







目录
一、研究背景
在推荐系统中使用神经网络进行协同过滤。传统的协同过滤方法,如矩阵分解,已经被广泛应用于推荐系统中。然而,它们通常依赖于线性模型,可能无法捕捉用户和物品之间复杂的非线性关系。本文旨在探索深度学习和神经网络在改善协同过滤性能方面的潜力。
论文地址:NeuMF
数据集:MovieLens、Pinterest
代码地址:NeuMF
二、相关知识
1、GFM(广义矩阵分解)模型:
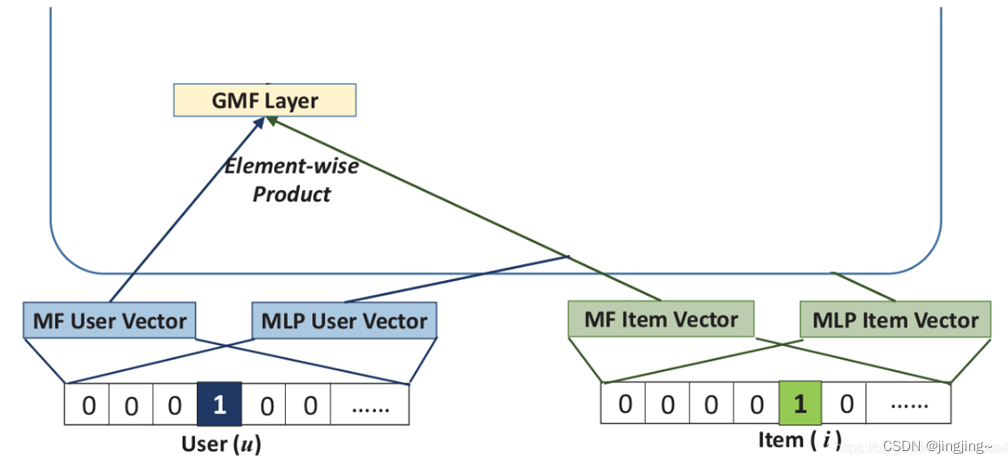
从论文中的解释看,user和item都通过one-hot编码得到稀疏向量,然后通过一个embedding层映射为user vector和item vector。这样就获得了user和item的隐向量,就可以使用哈达马积(Element-wise Produce)来交互user和item向量了。
2、One-hot编码
One-hot编码是一种常见的特征编码技术,用于将离散的分类特征转换为机器学习模型能够理解的数字表示。例如,如果我们有一个特征"颜色",可能的取值有"红色"、“蓝色"和"绿色”。使用独热编码,我们可以将"红色"表示为[1, 0, 0],"蓝色"表示为[0, 1, 0],"绿色"表示为[0, 0, 1]。
3、embedding层
嵌入层(embedding)是一种将高维离散数据映射到低维连续向量空间的技术。比如,在推荐系统中,将用户和物品表示为嵌入向量,可以更好地捕捉用户和物品之间的关联性。
优点:是能够减少特征的维度,去除离散数据的无序性,并且将相关的实体映射到相似的向量空间位置。这些嵌入向量可以作为机器学习模型的输入,从而提高模型的表现和泛化能力(指机器学习模型在未见过的数据上的表现能力)。
4、哈达马积
B=[[5,6],[7,8]]
A ⊙ B = [[1 5, 2 6], [3 7, 4 8]] = [[5, 12], [21, 32]]
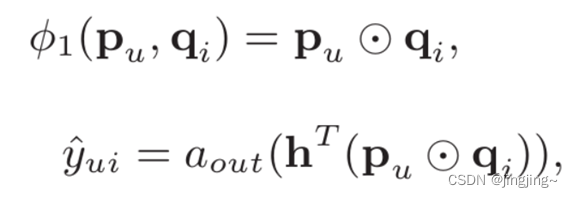
5、MLP(多层感知机)模型:
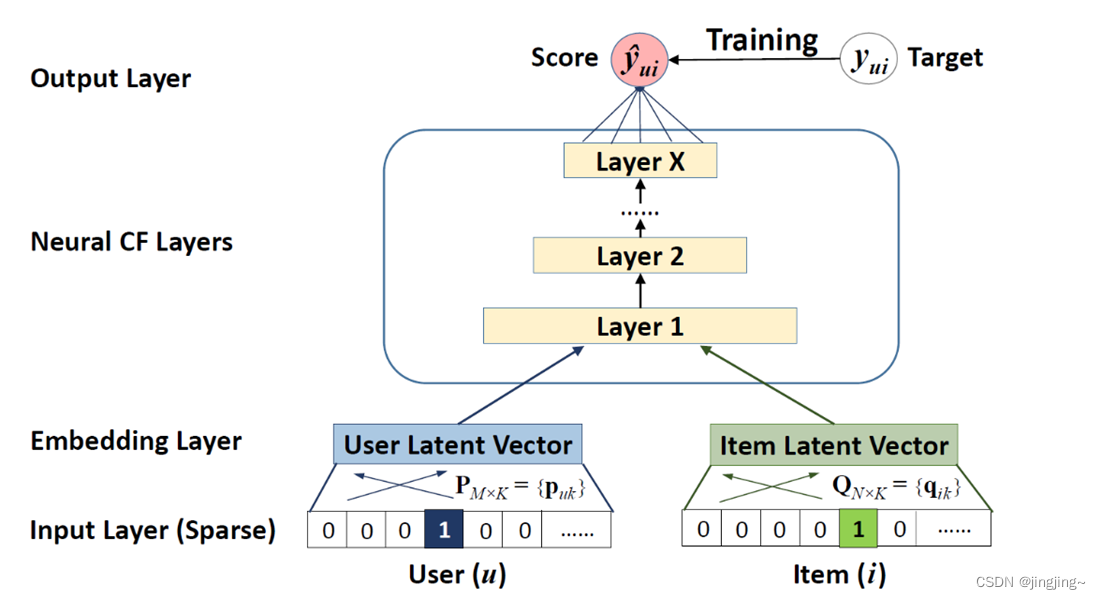
Output Layer:最终输出只有一个值,离1越近表示user可能越喜欢这个item。与y ^ u i 进行比较后,将损失进行反向传播,优化整个模型。 其Embedding层和InputLayer和GMF一样。Neural CF Layers使用的激活函数为ReLU。
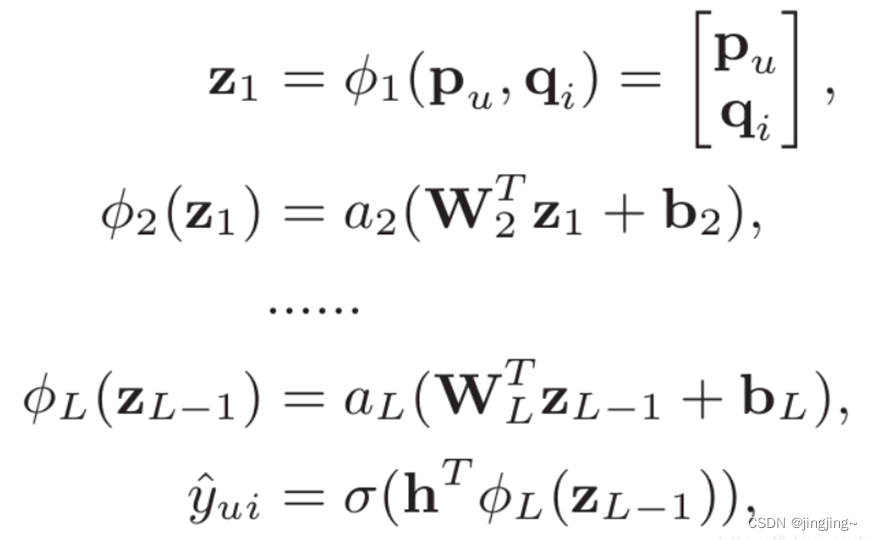
6、激活函数ReLU
使用的激活函数ReLU函数:对于大于零的输入,输出等于输入;对于小于等于零的输入,输出为零。ReLU函数通常具有更好的计算效率和收敛性。
