






void download(std::string file) {
for (int i = 0; i < 10; i++) {
std::cout << "Downloading " << file
<< " (" << i * 10 << "%)..." << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(400));
}
std::cout << "Download complete: " << file << std::endl;
}
void interact() {
std::string name;
std::cin >> name;
std::cout << "Hi, " << name << std::endl;
}
int main() {
std::thread t1([&] {
download("hello.zip");
});
interact();
std::cout << "Waiting for child thread..." << std::endl;
t1.join();
std::cout << "Child thread exited!" << std::endl;
return 0;
}这是我们上一次的代码,用了两个线程,而tbb的工作模式是任务组:
void download(std::string file) {
for (int i = 0; i < 10; i++) {
std::cout << "Downloading " << file
<< " (" << i * 10 << "%)..." << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(400));
}
std::cout << "Download complete: " << file << std::endl;
}
void interact() {
std::string name;
std::cin >> name;
std::cout << "Hi, " << name << std::endl;
}
int main() {
tbb::task_group tg;
tg.run([&] {
download("hello.zip");
});
tg.run([&] {
interact();
});
tg.wait();
return 0;
}用一个task_group任务组启动多个任务,用tg.wait()等待线程完成。
它和上节课的区别在于,一个任务不一定对应一个线程,如果任务数量超过CPU最大的线程数,会由 TBB 在用户层负责调度任务运行在多个预先分配好的线程,而不是由操作系统负责调度线程运行在多个物理核心。
int main() {
tbb::parallel_invoke([&] {
download("hello.zip");
}, [&] {
interact();
});
return 0;
}也可以使用这种封装好了的parallel_invoke,可以接受任意个lambda函数。
int main() {
std::string s = "Hello, world!";
char ch = 'd';
tbb::parallel_invoke([&] {
for (size_t i = 0; i < s.size() / 2; i++) {
if (s[i] == ch)
std::cout << "found!" << std::endl;
}
}, [&] {
for (size_t i = s.size() / 2; i < s.size(); i++) {
if (s[i] == ch)
std::cout << "found!" << std::endl;
}
});
return 0;
}多线程tbb可以用来查找,就像上面就是并行的二分法。
并行算法
int main() {
size_t n = 1<<26;
std::vector<float> a(n);
size_t maxt = 4;
tbb::task_group tg;
for (size_t t = 0; t < maxt; t++) {
auto beg = t * n / maxt;
