







好上篇讲了RNN和LSTM训练和结构与MLP和CNN的区别,讲的是比较清晰的。
然后讲了RNN和LSTM的所有参数和输入输出。
这篇讲RNN和LSTM的训练。以下直接讲RNN的,因为是一样的。差异会附在后面。
emm还想分享一下自己的体会。一定要先看MLP结构和训练原理,再看CNN,再看RNN,再看LSTM。
开始正文。
一、RNN训练过程
我们先看两张图。
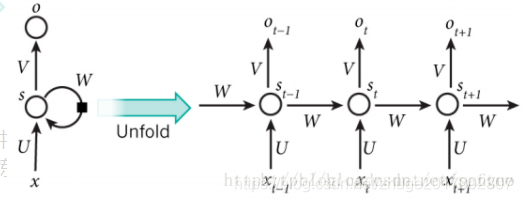
在上图中可以看出,对于一个RNN,需要求的参数有W,V和U。有人问上面不是有很多个U,V和W嘛,它们是不是都不同值?这就错了,上面有很多是因为这个是RNN在时间序列上展开的图,它作为一个RNN层,其实只有一个圆圈,里面有规定的隐藏层节点,假设为128。虽然它长得看起来有很多个,但始终只有一个单元,展开成了不同时间的cell。所以他只有一个W,V和U值。其中U是输入x(长度为input_size,假设为100)变到中间状态s的变换系数矩阵,那么U的维度就是(input_size,hidden_size),即100*128。W是上一个时间状态t-1到本cell的时间t的单元状态st,其维度为(hidden_size,hidden_size),即128*128。即把上一个时间状态的各个节点的状态传下来,现在要用,不然怎么能体现RNN处理时间序列的数据呢?正是因为传下来了上一个时间状态的节点状态,才有了RNN。V是节点状态st映射到输出o的系数变换矩阵,维度为(hidden_size,output_size),即128*100。此处output_size是等于input_size的,因为它们是一个东西。这就是所有的weight矩阵参数。
还有就是Bias参数,即每个节点的值。此处显然只有隐藏层节点128个(hidden_size),输出层节点100个(output_size),于是只有128+100个bias的参数。