7、NeuMF模型:
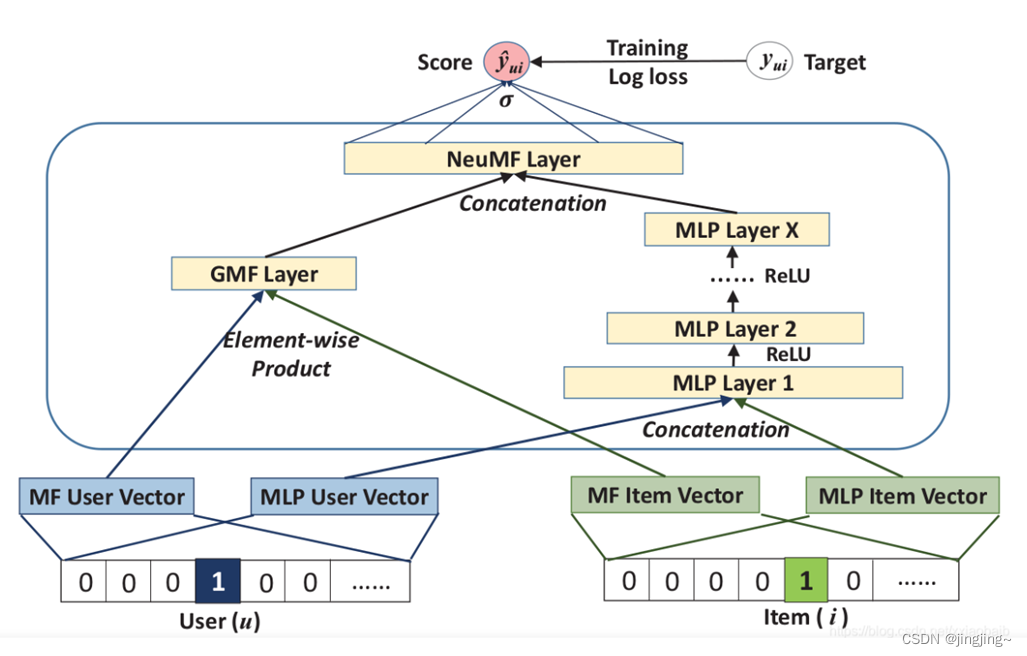
对分开的两部分进行融合。如下式所示:
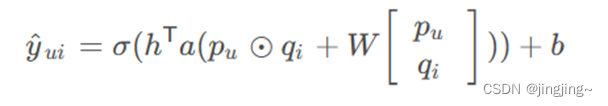
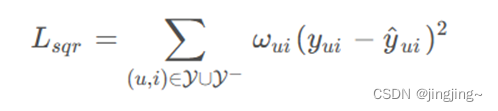
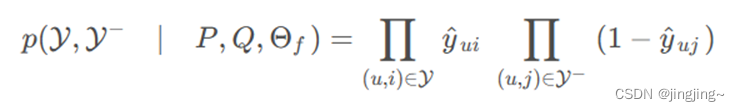
对似然函数取对数后取反,可以得到最小化的目标函数如下:
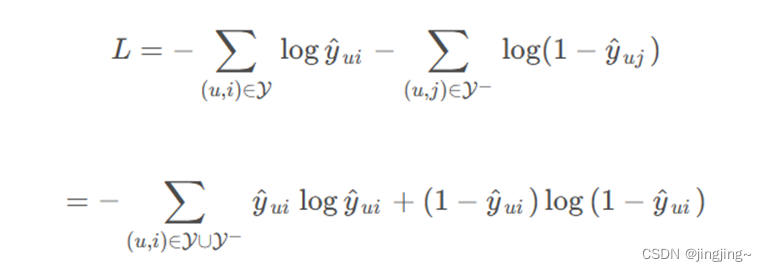
三、研究方法
1、留白评估法
留白评估法是一种评估人工智能系统或算法的方法。它的主要目的是在没有先验知识或预设条件下,评估系统在面对新情境或未知数据时的表现和能力。
基本思想:是将训练好的模型或系统应用于新的测试集或数据,并观察其在未知情境下的行为和输出。与传统的评估方法不同,留白评估法强调系统在面对新情境时的鲁棒性和泛化能力。
2、数据集划分
数据集的划分采用负采率的方式:是指在训练二分类模型时,为了平衡正向样本和负向样本的比例,从负向样本中采样的比例。
3、数据集介绍
(1)MovieLens 1M,是MovieLens数据集中的一个版本,包含了100多万条用户对电影的评分数据。包括:用户评分数据,电影信息和用户信息。
(2) Pinterest是一个全球知名的图片分享和发现平台,用户可以通过Pinterest来收集、组织和分享自己喜欢的图片和视觉内容。
四、实现结果(论文详细结果可看原文)
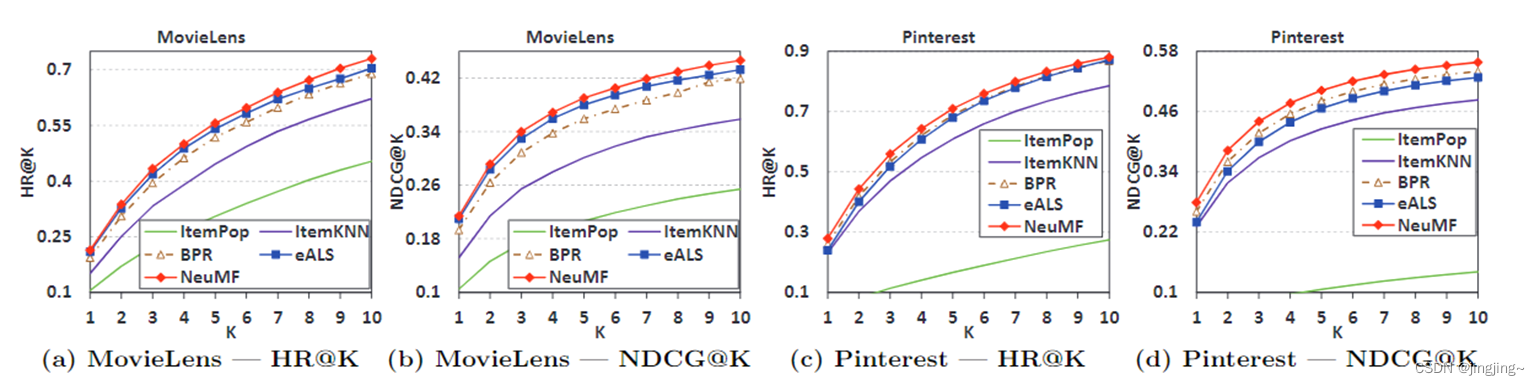
1、Top-K项目推荐
Top-K项目推荐是一种常见的推荐系统方法,它旨在根据用户的兴趣和偏好,为用户推荐最适合他们的前K个项目或物品。
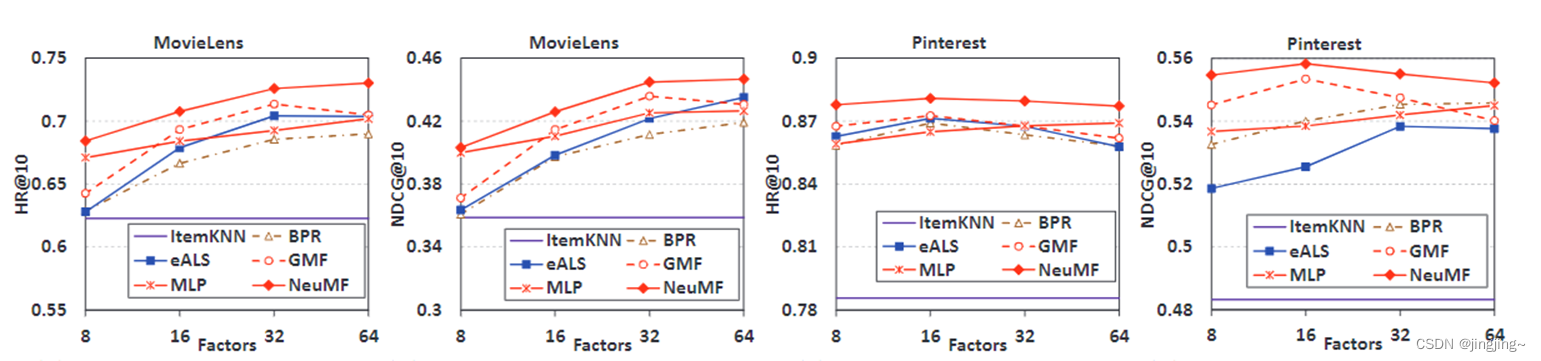

NCF方法的训练损失和推荐性能与MovieLens的迭代次数有关(系数为8)
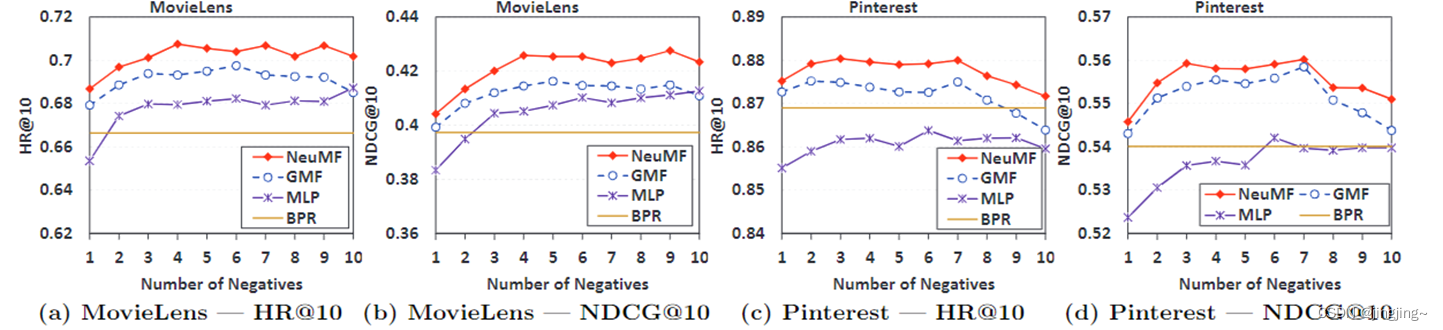
NCF方法的性能与每个阳性实例的阴性样本数量有关(factors=16)。图中还显示了BPR的性能,它只对一个负面实例进行采样,与一个正面实例配对学习。具有较大采样率的BPR。这表明点式对数损失比成对的BPR损失更有优势。对于这两个数据集,最佳采样率大约是3到6。在Pinterest上,我们发现当采样率大于7时,NCF方法的性能开始下降。它显示,过于积极地设置采样率可能会对性能产生不利影响。
不同层的MLP的HR上和NDCG下 K=10
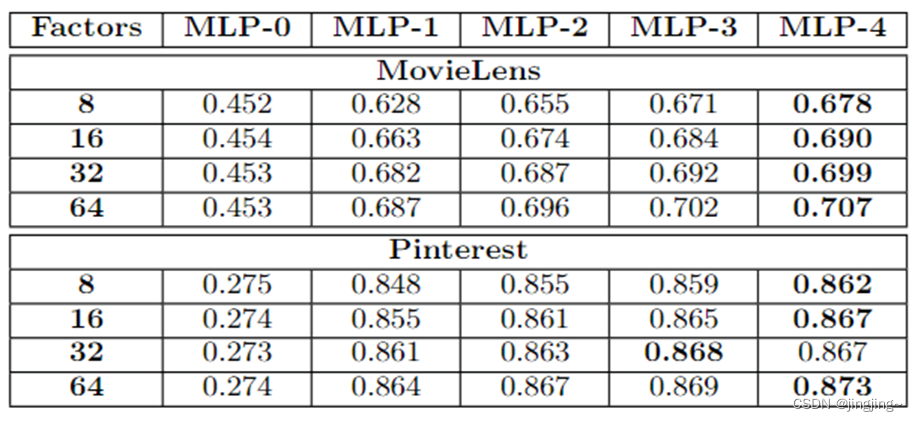
