







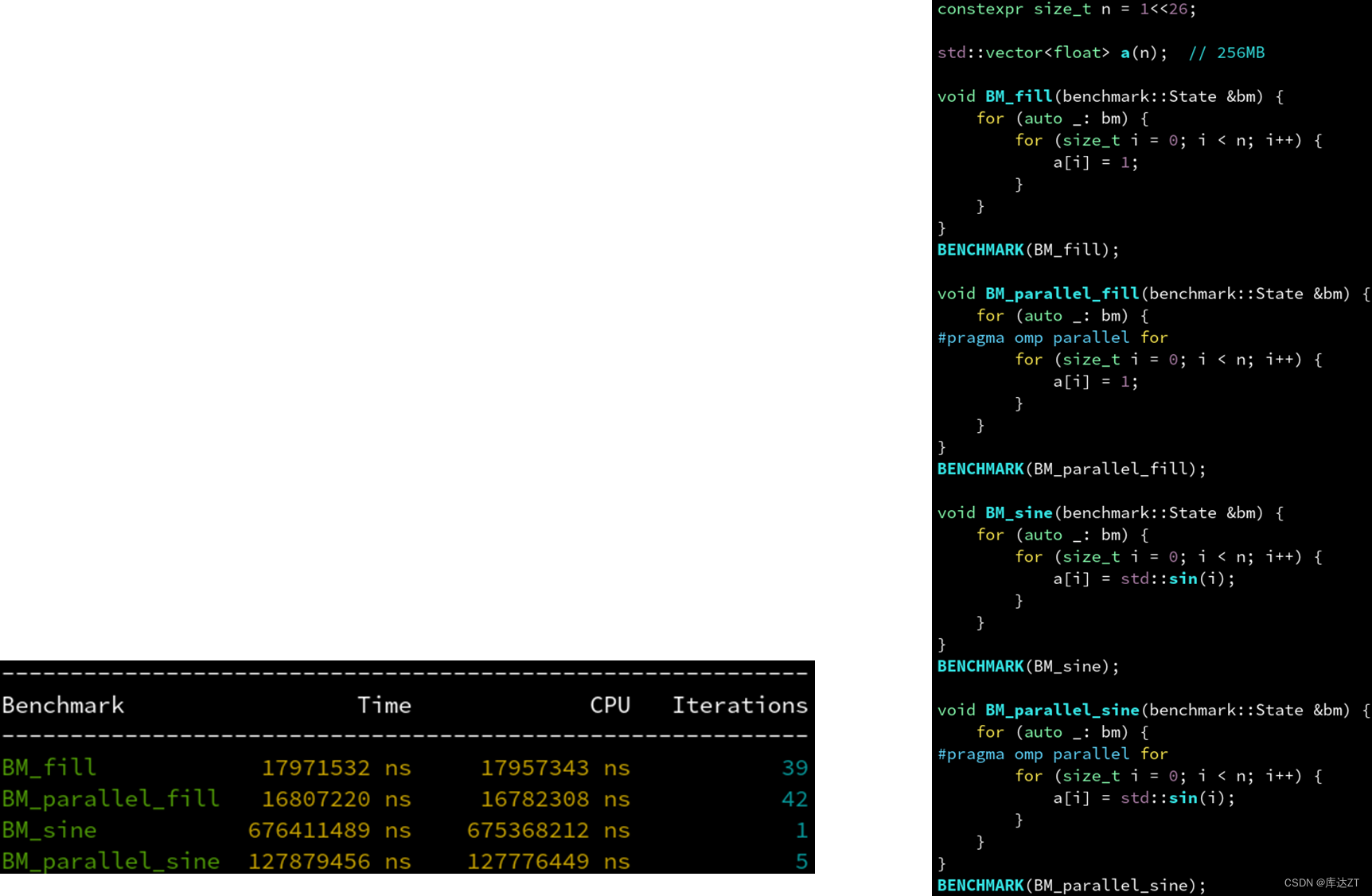
通常来说,并行只能加速计算的部分,不能加速内存读写的部分。
因此,对 fill 这种没有任何计算量,纯粹只有访存的循环体,并行没有加速效果。称为内存瓶颈(memory-bound)。
而 sine 这种内部需要泰勒展开来计算,每次迭代计算量很大的循环体,并行才有较好的加速效果。称为计算瓶颈(cpu-bound)。
并行能减轻计算瓶颈,但不减轻内存瓶颈,故后者是优化的重点。
那我们给他每个加上1是不是就能变快了?
