分解后为+的数据,不包含-的数据。

右边的矩阵是根据左边矩阵的数据构建出的每个用户的偏序关系矩阵,其中符号“+”代表用户u喜欢项目i胜过喜欢项目j;而符号“-”代表用户u喜欢项目j胜过喜欢项目i。符号“?”代表同类数据无法确定偏序关系。对于两个没有一个用户点击过的项目,不能推断出任何偏好。同样地,也不能推断出两个用户点击过的商品的任何偏好。也就是说,本研究不能在有反馈的两个数据之间和没有反馈的两个数据之间建立一个偏序关系。
五、BPR-OPT
BPR 基于最大后验估计 P(W,H|>u)来解解模型参数 W,H,这里我们用𝜃来表示参数 W 和 𝐻, >𝑢代表用户 u 对应的所有商品的全序关系,则优化目标是𝑃(𝜃| >𝑢 )。根据贝叶斯公式,我 们有:
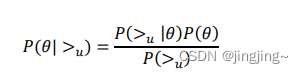
由于我们解解假设了用户的排序和其他用户无关(朴素贝叶斯),那么对于任意一个用户 u 来说,P(>u) 对所有的物品一样,所以有

这个就是贝叶斯公式的简化。
六、sigmoid函数
6.1什么是sigmoid函数
Sigmoid 函数是一种常见的非线性函数,通常用于机器学习中的二元分类任务。它将任何实数映射到一个介于0和1之间的值,数学表达式为:
sigmoid(x)=1/ (1 +exp(-x))
其中,exp(-x)表示e的-x次方,也称为指数函数。
Sigmoid函数的图像呈现出一种”S"形状,它具有以下特点:
1.输出值介于0和1之间,可以用作概率估计;
2.在输入为0时,输出为0.5,可以用作神经网络的激活函数;
3.具有导数,因此可以进行反向传播算法进行模型训练。
然而,Sigmoid函数也存在一些缺点,例如:
1. Sigmoid函数的导数最大值仅为0.25,因此在神经网络的反向传播过程中容易出现梯度消失的问题;
2.当输入很大或很小时,Sigmoid 函数的梯度接近于0,导致网络的学习速度变慢;
3.在实际应用中,Sigmoid 函数在输出值接近0或1时,斜率趋于0,使得模型的预测不够鲁棒;
方便计算,且满足BPR的完整性,反对称性和传递性。
比如:
sigmoid函数是一种常用的数学函数,在神经网络中被广泛使用。这个函数可以将任何实数值(比如说身高、体重、成绩等等)映射到一个范围在0到1之间的数值,这个映射的过程类似于把照片压缩到更小的大小。
你可以把sigmoid函数想象成一个水管,输入的数值就像是水一样,从一端流入,然后经过一些转换后从另一端流出。在这个过程中,sigmoid函数会将输入的数值"挤压"到0到1之间,就像是把水从一个大水管里面挤压到一个小水管里面一样。这个过程会使得一些本来很大或者很小的数值,变得更加接近0.5这个中间值。
在神经网络中,sigmoid函数常用于将神经元的输出压缩到0到1之间,作为下一层神经元的输入。这个过程可以使得神经网络的输出更加平滑,并且可以用来做一些二元分类的任务,比如说判断一张图片中是否有狗。
6.2什么是梯度消失
在深度神经网络中,梯度消失(Vanishing Gradient))是指在反向传播算法中,当梯度从网络的输出层向输入层反向传播时,由于链式法则的连乘效应,每一层的梯度都会被乘以一个小于1的数值(通常是权重矩阵的特征值),导致梯度不断减小,最终趋近于零。
梯度消失的问题会导致神经网络在训练过程中无法有效地更新较浅层的权重参数,从而影响网络的收敛速度和训练效果,甚至导致网络无法训练。
梯度消失的原因可以归结为两个方面:一是使用了非线性激活函数(如sigmoid函数)导致梯度在传播过程中逐渐缩小;二是网络层数太多,梯度在多层传播中逐渐消失。
为了解决梯度消失问题,可以采用一些方法,如使用ReLU等更稳定的激活函数、使用批归一化等技术来增加梯度传播的稳定性、或者使用更复杂的网络结构,如残差网络(ResNet)和高速公路网络(Highway Network)等来保持梯度的传播。
比如:
假设你要走到一个很远的地方,路上有很多山丘,你需要爬上去才能继续前进。每爬一个山丘,你需要的力量就会变弱,但你可以通过喝水和休息来恢复体力。但是如果有些山丘太高了,你就需要爬很久才能到达山顶,可能会累到无法再前进了。
在神经网络中,我们需要计算梯度来调整网络中的权重,这个梯度就像是你需要的力量,它要通过每一层神经元传递下去。但是,如果网络太深了,每一层神经元都会削弱梯度的力量,最终梯度可能会变得非常小,无法更新权重,这就是梯度消失。
所以,我们需要设计合适的神经网络结构,来避免梯度消失的问题,使得我们可以训练更深的神经网络来解决更复杂的问题。
七、什么是AUC
AUC (Area Under Curve)是 ROC 曲线(Receiver Operating Characteristic curve)下的面积,指分类模型评估中的一个常用指标。ROC 曲线是一种用于描述二元分类器模型在所有分类阈值上性能的图形。通过计算 ROC 曲线下的面积,我们可以得到 AUC 值,用来衡量分类模型的优劣程度。AUC 的取值范围在 0 到 1 之间,AUC 值越接近 1,表示分类模型的性能越好。
参考文献
https://blog.csdn.net/qq_26274961/article/details/120701314
https://www.cnblogs.com/pinard/p/9128682.html#commentform
https://blog.csdn.net/weixin_46099084/article/details/109011670
https://blog.csdn.net/qq_26274961/article/details/120701314
https://www.cnblogs.com/linglanhuakai/p/14318807.html
https://www.bilibili.com/video/BV1xX4y1o7xY/?spm_id_from=333.337.search-card.all.click&vd_source=ce838d56b689e47d2bdd968af2d91d20
















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