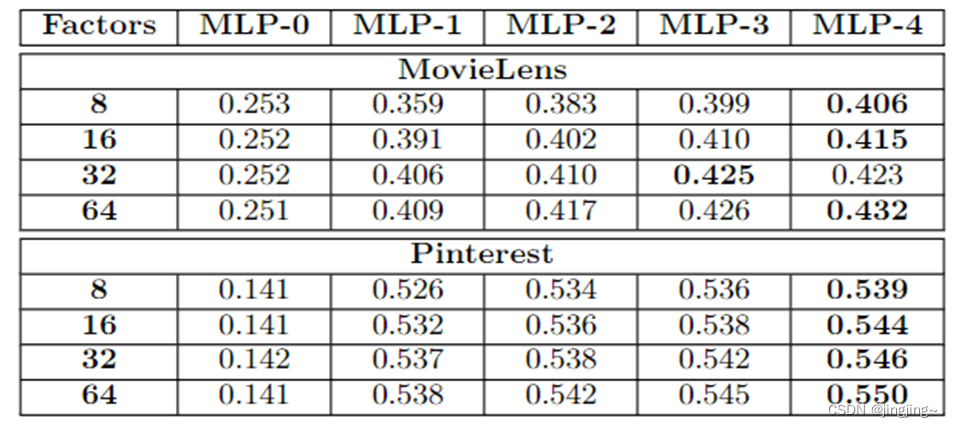
五、本人代码运行结果
论文作者原代码:https://github.com/hexiangnan/neural_collaborative_filtering
由于这份代码使用的python2.,keras的版本也是1.0.7,一直配置不好,遂使用他的代码,代码链接:https://github.com/wyl6/Recommender-Systems-Samples/tree/master/RecSys%20And%20Deep%20Learning/DNN/ncf。博客链接:
(1条消息) 基于深度学习的推荐(一):神经协同过滤NCF_神经协同过滤算法与协同过滤的区别_如雨星空的博客-CSDN博客
但是由于版本的更新,我对于上述代码进行了进一步的修改使用的是keras 2.10.0和theano 1.0.5版本, 完整代码已上传GitHub(Xian-Gang/NCF (github.com))和csdn的资源区域。
部分代码
GMF代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 14 14:07:54 2023
@author: Lenovo
"""
import numpy as np
import theano.tensor as T
import tensorflow.keras as keras
from keras import backend as K
from keras import initializers
from keras.models import Sequential, Model, load_model, save_model
from keras.layers import Add, Embedding, Input, Reshape, Flatten, Multiply
from keras.layers.core import Dense, Lambda, Activation
from keras.optimizers import Adagrad, Adam, SGD, RMSprop
from keras.regularizers import l2
from Dataset import Dataset
from evaluate import evaluate_model
from time import time
import multiprocessing as mp
import sys
import math
import argparse
import warnings
warnings.filterwarnings("ignore")
# In[1]:arguments
#################### Arguments ####################
def parse_args():
parser = argparse.ArgumentParser(description='Run GMF')
parser.add_argument('--path', nargs='?', default='Data/', help='Input data path')
parser.add_argument('--dataset', nargs='?', default='ml-1m', help='Choose a dataset.')
parser.add_argument('--epochs', type=int, default=1, help='Number of epochs.')
parser.add_argument('--batch_size', type=int, default=256, help='Batch size.')
parser.add_argument('--num_factors', type=int, default=8, help='Embedding size.')
parser.add_argument('--regs', nargs='?', default='[0,0]', help="Regularization for user and item embeddings.")
parser.add_argument('--num_neg', type=int, default=4, help='Number of negative instances to pair with a positive instance.')
parser.add_argument('--lr', type=float, default=0.001, help='Learning rate.')
parser.add_argument('--learner', nargs='?', default='adam', help='Specify an optimizer: adagrad, adam, rmsprop, sgd')
parser.add_argument('--verbose', type=int, default=1, help='Show performance per X iterations')
parser.add_argument('--out', type=int, default=1, help='Whether to save the trained model.')