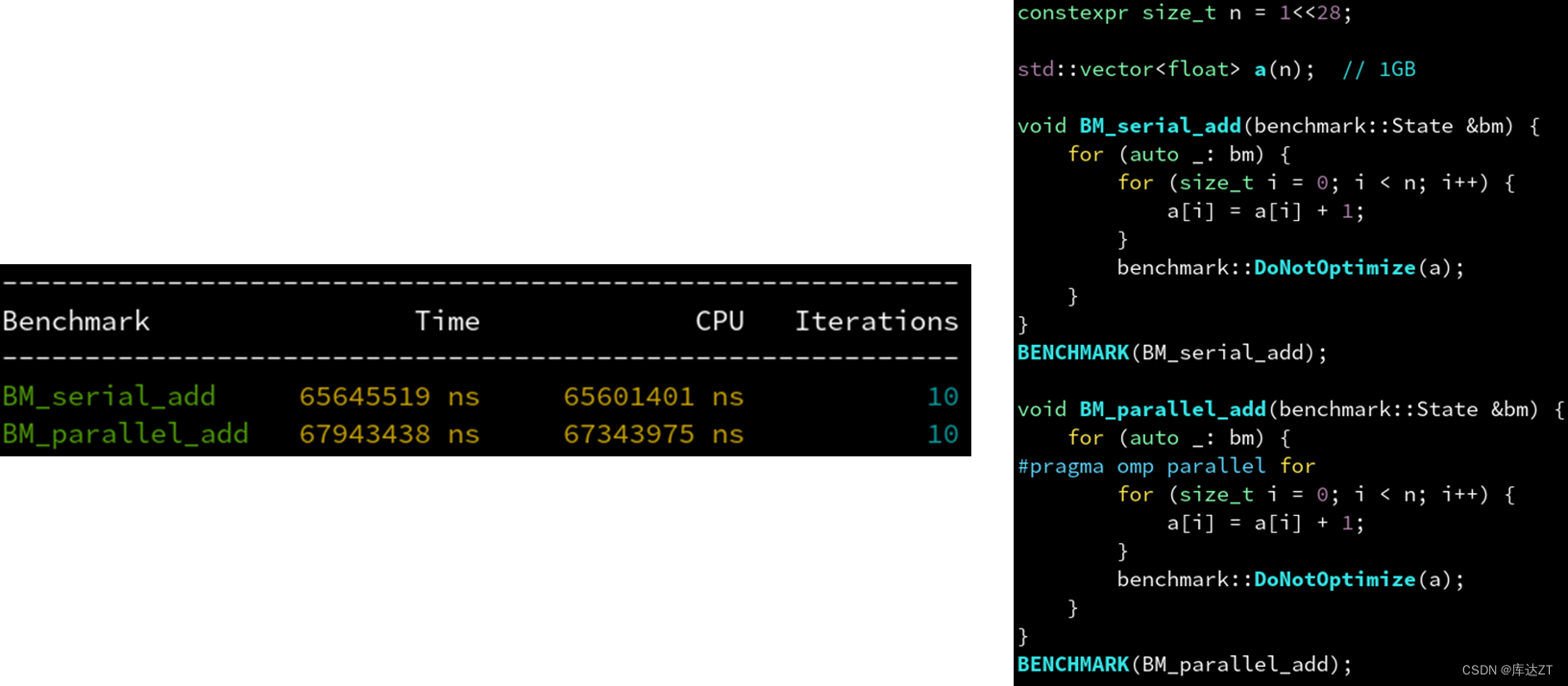
可以看到并不是这样的
因为一次浮点加法的计算量和访存的超高延迟相比实在太少了。
计算太简单,数据量又大,并行只带来了多线程调度的额外开销。
小彭老师的经验公式:1次浮点读写 ≈ 8次浮点加法
如果矢量化成功(SSE):1次浮点读写 ≈ 32次浮点加法
如果CPU有4核且矢量化成功:1次浮点读写 ≈ 128次浮点加法
所以就要足够的计算量来隐藏操作的延迟。
什么是超线程技术:不一定是两个线程在两个核上同时运行,而是有可能两个线程同时运行在一个核上,由硬件自动来调度。这个主要是针对如果内存卡住,cpu会自动切换到另一个核上。
内存条是并行的,所以2*8>1*16
CPU中的高速缓存:
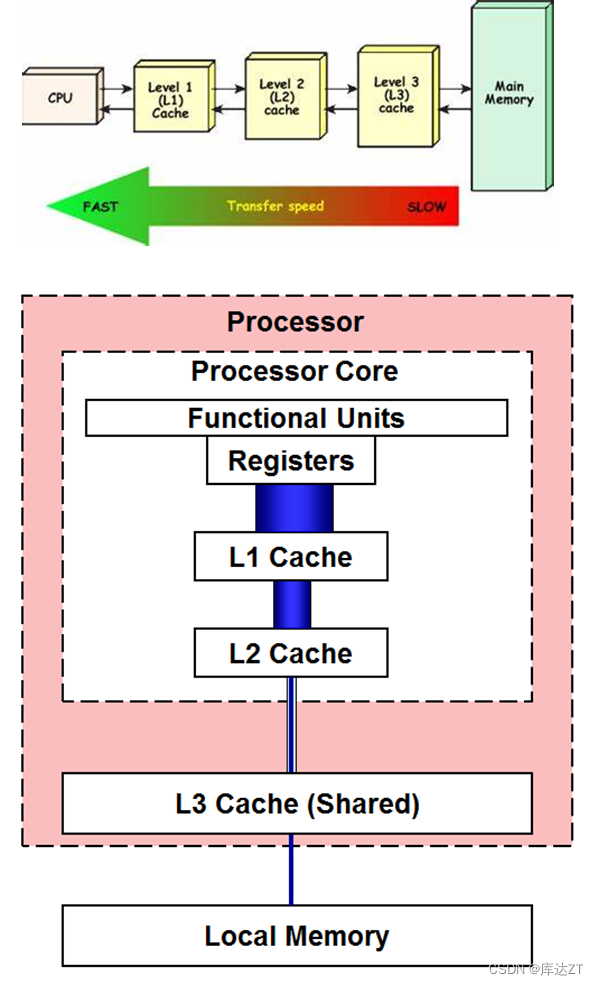
CPU的厂商早就意识到了内存延迟高,读写效率低下的问题。因此他们在CPU内部引入了一片极小的存储器——虽然小,但是读写速度却特别快。这片小而快的存储器称为缓存(cache)。
当CPU访问某个地址时,会先查找缓存中是否有对应的数据。如果没有,则从内存中读取,并存储到缓存中;如果有,则直接使用缓存中的数据。
这样一来,访问的数据量比较小时,就可以自动预先加载到这个更高效的缓存里,然后再开始做运算,从而避免从外部内存读写的超高延迟。
缓存的分级结构: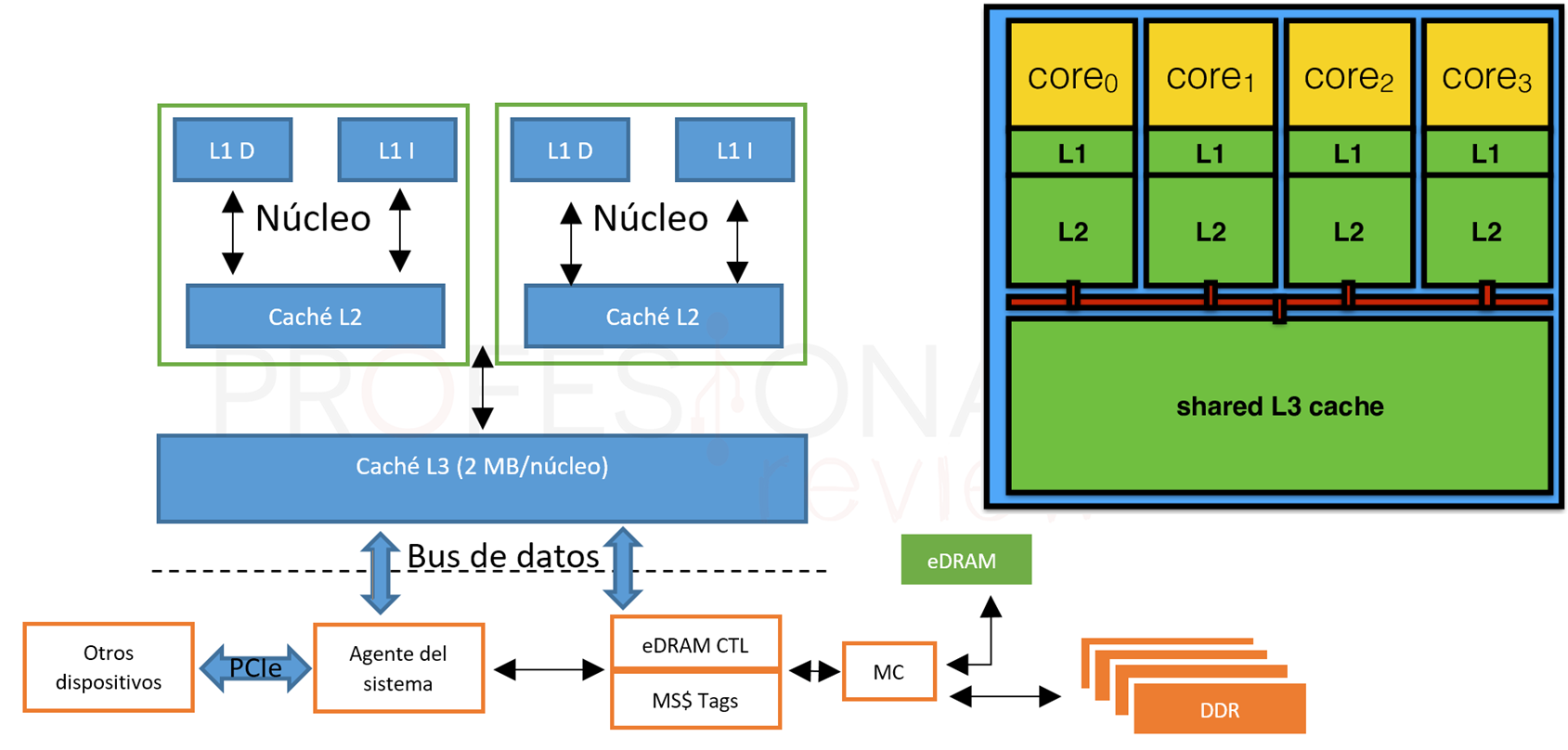
L1,L2缓存是只给自己核心用的,而L3比较大,可以给多个核心使用。
L1缓存分为数据缓存和指令缓存
