






由Duane等人(1987)提出的HMC算法是一种基于动态仿真采样技术的Metropolis算法,参见文章“Equations of State Calculations by Fast Computing Machines”1953年,Nicolas Metropolis。算法的输出是从一些特定分布采样的样本点,这些点可以被用于形成对各种关于这个分布的函数的期望的MC估计。对于Beysian学习,我们希望从给定数据的后验分布采样,并且关注需要预测测试样本的期望的估计。一种关于HMC的理解方式是作为Gibbs采样和一种特定Metropolis算法的组合。
1.基于能量明确公示表达
HMC是关于从规则的(或Boltzmann)分布的物理体系的状态,它是基于能量的形式定义的。然而,这个算法实际上可以用于任何概率密度函数的导数可以计算的实值变量的分布,即使在非物理系统中他可以很容易的保持这个物理特性,通过明确的公式表示该虚构的物理体系。
对应地,假设我们希望从一些位置变量q的分布进行采样,他有n个实值的成分。在实际的物理体系中,q包括所有的微粒对应的坐标:在我们的应用中,q是网络参数的序列。在规则的分布下变量的概率密度函数为:
P(x)正比于exp(-E(q)) (1)
其中E(q)是“潜在的能量”函数。(规则的分布的温度参数设置为1,因为他在表达应用时没用。)通过简单定义E(q)=-logP(q)-logZ,对任何Z,任何概率密度不为零都可以用这种形式。
为了使用动态方法,我们介绍一个动态变量p,有n个实值成分pi,与q形成1对1的对应关系。关于p和q的联合相位空间的标准分布为:
P(q,p)正比于exp(-H(q,p)) (2)
这里H(q,p)=E(q)+K(p)是Hamiltonian函数,定义总能量。K(p)是“kinetic能量”关于动量,因此一般的选择是:
K(P)=sum(pi^2/2mi) mi=1...n (3)
mi是每个成分的质量,对这些质量值的调整可以提高效率,对于动量,他们可以都取为1.
在分布等式(2)中,q和p是独立的,q的边缘分布为等式(1),我们想从他采样。我们就可以定义一个MC关于q和p收敛到规范表达式,当估计q的表达时时忽略p的值。
这种策略是毫无目的的现在,但是它最终会证明是持续有效的通过抑制随机行走的行为。
2.统计动态方法
HMC可以被看做是统计动态方法的详细阐述,其中从q和p由等式(2)定义的规范分布分成两个子任务--从有固定总能量H(q,p)的q和p进行采样,从不同的H中得到。
从固定的总能量重采样可以通过体系的Hamiltonian动态函数实现,其中状态牵扯到虚构时间t,表示为下式:
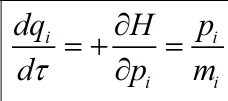