return parser.parse_args()
def get_model(num_users, num_items, latent_dim, regs=[0,0]):
user_input = Input(shape=(1,), dtype='int32', name='user_input')
item_input = Input(shape=(1,), dtype='int32', name='item_input')
MF_Embedding_User = Embedding(input_dim=num_users, output_dim=latent_dim, name='user_embedding',
embeddings_regularizer = l2(regs[0]), input_length=1)
MF_Embedding_Item = Embedding(input_dim=num_items, output_dim=latent_dim, name='item_embedding',
embeddings_regularizer = l2(regs[1]), input_length=1)
user_latent = Flatten()(MF_Embedding_User(user_input))
item_latent = Flatten()(MF_Embedding_Item(item_input))
predict_vector = Multiply()([user_latent, item_latent])
prediction = Dense(1, activation='sigmoid', kernel_initializer='lecun_uniform', name = 'prediction')(predict_vector)
model = Model(inputs=[user_input, item_input], outputs=prediction)
return model
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [], [], []
num_items = train.shape[1]
for u, i in train.keys():
user_input.append(u)
item_input.append(i)
labels.append(1)
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u,j) in train:
j = np.random.randint(num_items)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
# In[2]: configure parameters
if(__name__ == '__main__'):
args = parse_args()
num_factors = args.num_factors
regs = eval(args.regs);print('regs', regs)
num_negatives = args.num_neg
learner = args.learner
learning_rate = args.lr
epochs = args.epochs
batch_size = args.batch_size
verbose = args.verbose
topK = 10
evaluation_threads = 1
print('GMF arguments: %s' % (args))
model_out_file = 'Pretrain/%s_GMF_%d_%d.h5' %(args.dataset, num_factors, time())
# In[3]: load datasets
t1 = time()
dataset = Dataset(args.path + args.dataset)
train, testRatings, testNegatives = dataset.trainMatrix, dataset.testRatings, dataset.testNegatives
num_users, num_items = train.shape
print("Load data done [%.1f s]. #user=%d, #item=%d, #train=%d, #test=%d"
%(time()-t1, num_users, num_items, train.nnz, len(testRatings)))
# In[4]: build model
model = get_model(num_users, num_items, num_factors, regs)
if learner.lower() == "adagrad":
model.compile(optimizer=Adagrad(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "rmsprop":
model.compile(optimizer=RMSprop(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "adam":
model.compile(optimizer=Adam(lr=learning_rate), loss='binary_crossentropy')
else:
model.compile(optimizer=SGD(lr=learning_rate), loss='binary_crossentropy')
#print(model.summary())
# In[4]: trian and test
# Init performance
t1 = time()
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR = %.4f, NDCG = %.4f\t [%.1f s]' % (hr, ndcg, time()-t1))
# train model
best_hr, best_ndcg, best_iter = hr, ndcg, -1
for epoch in range(epochs):
t1 = time()
user_input, item_input, labels = get_train_instances(train, num_negatives)
hist = model.fit([np.array(user_input), np.array(item_input)], #input
np.array(labels), # labels
batch_size=batch_size, epochs=1, verbose=0, shuffle=True)
t2 = time()
if epoch %verbose == 0:
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg, loss = np.array(hits).mean(), np.array(ndcgs).mean(), hist.history['loss'][0]
print('Iteration %d [%.1f s]: HR = %.4f, NDCG = %.4f, loss = %.4f [%.1f s]'
% (epoch, t2-t1, hr, ndcg, loss, time()-t2))
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
if args.out > 0:
model.save_weights(model_out_file, overwrite=True)
print("End. Best Iteration %d: HR = %.4f, NDCG = %.4f. " %(best_iter, best_hr, best_ndcg))
if args.out > 0:
print("The best GMF model is saved to %s" %(model_out_file))MLP代码:
'''
Created on Aug 9, 2016
Keras Implementation of Multi-Layer Perceptron (GMF) recommender model in:
He Xiangnan et al. Neural Collaborative Filtering. In WWW 2017.
@author: Xiangnan He (xiangnanhe@gmail.com)
'''
import numpy as np
import theano
import theano.tensor as T
import keras
from keras import backend as K
from keras import initializers as initializations
from keras.regularizers import l2
from keras.models import Sequential, Model
from keras.layers.core import Dense, Lambda, Activation
from keras.layers import Embedding, Input, Dense, Add, Reshape, Flatten, Dropout, Concatenate
from keras.constraints import maxnorm
from keras.optimizers import Adagrad, Adam, SGD, RMSprop
from evaluate import evaluate_model
from Dataset import Dataset
from time import time
import sys
import argparse
import multiprocessing as mp
#################### Arguments ####################
def parse_args():
parser = argparse.ArgumentParser(description="Run MLP.")
parser.add_argument('--path', nargs='?', default='Data/',
help='Input data path.')
parser.add_argument('--dataset', nargs='?', default='ml-1m',
help='Choose a dataset.')
parser.add_argument('--epochs', type=int, default=1,
help='Number of epochs.')
parser.add_argument('--batch_size', type=int, default=256,
help='Batch size.')
parser.add_argument('--layers', nargs='?', default='[64,32,16,8]',
help="Size of each layer. Note that the first layer is the concatenation of user and item embeddings. So layers[0]/2 is the embedding size.")
parser.add_argument('--reg_layers', nargs='?', default='[0,0,0,0]',
help="Regularization for each layer")
parser.add_argument('--num_neg', type=int, default=4,
help='Number of negative instances to pair with a positive instance.')
parser.add_argument('--lr', type=float, default=0.001,
help='Learning rate.')
parser.add_argument('--learner', nargs='?', default='adam',
help='Specify an optimizer: adagrad, adam, rmsprop, sgd')
parser.add_argument('--verbose', type=int, default=1,
help='Show performance per X iterations')
parser.add_argument('--out', type=int, default=1,
help='Whether to save the trained model.')
return parser.parse_args()
def get_model(num_users, num_items, layers = [20,10], reg_layers=[0,0]):
assert len(layers) == len(reg_layers)
num_layer = len(layers) #Number of layers in the MLP
# Input variables
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
MLP_Embedding_User = Embedding(input_dim = num_users, output_dim = int(layers[0]/2), name = 'user_embedding',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = num_items, output_dim = int(layers[0]/2), name = 'item_embedding',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