auto end = std::min(n, (t + 1) * n / maxt);
tg.run([&, beg, end] {
for (size_t i = beg; i < end; i++) {
a[i] = std::sin(i);
}
});
}
tg.wait();
return 0;
}还有一种封装好了的算法 :parallel_for的作用就是将0-n上的区间拆分好,给lambda作为参数r
tbb创建的是和核心数量一样的线程。
int main() {
size_t n = 1 << 16;
std::vector<float> a(n);
tbb::parallel_for(tbb::blocked_range<size_t>(0, n),
[&](tbb::blocked_range<size_t> r) {
for (size_t i = r.begin(); i < r.end(); i++)
{
a[i] = std::sin(i);
}
});
return 0;
}还有面向初学者版的parallel_for,
void parallel_for(Index first, Index last, Index step, const Function& f)
tbb::parallel_for((size_t)0, (size_t)n, [&](size_t i) {
a[i] = std::sin(i);
});但这么做的话会损失性能,编译器看到了之后就不会进行SIMD优化了。
针对于迭代器的区间:parallel_for_each
tbb::parallel_for_each(a.begin(), a.end(), [&](float& f) {
f = 32.f;
});还有针对于二维的循环和三维的循环:
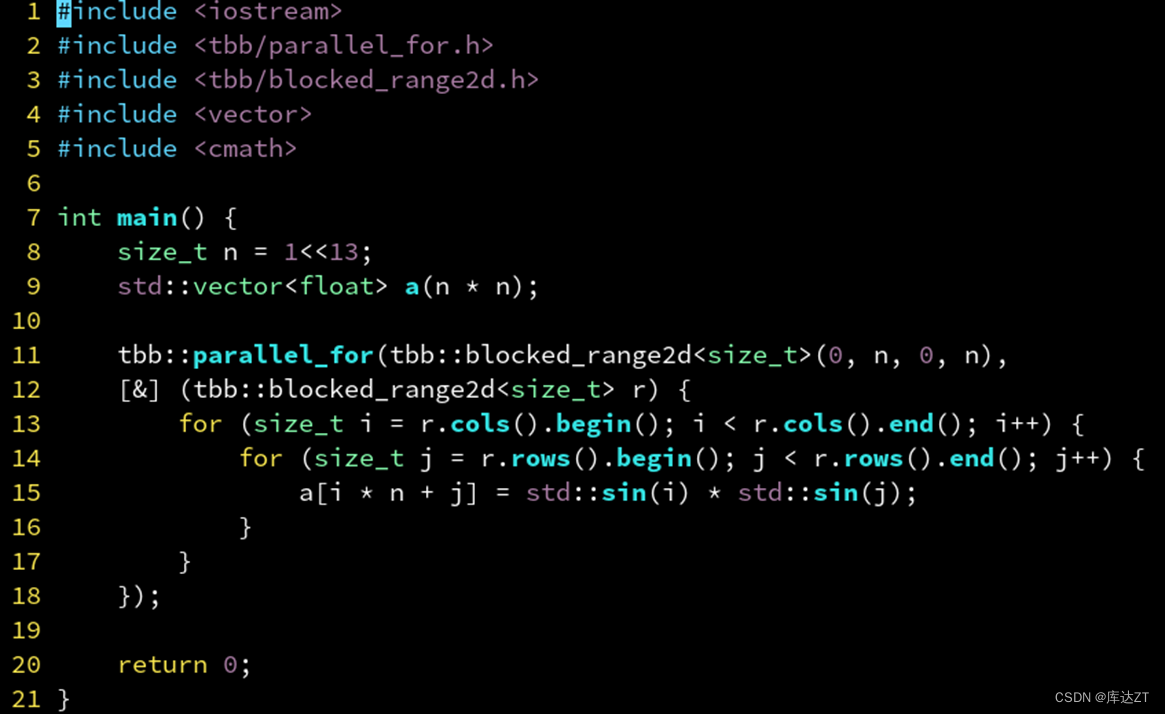
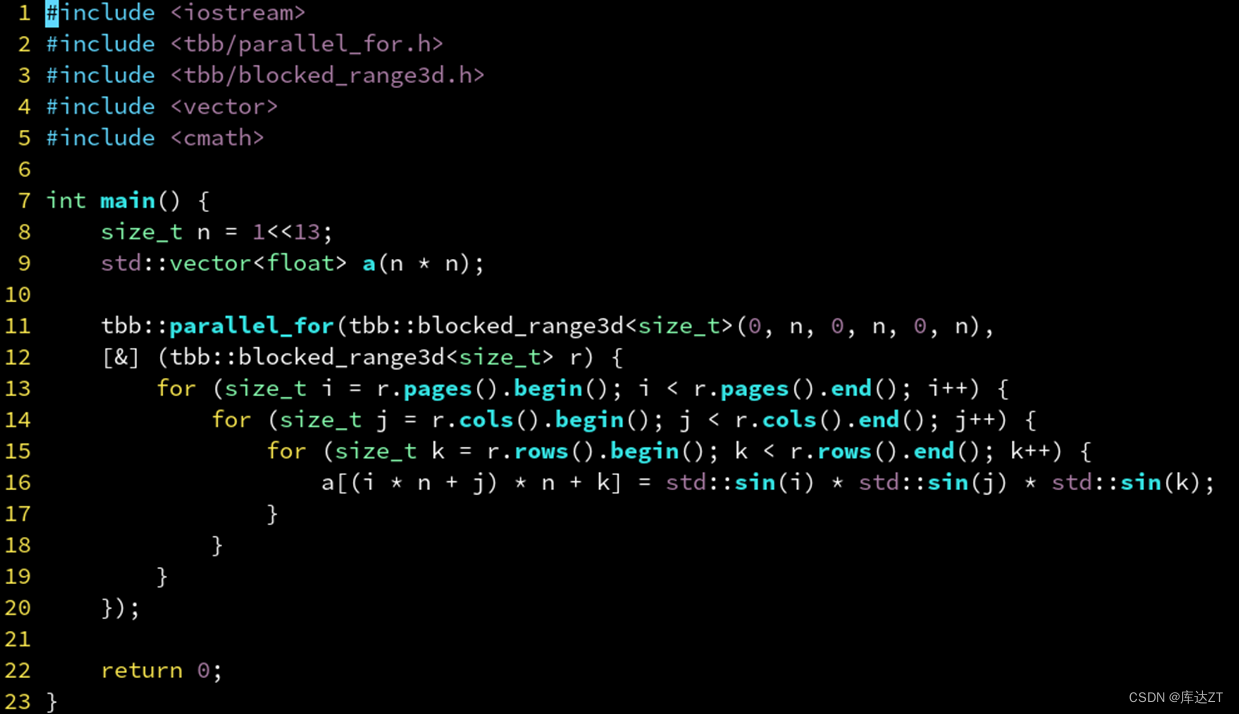
并行算法:Reduce
parallel_reduce
![]()
float res = tbb::parallel_reduce(tbb::blocked_range<size_t>(0, n), (float)0, [&](tbb::blocked_range<size_t> r, float local_res) {
for (size_t i = r.begin(); i < r.end(); i++) {
local_res += std::sin(i);
};
return local_res;
}, [](float x, float y) {
return x + y;
});
tbb::blocked_range<size_t>(0, n)表示要处理的数据范围,这里是从 0 到 n-1 的整数范围。(float)0表示初始值,这里是 0。- 第一个 lambda 函数,它接受两个参数:
r和local_res。r表示当前要处理的数据范围,local_res表示当前的局部结果。在 lambda 函数中,使用一个 for 循环遍历r中的所有元素,并将它们的正弦值累加到local_res中,最后返回local_res。 - 第二个 lambda 函数是一个合并函数,用于将所有的局部结果合并成一个最终的结果。它接受两个参数
x和y,分别表示两个局部结果,将它们相加并返回结果。
缩并算法还有额外的好处:能减少浮点误差
size_t n = 1<<26;
std::vector<float> a(n);
for (size_t i = 0; i < n; i++) {
a[i] = 10.f + std::sin(i);
}
float serial_avg = 0;
for (size_t i = 0; i < n; i++) {
serial_avg += a[i];
}
serial_avg /= n;
std::cout << serial_avg << std::endl;比如要是上图这种情况,加到最后serial_avg会非常大,那么再加上一个小数就会出现误差。
而reduce将整个大的加法分为了很多的小区间,每一个小区间的加法数量级都差不多,所以最后加在一起 的精度也可以收到保证
并行算法:Scan(前缀和)