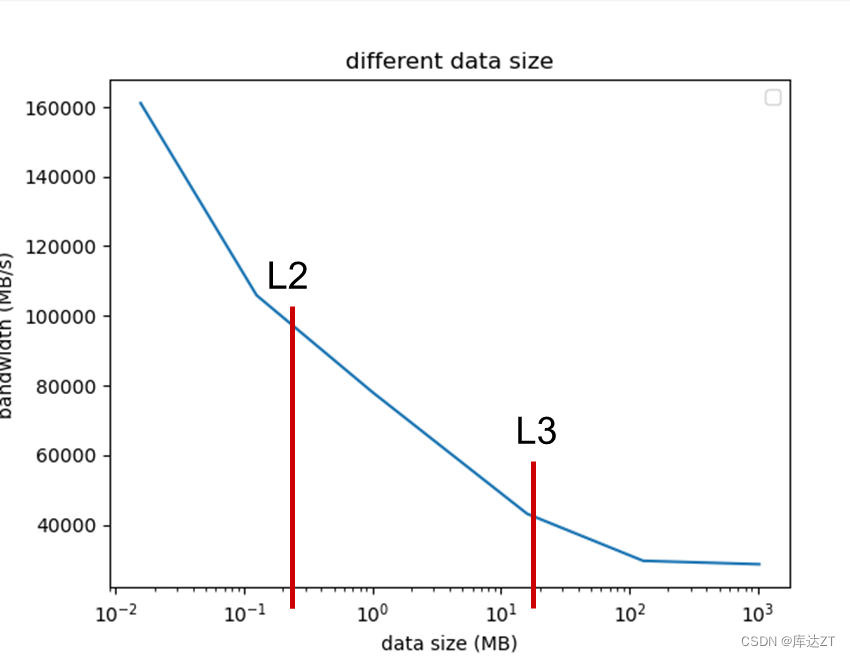
也可以看到刚刚两个出现转折的点,也是在二级缓存和三级缓存的大小附近。
因此,数据小到装的进二级缓存,则最大带宽就取决于二级缓存的带宽。稍微大一点则只能装到三级缓存,就取决于三级缓存的带宽。三级缓存也装不下,那就取决于主内存的带宽了。
结论:要避免mem-bound,数据量尽量足够小,如果能装的进缓存就高效了。
缓存的工作机制:读:
通俗点来讲,当CPU想要读取一个地址的时候, 就会跟缓存说,我要读取这个地址,缓存就去查找,看看这个地址有没有存储过,要是存储过就直接将缓存里存的数据返回给CPU,要是没找到,就像下一级缓存下令,让它去读,如果三级缓存也读不到,三级缓存就会向主内存发送请求,就会创建一个新条目,这样下一次再寻找这个数据的时候就不用再去主内存里读取了。
在X86架构中,这个条目的大小是64字节。比如当访问 0x0048~0x0050 这 4 个字节时,实际会导致 0x0040~0x0080 的 64 字节数据整个被读取到缓存中。

缓存的工作机制:写:
同样的,当CPU写入一个数组时,缓存会查找与该地址匹配的条目,如果找到,那就修改数据,如果没有找到,就创建一个新条目,并且标记为dirty。
当读和写创建的新条目过多,缓存快要塞不下时,他会把最不常用的那个条目移除,这个现象称为失效(invalid)。如果那个条目时刚刚读的时候创建的,那没问题可以删,但是如果那个条目是被标记为脏的,则说明是当时打算写入的数据,那就麻烦了,需要向主内存发送写入请求,等他写入成功,才能安全移除这个条目。