# Crucial to flatten an embedding vector!
user_latent = Flatten()(MLP_Embedding_User(user_input))
item_latent = Flatten()(MLP_Embedding_Item(item_input))
# The 0-th layer is the concatenation of embedding layers
vector = Concatenate(axis=-1)([user_latent, item_latent])
# MLP layers
for idx in range(1, num_layer):
layer = Dense(layers[idx], kernel_regularizer= l2(reg_layers[idx]), activation='relu', name = 'layer%d' %idx)
vector = layer(vector)
# Final prediction layer
prediction = Dense(1, activation='sigmoid', kernel_initializer='lecun_uniform', name = 'prediction')(vector)
model = Model(inputs=[user_input, item_input],
outputs=prediction)
return model
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [],[],[]
num_items = train.shape[1]
for (u, i) in train.keys():
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u, j) in train:
j = np.random.randint(num_items)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
if __name__ == '__main__':
args = parse_args()
path = args.path
dataset = args.dataset
layers = eval(args.layers)
print(layers, type(layers[0]))
reg_layers = eval(args.reg_layers)
print(reg_layers, type(reg_layers[0]))
num_negatives = args.num_neg
learner = args.learner
learning_rate = args.lr
batch_size = args.batch_size
epochs = args.epochs
verbose = args.verbose
topK = 10
evaluation_threads = 1 #mp.cpu_count()
print("MLP arguments: %s " %(args))
model_out_file = 'Pretrain/%s_MLP_%s_%d.h5' %(args.dataset, args.layers, time())
# Loading data
t1 = time()
dataset = Dataset(args.path + args.dataset)
train, testRatings, testNegatives = dataset.trainMatrix, dataset.testRatings, dataset.testNegatives
num_users, num_items = train.shape
print("Load data done [%.1f s]. #user=%d, #item=%d, #train=%d, #test=%d"
%(time()-t1, num_users, num_items, train.nnz, len(testRatings)))
# Build model
model = get_model(num_users, num_items, layers, reg_layers)
if learner.lower() == "adagrad":
model.compile(optimizer=Adagrad(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "rmsprop":
model.compile(optimizer=RMSprop(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "adam":
model.compile(optimizer=Adam(lr=learning_rate), loss='binary_crossentropy')
else:
model.compile(optimizer=SGD(lr=learning_rate), loss='binary_crossentropy')
# Check Init performance
t1 = time()
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR = %.4f, NDCG = %.4f [%.1f]' %(hr, ndcg, time()-t1))
# Train model
best_hr, best_ndcg, best_iter = hr, ndcg, -1
for epoch in range(epochs):
t1 = time()
# Generate training instances
user_input, item_input, labels = get_train_instances(train, num_negatives)
# Training
hist = model.fit([np.array(user_input), np.array(item_input)], #input
np.array(labels), # labels
batch_size=batch_size, epochs=1, verbose=0, shuffle=True)
t2 = time()
# Evaluation
if epoch %verbose == 0:
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg, loss = np.array(hits).mean(), np.array(ndcgs).mean(), hist.history['loss'][0]
print('Iteration %d [%.1f s]: HR = %.4f, NDCG = %.4f, loss = %.4f [%.1f s]'
% (epoch, t2-t1, hr, ndcg, loss, time()-t2))
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
if args.out > 0:
model.save_weights(model_out_file, overwrite=True)
print("End. Best Iteration %d: HR = %.4f, NDCG = %.4f. " %(best_iter, best_hr, best_ndcg))
if args.out > 0:
print("The best MLP model is saved to %s" %(model_out_file))NeuMF代码
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 14 21:51:58 2023
@author: Lenovo
"""
'''
Created on Aug 9, 2016
Keras Implementation of Neural Matrix Factorization (NeuMF) recommender model in:
He Xiangnan et al. Neural Collaborative Filtering. In WWW 2017.
@author: Xiangnan He (xiangnanhe@gmail.com)
'''
import numpy as np
import theano
import theano.tensor as T
import keras
from keras import backend as K
from keras.regularizers import l1, l2, l1_l2
from keras.models import Sequential, Model
from keras.layers.core import Dense, Lambda, Activation
from keras.layers import Embedding, Input, Dense, concatenate, Reshape, Multiply, Flatten, Dropout, Concatenate
from keras.optimizers import Adagrad, Adam, SGD, RMSprop
from evaluate import evaluate_model
from Dataset import Dataset
from time import time
import sys
import GMF, MLP
import argparse
# In[1]: parameters
#################### Arguments ####################
def parse_args():
parser = argparse.ArgumentParser(description="Run NeuMF.")
parser.add_argument('--path', nargs='?', default='Data/',
help='Input data path.')
parser.add_argument('--dataset', nargs='?', default='ml-1m',
help='Choose a dataset.')
parser.add_argument('--epochs', type=int, default=1,
help='Number of epochs.')
parser.add_argument('--batch_size', type=int, default=256,
help='Batch size.')
parser.add_argument('--num_factors', type=int, default=8,
help='Embedding size of MF model.')
parser.add_argument('--layers', nargs='?', default='[64,32,16,8]',
help="MLP layers. Note that the first layer is the concatenation of user and item embeddings. So layers[0]/2 is the embedding size.")
parser.add_argument('--reg_mf', type=float, default=0,
help='Regularization for MF embeddings.')
parser.add_argument('--reg_layers', nargs='?', default='[0,0,0,0]',
help="Regularization for each MLP layer. reg_layers[0] is the regularization for embeddings.")
parser.add_argument('--num_neg', type=int, default=4,
help='Number of negative instances to pair with a positive instance.')
parser.add_argument('--lr', type=float, default=0.001,
help='Learning rate.')
parser.add_argument('--learner', nargs='?', default='adam',
help='Specify an optimizer: adagrad, adam, rmsprop, sgd')
parser.add_argument('--verbose', type=int, default=1,
help='Show performance per X iterations')
parser.add_argument('--out', type=int, default=1,
help='Whether to save the trained model.')
