







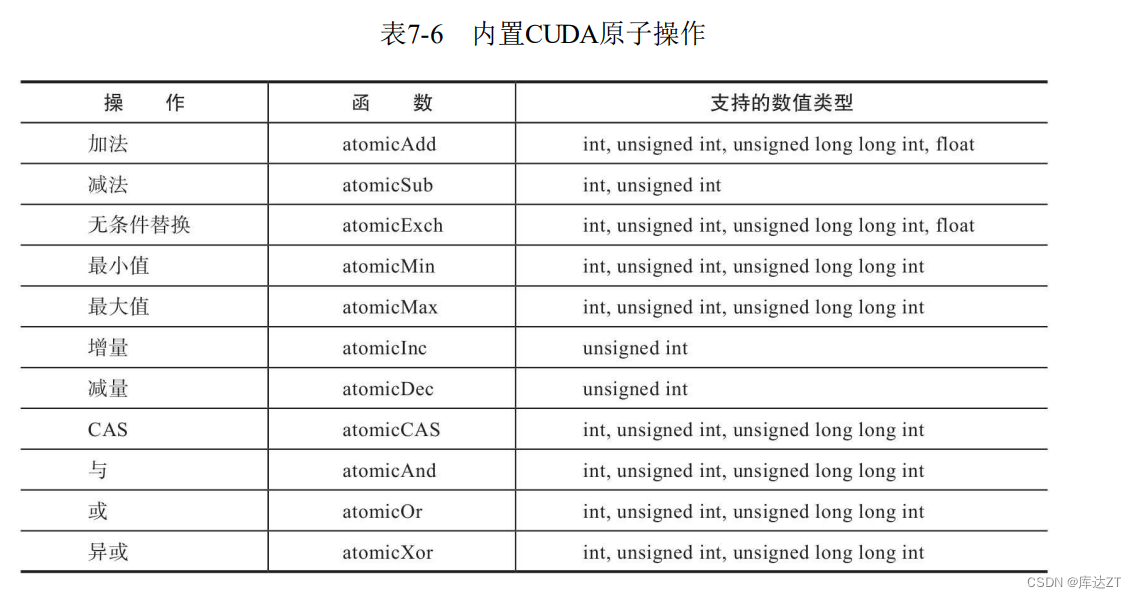
在本节中,将学习如何使用原子操作,并学习在高并发环境下的共享数据上如何执 行正确的操作。
通过使用一个原子函数,每个由CUDA提供的原子函数可以重复被执行:原子级比较并交换CAS运算符。原子级CAS是一个很重要的操作,不仅可以使你在CUDA中定义你自己的原子函数,还能帮助你更深层次地理解原子操作。
CAS将3个内容作为输入:内存地址,存储在此地址中的期望值,已经实际想要存储在此位置的新值;然后执行以下几步;
1. 读取目标地址并将该处地址的存储值与预期值进行比较。
a. 如果存储值与预期值相等,那么新值将存入目标位置。
b. 如果存储值与预期值不等,那么目标位置不会发生变化。
2. 不论发生什么情况,一个CAS操作总是返回目标地址中的值。注意,使用返回值可以来检查一个数值是否被替换成功。如果返回值等于传入的预期值,那么CAS操作一定成功了。
#include <stdio.h>
#include <stdlib.h>
#include "freshman.h"
#include "cuda_runtime_api.h"
__device__ int myAttomicAdd(int* address, int incr) {
int guess = *address;
int oldvalue = atomicCAS(address, guess, guess + incr);//address和guess如果相等就带入新值,不等则失败。
//在这里看应该是成功了,因为oldvalue目前的值与guess不等
while (oldvalue != guess)//如果不等,那就一直循环下去,直到相等或者超出次数退出
{
guess = oldvalue;
oldvalue = atomicCAS(address, guess, guess + incr);
}
return oldvalue;
}
__global__ void kernel(int* sharedInteger) {
myAttomicAdd(sharedInteger, 1);
}
int main(int argc, char** argv)
{
int h_sharedInteger;
int* d_sharedInteger;
CHECK(cudaMalloc((void**)&d_sharedInteger, sizeof(int)));
CHECK(cudaMemset(d_sharedInteger, 0x00, sizeof(int)));
kernel << <4, 128 >> > (d_sharedInteger);
CHECK(cudaMemcpy(&h_sharedInteger, d_sharedInteger, sizeof(int),
cudaMemcpyDeviceToHost));
printf("4 x 128 increments led to value of %d\n", h_sharedInteger);
return 0;
}当然每一次这样写都会很累,所以CUDA很贴心的内置了原子级操作
#include "freshman.h"
#include <stdio.h>
#include <stdlib.h>
/**
* This example illustrates the difference between using atomic operations and
* using unsafe accesses to increment a shared variable.
*
* In both the atomics() and unsafe() kernels, each thread repeatedly increments
* a globally shared variable by 1. Each thread also stores the value it reads
* from the shared location for the first increment.
**/
/**
* This version of the kernel uses atomic operations to safely increment a
* shared variable from multiple threads.