#include <iostream>
#include <tbb/parallel_reduce.h>
#include <tbb/blocked_range.h>
#include <tbb/task_group.h>
#include <string>
#include <cmath>
#include <vector>
//试一下int(结果正常) ,试一下值传递(不可以,这是因为值传递传进去的是副本,那么tmp_res 就不会发生变化了)
int main() {
size_t n = 1 << 16;
size_t maxt = 4;
std::vector<float> a(n);
float res = 0;
tbb::task_group tg1;
std::vector<float> tmp_res(maxt);
for (size_t t = 0; t < maxt; t++)
{
size_t beg = t * n / maxt;
size_t end = std::min(n, (t + 1) * n / maxt);
tg1.run([&, t, beg, end] { //这里的t,beg,end都是值传递,这是因为这个是异步的,可能在执行的时候t发生变化,所以要传t的值。
float local_res = 0;
for (size_t i = beg; i < end; i++) {
local_res += std::sin(i);
}
tmp_res[t] = local_res;
});
}
tg1.wait();
for (size_t t = 0; t < maxt; t++) {
tmp_res[t] += res;
res += tmp_res[t];
}
tbb::task_group tg2;
for (size_t t = 1; t < maxt; t++)
{
size_t beg = t * n / maxt - 1;
size_t end = std::min(n, (t + 1) * n / maxt - 1);
tg2.run([&, t, beg, end] {
float local_res = tmp_res[t];
for (size_t i = beg; i < end; i++) {
local_res += std::sin(i);
a[i] = local_res;
}
});
}
tg2.wait();
std::cout << a[n / 2] << std::endl;
std::cout << res << std::endl;
}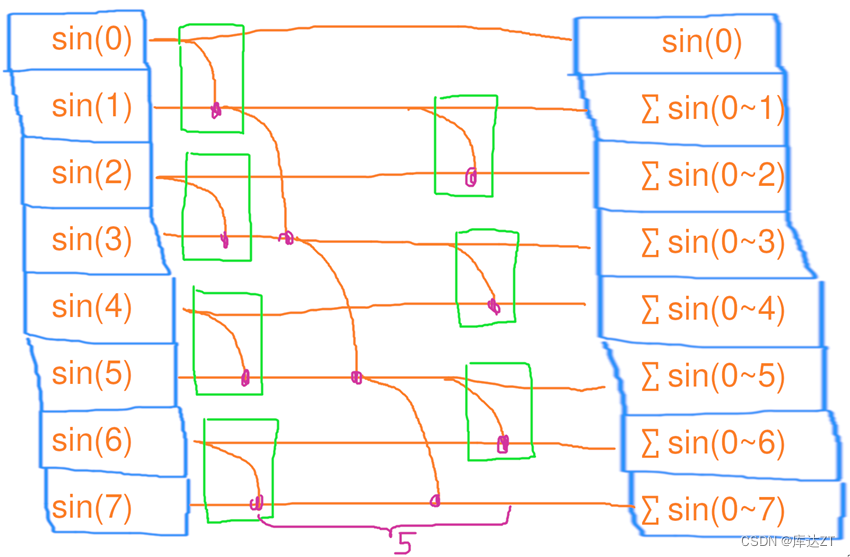
这个图配的非常巧妙,结合上面的公式一看就能懂。
可以看到并行的扫描是有代价的,可以看到工作的复杂度明显增加了。
#include <iostream>
#include <tbb/parallel_scan.h>
#include <tbb/blocked_range.h>
#include <vector>
#include <cmath>
int main() {
size_t n = 1<<26;
std::vector<float> a(n);
float res = tbb::parallel_scan(tbb::blocked_range<size_t>(0, n), (float)0,
[&] (tbb::blocked_range<size_t> r, float local_res, auto is_final) {
for (size_t i = r.begin(); i < r.end(); i++) {
local_res += std::sin(i);
if (is_final) {
a[i] = local_res;
}
}
return local_res;
}, [] (float x, float y) {
return x + y;
});
std::cout << a[n / 2] << std::endl;
std::cout << res << std::endl;
return 0;
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