那么一个RNN层总的参数个数就是100*128+128*128+128*100+128+100个。
这就是一个RNN层所有的参数。当然有的时候你可能设置多个RNN层,此时不同层之间的U,V 和W当然可以是不一样的。
这还是一张图,原理一样的,不同U,V和W代表的不一样。
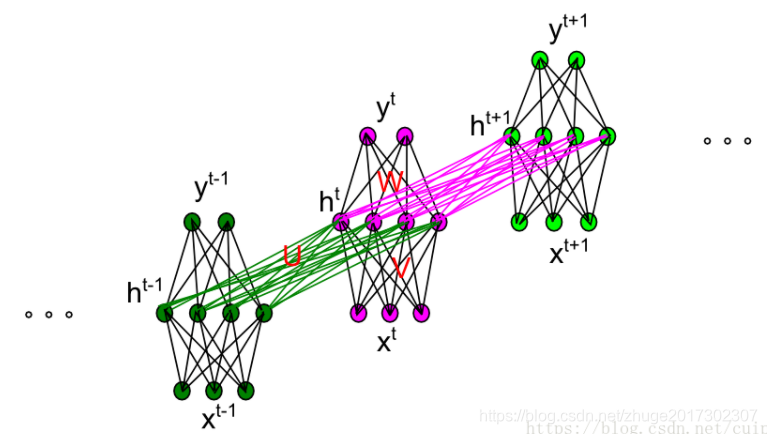
关于计算公式,粘贴一下我自己写的博客:
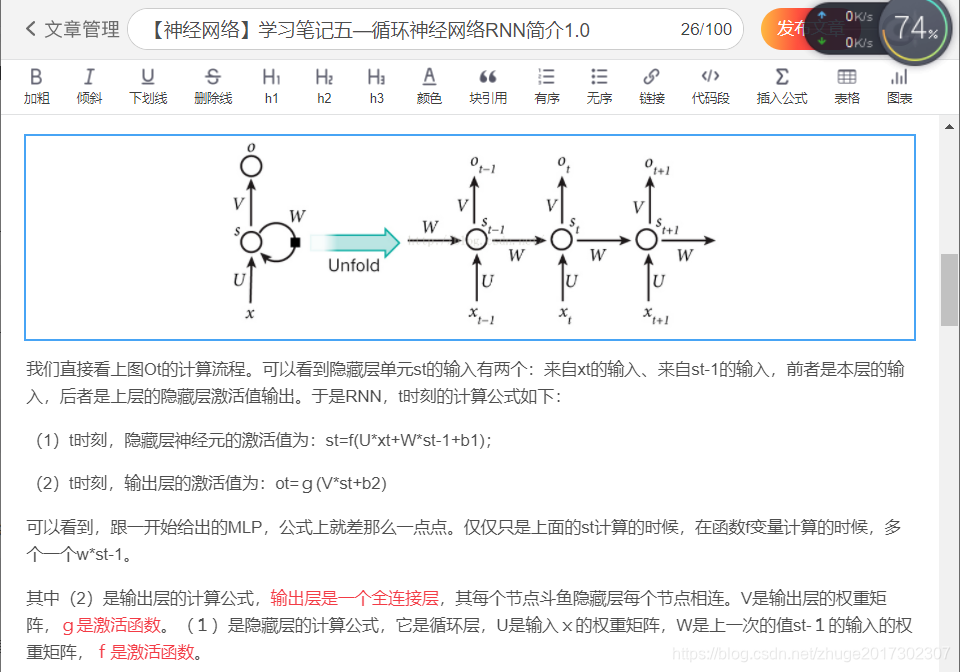
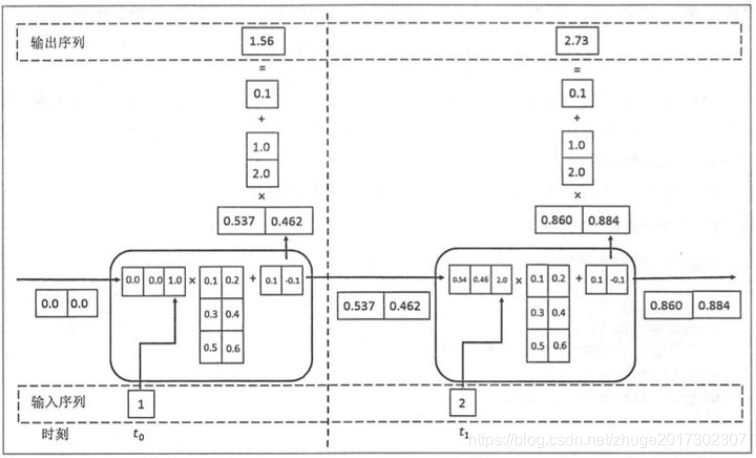
这里再粘一张图,很好的表明了RNN训练的过程及参数:
二、LSTM训练过程
LSTM跟RNN差不多,但由于其选择性遗忘的特点,参数多了一些,也更复杂一些。
首先来一张图。

假设输入x是100维向量,LSTM层隐藏节点数为128,输出为10维向量,意为分10类。
it输入门,ft忘记门,ot输出门。四个激活函数1、2、4为sigmoid,用处是将所得向量映射成0—1的数字进行概率运算,3为tanh,用于计算输出。
(1)忘记门
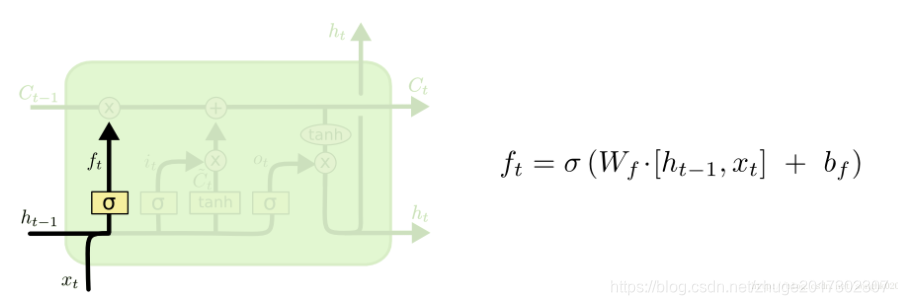
对于忘记门,其将上一个时间步的cell工作状态h(t-1)和本时间步的输入x(t)拼合成输入,进行计算。显然W(f)的维度为(hidden_size,hidden_size+x(t)),即128*(128+100)。后者是输入向量和状态向量拼合而成,参与运算。计算得出的向量长为128,经过sigmoid投射成一个长度为128的一维向量,里边的数字都介于0~1之间,作为忘记概率,准备与长时记忆C(t-1)相乘,意为把从头贯彻到终的长时记忆忘记多少。
此处的参数有两个,第一个是忘记weight矩阵W(f),维度128*228;第二个是参与运算的bias一维矩阵,长度为128。