**/
__global__ void atomics(int* shared_var, int* values_read, int N, int iters)
{
int i;
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid >= N) return;
values_read[tid] = atomicAdd(shared_var, 1);
for (i = 0; i < iters; i++)
{
atomicAdd(shared_var, 1);
}
}
/**
* This version of the kernel performs the same increments as atomics() but in
* an unsafe manner.
**/
__global__ void unsafe(int* shared_var, int* values_read, int N, int iters)
{
int i;
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid >= N) return;
int old = *shared_var;
*shared_var = old + 1;
values_read[tid] = old;
for (i = 0; i < iters; i++)
{
int old = *shared_var;
*shared_var = old + 1;
}
}
/**
* Utility function for printing the contents of an array.
**/
static void print_read_results(int* h_arr, int* d_arr, int N,
const char* label)
{
int i;
int maxNumToPrint = 10;
int nToPrint = N > maxNumToPrint ? maxNumToPrint : N;
CHECK(cudaMemcpy(h_arr, d_arr, nToPrint * sizeof(int),
cudaMemcpyDeviceToHost));
printf("Threads performing %s operations read values", label);
for (i = 0; i < nToPrint; i++)
{
printf(" %d", h_arr[i]);
}
printf("\n");
}
int main(int argc, char** argv)
{
int N = 64;
int block = 32;
int runs = 30;
int iters = 100000;
int r;
int* d_shared_var;
int h_shared_var_atomic, h_shared_var_unsafe;
int* d_values_read_atomic;
int* d_values_read_unsafe;
int* h_values_read;
CHECK(cudaMalloc((void**)&d_shared_var, sizeof(int)));
CHECK(cudaMalloc((void**)&d_values_read_atomic, N * sizeof(int)));
CHECK(cudaMalloc((void**)&d_values_read_unsafe, N * sizeof(int)));
h_values_read = (int*)malloc(N * sizeof(int));
double atomic_mean_time = 0;
double unsafe_mean_time = 0;
/*for (r = 0; r < runs; r++)
{*/
double start_atomic = cpuSecond();
CHECK(cudaMemset(d_shared_var, 0x00, sizeof(int)));
atomics << <N / block, block >> > (d_shared_var, d_values_read_atomic, N,
iters);
CHECK(cudaDeviceSynchronize());
atomic_mean_time += cpuSecond() - start_atomic;