parser.add_argument('--mf_pretrain', nargs='?', default='',
help='Specify the pretrain model file for MF part. If empty, no pretrain will be used')
parser.add_argument('--mlp_pretrain', nargs='?', default='',
help='Specify the pretrain model file for MLP part. If empty, no pretrain will be used')
return parser.parse_args()
# In[2]: model
def get_model(num_users, num_items, mf_dim=10, layers=[10], reg_layers=[0], reg_mf=0):
assert len(layers) == len(reg_layers)
num_layer = len(layers) #Number of layers in the MLP
# Input variables
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
# Embedding layer
MF_Embedding_User = Embedding(input_dim = num_users, output_dim = mf_dim, name = 'mf_embedding_user',
embeddings_regularizer = l2(reg_mf), input_length=1)
MF_Embedding_Item = Embedding(input_dim = num_items, output_dim = mf_dim, name = 'mf_embedding_item',
embeddings_regularizer = l2(reg_mf), input_length=1)
MLP_Embedding_User = Embedding(input_dim = num_users, output_dim = int(layers[0]/2), name = "mlp_embedding_user",
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = num_items, output_dim = int(layers[0]/2), name = 'mlp_embedding_item',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
# MF part
mf_user_latent = Flatten()(MF_Embedding_User(user_input))
mf_item_latent = Flatten()(MF_Embedding_Item(item_input))
mf_vector = Multiply()([mf_user_latent, mf_item_latent]) # element-wise multiply
# MLP part
mlp_user_latent = Flatten()(MLP_Embedding_User(user_input))
mlp_item_latent = Flatten()(MLP_Embedding_Item(item_input))
mlp_vector = Concatenate(axis = 1)([mlp_user_latent, mlp_item_latent])
for idx in range(1, num_layer):
layer = Dense(layers[idx], kernel_regularizer= l2(reg_layers[idx]), activation='relu', name="layer%d" %idx)
mlp_vector = layer(mlp_vector)
# Concatenate MF and MLP parts
#mf_vector = Lambda(lambda x: x * alpha)(mf_vector)
#mlp_vector = Lambda(lambda x : x * (1-alpha))(mlp_vector)
predict_vector = Concatenate(axis = -1)([mf_vector, mlp_vector])
# Final prediction layer
prediction = Dense(1, activation='sigmoid', kernel_initializer='lecun_uniform', name = "prediction")(predict_vector)
model = Model(inputs=[user_input, item_input],
outputs=prediction)
return model
def load_pretrain_model(model, gmf_model, mlp_model, num_layers):
# MF embeddings
gmf_user_embeddings = gmf_model.get_layer('user_embedding').get_weights()
gmf_item_embeddings = gmf_model.get_layer('item_embedding').get_weights()
model.get_layer('mf_embedding_user').set_weights(gmf_user_embeddings)
model.get_layer('mf_embedding_item').set_weights(gmf_item_embeddings)
# MLP embeddings
mlp_user_embeddings = mlp_model.get_layer('user_embedding').get_weights()
mlp_item_embeddings = mlp_model.get_layer('item_embedding').get_weights()
model.get_layer('mlp_embedding_user').set_weights(mlp_user_embeddings)
model.get_layer('mlp_embedding_item').set_weights(mlp_item_embeddings)
# MLP layers
for i in range(1, num_layers):
mlp_layer_weights = mlp_model.get_layer('layer%d' %i).get_weights()
model.get_layer('layer%d' %i).set_weights(mlp_layer_weights)
# Prediction weights
gmf_prediction = gmf_model.get_layer('prediction').get_weights()
mlp_prediction = mlp_model.get_layer('prediction').get_weights()
new_weights = np.concatenate((gmf_prediction[0], mlp_prediction[0]), axis=0)
new_b = gmf_prediction[1] + mlp_prediction[1]
print('new_b.shape', new_b.shape)
model.get_layer('prediction').set_weights([0.5*new_weights, 0.5*new_b])
return model
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [],[],[]