为了实现它,我们必须计算E关于qi的偏导数。
在采样时,Hamiltonian动态函数的三个性质对它的应用是约束的。首先,q和p关于动态进行改变时H是常数,可以看做:
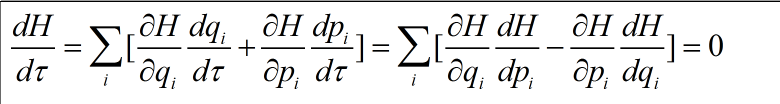
第二点,Hamiltonian动态函数保留相位空间的列--例如,如果我们随着关于动态等式的列V在一些区域怎样移动。我们发现这些点在给定的移动时间后仍然有列V,我们可以通
过相位空间中动作的散度看出:
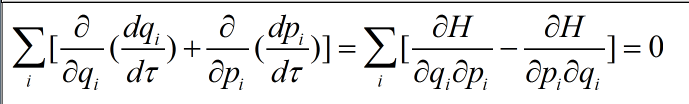
最后,动态是可逆的,在沿着动态行为一段时间后,我们可以通过动态的返回进行同样的时间恢复原来的状态。
总结,这些性能表明规范的分布对q和p关于包括一系列已经预先设定好时间段是不变的,使用Hamiltonian动态函数的轨迹的变换。通过变换后在一些小区域会结束的概率与我们在
对应区域开始的概率通过逆动态函数得到。如果这个概率由规范分布已知,最终区域的概率也和规范分布对应,因为基于规范分布的概率仅仅取决于H,H在轨迹的开始与结束是相同的。
在许多情况下,基于Hamiltonian动态函数的变换实际上是采用给定一个H值得整个相位空间的区域。而这种方法并不能产生遍历性的MC,然而,区域有不同的H值而不被遍历。
在Hamiltonian动态方法中,一个遍历的MC是通过迭代的执行决策动态变换和统计的Gibbs采样更新动量。因为q和p是独立的,p的更新与q无关并且得到一个新值的概率密度指数为
exp(-K(P))。对于(3)中的活性能量函数,这很容易实现,因为pi有独立的高斯分布。p的更新可以改变H,同样的整个相位空间都可以实现。
统计动态方法中轨迹的虚构时间长度是可调整的参数,最好使用轨迹线使q有大的改变,这样可以避免在每次轨迹改变时由随机动量产生的随机行走的影响(下面会
与HMC一起进一步讨论)。
事实上,Hamiltonian动态函数不能被确切的仿真,但是可以通过有限步的离散化进行近似。在通常使用的leapfrog方法中,用简单的迭代计算位置和动量的近似,
q‘和p’,从时间t到时间t+e的q'和p'为:



这个迭代包括一半步的qi,一半步的pi,(也可以做一半步的qi,满步的pi,接着另一半步的qi,但是这样通常有点不方便。)为了接着这样的动态一段时间rt,在给
定的误差范围内e的值应该尽可能地小,等式(8)-(10)要迭代L=rt/e 次。当这样做时,一次迭代中后一半步的可以由下一次迭代时的一半步的pi立刻连接。所有的迭代除了第一
次和最后一次,这样的半步都可以合并成一整步从时间t+ke+e/2开始,超过了关于qi的“leapfrog”步从时间t+ke开始。
在leapfrog的离散化中,相位空间的列仍然被保留(这是由leapfrog迭代的事实产生的,每个成分q和p的增加都是仅仅取决于其他成分的现有值)。这种动态仍然是可逆的(通过采用相同
次的leapfrog迭代有e误差)。然而,H的值不再是一个确切的常数,因此,MC估计发现使用动态方法会产生动态的误差,只有在步长e为0时误差才会为0(需要计算每次轨迹的步骤
趋于无限)。
3.HMC
在Duane(1987)的MC算法中,统计动态方法的系统误差通过Metroplis算法一起出现时计算。
像不正确的统计动态方法,HMC用MC的方法在相位空间采样样本点,其中统计和动态变换可以等价。在统计变换中,动量由Gibbs采样代替,正如前面所讲。HMC的动态变换与统计变换
中用的方法相似,但是有两个改变--首先,无论对动态的仿真提前还是推后进行,都要决定一个随机决策值对每个变换;的第二,通过动态变换改变的点仅仅是对于新状态
的一个候选点,被接受与拒绝仅仅取决于整体能量的改变,正如Metroplis算法中那样。如果动态可以被确切的仿真,H的改变通常为0,新的点通常可以被接受。当动态是由近似分布仿真的,
H就会改变,移动有时候就会被拒绝。这些拒绝恰恰消除了不确切的仿真中的偏置。
详细的,给定步长e的数量级,以及leapfrog迭代的次数L,动态变换包括以下几步:
1)随机选择一个方向,对于轨迹 ,表达前向的轨迹,表达后向的轨迹,具有同等可能性。
2)从现在的状态开始,(q,p)=(q'(0),p'(0)),进行L此leapfrog迭代步长为s,产生的新状态为(q‘(s属于L),p’(s属于L))=(q*,p*)
3)将(q*,p*)当做下一个状态的候补,正如Metroplis算法中一样,接受的概率为min(1,exp(-(H(q*,p*)-H(q,p)))),然后使新的状态和旧的一样。
通过动态表达相位空间的列,和随机选择的 一起确保了候补点的移动的提议是对称的,正 如Metroplis算法所必需的(事实上,当p在每次动态变换前被随机初始化时,的随机选择就不必要了
但是当动态变换在其他情况下使用时就必须了)。e和L的值可以从特定分布随机选择。当最佳值不知道时,这可能是有用的,或者从一个地方到另一个地方。一些变量值仍然是必须的来避免
可以通过遍历推断的周期性。虽然这是不希望的问题对一个不规则的分布例如神经网络的后验。
L=1时HMC称为LangevinMC也就是说在这种方法中仅需要进行一次leapfrog迭代就可以形成候补的状态。“Smart MC跟这个等价”。
然而,只有当L相当大的时候,才能得到HMC的主要优势-避免随机行走。有人可能会考虑比较大的误差在一长步的轨迹后才会形成,导致非常低的接受率。对于足够小的步长,这个通常不会
出现。相反,H的值沿着轨迹震荡,接受率与轨迹长度几乎是独立的,步长超过一定的限度时,leapfrog离散化就会不稳定,接受率会变得非常低,优化策略通常是选择步长恰好在不稳定点下。
轨迹应该足够长可以使状态远离它们的开始点,但更长就不行。较短的轨迹将会导致分布通过随机行走寻找:更长的轨迹将会穿过整个分布数次,最后得到的点可能跟较短的轨迹得到的点相似。
这里,我们希望采样的q=(q1,q2)是有高度相关性的双变量的高斯分布,由潜在的能量函数定义:
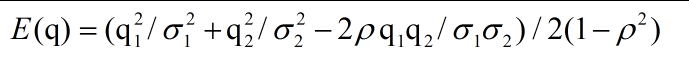
我们当然也可以变换到一个不同的坐标体系,其中这两个成分是不相关的,这样点采样就会简单一点,在更复杂的情况下这可能是困难的,因此我们假设我们不能这样做。如果两个成分的质量
m1和m2都为1,即使是在有限的方向,迭代次数比标准的迭代次数少两倍,leapfrog方法仍然是稳定的,为了使拒绝率低我们必须限制我们的步长比这个小一点。更多的leapfrog迭代就是必须
的为了寻找更有限的方向。

图的左边表示了30次LangevinMC的过程,在每次迭代中,动量从它的规范分布被迭代,然后,进行单一的leapfrog迭代(结果有时候会被拒绝),因为每次迭代的方向的随机性,过程采取随机
行走的方式。如果每次行走的距离大约为l,k次迭代后的距离就会只为l*sqrt(k)。
图的右边表示单一的leapfrogHMC轨迹包括20次leapfrog迭代,动量在开始时随机初始化。例如轨迹线在一个方向连续移动,直到他们投影到一个低概率的区域。对应地,在k步里,每次移动的距离
关于HMC可以使距离达到lk,允许比随机行走获得更有效的寻找。
LangevinMC方法要保持更好的获取率不允许更长的leapfrog步长,但对于更高的相关性的分布,这个优势更多补偿通过进行随机行走的惩罚。这种分布的Gibbs采样也可以产生随机行走,有相似大
小的改变,在Metroplis的简单的版本中,离散状态是通过中心在该点处的对称高斯分布得到的,得到较高的接受率需要限制与LangevinMC或Gibbs采样同样数量改变的大小,也可以产生随机行走。
(对于这个二维问题,事实上,当有较大的改变时,简单的Metropolis的性能最好,即使那时接受率非常低,但是这种策略在高维情况就会终止。)
参考文献:Bayesian learning for neural networks Radford M.Neal 1996















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