CHECK(cudaMemcpy(&h_shared_var_atomic, d_shared_var, sizeof(int),
cudaMemcpyDeviceToHost));
double start_unsafe = cpuSecond();
CHECK(cudaMemset(d_shared_var, 0x00, sizeof(int)));
unsafe << <N / block, block >> > (d_shared_var, d_values_read_unsafe, N,
iters);
CHECK(cudaDeviceSynchronize());
unsafe_mean_time += cpuSecond() - start_unsafe;
CHECK(cudaMemcpy(&h_shared_var_unsafe, d_shared_var, sizeof(int),
cudaMemcpyDeviceToHost));
/*}*/
printf("In total, %d runs using atomic operations took %f s\n",
runs, atomic_mean_time);
printf(" Using atomic operations also produced an output of %d\n",
h_shared_var_atomic);
printf("In total, %d runs using unsafe operations took %f s\n",
runs, unsafe_mean_time);
printf(" Using unsafe operations also produced an output of %d\n",
h_shared_var_unsafe);
print_read_results(h_values_read, d_values_read_atomic, N, "atomic");
print_read_results(h_values_read, d_values_read_unsafe, N, "unsafe");
return 0;
}这里当N等于64时,是有两个block,所以我们也不知道哪个线程会抢到前面,这里就是先走了28个线程才轮到我们所读取的第一个线程,所以第一个线程的值为29
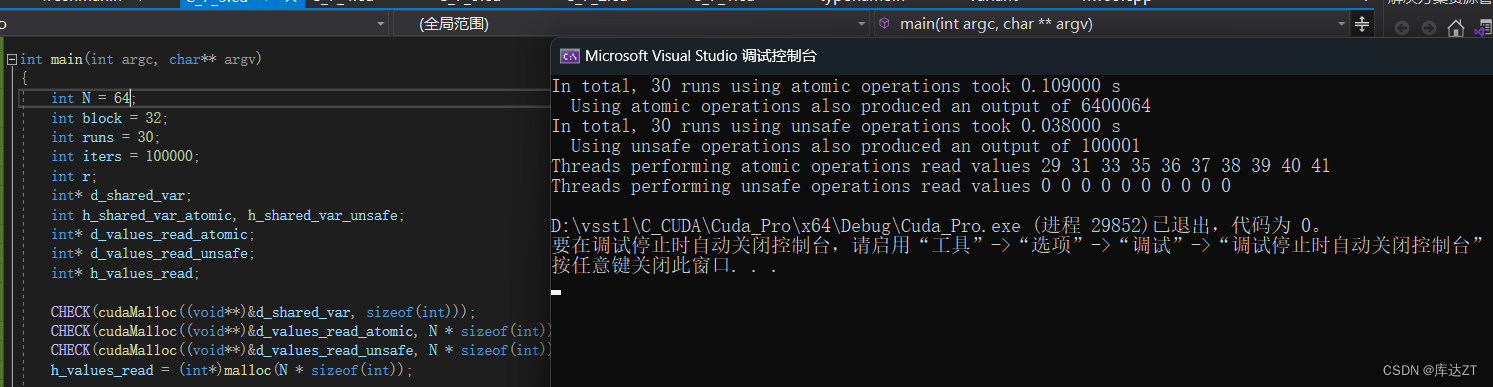

 可以看到每次的值都不固定,这就是因为很多线程都在同时使用,谁都不能保证这个线程肯定能抢到这个地址
可以看到每次的值都不固定,这就是因为很多线程都在同时使用,谁都不能保证这个线程肯定能抢到这个地址
而当N等于32之后,只有一个block了,不存在相互争夺了
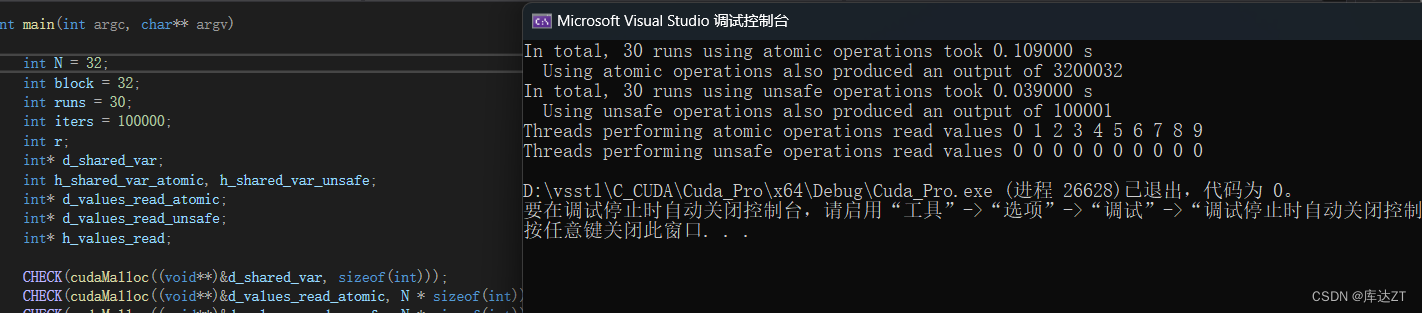
性能上的差异很明显:使用atomics版本的运行时间是unsafe运行时间的300倍还要 多。最终的输出说明不是所有在unsafe中执行的加法都会写入到全局内存中,许多是重写 的并且永远不会被其他线程所读取。
这个例子说明了当原子操作是必要的而不安全访问是一个选择项时,这将在很大程度 上降低性能和正确性。当做这个决定时必须非常小心,并不推荐使用不安全访问,应当只 有在能保证正确性的情况下才尝试使用不安全访问。
限制原子操作的性能成本
如何通过使用局部操作来增强全局原子操作的性能,并减少执行原子操作时所产生的锁竞争和延迟。其中提到了两种方法:
-
使用 shuffle 指令:shuffle 可以在同一线程块内进行操作,它将同一个向量中的元素进行重组,使得每个线程都可以读取到该向量中的不同位置的元素。因此,可以先把每个线程要执行的数据通过 shuffle 放入共享内存中,在操作完毕后再把结果通过原子操作放回主存。
-
使用共享内存:在同一线程块内可以使用共享内存来存储需要参与原子操作的变量或数组的局部结果,然后通过原子操作把每个线程块的局部结果合并成最终结果。
但无论使用哪种方法,为了确保最终的结果是正确的,需要满足以下条件:
-
操作必须是可替换的,即操作顺序不会影响最终的结果。
-
操作结果必须通过原子操作将结果最终合并到主存中。
-
同一次操作中不能有竞争发生,即所有线程都只需要读取和写入自己部分的数据。
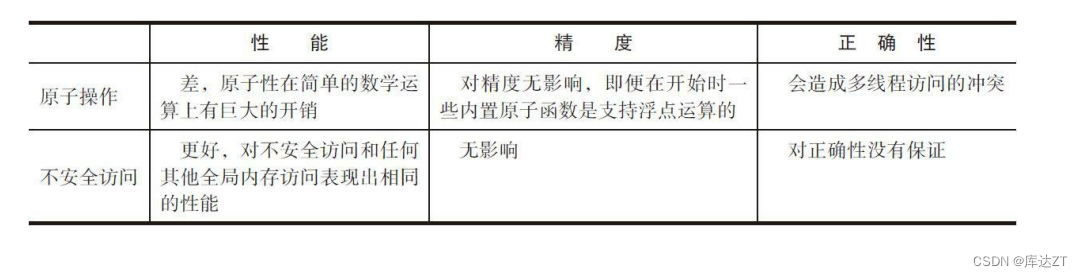
小结:















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