(2)输入门
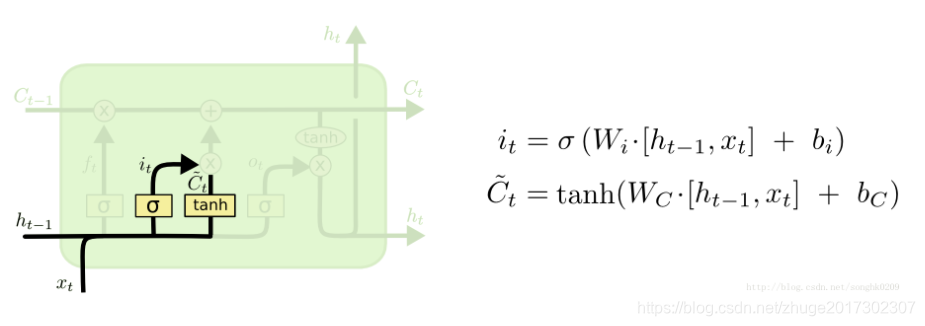
将两个输入:上一个时间步的cell工作状态h(t-1)和本时间步的输入x(t)整合起来,经过变换以后形成本cell的正式输入i(t)和。其中i(t)经过sigmoid变换成一个长度为128的概率一维向量,
也是长度为128的一维矩阵,前者是输入概率,后者是本cell的输入产生的工作状态,作为长时记忆的一部分乘以概率i(t)之后传入后边,也作为本cell的工作状态,经过tanh变换传入下一个cell,作为其输入的一部分。此处两个weight矩阵,都为128*(128+100),两个bias矩阵,长度都为128。其中W(i)是转换成输入的矩阵,W(c)是转换工作状态的矩阵,
(3)输出门
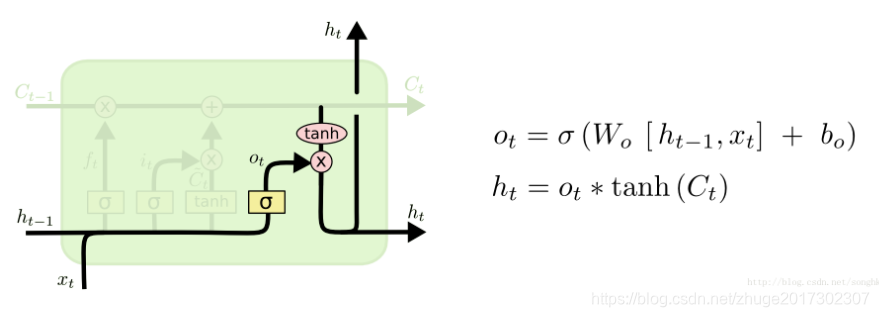
输出门控制cell的输出,即t时刻的工作状态h(t),其作为本时间步的输出传入下一个时刻参与运算。o(t)依然是一个长度为128的一维向量,以表示概率,与经过tanh变换的长时记忆C(t)相乘,作为本时间步的工作状态。此时的长时记忆C(t)已经经过更新,不仅包含了以前所有的记忆,也包含了本时间步的输入特点。所以能够构成本时间步的输出H(t)。此处有一个weight矩阵W(o),维度依然为128*228,一个Bias矩阵,长度为128。
(4)更新
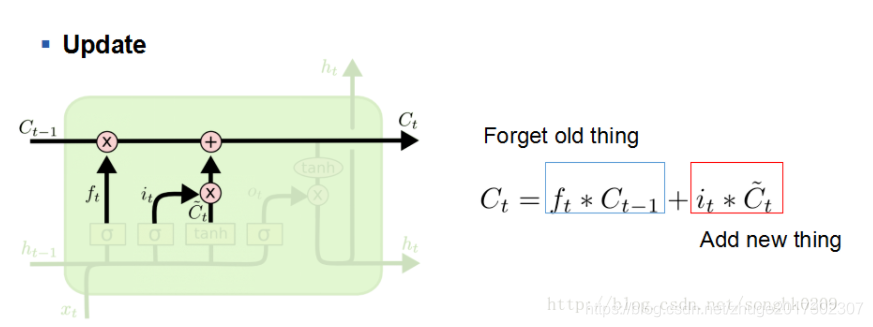
利用两个长度为128的概率向量i(t)和f(t)进行更新长时记忆C(t)。i(t)是输入的概率,输入是纯粹有本时间步的输入产生的,f(t)是忘记的概率,忘记以前的长时记忆C(t-1)的一部分。功能是忘记以前的一部分,加进去自己的一部分,以构成新的长时记忆。