如有多级缓存,则一级缓存失效后会丢给二级缓存。二级再丢给三级,三级最后丢给主内存。

连续访问与跨步访问:
#include <iostream>
#include <vector>
#include <cmath>
#include <cstring>
#include <cstdlib>
#include <array>
#include <benchmark/benchmark.h>
#include <omp.h>
constexpr size_t n = 1 << 28;
std::vector<float> a(n);
void BM_skip1(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 1) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip1);
void BM_skip2(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 2) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip2);
void BM_skip4(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 4) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip4);
void BM_skip8(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 8) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip8);
void BM_skip16(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 16) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip16);
void BM_skip32(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 32) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip32);
void BM_skip64(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 64) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip64);
void BM_skip128(benchmark::State& bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i += 128) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_skip128);
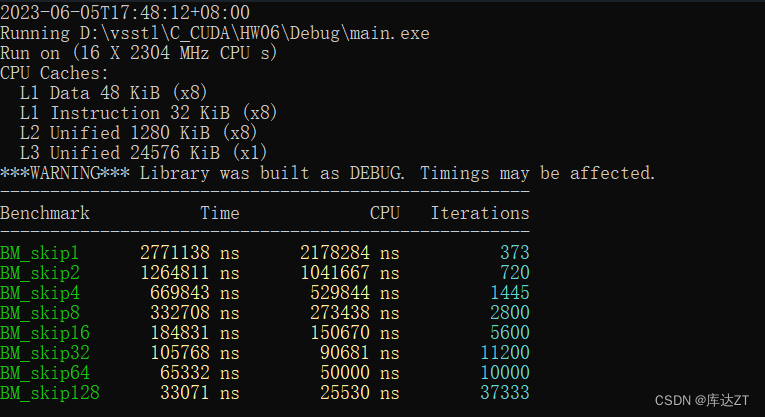
BENCHMARK_MAIN();如果访问数组时,按一定的间距跨步访问,则效率如何?