num_items = train.shape[1]
for (u, i) in train.keys():
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u, j) in train:
j = np.random.randint(num_items)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
# In[3]:
if __name__ == '__main__':
args = parse_args()
num_epochs = args.epochs
batch_size = args.batch_size
mf_dim = args.num_factors
layers = eval(args.layers)
reg_mf = args.reg_mf
reg_layers = eval(args.reg_layers)
num_negatives = args.num_neg
learning_rate = args.lr
learner = args.learner
verbose = args.verbose
mf_pretrain = args.mf_pretrain
mlp_pretrain = args.mlp_pretrain
topK = 10
evaluation_threads = 1#mp.cpu_count()
print("NeuMF arguments: %s " %(args))
model_out_file = 'Pretrain/%s_NeuMF_%d_%s_%d.h5' %(args.dataset, mf_dim, args.layers, time())
# Loading data
t1 = time()
dataset = Dataset(args.path + args.dataset)
train, testRatings, testNegatives = dataset.trainMatrix, dataset.testRatings, dataset.testNegatives
num_users, num_items = train.shape
print("Load data done [%.1f s]. #user=%d, #item=%d, #train=%d, #test=%d"
%(time()-t1, num_users, num_items, train.nnz, len(testRatings)))
# Build model
model = get_model(num_users, num_items, mf_dim, layers, reg_layers, reg_mf)
if learner.lower() == "adagrad":
model.compile(optimizer=Adagrad(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "rmsprop":
model.compile(optimizer=RMSprop(lr=learning_rate), loss='binary_crossentropy')
elif learner.lower() == "adam":
model.compile(optimizer=Adam(lr=learning_rate), loss='binary_crossentropy')
else:
model.compile(optimizer=SGD(lr=learning_rate), loss='binary_crossentropy')
# Load pretrain model
if mf_pretrain != '' and mlp_pretrain != '':
gmf_model = GMF.get_model(num_users,num_items,mf_dim)
gmf_model.load_weights(mf_pretrain)
mlp_model = MLP.get_model(num_users,num_items, layers, reg_layers)
mlp_model.load_weights(mlp_pretrain)
model = load_pretrain_model(model, gmf_model, mlp_model, len(layers))
print("Load pretrained GMF (%s) and MLP (%s) models done. " %(mf_pretrain, mlp_pretrain))
# Init performance
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR = %.4f, NDCG = %.4f' % (hr, ndcg))
best_hr, best_ndcg, best_iter = hr, ndcg, -1
if args.out > 0:
model.save_weights(model_out_file, overwrite=True)
# Training model
for epoch in range(num_epochs):
t1 = time()
# Generate training instances
user_input, item_input, labels = get_train_instances(train, num_negatives)
# Training
hist = model.fit([np.array(user_input), np.array(item_input)], #input
np.array(labels), # labels
batch_size=batch_size, epochs=1, verbose=0, shuffle=True)
t2 = time()
# Evaluation
if epoch %verbose == 0:
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg, loss = np.array(hits).mean(), np.array(ndcgs).mean(), hist.history['loss'][0]
print('Iteration %d [%.1f s]: HR = %.4f, NDCG = %.4f, loss = %.4f [%.1f s]'
% (epoch, t2-t1, hr, ndcg, loss, time()-t2))
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
if args.out > 0:
model.save_weights(model_out_file, overwrite=True)
print("End. Best Iteration %d: HR = %.4f, NDCG = %.4f. " %(best_iter, best_hr, best_ndcg))
if args.out > 0:
print("The best NeuMF model is saved to %s" %(model_out_file))完整代码已上传GitHub(Xian-Gang/NCF (github.com))和csdn的资源区域。
1、GMF
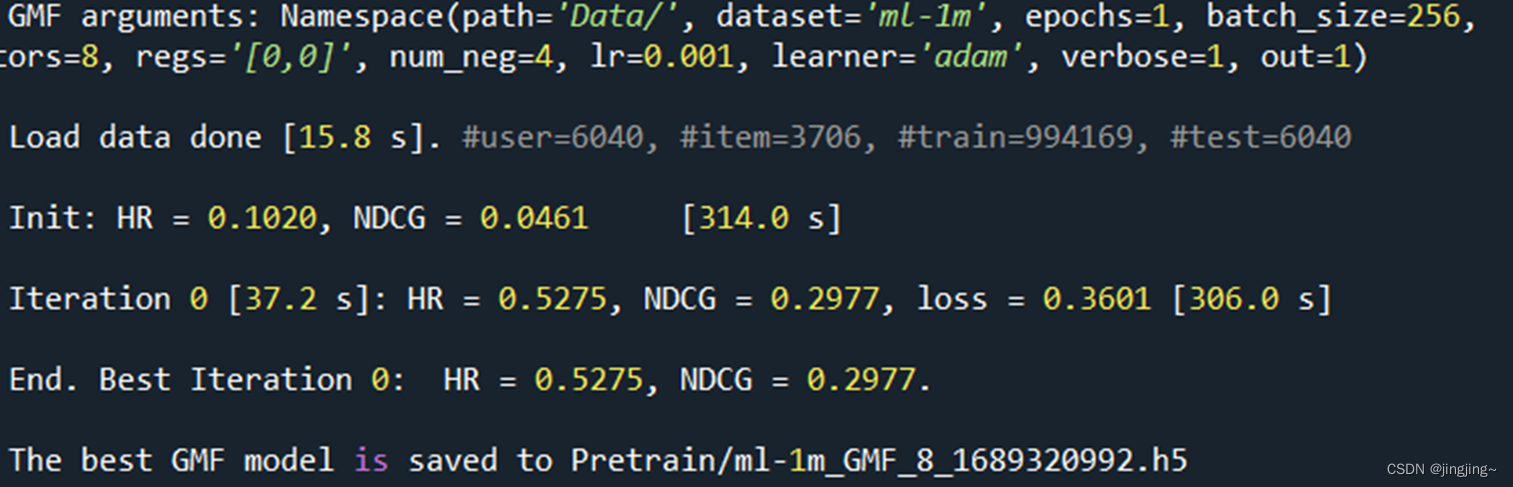
2、MLP
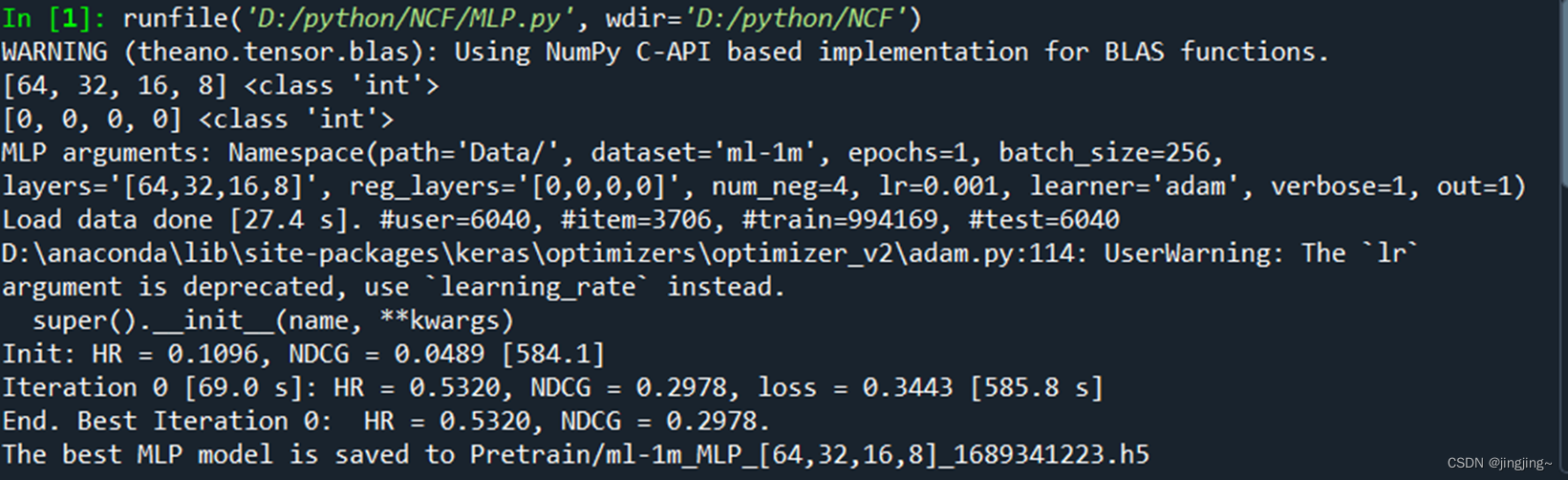
3、NeuMF
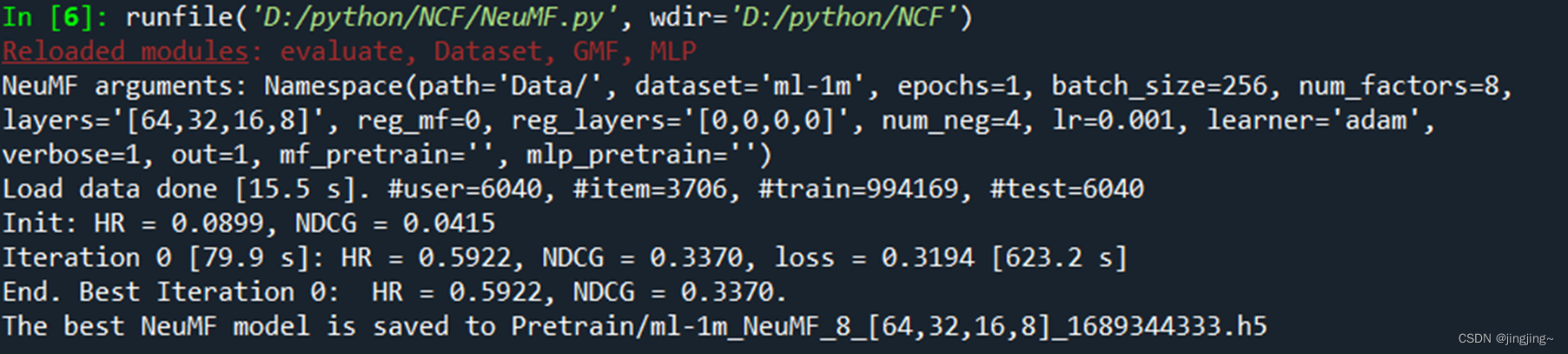
同时会产生对应的预训练文件:



















 1829
1829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