所以总的来说,一个LSTM层有四个weight矩阵参数,四个bias参数,前者的长度为128*(128+100),后者为128。相比于RNN,参数多了很多,有句话说LSTM参数是RNN的四倍,这句话一定程度上是对的,但也不完全正确。
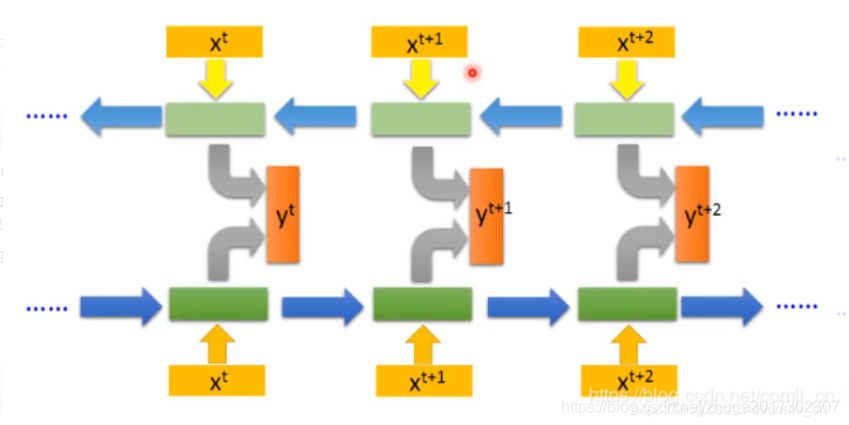
三、双向LSTM
单向LSTM和LSTM实现差别不大,但效果不一样。
import torch
rnn = torch.nn.LSTM(input_size=10, hidden_size=20, num_layers=2,bidirectional=True)#(input_size,hidden_size,num_layers)
input = torch.randn(5, 3, 10)#(seq_len, batch, input_size)
h0 = torch.randn(4, 3, 20) #(num_layers,batch,output_size)
c0 = torch.randn(4, 3, 20) #(num_layers,batch,output_size)
output, (hn, cn) = rnn(input, (h0, c0))只需要在torch.nn.LSTM()的括号中加入bidirectional=True就开启了双向LSTM。双向LSTM和单向LSTM的区别在于计算一个时间步的相关数值时只可以用到前面几步的数值,双向LSTM既可以用到前面几步,也可以用到后面几步。
比如说在补充一句话的时候:
“我要去__。”
这时用单向LSTM可以推测出空格里面应该填一个地名。但如果残句变为:
“我要__学校。”
这是只根据“我要”这两个字很难推出空格里面内容,但是如果结合“学校”就可以准确推测了。这就是双向LSTM的应用场景了。

















 2120
2120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