从1到16都是一样快的,32开始才按2的倍率变慢,为什么?
因为CPU和内存之间隔着缓存,而缓存和内存之间传输数据的最小单位是缓存行(64字节)。16个float是64字节,所以小于64字节的跨步访问,都会导致数据全部被读取出来。而超过64字节的跨步,则中间的缓存行没有被读取,从而变快了。
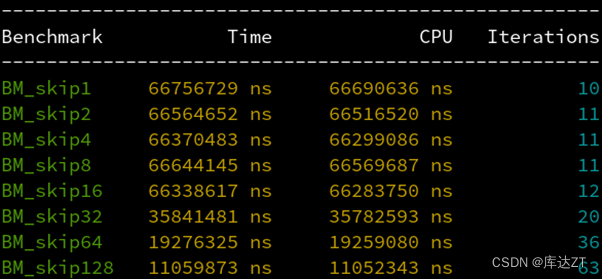
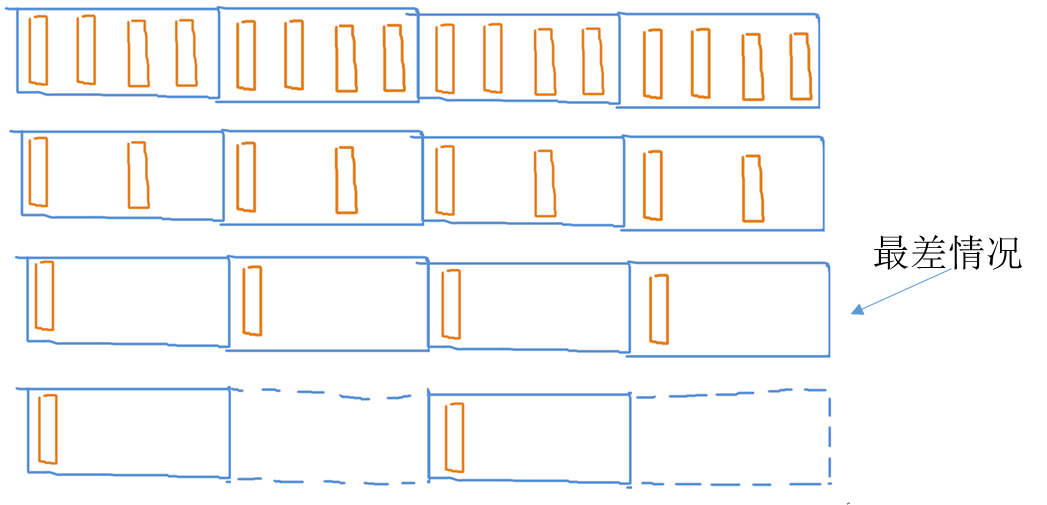
(上面是原作者在课堂上所教授的内容,下图是我实际操作的结果,可以看到CPU已经对跨步访问有了足够的优化,步长增加一倍,对应时间也缩小一倍)
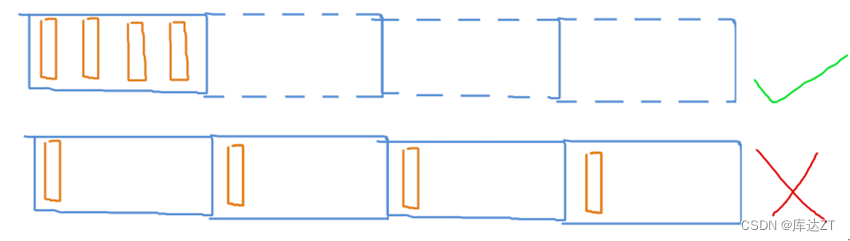
所以我们设计数据结构时,应该把数据存储的尽可能紧凑,不要松散排列。最好每个缓存行里要么有数据,要么没数据,避免读取缓存行时浪费一部分空间没用。
重新认识一下结构体:
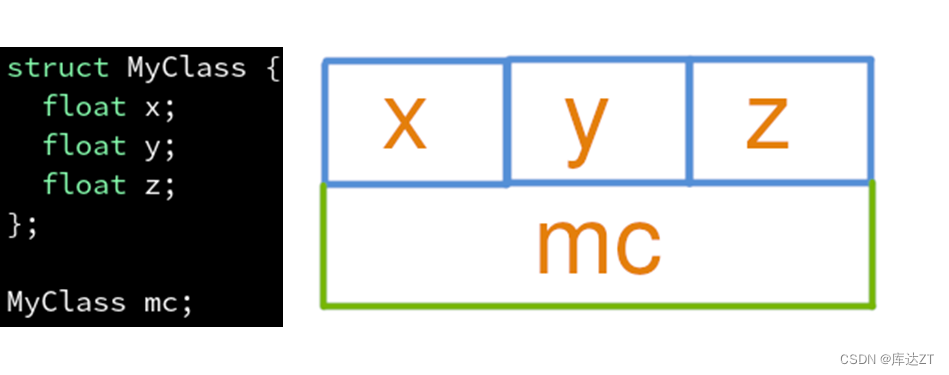
MyClass在内存中所占的是12个字节
AOS:不方便连续访问x元素
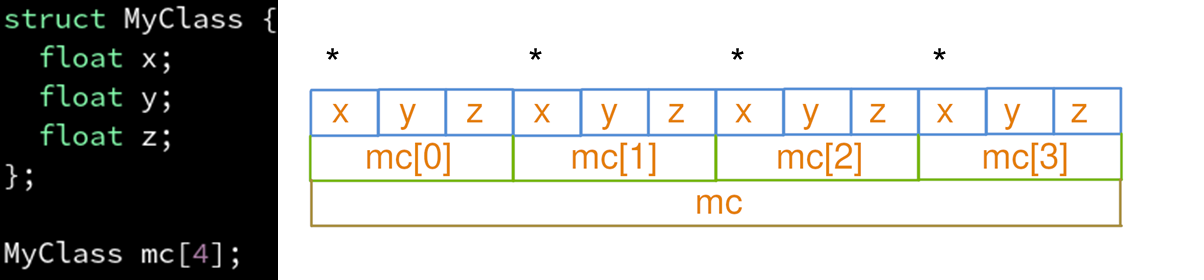
SOA:
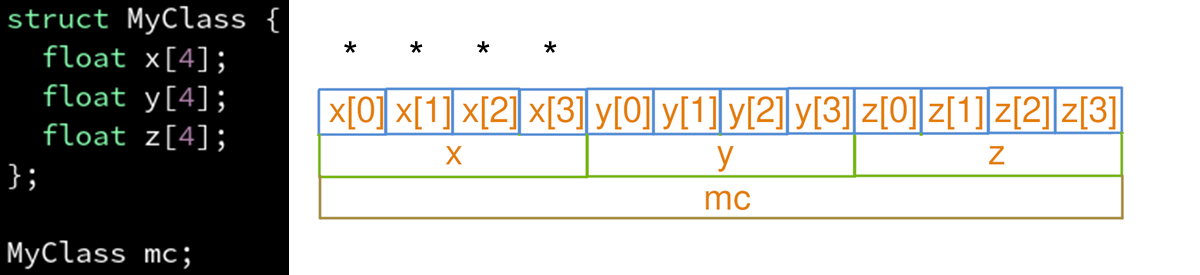
如果每个属性都要访问到,那还是AOS比较好
这是因为使用SOA会让CPU不得不同时维护很多条预取赛道(mc_x, mc_y, mc_z),当赛道多了以后每一条赛道的长度就变短了,从而能够周转的余地时间比较少,不利于延迟隐藏。
而如果把这三条赛道合并成一条(mc),这样同样的经费(缓存容量)能铺出的赛道(预取)就更长,从而CPU有更长的周转时间来隐藏他内部计算的延迟。所以本案例中AOS比SOA好
结论:
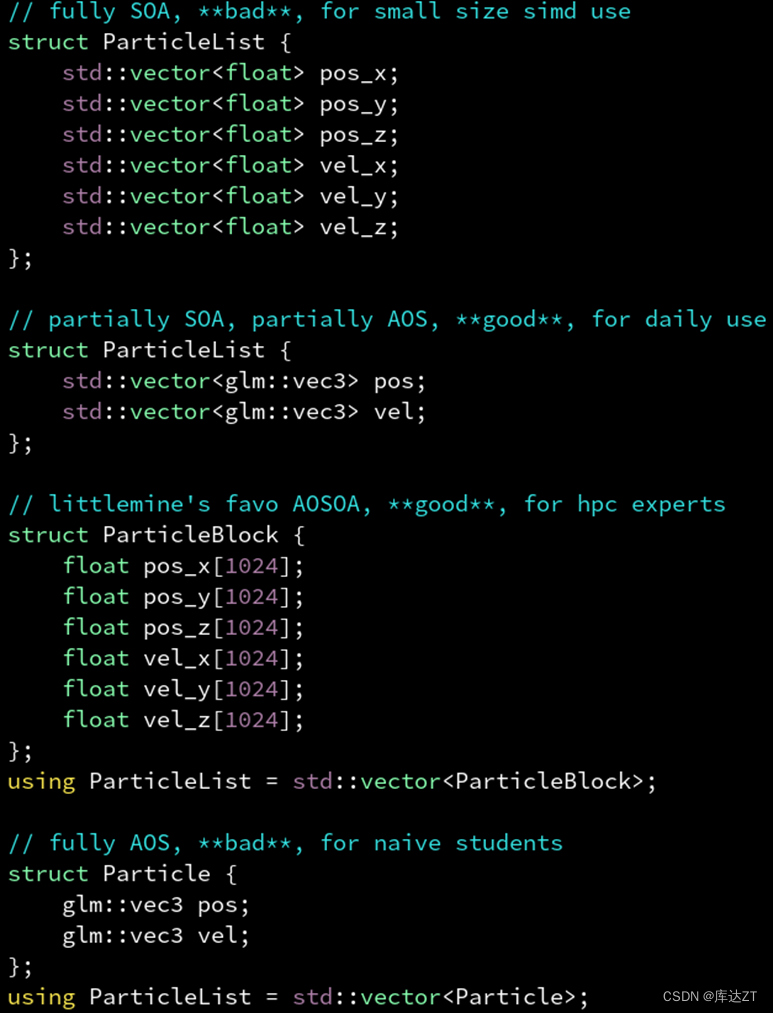
如果几个属性几乎总是同时一起用的,比如位置矢量pos的xyz分量,可能都是同时读取同时修改的,这时用AOS,减轻预取压力。
如果几个属性有时只用到其中几个,不一定同时写入,比如pos和vel,通常的情况都是pos+=vel,也就是pos是读写,vel是只读,那这时候就用SOA比较好,省内存带宽。
不过“pos的xyz分量用AOS”这个结论,是单从内存访问效率来看的,需要SIMD矢量化的话可能还是要SOA或AOSOA,比如hw04那种的。而“pos和vel应该用SOA分开存”是没问题的。
SOA大多数情况下不亏。















 4089
4089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









